Reducing Class Bias In Data-Balanced Datasets Through Hardness-Based Resampling
Pith reviewed 2026-05-22 19:39 UTC · model grok-4.3
The pith
Class bias persists in perfectly balanced datasets because some classes are harder to learn, and hardness-guided resampling reduces performance gaps between classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Class-bias, defined as class-wise performance disparities, continues in datasets that are perfectly balanced by frequency. Hardness-Based Resampling (HBR) uses estimates of class-level learning difficulty to guide which samples to keep or emphasize during training. When combined with gap- and dispersion-based evaluation metrics, HBR reduces recall gaps substantially compared with frequency-only methods and can be enhanced by drawing hardest examples from a state-of-the-art generative model.
What carries the argument
Hardness-Based Resampling (HBR), a data-selection strategy that replaces frequency-based balancing with hardness estimates computed from model behavior or auxiliary models to decide which examples to retain or prioritize.
If this is right
- Models trained under HBR exhibit smaller differences in per-class recall than those trained under frequency balancing.
- Gap- and dispersion-based metrics expose class disparities that global accuracy hides.
- Selectively retaining hardest samples from a diffusion model improves fairness without requiring new labeled data.
- Data balance by count is insufficient; hardness-aware curation is needed to mitigate class bias.
Where Pith is reading between the lines
- Dataset pipelines could incorporate hardness scoring as a standard preprocessing step alongside class balancing.
- The method may extend to other modalities such as text or tabular data where class difficulty also varies independently of frequency.
- Combining HBR with existing fairness techniques could produce additive gains in equitable performance.
Load-bearing premise
Hardness estimates derived from model behavior or auxiliary models can be computed reliably and transferred to guide resampling without creating circular dependence on the final trained model or introducing new selection biases.
What would settle it
Train the same architecture on two versions of a balanced dataset: one resampled by frequency alone and one by HBR using hardness scores computed from an independent auxiliary model; if the recall gap between classes remains unchanged or increases, the central claim fails.
Figures













read the original abstract
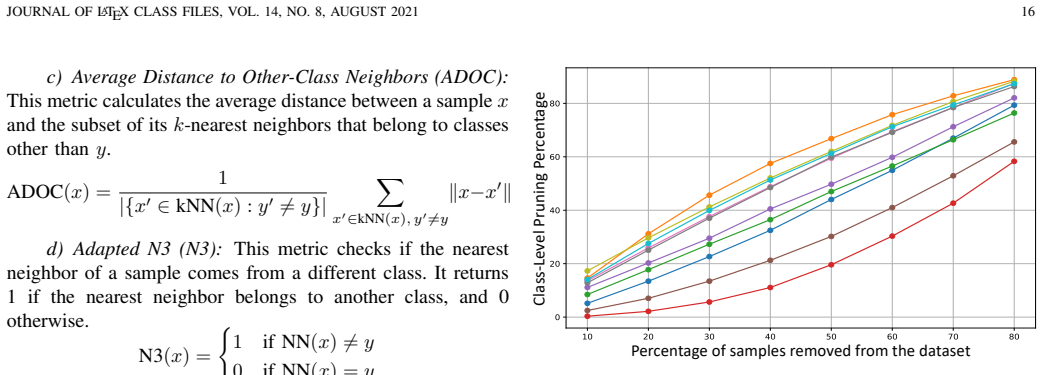
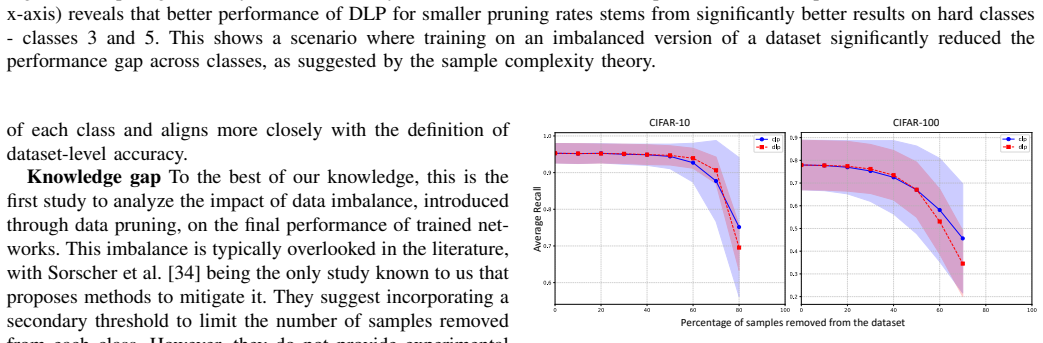
Class-bias, that is class-wise performance disparities, is typically attributed to data imbalance and addressed through frequency-based resampling. However, we demonstrate that substantial bias persists even in perfectly balanced datasets, proving that class frequency alone cannot explain unequal model performance. We investigate these disparities through the lens of class-level learning difficulty and propose Hardness-Based Resampling (HBR), a strategy that leverages hardness estimates to guide data selection. To better capture these effects, we introduce an evaluation protocol that complements global metrics with gap- and dispersion-based measures. Our experiments show that HBR significantly reduces recall gaps, by up to 32% on CIFAR-10 and 16% on CIFAR-100, outperforming standard frequency-based resampling. We further show that we can improve fairness outcomes by selectively using the hardest samples from a state-of-the-art diffusion model, rather than randomly selecting them. These findings demonstrate that data balance alone is insufficient to mitigate class bias, necessitating a shift toward hardness-aware approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that substantial class bias persists even in perfectly balanced