Compass: SLO-aware Query Planner for Compound AI Serving at Scale
Pith reviewed 2026-05-22 19:09 UTC · model grok-4.3
The pith
Compass decomposes multi-SLO planning for compound AI systems into tractable subproblems while preserving global decision quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
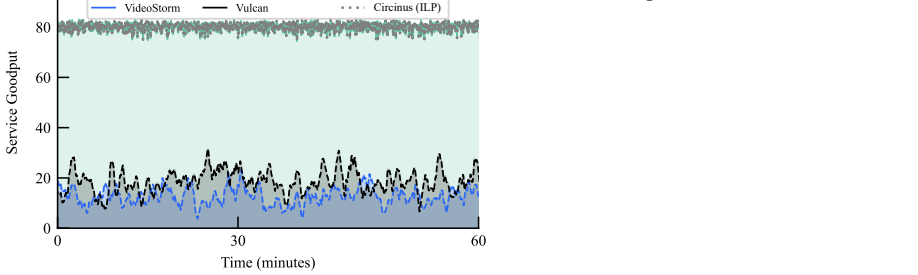
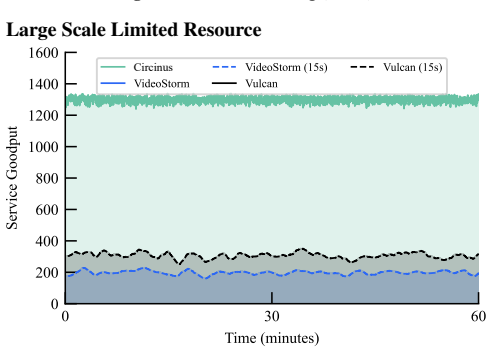
Compass is the first SLO-aware query planner that optimizes large-scale compound AI workloads across diverse deployment spaces. It decomposes the many-query, multi-SLO planning problem into tractable subproblems while preserving global decision quality, exploits plan similarities within and across queries to reduce search steps, improves per-step efficiency with selective profiling for high-fidelity estimates, and applies query-plan bipartite matching at runtime to maximize SLO goodput under resource contentions.
What carries the argument
Decomposition of the many-query multi-SLO planning problem into subproblems that exploit plan similarities, paired with selective plan profiling and runtime bipartite matching.
Load-bearing premise
Decomposing the many-query multi-SLO planning problem into tractable subproblems while exploiting plan similarities preserves global decision quality.
What would settle it
A deployment trace with heterogeneous device speeds and hundreds of concurrent queries where measured goodput stays within 10 percent of a baseline planner or planning latency exceeds a few seconds.
Figures
















read the original abstract
The rise of compound AI serving that integrates multiple operators in a pipeline enables end-user applications such as generative AI-powered meeting companions, autonomous driving, and immersive gaming. These workloads span diverse deployment spaces, from cloud-only queries to edge-assisted ones across infrastructure tiers, often including both within an application. Achieving high service goodput -- i.e., meeting service level objectives (SLOs) for pipeline latency, accuracy, and costs -- requires joint planning of operators' placement, configuration, and resource allocation. However, diverse SLOs, varying runtime environments (e.g., heterogeneous device speeds), and a large volume of queries competing for shared infrastructure explode the planning space, making real-time serving and cost-efficient deployment intractable with existing advances. This paper presents Compass, the first SLO-aware query planner that optimizes large-scale compound AI workloads across diverse deployment spaces. Compass decomposes the many-query, multi-SLO planning problem into tractable subproblems while preserving global decision quality, exploiting plan similarities within and across queries to slash the search steps. It further improves per-step efficiency with a plan profiler that performs selective profiling to achieve high-fidelity performance estimates at a fraction of the profiling cost. At runtime, Compass performs query-plan bipartite matching to maximize SLO goodput under resource contentions. Real-world evaluations show that Compass improves service goodput by 2.4--5.1x, reduces deployment costs by 3.8--4.5x, and accelerates planning by 4.2--10.5x, achieving service responsiveness within seconds and near-optimal decision quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Compass, the first SLO-aware query planner for large-scale compound AI workloads spanning cloud and edge deployments. It decomposes the many-query multi-SLO planning problem into tractable subproblems, exploits plan similarities within and across queries to reduce search steps, introduces a selective plan profiler for efficient performance estimates, and uses query-plan bipartite matching at runtime to maximize SLO goodput under contention. Real-world evaluations report 2.4--5.1x higher service goodput, 3.8--4.5x lower deployment costs, and 4.2--10.5x faster planning, with responsiveness in seconds and near-optimal decision quality.
