Fine-Grained Fusion: The Missing Piece in Area-Efficient State Space Model Acceleration
Pith reviewed 2026-05-22 19:07 UTC · model grok-4.3
The pith
A fusion-aware hardware architecture for State Space Models achieves 1.78 times the performance of the MARCA accelerator within the same area budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
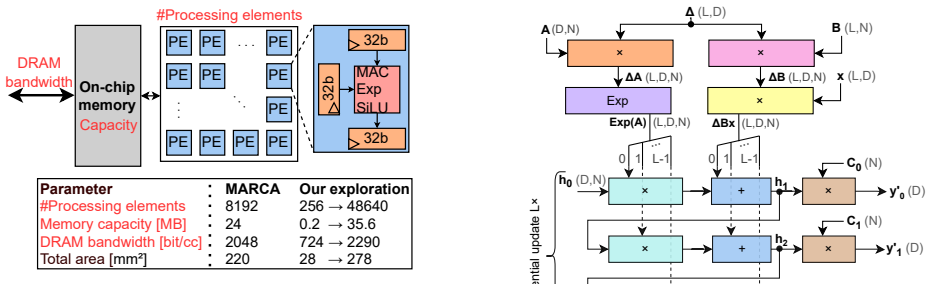
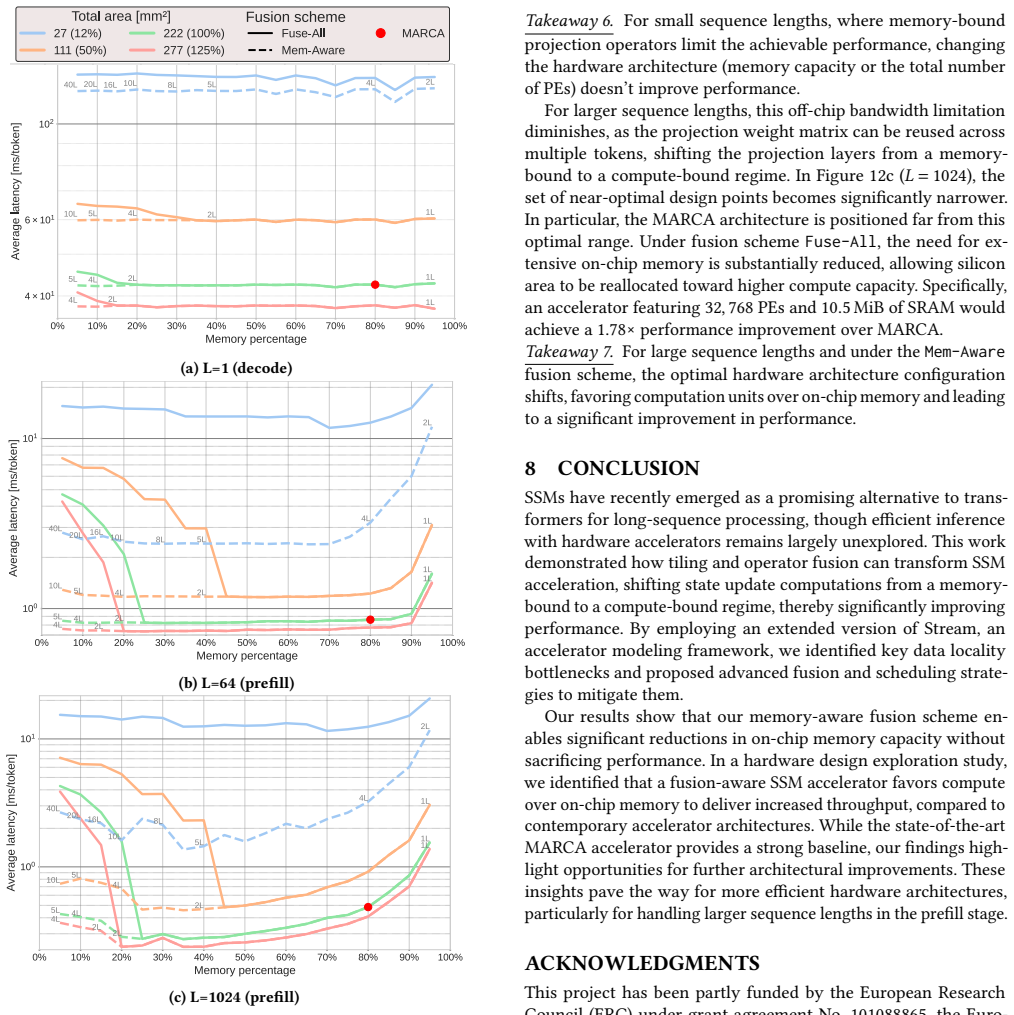
The paper claims that fine-grained operator fusion and adaptive memory-aware scheduling improve data locality enough to produce speedups of up to 4.8x over unfused SSM execution and reduce on-chip memory needs by an order of magnitude. When these schedules are supported by a tailored hardware architecture, the resulting design achieves 1.78x higher performance than the state-of-the-art MARCA accelerator inside the same area budget.
What carries the argument
Fine-grained operator fusion schedules together with adaptive memory-aware fusion, explored through design space trade-offs in an extended Stream modeling framework.
If this is right
- SSM accelerators can reach up to 4.8x speedup over unfused execution through improved data locality.
- On-chip memory requirements drop by an order of magnitude with no performance penalty.
- A fusion-aware hardware architecture outperforms the MARCA accelerator by 1.78x at identical area cost.
- Operator fusion becomes a necessary ingredient in the design of next-generation SSM accelerators.
Where Pith is reading between the lines
- Similar fusion schedules could reduce memory pressure in other memory-bound sequence models beyond SSMs.
- If the modeling predictions hold, the efficiency gains would appear in physical silicon prototypes of the proposed architecture.
- Future accelerator designs might embed dedicated support for fine-grained fusion to handle long-context workloads more efficiently.
Load-bearing premise
The extended Stream modeling framework produces performance and area estimates that accurately reflect real silicon behavior for the proposed fine-grained fusion schedules and hardware configurations.
