FreeGraftor: Training-Free Cross-Image Feature Grafting for Subject-Driven Text-to-Image Generation
Pith reviewed 2026-05-22 18:03 UTC · model grok-4.3
The pith
FreeGraftor performs subject-driven text-to-image generation without any training by grafting features from reference images via semantic matching and attention fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FreeGraftor is a training-free framework for subject-driven text-to-image generation that leverages semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to generated images. A novel noise initialization strategy preserves geometry priors of the subjects. This enables precise subject identity transfer while maintaining text-aligned scene synthesis, outperforming existing zero-shot and training-free approaches in both subject fidelity and text alignment, and extends seamlessly to multi-subject generation.
What carries the argument
Cross-image feature grafting through semantic matching to identify corresponding regions and position-constrained attention fusion to blend visual details while respecting spatial layout, combined with a novel noise initialization strategy.
If this is right
- Precise subject identity transfer from reference images to new scenes without fine-tuning.
- Improved text alignment compared to prior zero-shot and training-free methods.
- Natural extension to multi-subject generation in a single process.
- Faster and more practical deployment for real-world custom image synthesis.
Where Pith is reading between the lines
- This grafting strategy could enable on-device personalization in consumer image tools by removing per-user training costs.
- The same matching and fusion steps might extend to maintaining consistency across frames in video generation tasks.
- Careful cross-image detail transfer could substitute for optimization in other identity-sensitive generative applications.
Load-bearing premise
Semantic matching combined with position-constrained attention fusion will reliably transfer fine visual details from reference subjects without any subject-specific optimization or post-processing.
What would settle it
Generate images using reference subjects that contain fine details such as text on fabric or subtle facial expressions, then check whether those exact details appear accurately in outputs for prompts that change pose or context.
Figures









read the original abstract
Subject-driven image generation aims to synthesize novel scenes that faithfully preserve subject identity from reference images while adhering to textual guidance. However, existing methods struggle with a critical trade-off between fidelity and efficiency. Tuning-based approaches rely on time-consuming and resource-intensive, subject-specific optimization, while zero-shot methods often fail to maintain adequate subject consistency. In this work, we propose FreeGraftor, a training-free framework that addresses these limitations through cross-image feature grafting. Specifically, FreeGraftor leverages semantic matching and position-constrained attention fusion to transfer visual details from reference subjects to the generated images. Additionally, our framework introduces a novel noise initialization strategy to preserve the geometry priors of reference subjects, facilitating robust feature matching. Extensive qualitative and quantitative experiments demonstrate that our method enables precise subject identity transfer while maintaining text-aligned scene synthesis. Without requiring model fine-tuning or additional training, FreeGraftor significantly outperforms existing zero-shot and training-free approaches in both subject fidelity and text alignment. Furthermore, our framework can seamlessly extend to multi-subject generation, making it practical for real-world deployment. Our code is available at https://github.com/Nihukat/FreeGraftor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FreeGraftor, a training-free approach for subject-driven text-to-image generation. It uses semantic matching and position-constrained attention fusion to transfer features from reference images, along with noise initialization for geometry preservation. Extensive experiments are said to show superior performance over zero-shot and training-free methods in subject fidelity and text alignment, with support for multi-subject generation.
Significance. This work could be significant if the claims hold, as it provides an efficient, training-free alternative to resource-intensive tuning methods for personalized image generation. The public availability of the code supports reproducibility and allows for further validation and extension by the community.
major comments (2)
- The core mechanism of semantic matching combined with position-constrained attention fusion lacks an explicit mechanism (such as keypoint alignment or feature normalization) to correct for geometric mismatches in scale, pose, or occlusion between reference and target subjects. This assumption is load-bearing for the central claim of precise subject identity transfer, as diffusion U-Net attention maps are typically coarse and semantically driven rather than detail-preserving.
- The quantitative evaluation section should provide ablation studies isolating the contributions of semantic matching, position-constrained fusion, and noise initialization, along with explicit details on all baselines, metrics (e.g., CLIP scores, identity similarity), and datasets to substantiate the reported outperformance.
minor comments (1)
- The abstract states that the method 'significantly outperforms' existing approaches but does not name the specific zero-shot and training-free baselines used; adding these names would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate to improve clarity and completeness.
read point-by-point responses
-
Referee: The core mechanism of semantic matching combined with position-constrained attention fusion lacks an explicit mechanism (such as keypoint alignment or feature normalization) to correct for geometric mismatches in scale, pose, or occlusion between reference and target subjects. This assumption is load-bearing for the central claim of precise subject identity transfer, as diffusion U-Net attention maps are typically coarse and semantically driven rather than detail-preserving.