Significance. If the decomposition and similarity exploitation indeed preserve near-optimal global decisions, the work would be significant for enabling practical, real-time serving of compound AI pipelines with heterogeneous SLOs on shared infrastructure. The reported empirical gains are substantial and directly relevant to deployment challenges in generative AI and edge-assisted applications; the absence of machine-checked proofs or parameter-free derivations is offset by the concrete system-level evaluation focus.
major comments (1)
- [Abstract] Abstract (Compass approach paragraph): the central claim that 'decomposes the many-query, multi-SLO planning problem into tractable subproblems while preserving global decision quality' lacks approximation bounds, worst-case analysis, or any small-scale comparison against an exact solver such as ILP or exhaustive enumeration. This is load-bearing for the 2.4--5.1x goodput and near-optimal quality assertions, because similarity-based pruning could discard cross-query allocations that only appear optimal at the global level under contention.
minor comments (1)
- [Abstract] The abstract refers to 'real-world evaluations' and 'near-optimal decision quality' without specifying workload characteristics, baseline systems, or statistical significance tests; these details should be expanded in the evaluation section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical significance of Compass for compound AI serving. We address the major comment below and will revise the manuscript to strengthen the supporting evidence for our central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (Compass approach paragraph): the central claim that 'decomposes the many-query, multi-SLO planning problem into tractable subproblems while preserving global decision quality' lacks approximation bounds, worst-case analysis, or any small-scale comparison against an exact solver such as ILP or exhaustive enumeration. This is load-bearing for the 2.4--5.1x goodput and near-optimal quality assertions, because similarity-based pruning could discard cross-query allocations that only appear optimal at the global level under contention.
Authors: We thank the referee for identifying this gap in the presentation of our claims. Compass decomposes the joint planning problem by first generating candidate plans per query (with intra- and inter-query similarity pruning to reduce the search space) and then resolving resource contention via bipartite matching at runtime. The matching step explicitly accounts for cross-query interactions and contention, which is how global quality is intended to be preserved. We acknowledge that the manuscript currently lacks formal approximation bounds or worst-case analysis, which is a limitation given the NP-hard multi-objective nature of the problem. However, the evaluation sections already compare Compass against strong baselines and report near-optimal decision quality under the tested workloads. To directly address the referee's concern, we will add a new small-scale experiment in the revised manuscript that solves an ILP formulation (using a standard solver) on instances with 5-10 queries where exact solutions remain tractable. This will quantify the optimality gap introduced by decomposition and pruning. We will also update the abstract to reference these results. On the specific worry about pruning discarding globally optimal allocations, the similarity metric only removes plans that are strictly dominated across all SLO dimensions, and the runtime matching re-optimizes assignments; we will clarify this mechanism and its safeguards in the revision. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents Compass as an algorithmic query planner whose core claims rest on a decomposition strategy and plan-similarity exploitation, with performance gains (goodput, cost, planning time) demonstrated exclusively through external real-world evaluations on compound AI workloads. No equations, fitted parameters, or self-citations are shown to reduce the preservation of global decision quality to a definitional tautology or input renaming; the approach is framed as a practical system whose value is measured against independent benchmarks rather than derived by construction from its own assumptions. The derivation chain therefore remains self-contained against external measurements.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diverse SLOs, heterogeneous device speeds, and high query volume render existing planning methods intractable
- domain assumption Decomposing the planning problem into tractable subproblems while exploiting plan similarities preserves global decision quality
Forward citations
Cited by 1 Pith paper
-
ForkKV: Scaling Multi-LoRA Agent Serving via Copy-on-Write Disaggregated KV Cache
ForkKV uses copy-on-write disaggregated KV cache with DualRadixTree and ResidualAttention kernels to deliver up to 3x throughput over prior multi-LoRA serving systems with negligible quality loss.