datasets, showing that class frequency alone cannot explain unequal model performance across classes. It proposes Hardness-Based Resampling (HBR) that leverages hardness estimates to guide data selection instead of frequency-based approaches. The work introduces gap- and dispersion-based evaluation measures to complement global metrics and reports that HBR reduces recall gaps by up to 32% on CIFAR-10 and 16% on CIFAR-100 while outperforming standard resampling. Additional experiments demonstrate improved fairness by selecting the hardest samples from a diffusion model.
Significance. If the hardness estimates can be shown to be independent of the final model and evaluation, the result would meaningfully advance understanding of class bias beyond frequency imbalance. The shift toward hardness-aware resampling and the proposed gap/dispersion metrics could influence dataset curation practices in computer vision and imbalanced learning. The diffusion-model experiment provides an interesting direction for sourcing hard examples without new labeling.
major comments (2)
- Abstract: The hardness estimation method is not specified. This is load-bearing for the central claim because the reported gap reductions (32% on CIFAR-10, 16% on CIFAR-100) and the assertion that frequency alone is insufficient both depend on hardness being an independent, transferable signal rather than one derived from the same model or data distribution used for final evaluation.
- Abstract (experiments paragraph): No details are provided on how the perfectly balanced datasets were constructed, how hardness was computed for the main CIFAR results, or whether hardness calculation was separated from the training and evaluation loops. Without this separation, the resampling step risks embedding model-specific biases that the method aims to correct.
minor comments (2)
- Abstract: The phrase 'class-bias' is used without an explicit definition; a brief clarification of how it differs from standard class imbalance would improve readability.
- Abstract: The evaluation protocol is introduced but not named or summarized; a short description of the gap- and dispersion-based measures would help readers assess their novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications drawn from the manuscript and commit to revisions that improve the abstract's completeness without altering the core claims or results.
read point-by-point responses
-
Referee: [—] Abstract: The hardness estimation method is not specified. This is load-bearing for the central claim because the reported gap reductions (32% on CIFAR-10, 16% on CIFAR-100) and the assertion that frequency alone is insufficient both depend on hardness being an independent, transferable signal rather than one derived from the same model or data distribution used for final evaluation.
Authors: We agree that the abstract would be strengthened by briefly naming the hardness estimation approach. Section 3.2 of the manuscript defines hardness via per-sample loss averaged across multiple independent training runs on a held-out validation split, using a proxy architecture distinct from the final evaluation model. This procedure is designed to produce a transferable difficulty signal. We will revise the abstract to include a short clause specifying this independent, loss-based estimation method, thereby directly addressing the concern that the reported improvements rely on a non-independent signal. revision: yes
-
Referee: [—] Abstract (experiments paragraph): No details are provided on how the perfectly balanced datasets were constructed, how hardness was computed for the main CIFAR results, or whether hardness calculation was separated from the training and evaluation loops. Without this separation, the resampling step risks embedding model-specific biases that the method aims to correct.