Authors: We appreciate this observation on geometric robustness. Our semantic matching operates on deep semantic features from the U-Net, which provide a degree of invariance to moderate scale and pose changes, while the position-constrained attention fusion explicitly restricts feature transfer to spatially corresponding regions to mitigate misalignment. The noise initialization further anchors geometry. That said, we acknowledge that extreme occlusions or large pose discrepancies remain challenging for attention-based methods in general. In the revision we will add a dedicated limitations paragraph discussing these cases and include qualitative examples of failure modes under severe geometric mismatch. revision: partial
-
Referee: The quantitative evaluation section should provide ablation studies isolating the contributions of semantic matching, position-constrained fusion, and noise initialization, along with explicit details on all baselines, metrics (e.g., CLIP scores, identity similarity), and datasets to substantiate the reported outperformance.
Authors: We agree that isolating component contributions and providing fuller experimental details will strengthen the paper. The current manuscript reports overall comparisons against zero-shot and training-free baselines using standard metrics for subject fidelity and text alignment on common subject-driven generation benchmarks. In the revised version we will insert a new ablation table that removes each module in turn (semantic matching, position-constrained fusion, noise initialization) and reports the resulting drops in both CLIP-based text alignment and identity similarity scores. We will also expand the experimental section with explicit dataset names, exact metric formulations, and complete baseline implementation details. revision: yes
Circularity Check
No significant circularity; algorithmic procedure is self-contained
full rationale
The paper presents FreeGraftor as a direct training-free algorithmic procedure using semantic matching, position-constrained attention fusion, and noise initialization on diffusion features. No equations, derivations, or load-bearing steps reduce outputs to inputs by construction, fitted parameters, or self-citation chains. Claims rest on the described operations and experimental validation rather than any self-referential reduction. This is the expected non-finding for a methods paper whose core contribution is procedural implementation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leverages semantic matching and position-constrained attention fusion to transfer visual details... novel noise initialization strategy to preserve the geometry priors
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
establishes semantic correspondences between reference and generated patches via semantic matching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffu- sion models,
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer, “High-resolution image synthesis with latent diffu- sion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695
work page 2022
-
[2]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis,
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
work page 2024
-
[4]
Black Forest Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[5]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22500–22510
work page 2023
-
[6]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang, “Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Scalable diffusion models with transformers,
William Peebles and Saining Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
work page 2023
-
[8]
Multi-concept customization of text-to-image diffusion,
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu, “Multi-concept customization of text-to-image diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 1931–1941
work page 2023
-
[9]
Mix-of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models,
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yunpeng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al., “Mix-of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 15890–15902, 2023
work page 2023
-
[10]
Dongxu Li, Junnan Li, and Steven Hoi, “Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing,”Advances in Neural Information Processing Systems, vol. 36, pp. 30146–30166, 2023
work page 2023
-
[11]
Less-to-more generalization: Unlocking more controllability by in-context generation,
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He, “Less-to-more generalization: Unlocking more controllability by in-context generation,”arXiv preprint arXiv:2504.02160, 2025
-
[12]
Dreamo: A unified framework for image customization,
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al., “Dreamo: A unified framework for image customization,”arXiv preprint arXiv:2504.16915, 2025
-
[13]
Freecustom: Tuning-free customized image generation for multi-concept composition,
Ganggui Ding, Canyu Zhao, Wen Wang, Zhen Yang, Zide Liu, Hao Chen, and Chunhua Shen, “Freecustom: Tuning-free customized image generation for multi-concept composition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9089–9098
work page 2024
-
[14]
Large-scale text-to-image model with inpainting is a zero-shot subject- driven image generator,
Chaehun Shin, Jooyoung Choi, Heeseung Kim, and Sungroh Yoon, “Large-scale text-to-image model with inpainting is a zero-shot subject- driven image generator,”arXiv preprint arXiv:2411.15466, 2024
