Recognition: no theorem link
Mambalaya: Einsum-Based Fusion Optimizations on State-Space Models
Pith reviewed 2026-05-13 16:52 UTC · model grok-4.3
The pith
Mambalaya models Mamba as a cascade of Einsums to find fusion mappings that cut off-chip traffic and deliver 4.9x prefill speedup over MARCA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Mamba's full computational structure is captured as a cascade-of-Einsums; the extended Einsum framework then enumerates inter-Einsum fusion opportunities that reduce off-chip traffic. These fusions are realized on the Mambalaya reconfigurable accelerator, which achieves 4.9× layer speedup for prefill and 1.9× for generation versus MARCA, and up to 1.5× versus a recent fine-grained memory-aware Mamba accelerator in prefill-heavy workloads.
What carries the argument
The cascade-of-Einsums abstraction that represents Mamba's entire operator graph as a chained sequence of Einsum operations, enabling the extended Einsum framework to discover and validate cross-operator fusion mappings.
If this is right
- Mamba layers can be executed with substantially less inter-operator data movement once the identified fusions are applied.
- Reconfigurable hardware becomes a practical target for state-space models because the fusion mappings are supported by modest architectural extensions.
- Prefill-dominated inference workloads benefit most, reaching up to 1.5× improvement over existing specialized Mamba accelerators.
- The same systematic fusion search can be repeated for other state-space or hybrid recurrent models that share similar cascaded structure.
Where Pith is reading between the lines
- Designers of future accelerators for sequence models could adopt the cascade-of-Einsums view as a standard way to expose fusion opportunities across the entire layer.
- The traffic reductions may compound when Mamba is used inside larger pipelines that already fuse surrounding operators such as embeddings or output projections.
- Extending the same framework to mixed-precision or sparsity-aware Einsums could yield additional gains without changing the core fusion logic.
Load-bearing premise
The discovered fusion mappings can be realized on the Mambalaya hardware with negligible control and reconfiguration overhead while still delivering the modeled reductions in off-chip traffic.