What would settle it
Fabricate a chip implementing the proposed fusion-aware architecture, measure its actual runtime and silicon area, and compare those measurements to the framework's predictions.
Figures






read the original abstract
State Space Models (SSMs) offer a promising alternative to transformers for long-sequence processing. However, their efficiency remains hindered by memory-bound operations, particularly in the prefill stage. While MARCA, a recent first effort to accelerate SSMs through a dedicated hardware accelerator, achieves great speedup over high-end GPUs, an analysis into the broader accelerator design space is lacking. This work systematically analyzes SSM acceleration opportunities both from the scheduling perspective through fine-grained operator fusion and the hardware perspective through design space exploration, using an extended version of the Stream modeling framework. Our results demonstrate that the improved data locality stemming from our optimized fusion and scheduling strategy enables a speedup of up to 4.8x over unfused execution, while our adaptive memory-aware fusion approach reduces on-chip memory requirements by an order of magnitude without sacrificing performance. We further explore accelerator design trade-offs, showing that a fusion-aware hardware architecture can achieve 1.78x higher performance than the state-of-the-art MARCA accelerator, within the same area budget. These results establish operator fusion as a key enabler for next-generation SSM accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically explores SSM acceleration opportunities through fine-grained operator fusion and scheduling, combined with hardware design-space exploration, all evaluated via an extended Stream modeling framework. It reports up to 4.8x speedup from optimized fusion over unfused baselines, an order-of-magnitude reduction in on-chip memory via adaptive memory-aware fusion without performance loss, and a fusion-aware accelerator architecture that delivers 1.78x higher performance than the prior MARCA design at identical area.