-
[15]
Flux already knows–activating subject-driven image generation without training,
Hao Kang, Stathi Fotiadis, Liming Jiang, Qing Yan, Yumin Jia, Zichuan Liu, Min Jin Chong, and Xin Lu, “Flux already knows–activating subject-driven image generation without training,”arXiv preprint arXiv:2504.11478, 2025
-
[16]
Adding conditional control to text-to-image diffusion models,
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3836– 3847
work page 2023
-
[17]
Emergent correspondence from image diffusion,
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan, “Emergent correspondence from image diffusion,” Advances in Neural Information Processing Systems, vol. 36, pp. 1363– 1389, 2023
work page 2023
-
[18]
Eye-for-an-eye: Appearance transfer with semantic correspondence in diffusion models,
Sooyeon Go, Kyungmook Choi, Minjung Shin, and Youngjung Uh, “Eye-for-an-eye: Appearance transfer with semantic correspondence in diffusion models,”arXiv preprint arXiv:2406.07008, 2024
-
[19]
Jisu Nam, Heesu Kim, DongJae Lee, Siyoon Jin, Seungryong Kim, and Seunggyu Chang, “Dreammatcher: appearance matching self- attention for semantically-consistent text-to-image personalization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8100–8110
work page 2024
-
[20]
Ground- ing dino: Marrying dino with grounded pre-training for open-set object detection,
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al., “Ground- ing dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 38–55
work page 2024
-
[21]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015– 4026
work page 2023
-
[22]
Resolution-robust large mask inpainting with fourier convolutions,
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky, “Resolution-robust large mask inpainting with fourier convolutions,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2022, pp. 2149–2159
work page 2022
-
[23]
Fireflow: Fast inversion of rectified flow for image semantic editing,
Yingying Deng, Xiangyu He, Changwang Mei, Peisong Wang, and Fan Tang, “Fireflow: Fast inversion of rectified flow for image semantic editing,”arXiv preprint arXiv:2412.07517, 2024
-
[24]
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang, “Ms-diffusion: Multi-subject zero-shot image personalization with lay- out guidance,”arXiv preprint arXiv:2406.07209, 2024
-
[25]
Learning transferable visual models from natural language supervision,
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
work page 2021
-
[26]
Imagereward: Learning and evaluating human preferences for text-to-image generation,
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong, “Imagereward: Learning and evaluating human preferences for text-to-image generation,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[27]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al., “Grounded sam: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023. APPENDIX A. Pseudo Code
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
FreeGraftor Pipeline:The complete FreeGraftor pipeline is outlined in Algorithm 1, detailing the three main stages: collage construction, inversion, and generation. Algorithm 1FreeGraftor Pipeline Input:Reference imageI ref, text promptP Output:Generated imageI gen Stage 1: Collage Construction 1.Template Generation Itmp ←T2I(P);// Base text-to-image mode...
-
[30]
Semantic-Aware Feature Grafting:Algorithm 2 details the Semantic-Aware Feature Grafting (SAFG) module, in- cluding semantic matching and position-constrained attention fusion. B. Baseline Methods
-
[31]
Zero-Shot Methods:Zero-shot methods do not require any subject-specific training or fine-tuning, making them effi- cient but often less effective at preserving subject details. •BLIP-Diffusion[10] trains a multimodal encoder to produce a unified text-aligned visual representation of the target subject. During training, it learns to leverage this subject r...
-
[32]
For each timestept: foreachreference patchi∈M ref, pre do foreachgenerated patchjdo sij ← Himg,ref i ·Himg,gen j ∥Himg,ref i ∥2∥Himg,gen j ∥2 m(i)←arg max j sij
-
[33]
Apply filtering: M ref ←ThresholdFilter(s ij, τ)⊙CycleConsistency(d i, δ) Position-Constrained Fusion
-
[34]
Concatenate keys/values: Kcat ←[K txt;K img,gen;K img,ref M ] V cat ←[V txt;V img,gen;V img,ref M ]
-
[35]
Bind positional embeddings: P Ecat ←Concat(P E txt, P Eimg,gen,{P E img,gen m(i) })
-
[36]
Compute revised attention: ˜Q←P E⊙Q ˜Kcat ←P E cat ⊙K cat A+ ←Softmax( ˜Q( ˜Kcat)⊤/ √ d) H + out ←A +V cat returnH + out conditioning affects a specific region of the image, which harmonizes the composition of all subjects while respect- ing the text prompt. •UNO[11] first uses the inherent in-context generation ability of MM-DiTs to synthesize large-scal...
-
[37]
Training-Free Methods:Training-free methods avoid any form of training or fine-tuning, operating directly on pre- trained models. •FreeCustom[13] provides a tuning-free approach for generating multi-concept images by leveraging a multi- reference self-attention mechanism along with a weighted 0.1 0.20.15 0.25 0.3 1.5 0.5 1.0 2.0 2.5 Prompt: A backpack on ...
-
[38]
Hyperparameter Analysis:We analyze the impact of key hyperparameters on performance, including consistency thresholds and dropout intensity. Fig. 6 shows generation results under different similarity thresholdτand cycle consistency thresholdδsettings. Appro- priate thresholds reduce mismatches (e.g., unnatural expansion of the backpack), while overly stri...