What would settle it
Implement the Mambalaya accelerator and measure actual off-chip memory traffic volume and execution latency on representative Mamba workloads; if the measured traffic is not materially lower than the unfused baseline or the speedups fall well below 4.9× prefill, the central claim is falsified.
Figures







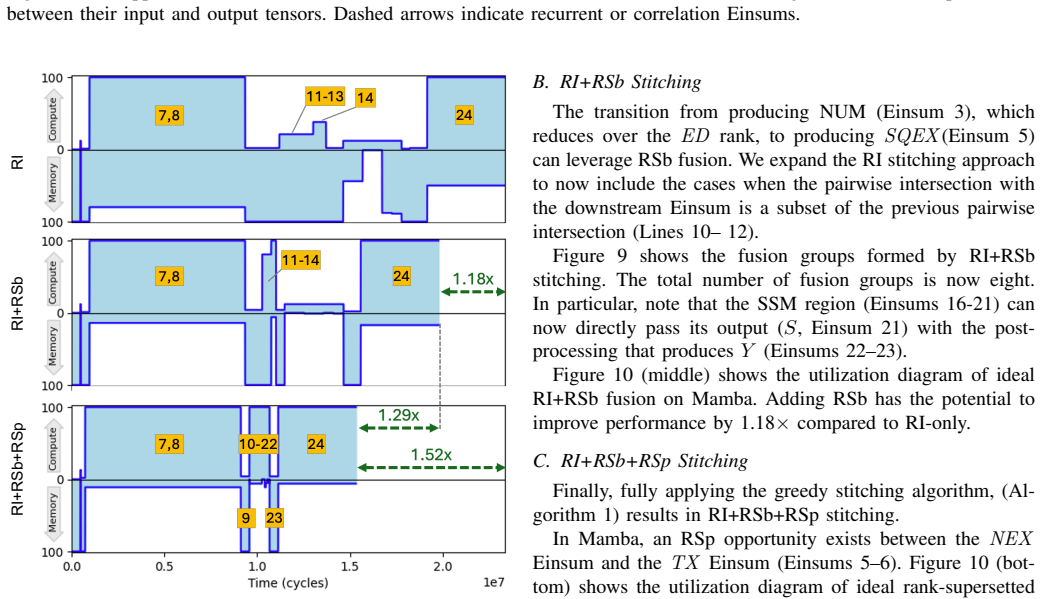


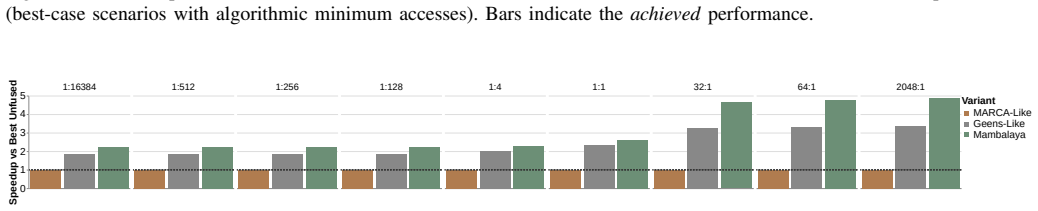
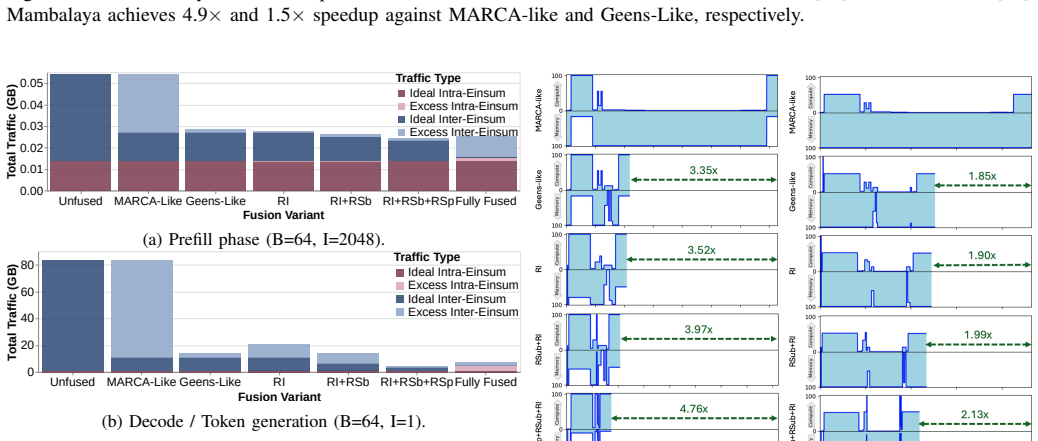
read the original abstract
Mamba is an emerging, complex workload with various short-range and long-range dependencies, nonlinearities, and elementwise computations that are unable to run at near-peak speeds on modern hardware. Specifically, Mamba's complex dependency graph makes fusion across its full operator cascade difficult, leaving substantial inter-operator memory traffic on the table. To address these challenges, we propose Mambalaya, a novel reconfigurable accelerator that leverages fusion to overcome the limitations of Mamba. We use the recently proposed cascade-of-Einsums abstraction to characterize Mamba's full computational structure, then apply the extended Einsum framework to systematically explore inter-Einsum fusion opportunities. This principled approach yields a series of fusion mappings that reduce off-chip inter-Einsum traffic. These mappings are supported by the underlying Mambalaya architecture. Mambalaya achieves a layer performance speedup of 4.9$\times$ for prefill and 1.9$\times$ for generation over MARCA. In prefill-dominated scenarios, it achieves up to 1.5$\times$ over a recent fine-grained, memory-aware fusion accelerator for Mamba.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mambalaya, a reconfigurable accelerator for Mamba state-space models. It employs the cascade-of-Einsums abstraction and an extended Einsum framework to systematically identify inter-Einsum fusion opportunities that reduce off-chip memory traffic. The architecture supports these fusions, leading to reported speedups of 4.9× in prefill and 1.9× in generation phases compared to MARCA, and up to 1.5× over a recent fine-grained fusion accelerator in prefill-dominated scenarios.