Significance. If the modeling results prove accurate, the work would usefully identify operator fusion as a key lever for area-efficient SSM hardware, providing concrete guidance on scheduling and memory trade-offs that could influence next-generation accelerators for long-sequence models. The breadth of the design-space study is a positive contribution to the cs.AR literature on emerging sequence-model hardware.
major comments (2)
- [Modeling Methodology and Evaluation sections] The 1.78x performance advantage over MARCA (same area) and the order-of-magnitude memory-reduction claim rest entirely on performance and area estimates produced by the extended Stream framework for the new fine-grained fusion schedules. The manuscript contains no cycle-accurate RTL simulation, FPGA prototype, or silicon measurement that calibrates or bounds modeling error for these schedules; if bank-conflict or reuse assumptions are optimistic, the central quantitative claims become unreliable.
- [Results and Discussion] The paper does not report sensitivity analysis or error bars on the Stream-derived speedups and area numbers when key modeling parameters (e.g., memory-bank conflict rates, fusion-control logic overhead) are varied within plausible ranges; this omission directly affects confidence in the design-space conclusions.
minor comments (2)
- [Abstract and Results] Clarify in the text whether the reported 4.8x and 1.78x figures are peak or average values across the evaluated workloads.
- [Figures] Ensure all figures comparing fusion strategies include the exact on-chip memory sizes and bandwidth assumptions used in the Stream runs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our modeling methodology. We address each point below and have made revisions to improve the clarity and robustness of our claims.
read point-by-point responses
-
Referee: [Modeling Methodology and Evaluation sections] The 1.78x performance advantage over MARCA (same area) and the order-of-magnitude memory-reduction claim rest entirely on performance and area estimates produced by the extended Stream framework for the new fine-grained fusion schedules. The manuscript contains no cycle-accurate RTL simulation, FPGA prototype, or silicon measurement that calibrates or bounds modeling error for these schedules; if bank-conflict or reuse assumptions are optimistic, the central quantitative claims become unreliable.
Authors: We agree that our quantitative results rely on the extended Stream modeling framework. This framework has been validated in previous publications against cycle-accurate simulations and real hardware for similar accelerator designs. Our extensions for fine-grained fusion include explicit modeling of data reuse, bank conflicts, and control overhead based on the operator schedules. To further bound potential modeling errors, we will add a new subsection in the Evaluation section discussing the key assumptions (e.g., bank conflict rates and reuse factors) and their justification. We will also include a limitations paragraph noting that while modeling provides valuable design-space insights, full validation would require RTL implementation. revision: partial
-
Referee: [Results and Discussion] The paper does not report sensitivity analysis or error bars on the Stream-derived speedups and area numbers when key modeling parameters (e.g., memory-bank conflict rates, fusion-control logic overhead) are varied within plausible ranges; this omission directly affects confidence in the design-space conclusions.
Authors: We acknowledge the value of sensitivity analysis for increasing confidence in the results. In the revised manuscript, we will perform and report sensitivity analysis on critical parameters including memory-bank conflict rates (varied from 0% to 30%) and fusion-control logic overhead (0% to 15% of area). We will update the relevant figures to include error bars or shaded regions representing the range of outcomes under these variations, and add discussion on how these affect the 1.78x performance advantage and memory reduction claims. revision: yes
- Conducting cycle-accurate RTL simulation or fabricating a prototype for the fusion-aware accelerator design, which is beyond the scope of this high-level modeling and design-space exploration study.