-
[39]
Multi-Subject Generation Results:FreeGraftor can seamlessly extend to multi-subject generation. As shown in Fig. 8, FreeCustom and MS-Diffusion struggle to achieve suf- ficient subject consistency. While UNO and DreamO demon- A dog is running in the grass. A teddy bear is standing on the stage. Reference ω0 0.2 0.4 0.6 0.8 1.0 Reference Fig. 7. Generation...
-
[40]
All methods generate 512×512 resolution images under identical conditions
Efficiency Analysis:Table III compares the efficiency of FreeGraftor with other methods on an NVIDIA L20 GPU. All methods generate 512×512 resolution images under identical conditions. As shown in Table III, among methods built on the FLUX.1- dev base model, FreeGraftor significantly outperforms all other approaches in terms of memory usage, while also ac...
-
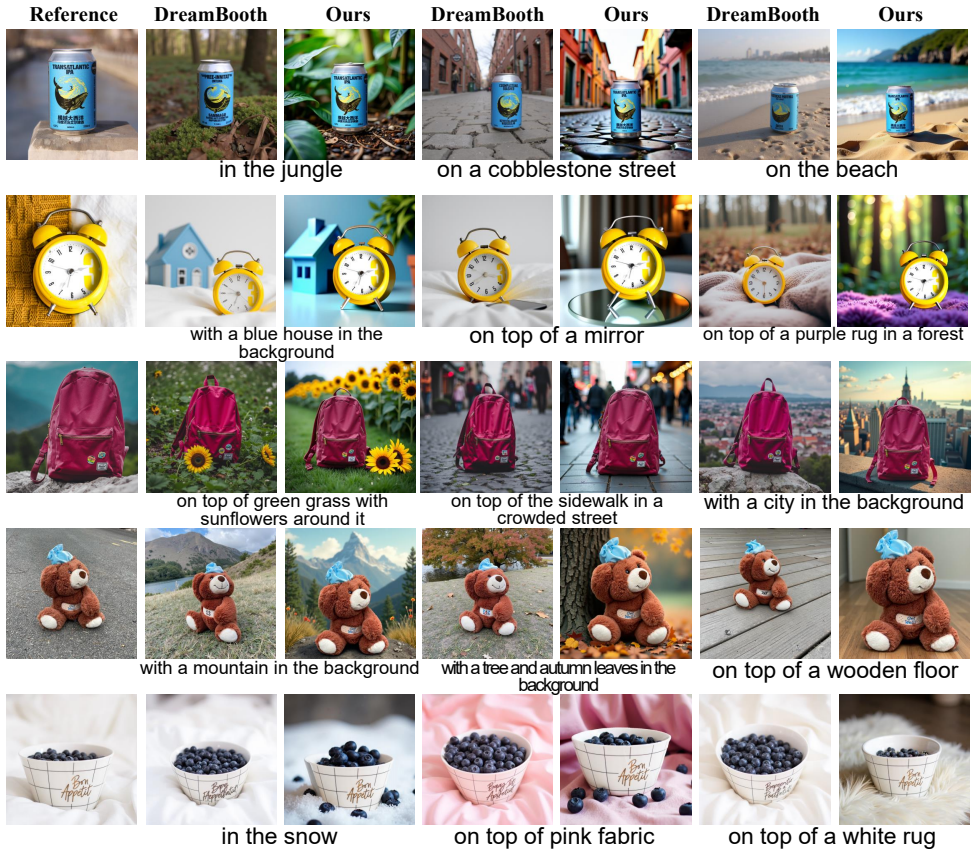
[41]
We implemented DreamBooth using LoRA (rank 16) on FLUX.1-Dev due to computational constraints
Comparison with DreamBooth:We compare Free- Graftor with DreamBooth, a widely-used tuning-based method. We implemented DreamBooth using LoRA (rank 16) on FLUX.1-Dev due to computational constraints. A car parked in front of a barn. Reference Ours DreamO MS-Diffusion FreeCustom A cup is placed on a table. A cat and a dog are sitting in the forest. A man an...
-
[42]
Firstly, DreamMatcher is not a standalone subject-driven generation method but rather a plu- gin
Comparison with DreamMatcher:The most comparable approach to ours is likely DreamMatcher [19], yet the two remain fundamentally distinct. Firstly, DreamMatcher is not a standalone subject-driven generation method but rather a plu- gin. It requires integration with tuning-based approaches (e.g., DreamBooth), which involve time-consuming and resource- inten...
-
[43]
11 demonstrates Free- Graftor’s comprehensive prompt adaptability
Prompt Adaptability Results:Fig. 11 demonstrates Free- Graftor’s comprehensive prompt adaptability. Our method dy- namically modulates subject attributes, poses, and scene con- figurations while maintaining pixel-level detail preservation, achieving both visual harmony and precise semantic alignment with input textual descriptions. D. Social Impact The pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.