Reference graph
Works this paper leans on
-
[1]
Gemma 3. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
Tarzan: Passively-learned real-time rate control for video conferencing
Neil Agarwal, Rui Pan, Francis Y Yan, and Ravi Netravali. Tarzan: Passively-learned real-time rate control for video conferencing. arXiv preprint arXiv:2410.03339, 2024
-
[4]
Taming Throughput-Latency tradeoff in LLM inference with Sarathi-Serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming Throughput-Latency tradeoff in LLM inference with Sarathi-Serve. In OSDI, 2024
work page 2024
-
[5]
CherryPick: Adaptively unearthing the best cloud configurations for big data analytics
Omid Alipourfard, Hongqiang Harry Liu, Jianshu Chen, Shivaram Venkataraman, Minlan Yu, and Ming Zhang. CherryPick: Adaptively unearthing the best cloud configurations for big data analytics. In NSDI, 2017
work page 2017
-
[6]
Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Fara- jtabar
Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, S. Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Fara- jtabar. Llm in a flash: Efficient large language model inference with limited memory. In ACL, 2024
work page 2024
-
[7]
https://www.aboutamazon.com/news/retail/ how-to-use-amazon-rufus , 2024
Amazon’s generative ai-powered shopping assistant. https://www.aboutamazon.com/news/retail/ how-to-use-amazon-rufus , 2024
work page 2024
-
[8]
Amd reveals world’s first hardware-virtualized gpu product line. https://ir.amd.com/ news-events/press-releases/detail/663/ amd-reveals-worlds-first-hardware-virtualized-gpu-product-line
-
[9]
Chatgpt free vs paid: What’s the difference? Apidog, 2023
Apidog. Chatgpt free vs paid: What’s the difference? Apidog, 2023
work page 2023
-
[10]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems , 33:12449–12460, 2020
work page 2020
-
[11]
Jehyeon Bang, Yujeong Choi, Myeongwoo Kim, Yongdeok Kim, and Minsoo Rhu. vtrain: A simulation framework for evaluating cost-effective and compute- optimal large language model training, 2023
work page 2023
-
[12]
On la- tency of e-commerce platforms
Marcus Basalla, Johannes Schneider, Martin Luksik, Roope Jaakonmäki, and Jan V om Brocke. On la- tency of e-commerce platforms. Journal of Organiza- tional Computing and Electronic Commerce, 31(1):1– 17, 2021
work page 2021
-
[13]
Ekya: Continuous learning of video analytics models on edge compute servers
Romil Bhardwaj, Zhengxu Xia, Ganesh Anantha- narayanan, Junchen Jiang, Yuanchao Shu, Nikolaos Karianakis, Kevin Hsieh, Paramvir Bahl, and Ion Sto- ica. Ekya: Continuous learning of video analytics models on edge compute servers. In 19th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 22), pages 119–135, 2022
work page 2022
-
[14]
Recall: Empowering mul- timodal embedding for edge devices
Dongqi Cai, Shangguang Wang, Chen Peng, Zeling Zhang, and Mengwei Xu. Recall: Empowering mul- timodal embedding for edge devices. In arXiv: 2409.15342, 2024
-
[15]
https://openai.com/index/ chatgpt-can-now-see-hear-and-speak/
Chatgpt can now see, hear, and speak. https://openai.com/index/ chatgpt-can-now-see-hear-and-speak/
-
[16]
Internvl: Scaling up vi- sion foundation models and aligning for generic visual- linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vi- sion foundation models and aligning for generic visual- linguistic tasks. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[17]
30+ deepseek statistics: How this ai model is changing the game
Cropink. 30+ deepseek statistics: How this ai model is changing the game. Cropink, 2025
work page 2025
-
[18]
https://paperswithcode.com/ dataset/dancetrack, 2020
Dancetrack. https://paperswithcode.com/ dataset/dancetrack, 2020
work page 2020
-
[19]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek. Deepseek-coder: When the large language model meets programming – the rise of code intelli- gence. arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Llm.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale. In NeurIPS, 2022