Authors: Thank you for this observation. Section 4.1 explains that the perfectly balanced CIFAR-10/100 datasets are obtained by subsampling each class to the size of the smallest original class while retaining the original sample distribution within classes. Hardness values for the primary experiments are pre-computed once using a separate proxy model and validation split before any resampling or final training occurs. This explicit separation is maintained throughout to prevent leakage of evaluation-model biases into the selection process. We will expand the experiments paragraph in the abstract to concisely state the balanced-dataset construction method and confirm the pre-computed, separated hardness calculation. revision: yes
Circularity Check
No significant circularity; claims rest on empirical experiments rather than self-referential derivations
full rationale
The paper's central claims—that class bias persists in perfectly balanced datasets and that HBR reduces recall gaps—are presented as results of experiments on CIFAR-10/100. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the core result to its own inputs appear in the provided abstract or described structure. Hardness estimation is introduced as a guiding signal for resampling without any quoted definition that makes the reported gap reductions (32% or 16%) tautological by construction. The evaluation protocol using gap- and dispersion-based measures is an independent addition. This is the common case of an empirical paper whose findings can be externally checked against the stated datasets and metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data-centric artificial intelligence: A survey
Zha, D., Bhat, Z. P., Lai, K. H., Yang, F., Jiang, Z., Zhong, S., & Hu, X. (2025). “Data-centric artificial intelligence: A survey.” ACM Computing Surveys, 57(5), 1-42
work page 2025
- [2]
-
[3]
Deep long- tailed learning: A survey
Zhang, Y ., Kang, B., Hooi, B., Yan, S., & Feng, J. (2023). “Deep long- tailed learning: A survey.” IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9), 10795-10816
work page 2023
-
[4]
Imbalance problems in object detection: A review
Oksuz, K., Cam, B. C., Kalkan, S., & Akbas, E. (2020). “Imbalance problems in object detection: A review.” IEEE Transactions on Pattern Analysis and Machine Intelligence , 43(10), 3388-3415
work page 2020
-
[5]
CIFAR10 to compare visual recognition per- formance between deep neural networks and humans
Ho-Phuoc, T. (2018). “CIFAR10 to compare visual recognition per- formance between deep neural networks and humans.” arXiv preprint arXiv:1811.07270
-
[6]
Torralba, A., & Efros, A. A. (2011). “Unbiased look at dataset bias.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1521-1528
work page 2011
-
[7]
Goodfellow, I., Bengio, Y ., Courville, A., & Bengio, Y . (2016). “Deep learning.” V ol. 1, No. 2, Cambridge: MIT Press
work page 2016
-
[8]
Understanding machine learning: From theory to algorithms
Shalev-Shwartz, S., & Ben-David, S. (2014). “Understanding machine learning: From theory to algorithms.” Cambridge University Press
work page 2014
-
[9]
The true sample complexity of active learning
Balcan, M. F., Hanneke, S., & Vaughan, J. W. (2010). “The true sample complexity of active learning.” Machine Learning, 80, 111-139
work page 2010
-
[10]
On the Sample Complexity of Learning Bayesian Networks
Friedman, N., & Yakhini, Z. (2013). “On the sample complexity of learning Bayesian networks.” arXiv preprint arXiv:1302.3579
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Theoretical foundations of active learning
Hanneke, S. (2009). “Theoretical foundations of active learning.” Carnegie Mellon University
work page 2009
-
[12]
Neyshabur, B., Bhojanapalli, S., & Srebro, N. (2017). “A pac-bayesian approach to spectrally-normalized margin bounds for neural networks.’ International Conference on Learning Representations
work page 2017
-
[13]
Stronger generalization bounds for deep nets via a compression approach