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper derives its performance claims (e.g., 1.78x speedup over MARCA within same area) and memory reductions from applying an extended Stream modeling framework to proposed fine-grained fusion schedules and hardware configurations. No equations, fitted parameters, or self-citations are shown that would make the reported speedups or area numbers reduce to the input assumptions by construction. The modeling runs provide independent estimates of data locality, bank conflicts, and reuse, and the central results do not collapse to self-definition or renaming of known patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The extended Stream modeling framework accurately captures the performance and memory behavior of fine-grained fused SSM operators on target hardware.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
using an extended version of the Stream modeling framework... adaptive memory-aware fusion approach reduces on-chip memory requirements by an order of magnitude
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a fusion-aware hardware architecture can achieve 1.78x higher performance than the state-of-the-art MARCA accelerator, within the same area budget
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Mambalaya: Einsum-Based Fusion Optimizations on State-Space Models
Mambalaya delivers 4.9x prefill and 1.9x generation speedups on Mamba layers over prior accelerators by systematically fusing inter-Einsum operations.
Reference graph
Works this paper leans on
-
[1]
Steve Dai, Hasan Genc, Rangharajan Venkatesan, and Brucek Khailany. 2023. Efficient Transformer Inference with Statically Structured Sparse Attention. In 2023 60th ACM/IEEE Design Automation Conference (DAC) . 1–6. https://doi.org/ 10.1109/DAC56929.2023.10247993
-
[2]
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, and Pavlo Molchanov. 2024. Hymba: A 10 Hybrid-head Architecture for Small Language Models. arXiv:2411.13676 (Nov. 2024). https://doi.org/10.48550/arXiv.2411.13676 arXiv:2411...
-
[3]
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Millidge. 2024. Zamba: A Compact 7B SSM Hybrid Model. arXiv:2405.16712 (May 2024). https://doi.org/10.48550/arXiv.2405. 16712 arXiv:2405.16712 [cs]
-
[4]
Albert Gu and Tri Dao. 2024. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752 (May 2024). https://doi.org/10.48550/ arXiv.2312.00752 arXiv:2312.00752 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Albert Gu, Karan Goel, and Christopher Ré. 2021. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Albert Gu, Karan Goel, and Christopher Ré. 2022. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv:2111.00396 (Aug. 2022). https: //doi.org/10.48550/arXiv.2111.00396 arXiv:2111.00396 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2111.00396 2022
-
[7]
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. 2021. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems 34 (2021), 572–585
work page 2021
-
[8]
Tae Jun Ham, Yejin Lee, Seong Hoon Seo, Soosung Kim, Hyunji Choi, Sung Jun Jung, and Jae W. Lee. 2021. ELSA: Hardware-Software Co-design for Efficient, Lightweight Self-Attention Mechanism in Neural Networks. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) . IEEE, Valencia, Spain, 692–705. https://doi.org/10.1109/ISCA5...
-
[9]
Mark Harris, Shubhabrata Sengupta, and John D. Owens. [n. d.]. Chapter 39. Parallel Prefix Sum (Scan) with CUDA. https://developer.nvidia.com/gpugems/ gpugems3/part-vi-gpu-computing/chapter-39-parallel-prefix-sum-scan-cuda
-
[10]
Sheng-Chun Kao, Suvinay Subramanian, Gaurav Agrawal, Amir Yazdanbakhsh, and Tushar Krishna. 2023. FLAT: An Optimized Dataflow for Mitigating Attention Bottlenecks. In Proceedings of the 28th ACM International Conference on Archi- tectural Support for Programming Languages and Operating Systems, Volume 2 . ACM, Vancouver BC Canada, 295–310. https://doi.org...
-
[11]
Ben Keller, Rangharajan Venkatesan, Steve Dai, Stephen G. Tell, Brian Zimmer, William J. Dally, C. Thomas Gray, and Brucek Khailany. 2022. A 17–95.6 TOPS/W Deep Learning Inference Accelerator with Per-Vector Scaled 4-bit Quantization for Transformers in 5nm. In2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, Honolu...
work page doi:10.1109/vlsitechnologyandcir46769.2022.9830277 2022
-
[12]
Sangyeob Kim, Sangjin Kim, Wooyoung Jo, Soyeon Kim, Seongyon Hong, and Hoi-Jun Yoo. 2024. 20.5 C-Transformer: A 2.6-18.1uJ/Token Homogeneous DNN- Transformer/Spiking-Transformer Processor with Big-Little Network and Implicit Weight Generation for Large Language Models. In 2024 IEEE International Solid- State Circuits Conference (ISSCC) , Vol. 67. 368–370....