work page 2022
-
[21]
Ds-1000: A natural and reliable bench- mark for data science code generation
DS-1000. Ds-1000: A natural and reliable bench- mark for data science code generation. arXiv preprint arXiv:2211.11501, 2022
-
[22]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Matthew W. G. Dye, Shawn C. Green, and Daphné Bavelier. Increasing speed of processing with action video games. Current Directions in Psychological Science, 2009
work page 2009
-
[24]
https: //huggingface.co/datasets/google/fleurs, 2022
Flores machine translation benchmark. https: //huggingface.co/datasets/google/fleurs, 2022
work page 2022
-
[25]
Jacob R. Gardner, Matt J. Kusner, Zhixiang (Eddie) Xu, Kilian Q. Weinberger, and John P. Cunningham. Bayesian optimization with inequality constraints. In ICML, 2014
work page 2014
-
[26]
The evolution of play: From live to living games. https://cloud. google.com/blog/products/gaming/ generative-ai-fuels-next-gen-living-games , 2024
work page 2024
-
[27]
Iot platform product architecture on google cloud. https://cloud.google. com/architecture/connected-devices/ iot-platform-product-architecture
-
[28]
Google cloud: Gpu pricing. https://cloud.google. com/compute/gpus-pricing?hl=en
-
[29]
https://cloud.google.com/ gemini-api/pricing
Gemini api pricing. https://cloud.google.com/ gemini-api/pricing
-
[30]
https://deepmind.google/discover/blog/ genie-2-a-large-scale-foundation-world-model/ , 2024
Genie 2: A large-scale foundation world model. https://deepmind.google/discover/blog/ genie-2-a-large-scale-foundation-world-model/ , 2024
work page 2024
-
[31]
https://spritea.github.io/ GMOT40/, 2021
Gmot-40(jì mò-40). https://spritea.github.io/ GMOT40/, 2021
work page 2021
-
[32]
W. S. Gosset. The probable error of a mean. Biometrika, 6(1):1–25, 1908
work page 1908
-
[33]
gRPC: A High Performance, Open Source Universal RPC Framework
gRPC Authors. gRPC: A High Performance, Open Source Universal RPC Framework. https://grpc. io/
-
[34]
Fila: Online audit- ing of machine learning model accuracy under finite labelling budget
Naiqing Guan and Nick Koudas. Fila: Online audit- ing of machine learning model accuracy under finite labelling budget. In SIGMOD, 2022
work page 2022
-
[35]
Serving DNNs like clockwork: Performance predictability from the bottom up
Arpan Gujarati, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. Serving DNNs like clockwork: Performance predictability from the bottom up. In OSDI, 2020
work page 2020
-
[36]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
work page 2015
-
[37]
An efficient bandit algorithm for realtime multivariate optimization
Daniel N Hill, Houssam Nassif, Yi Liu, Anand Iyer, and SVN Vishwanathan. An efficient bandit algorithm for realtime multivariate optimization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1813– 1821, 2017
work page 2017
-
[38]
Honeywell Forge: Enterprise Performance Management for Industrials
Honeywell. Honeywell Forge: Enterprise Performance Management for Industrials. https://www.honeywell.com/us/en/solutions/ honeywell-forge, 2024
work page 2024
-
[39]
Kevin Hsieh, Ganesh Ananthanarayanan, Peter Bodik, Shivaram Venkataraman, Paramvir Bahl, Matthai Phili- pose, Phillip B. Gibbons, and Onur Mutlu. Focus: Querying large video datasets with low latency and low cost. In OSDI, 2018
work page 2018
-
[40]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Ab- delrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021
work page 2021
-
[41]
Multimodal pretraining for dense video captioning
Gabriel Huang, Bo Pang, Zhenhai Zhu, Clara Rivera, and Radu Soricut. Multimodal pretraining for dense video captioning. In AACL-IJCNLP 2020, 2020
work page 2020
-
[42]
Evaluating Large Language Models Trained on Code
