FedOptima: Optimizing Resource Utilization in Federated Learning
Pith reviewed 2026-05-22 23:55 UTC · model grok-4.3
The pith
FedOptima minimizes both task-dependency and straggler idle times in federated learning by offloading selected layers to the server.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FedOptima offloads the training of certain layers of a neural network from a device to a server using three innovations. First, devices operate independently of each other using asynchronous aggregation to eliminate straggler effects, and independently of the server by utilizing auxiliary networks to minimize idle time caused by task dependency. Second, the server performs centralized training using a task scheduler that ensures balanced contributions from all devices, improving model accuracy. Third, an efficient memory management mechanism on the server increases the scalability of the number of participating devices. This yields higher or comparable accuracy, 1.9x to 21.8x faster training
What carries the argument
Layer offloading to the server via auxiliary networks together with asynchronous aggregation and centralized server scheduling.
If this is right
- Training finishes faster even when devices differ widely in speed.
- Both server and devices spend far less time idle while waiting.
- More devices can participate without exhausting server memory.
- Accuracy holds steady on image classification and sentiment analysis.
- Overall system throughput rises compared with prior offloading and asynchronous approaches.
Where Pith is reading between the lines
- The same offloading pattern could be tested in other distributed training settings that mix edge devices with a central server.
- Dynamic layer selection based on live device measurements might further reduce idle time beyond the fixed choices in the paper.
- Energy use on battery-powered devices could drop as a direct result of shorter overall participation time.
- The centralized scheduler might be adapted to incorporate privacy constraints without reintroducing dependency waits.
Load-bearing premise
Offloading selected layers to the server via auxiliary networks preserves model accuracy across heterogeneous devices and the lab testbeds represent real-world network conditions and participation patterns.
What would settle it
An experiment on devices with greater compute and network heterogeneity than the testbeds where FedOptima either drops below baseline accuracy or fails to cut idle times by the reported margins.
Figures









read the original abstract
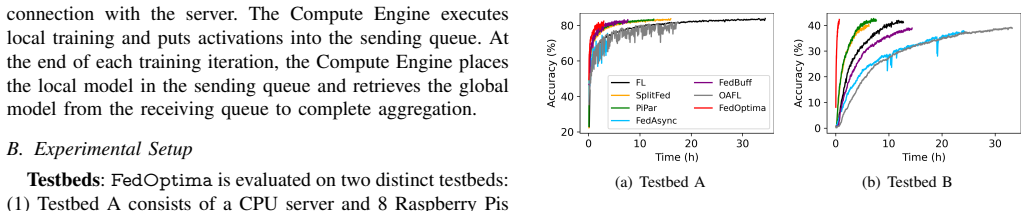
Federated learning (FL) systems facilitate distributed machine learning across a server and multiple devices. However, FL systems have low resource utilization on servers and devices, limiting their practical use in the real world. This inefficiency primarily arises from two types of idle time: (i) task dependency between the server and devices, and (ii) stragglers among heterogeneous devices. This paper introduces FedOptima, a resource-optimized FL system designed to simultaneously minimize both types of idle time; existing systems do not eliminate or reduce both at the same time. FedOptima offloads the training of certain layers of a neural network from a device to a server using three innovations. First, devices operate independently of each other using asynchronous aggregation to eliminate straggler effects, and independently of the server by utilizing auxiliary networks to minimize idle time caused by task dependency. Second, the server performs centralized training using a task scheduler that ensures balanced contributions from all devices, improving model accuracy. Third, an efficient memory management mechanism on the server increases the scalability of the number of participating devices. Extensive experiments are conducted on multiple lab-based testbeds, evaluated on image classification and sentiment analysis tasks with CNNs and Transformers. Compared to four state-of-the-art offloading-based and asynchronous FL baselines, FedOptima (i) achieves higher or comparable accuracy, (ii) accelerates training by 1.9x to 21.8x, (iii) reduces server and device idle time by up to 93.9% and 81.8%, respectively, and (iv) increases throughput by 1.1x to 2.0x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FedOptima, a federated learning system that employs layer offloading to the server via auxiliary networks, asynchronous aggregation among devices, a centralized task scheduler to ensure balanced device contributions, and server-side memory management. These mechanisms are claimed to simultaneously eliminate task-dependency idle time and straggler idle time. Experiments on image classification and sentiment analysis tasks with CNNs and Transformers report higher or comparable accuracy, 1.9x–21.8x faster training, up to 93.9% server and 81.8% device idle-time reduction, and 1.1x–2.0x higher throughput versus four baselines on lab testbeds.
Significance. If the accuracy and performance claims hold under rigorous validation, the work would be significant for practical FL deployment in heterogeneous environments by addressing both sources of idle time concurrently, a gap not covered by prior offloading or asynchronous systems. The experimental comparisons to external baselines provide concrete evidence of gains in speed and utilization.
major comments (1)
- [Abstract / innovations paragraph] Abstract, innovations paragraph: The claim that the centralized task scheduler 'ensures balanced contributions from all devices, improving model accuracy' provides no concrete mechanism (e.g., staleness weighting, gradient correction, or convergence bound) to counteract potential instability from asynchronous aggregation with auxiliary networks under device heterogeneity. This link is load-bearing for the 'higher or comparable accuracy' result, as the abstract asserts the scheduler achieves balance but does not demonstrate how.
minor comments (2)
- The abstract reports speedups and idle-time reductions but omits details on number of experimental runs, error bars, statistical tests, or exclusion criteria for the lab testbeds.