Arora, S., Ge, R., Neyshabur, B., & Zhang, Y . (2018, July). “Stronger generalization bounds for deep nets via a compression approach.” In International conference on machine learning (pp. 254-263). PMLR
work page 2018
-
[14]
A theoretical- empirical approach to estimating sample complexity of dnns
Bisla, D., Saridena, A. N.,& Choromanska, A. (2021). “A theoretical- empirical approach to estimating sample complexity of dnns.” In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3270-3280)
work page 2021
-
[15]
An overview of statistical learning theory
Vapnik, V . N. (1999). “An overview of statistical learning theory.” IEEE transactions on neural networks , 10(5), 988-999
work page 1999
-
[16]
Metrics for dataset demographic bias: A case study on facial expression recognition
Dominguez-Catena, I., Paternain, D., & Galar, M. (2024). “Metrics for dataset demographic bias: A case study on facial expression recognition.” IEEE Transactions on Pattern Analysis and Machine Intelligence , 46(8), 5209-5226
work page 2024
-
[17]
Sarridis, I., Koutlis, C., Papadopoulos, S., & Diou, C. (2024). “Flac: Fairness-aware representation learning by suppressing attribute-class as- sociations.’IEEE Transactions on Pattern Analysis and Machine Intelli- gence
work page 2024
-
[18]
Learning classifiers when the training data is not IID
Dundar, M., Krishnapuram, B., Bi, J., & Rao, R. B. (2007, January). “Learning classifiers when the training data is not IID.” International Joint Conference on Artificial Intelligence (V ol. 2007, pp. 756-61)
work page 2007
-
[19]
Detecting Outliers in Non-IID Data: A Systematic Literature Review
Siddiqi, S., Qureshi, F., Lindstaedt, S., & Kern, R. (2023). “Detecting Outliers in Non-IID Data: A Systematic Literature Review.”IEEE Access, 11, 70333-70352
work page 2023
-
[20]
Towards non-iid image classification: A dataset and baselines
He, Y ., Shen, Z., & Cui, P. (2021). “Towards non-iid image classification: A dataset and baselines.” Pattern Recognition, 110, 107383
work page 2021
-
[21]
Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
Cummings, J., Snorrason, E., & Mueller, J. (2023). “Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors.”’ arXiv preprint arXiv:2305.15696
-
[22]
Are all linear regions created equal?
Gamba, M., Chmielewski-Anders, A., Sullivan, J., Azizpour, H., & Bjorkman, M. (2022, May). “Are all linear regions created equal?” In International Conference on Artificial Intelligence and Statistics (pp. 6573-6590). PMLR
work page 2022
-
[23]
Overparameterization from computational constraints
Garg, S., Jha, S., Mahloujifar, S., Mahmoody, M., & Wang, M. (2022). “Overparameterization from computational constraints.”Advances in Neu- ral Information Processing Systems , 35, 13557-13569
work page 2022
-
[24]
Implicit Regularization in Deep Learning
Neyshabur, B. (2017). “Implicit regularization in deep learning.” arXiv preprint arXiv:1709.01953
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Learnability and the Vapnik-Chervonenkis dimension
Blumer, A., Ehrenfeucht, A., Haussler, D., & Warmuth, M. K. (1989). “Learnability and the Vapnik-Chervonenkis dimension.” Journal of the ACM (JACM), 36(4), 929-965
work page 1989
-
[26]
Why over-parameterization of deep neural net- works does not overfit
Zhou, Z. H. (2021). “Why over-parameterization of deep neural net- works does not overfit.” Science China Information Sciences , 64(1), 1-3
work page 2021
-
[27]
Identifying mislabeled data using the area under the margin ranking
Pleiss, G., Zhang, T., Elenberg, E., & Weinberger, K. Q. (2020). “Identifying mislabeled data using the area under the margin ranking.” Advances in Neural Information Processing Systems , 33, 17044-17056
work page 2020
-
[28]
Deep learning on a data diet: Finding important examples early in training
Paul, M., Ganguli, S., & Dziugaite, G. K. (2021). “Deep learning on a data diet: Finding important examples early in training.” Advances in neural information processing systems , 34, 20596-20607
work page 2021
-
[29]
An empirical study of example forgetting during deep neural network learning