HumanEval. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Chatgpt facts and statistics you need to know in 2025
Invgate. Chatgpt facts and statistics you need to know in 2025. Invgate, 2025
work page 2025
-
[44]
Chameleon: scalable adaptation of video analytics
Junchen Jiang, Ganesh Ananthanarayanan, Peter Bodik, Siddhartha Sen, and Ion Stoica. Chameleon: scalable adaptation of video analytics. In Proceedings of the 2018 conference of the ACM special interest group on data communication, pages 253–266, 2018
work page 2018
-
[45]
Kubernetes: Production-grade container scheduling and management. https://kubernetes.io/
-
[46]
Advances and open problems in federated learning,
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cor- mode, Rachel Cummings, Rafael G. L. DOliveira, Hubert Eichner, Salim El Rouayheb, David Evans, Josh Gardner, Zachary Garrett, Adrià Gascón, Badih Ghazi, Phillip B. Gibbons, Marco Gruteser, Zaid Har- chaoui, ...
-
[47]
{RECL}: Re- sponsive {Resource-Efficient} continuous learning for video analytics
Mehrdad Khani, Ganesh Ananthanarayanan, Kevin Hsieh, Junchen Jiang, Ravi Netravali, Yuanchao Shu, Mohammad Alizadeh, and Victor Bahl. {RECL}: Re- sponsive {Resource-Efficient} continuous learning for video analytics. In 20th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 23), pages 917–932, 2023
work page 2023
-
[48]
Selecta: heterogeneous cloud storage configuration for data analytics
Ana Klimovic, Heiner Litz, and Christos Kozyrakis. Selecta: heterogeneous cloud storage configuration for data analytics. In ATC, 2018
work page 2018
-
[49]
Cascadeserve: Unlock- ing model cascades for inference serving, 2024
Ferdi Kossmann, Ziniu Wu, Alex Turk, Nesime Tatbul, Lei Cao, and Samuel Madden. Cascadeserve: Unlock- ing model cascades for inference serving, 2024
work page 2024
-
[50]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[51]
Gon- zalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gon- zalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In SOSP, 2023
work page 2023
-
[52]
Singapuram, Jiachen Liu, Xiangfeng Zhu, Harsha V
Fan Lai, Yinwei Dai, Sanjay S. Singapuram, Jiachen Liu, Xiangfeng Zhu, Harsha V . Madhyastha, and Mosharaf Chowdhury. FedScale: Benchmarking model and system performance of federated learning at scale. In International Conference on Machine Learn- ing (ICML), 2022
work page 2022
-
[53]
Madhyastha, and Mosharaf Chowdhury
Fan Lai, Xiangfeng Zhu, Harsha V . Madhyastha, and Mosharaf Chowdhury. Oort: Efficient federated learn- ing via guided participant selection. In OSDI, 2021
work page 2021
- [54]
-
[55]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Sto- ica. AlpaServe: Statistical multiplexing with model parallelism for deep learning serving. In OSDI, 2023
work page 2023
-
[56]
https://huggingface.co/datasets/ openslr/librispeech_asr, 2021
Librispeech. https://huggingface.co/datasets/ openslr/librispeech_asr, 2021
work page 2021
-
[57]
Awq: Activation-aware weight quantization for llm compres- sion and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compres- sion and acceleration. In MLSys, 2024
work page 2024
-
[58]
Andes: Defining and enhancing quality-of-experience in llm- based text streaming services
Jiachen Liu, Zhiyu Wu, Jae-Won Chung, Fan Lai, Myungjin Lee, and Mosharaf Chowdhury. Andes: Defining and enhancing quality-of-experience in llm- based text streaming services. In arXiv: 2404.16283, 2024
-
[59]
https://huggingface.co/ datasets/LIUM/tedlium, 2022
Ted-lium corpus. https://huggingface.co/ datasets/LIUM/tedlium, 2022
work page 2022
-
[60]
Chengfei Lv, Chaoyue Niu, Renjie Gu, Xiaotang Jiang, Zhaode Wang, Bin Liu, Ziqi Wu, Qiulin Yao, Con- gyu Huang, Panos Huang, Tao Huang, Hui Shu, Jinde Song, Bin Zou, Peng Lan, Guohuan Xu, Fei Wu, Shao- jie Tang, Fan Wu, and Guihai Chen. Walle: An End- to-End, General-Purpose, and Large-Scale production system for Device-Cloud collaborative machine learn- ...