Significance. If the performance results are substantiated with detailed overhead analysis and experimental validation, this work would represent a meaningful advance in hardware acceleration for state-space models by providing a principled, Einsum-based method for operator fusion in workloads with complex dependencies. The systematic exploration of fusion mappings could influence future designs for efficient inference and training of Mamba-like models.
major comments (2)
- Abstract: The headline performance claims (4.9× prefill, 1.9× generation over MARCA) lack supporting details such as error bars, exact baseline implementations, or confirmation that reconfiguration and control overheads were included in the performance model; this is load-bearing because the speedups are attributed to traffic reductions that only materialize if these costs are negligible.
- Architecture and Evaluation sections: The description of the reconfigurable datapath must quantify bounds on crossbar/PE reconfiguration latency and ensure the control FSM does not introduce serialization that offsets the memory traffic savings from the fusion mappings identified by the extended Einsum framework.
minor comments (1)
- The abstract refers to 'prefill-dominated scenarios' without defining the workload mix, sequence lengths, or batch sizes used to obtain the 1.5× figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested clarifications and additional details.
read point-by-point responses
-
Referee: Abstract: The headline performance claims (4.9× prefill, 1.9× generation over MARCA) lack supporting details such as error bars, exact baseline implementations, or confirmation that reconfiguration and control overheads were included in the performance model; this is load-bearing because the speedups are attributed to traffic reductions that only materialize if these costs are negligible.
Authors: We agree that the abstract would be strengthened by additional context. In the revised manuscript we will update the abstract to explicitly reference the evaluation section, where error bars from repeated cycle-accurate simulations will be reported, the exact baseline configurations (including MARCA parameters and the fine-grained fusion accelerator setup) will be stated, and we will confirm that the performance model already accounts for reconfiguration and control overheads. These overheads are modeled as part of the net cycle count and do not negate the reported traffic reductions. revision: yes
-
Referee: Architecture and Evaluation sections: The description of the reconfigurable datapath must quantify bounds on crossbar/PE reconfiguration latency and ensure the control FSM does not introduce serialization that offsets the memory traffic savings from the fusion mappings identified by the extended Einsum framework.
Authors: We will expand Section 4 (Architecture) to report quantitative bounds on crossbar and PE reconfiguration latency derived from our synthesis and place-and-route results. In the revised Evaluation section we will add a dedicated analysis, including timing diagrams and per-fusion cycle breakdowns, showing that the control FSM executes in parallel with data movement and does not serialize the datapath in a manner that offsets the memory-traffic savings from the identified fusion mappings. revision: yes
Circularity Check
No significant circularity; speedups reported as modeled outcomes of external Einsum-derived mappings
full rationale
The paper characterizes Mamba via the cascade-of-Einsums abstraction, applies the extended Einsum framework to discover inter-operator fusions that reduce traffic, and then asserts that the Mambalaya reconfigurable architecture can realize those mappings. Performance numbers (4.9× prefill, 1.9× generation) are presented as results of that realization rather than as quantities fitted or defined in terms of themselves. No equation equates a claimed speedup to a fitted parameter, no prediction is statistically forced by the input data, and no uniqueness theorem or ansatz is smuggled via self-citation to close the loop. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sequence to sequence learning with neural networks,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to sequence learning with neural networks,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, Canada,
-
[2]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2014/file/5a18e133cbf9f257297f410bb7eca942-Paper.pdf
work page 2014
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS 2017. Curran Associates Inc., 2017, pp. 6000–6010. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2...