- The four baselines are described only as 'state-of-the-art offloading-based and asynchronous FL baselines' without explicit names or implementation references in the provided abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / innovations paragraph] Abstract, innovations paragraph: The claim that the centralized task scheduler 'ensures balanced contributions from all devices, improving model accuracy' provides no concrete mechanism (e.g., staleness weighting, gradient correction, or convergence bound) to counteract potential instability from asynchronous aggregation with auxiliary networks under device heterogeneity. This link is load-bearing for the 'higher or comparable accuracy' result, as the abstract asserts the scheduler achieves balance but does not demonstrate how.
Authors: We agree that the abstract and innovations paragraph assert the scheduler's balancing role without specifying its concrete policy. The manuscript body describes the scheduler as a centralized priority queue that allocates tasks according to each device's recent participation rate and current load, but this detail is not carried into the abstract. Because the accuracy claim is indeed load-bearing, we will revise the abstract to briefly state the policy (dynamic re-prioritization by historical contribution) and will add one sentence in the innovations paragraph that notes the empirical accuracy results under asynchrony. No new convergence bound is claimed or derived in the current work. revision: yes
Circularity Check
No circularity; empirical system evaluation against external baselines
full rationale
The paper describes a systems architecture (layer offloading, asynchronous aggregation, task scheduler, memory management) and reports experimental outcomes on accuracy, training time, idle time, and throughput versus four external baselines. No equations, fitted parameters, predictions, or first-principles derivations appear in the abstract or description. All performance claims rest on direct comparison to independent baselines rather than any self-referential definition, renaming, or self-citation chain. This is the expected non-finding for an applied systems paper whose central results are falsifiable measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-Efficient Learning of Deep Networks from Decentral- ized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentral- ized Data,” in 20th International Conference on Artificial Intelligence and Statistics, vol. 54, 2017, pp. 1273–1282
work page 2017
-
[2]
Federated Optimization: Distributed Optimization Beyond the Datacenter,
J. Kone ˇcn´y, B. McMahan, and D. Ramage, “Federated Optimization: Distributed Optimization Beyond the Datacenter,” 8th NIPS Workshop on Optimization for Machine Learning , 2015
work page 2015
-
[3]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
J. Kone ˇcn´y, H. B. McMahan, D. Ramage, and P. Richt ´arik, “Federated Optimization: Distributed Machine Learning for On-Device Intelli- gence,” CoRR, vol. abs/1610.02527, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
SplitFed: When Fed- erated Learning Meets Split Learning,
C. Thapa, M. A. P. Chamikara, and S. Camtepe, “SplitFed: When Fed- erated Learning Meets Split Learning,” AAAI Conference on Artificial Intelligence, vol. 36(8), pp. 8485–8493, 2022
work page 2022
-
[5]
PiPar: Pipeline Parallelism for Collaborative Machine Learning,
Z. Zhang, P. Rodgers, P. Kilpatrick, I. Spence, and B. Varghese, “PiPar: Pipeline Parallelism for Collaborative Machine Learning,” Journal of Parallel and Distributed Computing , vol. 193, p. 104947, 2024
work page 2024
-
[6]
Communication and Storage Efficient Federated Split Learning,
Y . Mu and C. Shen, “Communication and Storage Efficient Federated Split Learning,” in IEEE International Conf. on Communications , 2023
work page 2023
-
[7]
Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge,
C. He, M. Annavaram, and S. Avestimehr, “Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge,” in 34th International Conference on Neural Information Processing Systems , 2020
work page 2020
-
[8]
Incentivizing Participation in SplitFed Learning: Convergence Analysis and Model Versioning,
P. Han, C. Huang, X. Shi, J. Huang, and X. Liu, “Incentivizing Participation in SplitFed Learning: Convergence Analysis and Model Versioning,” in2024 IEEE 44th International Conference on Distributed Computing Systems, 2024, pp. 846–856
work page 2024
-
[9]
Asynchronous Federated Optimiza- tion,
C. Xie, O. Koyejo, and I. Gupta, “Asynchronous Federated Optimiza- tion,” in 12th Workshop on Optimization for Machine Learning , 2023
work page 2023
-
[10]
Federated Learning with Buffered Asynchronous Aggrega- tion,
J. Nguyen, K. Malik, H. Zhan, A. Yousefpour, M. Rabbat, M. Malek, and D. Huba, “Federated Learning with Buffered Asynchronous Aggrega- tion,” in Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , vol. 151, 2022, pp. 3581–3607
work page 2022
-
[11]
Libra: A Fairness-Guaranteed Framework for Semi-Asynchronous Federated Learning,