work page 2022
-
[61]
Program Synthesis with Large Language Models
MBPP. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[62]
Helix: Distributed serving of large language models via max-flow on heterogeneous gpus
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Distributed serving of large language models via max-flow on heterogeneous gpus. In ASPLOS, 2025
work page 2025
-
[63]
https://huggingface.co/datasets/ PolyAI/minds14, 2022
Minds-14. https://huggingface.co/datasets/ PolyAI/minds14, 2022
work page 2022
-
[64]
https://www.measurementlab.net/ tests/mobiperf/
Mobiperf: Measuring network performance on mobile platforms. https://www.measurementlab.net/ tests/mobiperf/
-
[65]
https://motchallenge.net/ data/MOT17/, 2017
Mot17 challenge. https://motchallenge.net/ data/MOT17/, 2017
work page 2017
-
[66]
https://motchallenge.net/ data/MOT20/, 2020
Mot20 challenge. https://motchallenge.net/ data/MOT20/, 2020
work page 2020
-
[67]
https://www.microsoft.com/en-us/research/ project/live-video-analytics/, 2020
Microsoft rocket for live video analytics. https://www.microsoft.com/en-us/research/ project/live-video-analytics/, 2020
work page 2020
-
[68]
Next-qa: Next phase of question-answering to explain- ing temporal actions. https://doc-doc.github. io/docs/nextqa.html, 2021
work page 2021
-
[69]
Nvidia multi-process service. https://docs. nvidia.com/deploy/mps/index.html#/
-
[70]
https://openai.com/index/ introducing-our-next-generation-audio-models/
Openai: Introducing next-generation audio mod- els in the api. https://openai.com/index/ introducing-our-next-generation-audio-models/
-
[71]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023
work page 2023
-
[72]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[73]
Astra-sim: Enabling sw/hw co-design exploration for distributed dl training plat- forms
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srini- vasan, and Tushar Krishna. Astra-sim: Enabling sw/hw co-design exploration for distributed dl training plat- forms. In ISPASS, 2020
work page 2020
-
[74]
You only look once: Unified, real-time ob- ject detection
J Redmon. You only look once: Unified, real-time ob- ject detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016
work page 2016
-
[75]
Yadwadkar, and Christos Kozyrakis
Francisco Romero, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. INFaaS: Automated model-less inference serving. In ATC, 2021
work page 2021
-
[76]
Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E. Gonzalez, and Ion Stoica. Fairness in serving large language models. In OSDI, 2024
work page 2024
-
[77]
Practical bayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25, 2012
work page 2012
-
[78]
Mostofa Ali Patwary, Prabhat, and Ryan P
Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat, and Ryan P. Adams. Scalable bayesian optimization using deep neural net- works. In ICML, 2015
work page 2015
-
[79]
Powerinfer: Fast large language model serving with a consumer-grade gpu
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. Powerinfer: Fast large language model serving with a consumer-grade gpu. In SOSP, 2024
work page 2024
-
[80]
Sportsmot: A large multi-object tracking dataset in multiple sports scenes. https://paperswithcode. com/dataset/sportsmot, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.