- [13]
-
[14]
Yandong Luo and Shimeng Yu. 2024. H3D-Transformer: A Heterogeneous 3D (H3D) Computing Platform for Transformer Model Acceleration on Edge Devices. ACM Transactions on Design Automation of Electronic Systems (Feb. 2024), 3649219. https://doi.org/10.1145/3649219
-
[15]
Eric Martin and Chris Cundy. 2018. Parallelizing Linear Recurrent Neural Nets Over Sequence Length. arXiv:1709.04057 [cs.NE] https://arxiv.org/abs/1709. 04057
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Odemuyiwa, Michael Pellauer, Joel S
Nandeeka Nayak, Xinrui Wu, Toluwanimi O. Odemuyiwa, Michael Pellauer, Joel S. Emer, and Christopher W. Fletcher. 2024. FuseMax: Leveraging Extended Einsums to Optimize Attention Accelerator Design. arXiv:2406.10491 [cs.AR] https://arxiv.org/abs/2406.10491
-
[17]
ONNX Community. 2024. ONNX: Open Neural Network Exchange. https: //github.com/onnx/
work page 2024
-
[18]
OpenAI. 2020. GPT-3: Language Models are Few-Shot Learners. https://arxiv. org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Yubin Qin, Yang Wang, Dazheng Deng, Xiaolong Yang, Zhiren Zhao, Yang Zhou, Yuanqi Fan, Jingchuan Wei, Tianbao Chen, Leibo Liu, Shaojun Wei, Yang Hu, and Shouyi Yin. 2024. Ayaka: A Versatile Transformer Accelerator With Low-Rank Estimation and Heterogeneous Dataflow. IEEE Journal of Solid-State Circuits (2024), 1–15. https://doi.org/10.1109/JSSC.2024.3397189
-
[20]
Yikan Qiu, Yufei Ma, Meng Wu, Yifan Jia, Xinyu Qu, Zecheng Zhou, Jincheng Lou, Tianyu Jia, Le Ye, and Ru Huang. 2024. Quartet: A 22nm 0.09mJ/lnference Digital Compute-in-Memory Versatile AI Accelerator with Heterogeneous Tensor Engines and Off-Chip-Less Dataflow. In2024 IEEE Custom Integrated Circuits Con- ference (CICC). IEEE, Denver, CO, USA, 1–2. https...
-
[21]
Arne Symons, Linyan Mei, Steven Colleman, Pouya Houshmand, Sebastian Karl, and Marian Verhelst. 2025. Stream: Design Space Exploration of Layer-Fused DNNs on Heterogeneous Dataflow Accelerators. IEEE Trans. Comput. 74, 1 (2025), 237–249. https://doi.org/10.1109/TC.2024.3477938
-
[22]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucu- rull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017)
work page 2017
-
[24]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (2009), 65–76
work page 2009
-
[25]
Shuai Yuan, Weifeng He, Zhenhua Zhu, Fangxin Liu, Zhuoran Song, Guohao Dai, Guanghui He, and Yanan Sun. 2024. HyCTor: A Hybrid CNN-Transformer Network Accelerator With Flexible Weight/Output Stationary Dataflow and Multi-Core Extension. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (2024), 1–1. https://doi.org/10.1109/TCAD....
-
[27]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. OPT: Open Pre-trained Transformer Language Models. arXiv:2205.01068 [cs.CL]...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Gamze İslamoğlu, Moritz Scherer, Gianna Paulin, Tim Fischer, Victor J. B. Jung, Angelo Garofalo, and Luca Benini. 2023. ITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers. (July 2023). arXiv:2307.03493 http://arxiv.org/abs/2307.03493 arXiv:2307.03493 [cs]. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.