C. Wang, H. Huang, R. Li, J. Liu, T. Cai, and Z. Zheng, “Libra: A Fairness-Guaranteed Framework for Semi-Asynchronous Federated Learning,” in 2024 IEEE 44th International Conference on Distributed Computing Systems, 2024, pp. 797–808
work page 2024
-
[12]
A. Howard, M. Sandler, G. Chu, L. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevan, Q. V . Le, and H. Adam, “Searching for MobileNetV3,” IEEE/CVF International Conference on Computer Vision, pp. 1314–1324, 2019
work page 2019
-
[13]
ImageNet Large Scale Visual Recognition Challenge
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” CoRR, vol. abs/1409.0575, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Very Deep Convolutional Networks for Large-scale Image Recognition,
K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-scale Image Recognition,” 3rd International Conference on Learning Representations, p. 1–14, 2015
work page 2015
-
[15]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
work page 2016
-
[16]
Deep Learning with Differential Privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep Learning with Differential Privacy,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016, p. 308–318
work page 2016
-
[17]
Certified Robustness to Adversarial Examples with Differential Privacy,
M. Lecuyer, V . Atlidakis, R. Geambasu, D. Hsu, and S. Jana, “Certified Robustness to Adversarial Examples with Differential Privacy,” in 2019 IEEE Symposium on Security and Privacy (SP) , 2019, pp. 656–672
work page 2019
-
[18]
Oort: Efficient Federated Learning via Guided Participant Selection,
F. Lai, X. Zhu, H. V . Madhyastha, and M. Chowdhury, “Oort: Efficient Federated Learning via Guided Participant Selection,” in 15th USENIX Symposium on Operating Systems Design and Implementation , 2021
work page 2021
-
[19]
REFL: Resource-Efficient Federated Learning,
A. M. Abdelmoniem, A. N. Sahu, M. Canini, and S. A. Fahmy, “REFL: Resource-Efficient Federated Learning,” in Proceedings of the Eigh- teenth European Conference on Computer Systems , 2023, p. 215–232
work page 2023
-
[20]
Federated Learning for Internet of Things,
T. Zhang, C. He, T. Ma, L. Gao, M. Ma, and S. Avestimehr, “Federated Learning for Internet of Things,” in 19th ACM Conference on Embedded Networked Sensor Systems , 2021, p. 413–419
work page 2021
-
[21]
Model Pruning Enables Efficient Federated Learning on Edge Devices,
Y . Jiang, S. Wang, V . Valls, B. J. Ko, W.-H. Lee, K. K. Leung, and L. Tassiulas, “Model Pruning Enables Efficient Federated Learning on Edge Devices,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 374–10 386, 2023
work page 2023
-
[22]
FedAdapt: Adaptive Offloading for IoT Devices in Federated Learning,
D. Wu, R. Ullah, P. Harvey, P. Kilpatrick, I. Spence, and B. Varghese, “FedAdapt: Adaptive Offloading for IoT Devices in Federated Learning,” IEEE Internet of Things Journal, vol. 9, no. 21, pp. 20 889–20 901, 2022
work page 2022
-
[23]
CIFAR-10 (Canadian Institute for Advanced Research),
A. Krizhevsky, V . Nair, and G. Hinton, “CIFAR-10 (Canadian Institute for Advanced Research),” 2009
work page 2009
-
[24]
Learning Multiple Layers of Features from Tiny Images,
A. Krizhevsky and G. Hinton, “Learning Multiple Layers of Features from Tiny Images,” Master’s thesis, Department of Computer Science, University of Toronto, 2009
work page 2009
-
[25]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is All you Need,” inAdvances in Neural Information Processing Systems , vol. 30, 2017
work page 2017
-
[26]
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts, “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing , 2013, pp. 1631–1642
work page 2013
-
[27]
Learning Word Vectors for Sentiment Analysis,
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts, “Learning Word Vectors for Sentiment Analysis,” in Proceedings of the 11 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, June 2011, pp. 142–150
work page 2011
-
[28]
Federated Learning Based on Dynamic Regularization,
D. A. E. Acar, Y . Zhao, R. Matas, M. Mattina, P. Whatmough, and V . Saligrama, “Federated Learning Based on Dynamic Regularization,” in International Conference on Learning Representations , 2021
work page 2021
-
[29]
Distributed Learning of Deep Neural Network over Multiple Agents,
O. Gupta and R. Raskar, “Distributed Learning of Deep Neural Network over Multiple Agents,” Journal of Network and Computer Applications , vol. 116, pp. 1–8, 2018
work page 2018
-
[30]
Split Learning For Health: Distributed Deep Learning without Sharing Raw Patient Data,
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split Learning For Health: Distributed Deep Learning without Sharing Raw Patient Data,” in ICLR Workshop on AI for Social Good , 2019
work page 2019
-
[31]
SplitGP: Achieving Both Generalization and Personalization in Federated Learn- ing,
D.-J. Han, D.-Y . Kim, M. Choi, C. G. Brinton, and J. Moon, “SplitGP: Achieving Both Generalization and Personalization in Federated Learn- ing,” in IEEE Conference on Computer Communications , 2023. 12
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.