work page 2017
-
[4]
CLEX: Continuous length extrapolation for large language models,
G. Chen, X. Li, Z. Meng, S. Liang, and L. Bing, “CLEX: Continuous length extrapolation for large language models,” in 12th International Conference on Learning Representations, ser. ICLR 2024. OpenReview.net, 2024. [Online]. Available: https: //openreview.net/forum?id=wXpSidPpc5
work page 2024
-
[5]
R. Li, J. Xu, Z. Cao, H.-T. Zheng, and H.-G. Kim, “Extending context window in large language models with segmented base adjustment for rotary position embeddings,”Applied Sciences, vol. 14, no. 7, 2024. doi: 10.3390/app14073076
-
[6]
PaLM: scaling language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y . Tay, N. Shazeer, V . Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev,...
work page 2023
-
[7]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst Conference on Language Modeling, ser. COLM 2024, Oct. 2024. [Online]. Available: https: //openreview.net/forum?id=tEYskw1VY2
work page 2024
-
[8]
Samba: Simple hybrid state space models for efficient unlimited context language modeling,
L. Ren, Y . Liu, Y . Lu, Y . Shen, C. Liang, and W. Chen, “Samba: Simple hybrid state space models for efficient unlimited context language modeling,” in13th International Conference on Learning Representations, ser. ICLR 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=bIlnpVM4bc
work page 2025
-
[9]
Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models
A. Blakeman, A. Basant, A. Khattar, A. Renduchintala, A. Bercovich, A. Ficek, A. Bjorlin, A. Taghibakhshi, A. S. Deshmukh, A. S. Maha- baleshwarkar, A. Tao, A. Shors, A. Aithal, A. Poojary, A. Dattagupta, B. Buddharaju, B. Chen, B. Ginsburg, B. Wang, B. Norick, B. Butter- field, B. Catanzaro, C. del Mundo, C. Dong, C. Harvey, C. Parisien, D. Su, D. Korzek...
-
[10]
Codestral Mamba: A Mamba2 language model specialized in code generation,
Mistral AI, “Codestral Mamba: A Mamba2 language model specialized in code generation,” https://mistral.ai/news/codestral-mamba, 2024
work page 2024
-
[11]
Bamba: Inference-efficient hybrid Mamba2 model,
L. Chu, D. Kumari, T. Dao, A. Gu, R. Ganti, D. Agrawal, M. Srivatsa, D. Wertheimer, Y . C. F. Lim, A. Viros, N. Gonzalez, T. HoangTrong, O. Arviv, Y . Perlitz, M. Shmueli, H. Shen, M. Zhang, G. Goodhart, N. Wang, N. Hill, J. Rosenkranz, C.-C. Liu, A. Hoque, C.-C. Yang, S. Sharma, A. Uong, J. Gala, S. Zawad, and R. Gordon, “Bamba: Inference-efficient hybri...
work page 2024
-
[12]
The Mamba in the Llama: Distilling and accelerating hybrid models,
J. Wang, D. Paliotta, A. May, A. M. Rush, and T. Dao, “The Mamba in the Llama: Distilling and accelerating hybrid models,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NeurIPS 2024. Curran Associates Inc., 2024. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2024/hash/ 723933067ad...