Toneva, M., Sordoni, A., Combes, R. T. D., Trischler, A., Bengio, Y ., & Gordon, G. J. (2018). “An empirical study of example forgetting during deep neural network learning.” International Conference on Learning Representations
work page 2018
-
[30]
Bengio, Y ., Louradour, J., Collobert, R., & Weston, J. (2009, June). “Curriculum learning.” In Proceedings of the 26th annual international conference on machine learning (pp. 41-48)
work page 2009
-
[31]
A survey on curriculum learn- ing
Wang, X., Chen, Y ., & Zhu, W. (2021). “A survey on curriculum learn- ing.” IEEE transactions on pattern analysis and machine intelligence , 44(9), 4555-4576
work page 2021
-
[32]
Annotation Efficiency: Identifying Hard Samples via Blocked Sparse Linear Bandits
Jain, A., Pal, S., Choudhary, S., Narayanam, R., & Krishnamurthy, V . (2024). “Annotation Efficiency: Identifying Hard Samples via Blocked Sparse Linear Bandits.” arXiv preprint arXiv:2410.20041
-
[33]
A survey on instance selection for active learning
Fu, Y ., Zhu, X., & Li, B. (2013). “A survey on instance selection for active learning.” Knowledge and information systems , 35, 249-283
work page 2013
-
[34]
Beyond neural scaling laws: beating power law scaling via data pruning
Sorscher, B., Geirhos, R., Shekhar, S., Ganguli, S., & Morcos, A. (2022). “Beyond neural scaling laws: beating power law scaling via data pruning.” Advances in Neural Information Processing Systems , 35, 19523-19536
work page 2022
-
[35]
Sachdeva, N., & McAuley, J. (2023). “Data Distillation: A Survey.” Transactions on Machine Learning Research , 2023
work page 2023
-
[36]
Learning multiple layers of features from tiny images
Krizhevsky, A., & Hinton, G. (2009). “Learning multiple layers of features from tiny images.”
work page 2009
-
[37]
Pervasive label errors in test sets destabilize machine learning benchmarks
Northcutt, C. G., Athalye, A., & Mueller, J. (2021). “Pervasive label errors in test sets destabilize machine learning benchmarks.” Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1,
work page 2021
-
[38]
SMOTE: synthetic minority over-sampling technique
Chawla, N. V ., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). “SMOTE: synthetic minority over-sampling technique.” Journal of artificial intelligence research , 16, 321-357
work page 2002
-
[39]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., ... & Chintala, S. (2019). “Pytorch: An imperative style, high-performance deep learning library.” Advances in neural information processing systems , 32
work page 2019
-
[40]
The intrinsic dimension of images and its impact on learning
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., & Goldstein, T. (2021). “The intrinsic dimension of images and its impact on learning.” International Conference on Learning Representations
work page 2021
-
[41]
Ma, Y ., Jiao, L., Liu, F., Li, Y ., Yang, S., & Liu, X. (2023). “Delving into semantic scale imbalance.’ International Conference on Learning Representations
work page 2023
-
[42]
Curvature- balanced feature manifold learning for long-tailed classification
Ma, Y ., Jiao, L., Liu, F., Yang, S., Liu, X., & Li, L. (2023). “Curvature- balanced feature manifold learning for long-tailed classification.” In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15824-15835
work page 2023
-
[43]
Data representations’ study of latent image manifolds
Kaufman, I., & Azencot, O. (2023, July). “Data representations’ study of latent image manifolds.” In International Conference on Machine Learning (pp. 15928-15945). PMLR
work page 2023
-
[44]
Kaushik, C., Liu, R., Lin, C. H., Khera, A., Jin, M. Y ., Ma, W., ... & Dyer, E. L. (2024). “Balanced Data, Imbalanced Spectra: Unveiling Class Disparities with Spectral Imbalance.’ International Conference on Machine Learning
work page 2024
-
[45]
Kaushik, C., Liu, R., Lin, C. H., Khera, A., Jin, M. Y ., Ma, W., ... & Dyer, E. L. (2024). “Balanced Data, Imbalanced Spectra: Unveiling JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 19 Class Disparities with Spectral Imbalance.” International Conference on Machine Learning
work page 2024
-
[46]
Measuring the complexity of classification problems
Ho, T. K., & Basu, M. (2000, September). “Measuring the complexity of classification problems.” In Proceedings 15th International Conference on Pattern Recognition. ICPR-2000 (V ol. 2, pp. 43-47). IEEE
work page 2000
-
[47]
Measures of geomet- rical complexity in classification problems
Ho, T. K., Basu, M., & Law, M. H. C. (2006). “Measures of geomet- rical complexity in classification problems.” Data complexity in pattern recognition, 1-23
work page 2006
-
[48]
Assessing the data complexity of imbalanced datasets
Barella, V . H., Garcia, L. P., de Souto, M. C., Lorena, A. C., & de Carvalho, A. C. (2021). “Assessing the data complexity of imbalanced datasets.” Information Sciences, 553, 83-109
work page 2021
-
[49]
On the class overlap problem in imbalanced data classification
Vuttipittayamongkol, P., Elyan, E., & Petrovski, A. (2021). “On the class overlap problem in imbalanced data classification.” Knowledge- based systems, 212, 106631
work page 2021
-
[50]
Intrinsic dimension of data representations in deep neural networks
Ansuini, A., Laio, A., Macke, J. H., & Zoccolan, D. (2019). “Intrinsic dimension of data representations in deep neural networks.” Advances in Neural Information Processing Systems , 32
work page 2019
-
[51]
Intrinsic dimension, persistent homology and generalization in neural networks
Birdal, T., Lou, A., Guibas, L. J., & Simsekli, U. (2021). “Intrinsic dimension, persistent homology and generalization in neural networks.” Advances in neural information processing systems , 34, 6776-6789
work page 2021
-
[52]
Topology of deep neural networks
Naitzat, G., Zhitnikov, A., & Lim, L. H. (2020). “Topology of deep neural networks.” Journal of Machine Learning Research , 21(184), 1-40
work page 2020
-
[53]
Deep neural networks architectures from the perspective of manifold learning
Magai, G. (2023, August). “Deep neural networks architectures from the perspective of manifold learning.” In 2023 IEEE 6th International Conference on Pattern Recognition and Artificial Intelligence (PRAI) (pp. 1021-1031). IEEE
work page 2023
-
[54]
On characterizing the evolution of embedding space of neural networks using algebraic topology
Suresh, S., Das, B., Abrol, V ., & Roy, S. D. (2024). “On characterizing the evolution of embedding space of neural networks using algebraic topology.” Pattern Recognition Letters, 179, 165-171
work page 2024
-
[55]
The effect of manifold entanglement and intrinsic dimensionality on learning
Kienitz, D., Komendantskaya, E., & Lones, M. (2022, June). “The effect of manifold entanglement and intrinsic dimensionality on learning.” In Proceedings of the AAAI Conference on Artificial Intelligence (V ol. 36, No. 7, pp. 7160-7167)
work page 2022
-
[56]
Seedat, N., Imrie, F., & van der Schaar, M. (2024). “Dissecting sample hardness: A fine-grained analysis of hardness characterization methods for data-centric.” International Conference on Learning Representations
work page 2024
-
[57]
The mnist database of handwritten digit images for machine learning research [best of the web]
Deng, L. (2012). “The mnist database of handwritten digit images for machine learning research [best of the web].” IEEE signal processing magazine, 29(6), 141-142
work page 2012
-
[58]
Deep Learning for Classical Japanese Literature
Clanuwat, T., Bober-Irizar, M., Kitamoto, A., Lamb, A., Yamamoto, K., & Ha, D. (2018). “Deep learning for classical japanese literature.” arXiv preprint arXiv:1812.01718
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., & V ollgraf, R. (2017). “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.” arXiv preprint arXiv:1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
Exploring the learning difficulty of data: Theory and measure
Zhu, W., Wu, O., Su, F., & Deng, Y . (2024). “Exploring the learning difficulty of data: Theory and measure.”ACM Transactions on Knowledge Discovery from Data , 18(4), 1-37
work page 2024
-
[61]