work page 2024
-
[13]
Jamba: A Hybrid Transformer-Mamba Language Model
O. Lieber, B. Lenz, H. Bata, G. Cohen, J. Osin, I. Dalmedigos, E. Safahi, S. Meirom, Y . Belinkov, S. Shalev-Shwartz, O. Abend, R. Alon, T. Asida, A. Bergman, R. Glozman, M. Gokhman, A. Manevich, N. Ratner, N. Rozen, E. Shwartz, M. Zusman, and Y . Shoham, “Jamba: A hybrid transformer-Mamba language model,”CoRR, no. 2403.19887v2, Mar. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Falcon Mamba: The first competitive attention-free 7B language model,
J. Zuo, M. Velikanov, D. E. Rhaiem, I. Chahed, Y . Belkada, G. Kunsch, and H. Hacid, “Falcon Mamba: The first competitive attention-free 7B language model,”CoRR, no. 2410.05355v1, Oct. 2024
-
[15]
Graph Mamba: Towards learning on graphs with state space models,
A. Behrouz and F. Hashemi, “Graph Mamba: Towards learning on graphs with state space models,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing, ser. KDD ’24. ACM, Aug. 2024, pp. 119–130. doi: 10.1145/3637528.3672044
-
[16]
What’s in the image? a deep-dive into the vision of vision language models
A. Hatamizadeh and J. Kautz, “MambaVision: A hybrid Mamba- Transformer vision backbone,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, ser. CVPR 2025. IEEE, Jun. 2025, pp. 25 261–25 270. doi: 10.1109/cvpr52734.2025.02352
-
[17]
Vision Mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision Mamba: Efficient visual representation learning with bidirectional state space model,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24, vol. 235. JMLR.org, Jul. 2024, pp. 62 429–62 442. [Online]. Available: https://proceedings.mlr.press/v235/ zhu24f.html
work page 2024
-
[18]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
S. De, S. L. Smith, A. Fernando, A. Botev, G. Cristian-Muraru, A. Gu, R. Haroun, L. Berrada, Y . Chen, S. Srinivasan, G. Desjardins, A. Doucet, D. Budden, Y . W. Teh, R. Pascanu, N. D. Freitas, and C. Gulcehre, “Griffin: Mixing gated linear recurrences with local attention for efficient language models,”CoRR, no. 2402.19427v1, Feb. 2024
work page internal anchor Pith review arXiv 2024
-
[19]
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,” in Proceedings of the 41st International Conference on Machine Learning, ser. ICML’24, vol. 235. JMLR.org, Jul. 2024, pp. 10 041–10 071. [Online]. Available: https://proceedings.mlr.press/v235/dao24a.html
work page 2024
-
[20]
Gated delta networks: Improving Mamba2 with delta rule,
S. Yang, J. Kautz, and A. Hatamizadeh, “Gated delta networks: Improving Mamba2 with delta rule,” in13th International Conference on Learning Representations, ser. ICLR 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=r8H7xhYPwz
work page 2025
-
[21]
MARCA: Mamba accelerator with reconfigurable architecture,
J. Li, S. Huang, J. Xu, J. Liu, L. Ding, N. Xu, and G. Dai, “MARCA: Mamba accelerator with reconfigurable architecture,” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, ser. ICCAD ’24. New York, NY , USA: Association for Computing Machinery, 2025. doi: 10.1145/3676536.3676798
-
[22]
Fine-Grained Fusion: The Missing Piece in Area-Efficient State Space Model Acceleration
R. Geens, A. Symons, and M. Verhelst, “Fine-grained fusion: The missing piece in area-efficient state space model acceleration,”CoRR, no. 2504.17333, Apr. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
F. Kjolstad, S. Kamil, S. Chou, D. Lugato, and S. Amarasinghe, “The tensor algebra compiler,”Proceedings of the ACM on Program- ming Languages, vol. 1, no. OOPSLA, pp. 1–29, Oct. 2017. doi: 10.1145/3133901
-
[24]
TeAAL: A declarative framework for modeling sparse tensor 13 accelerators,
N. Nayak, T. O. Odemuyiwa, S. Ugare, C. Fletcher, M. Pellauer, and J. Emer, “TeAAL: A declarative framework for modeling sparse tensor 13 accelerators,” in56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-56. ACM, Oct. 2023, p. 1255–1270. doi: 10.1145/3613424.3623791