How complex is your classification problem? a survey on measuring classification complexity
Lorena, A. C., Garcia, L. P., Lehmann, J., Souto, M. C., & Ho, T. K. (2019). “How complex is your classification problem? a survey on measuring classification complexity.” ACM Computing Surveys (CSUR) , 52(5), 1-34
work page 2019
-
[62]
ADASYN: Adaptive synthetic sampling approach for imbalanced learning
He, H., Bai, Y ., Garcia, E. A., & Li, S. (2008, June). “ADASYN: Adaptive synthetic sampling approach for imbalanced learning.” In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence) (pp. 1322-1328). Ieee
work page 2008
-
[63]
Class-difficulty based methods for long-tailed visual recognition
Sinha, S., Ohashi, H., & Nakamura, K. (2022). “Class-difficulty based methods for long-tailed visual recognition.” International Journal of Computer Vision, 130(10), 2517-2531
work page 2022
-
[64]
Differences between hard and noisy-labeled samples: An empirical study
Forouzesh, M., & Thiran, P. (2024). “Differences between hard and noisy-labeled samples: An empirical study.” In Proceedings of the 2024 SIAM International Conference on Data Mining (SDM) (pp. 91-99). Society for Industrial and Applied Mathematics
work page 2024
-
[65]
Inversion dynamics of class manifolds in deep learning reveals tradeoffs underlying generalization
Ciceri, S., Cassani, L., Osella, M., Rotondo, P., Valle, F., & Gherardi, M. (2024). “Inversion dynamics of class manifolds in deep learning reveals tradeoffs underlying generalization.” Nature Machine Intelligence , 6(1), 40-47
work page 2024
-
[66]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Frankle, J., & Carbin, M. (2018). “The lottery ticket hypothesis: Finding sparse, trainable neural networks.”’International Conference on Learning Representations
work page 2018
-
[67]
Har: Hardness aware reweighting for imbalanced datasets
Duggal, R., Freitas, S., Dhamnani, S., Chau, D. H., & Sun, J. (2021, December). “Har: Hardness aware reweighting for imbalanced datasets.” In 2021 IEEE International Conference on Big Data (Big Data) (pp. 735-745). IEEE
work page 2021
-
[68]
Marchesi, R., Micheletti, N., Kuo, N., Barbieri, S., Jurman, G. & Osmani, V . Generative AI Mitigates Representation Bias and Improves Model Fairness Through Synthetic Health Data. MedRxiv. (2025), https://www.medrxiv.org/content/early/2025/02/27/2023.09.26.23296163
work page 2025
-
[69]
Confident learning: Estimating uncertainty in dataset labels
Northcutt, C., Jiang, L., & Chuang, I. (2021). “Confident learning: Estimating uncertainty in dataset labels.” Journal of Artificial Intelligence Research, 70, 1373-1411
work page 2021
-
[70]
An interpretable measure of dataset complexity for imbalanced classification problems
Gøttcke, J. M. N., Bellinger, C., Branco, P., & Zimek, A. (2023). “An interpretable measure of dataset complexity for imbalanced classification problems.” In Proceedings of the 2023 SIAM International Conference on Data Mining (SDM) (pp. 253-261). Society for Industrial and Applied Mathematics
work page 2023
-
[71]
Spectral active clus- tering via purification of the k-nearest neighbor graph
Xiong, C., Johnson, D., & Corso, J. J. (2012, July). “Spectral active clus- tering via purification of the k-nearest neighbor graph.” In Proceedings of European conference on data mining (V ol. 1, No. 2, p. 3)
work page 2012
-
[72]
Concept Learning and the Problem of Small Disjuncts
Holte, R. C., Acker, L., & Porter, B. W. (1989, August). “Concept Learning and the Problem of Small Disjuncts.” In IJCAI (V ol. 89, pp. 813-818)
work page 1989
-
[73]
Concept-learning in the presence of between-class and within-class imbalances
Japkowicz, N. (2001, May). “Concept-learning in the presence of between-class and within-class imbalances.” In Conference of the Cana- dian society for computational studies of intelligence (pp. 67-77). Berlin, Heidelberg: Springer Berlin Heidelberg. BIOGRAPHY Pawel Pukowski is a Ph.D. candidate at the University of Sheffield, Sheffield, UK. His research ...
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.