-
[25]
Timeloop: A systematic approach to DNN accelerator evaluation,
A. Parashar, P. Raina, Y . S. Shao, Y .-H. Chen, V . A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to DNN accelerator evaluation,” in2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, Mar. 2019, pp. 304–315. doi: 10.1109/is- pass.2019.00042
work page doi:10.1109/is- 2019
-
[26]
Understanding reuse, performance, and hardware cost of DNN dataflow: A data-centric approach,
H. Kwon, P. Chatarasi, M. Pellauer, A. Parashar, V . Sarkar, and T. Kr- ishna, “Understanding reuse, performance, and hardware cost of DNN dataflow: A data-centric approach,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-
-
[27]
ACM, Oct. 2019, pp. 754–768. doi: 10.1145/3352460.3358252
-
[28]
LoopTree: Exploring the fused-layer dataflow accelerator design space,
M. Gilbert, Y . N. Wu, J. S. Emer, and V . Sze, “LoopTree: Exploring the fused-layer dataflow accelerator design space,”IEEE Transactions on Circuits and Systems for Artificial Intelligence, vol. 1, no. 1, pp. 97–111, Sep. 2024. doi: 10.1109/tcasai.2024.3461716
-
[29]
N. Nayak, X. Wu, T. O. Odemuyiwa, M. Pellauer, J. S. Emer, and C. W. Fletcher, “FuseMax: Leveraging extended einsums to optimize attention accelerator design,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, Nov. 2024, pp. 1458–1473. doi: 10.1109/micro61859.2024.00107
-
[30]
Accelerating sparse data orchestration via dynamic reflexive tiling,
T. O. Odemuyiwa, H. Asghari-Moghaddam, M. Pellauer, K. Hegde, P.- A. Tsai, N. Crago, A. Jaleel, J. D. Owens, E. Solomonik, J. Emer, and C. Fletcher, “Accelerating sparse data orchestration via dynamic reflexive tiling,” inProceedings of the 28th ACM International Con- ference on Architectural Support for Programming Languages and Operating Systems, ser. A...
-
[31]
Sparseloop: An analytical approach to sparse tensor accelerator modeling,
Y . N. Wu, P.-A. Tsai, A. Parashar, V . Sze, and J. S. Emer, “Sparseloop: An analytical approach to sparse tensor accelerator modeling,” in 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, Oct. 2022, pp. 1377–1395. doi: 10.1109/mi- cro56248.2022.00096
work page doi:10.1109/mi- 2022
-
[32]
The EDGE Language: Extended General Einsums for Graph Algorithms
T. O. Odemuyiwa, J. S. Emer, and J. D. Owens, “The EDGE lan- guage: Extended general einsums for graph algorithms,”CoRR, no. 2404.11591v1, Apr. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
J. Ragan-Kelley, C. Barnes, A. Adams, S. Paris, F. Durand, and S. P. Amarasinghe, “Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines,” inACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI’13, H. Boehm and C. Flanagan, Eds. ACM, Jun. 2013, pp. 519–530. doi:...
-
[34]
On the role of scientific thought,
E. W. Dijkstra, “On the role of scientific thought,” inSelected Writings on Computing: A personal Perspective. New York, NY: Springer New York, 1982, pp. 60–66. doi: 10.1007/978-1-4612-5695-3 12
-
[35]
HiPPO: recurrent memory with optimal polynomial projections,
A. Gu, T. Dao, S. Ermon, A. Rudra, and C. R ´e, “HiPPO: recurrent memory with optimal polynomial projections,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Curran Associates Inc., Dec
-
[36]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2020/hash/102f0bb6efb3a6128a3c750dd16729be-Abstract.html
work page 2020
-
[37]
Combining recurrent, convolutional, and continuous- time models with linear state-space layers,
A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. R ´e, “Combining recurrent, convolutional, and continuous- time models with linear state-space layers,” inProceedings of the 35th International Conference on Neural Information Processing Systems, ser. NeurIPS 2021. Curran Associates Inc.,
work page 2021
-
[38]
[Online]. Available: https://proceedings.neurips.cc/paper/2021/ file/05546b0e38ab9175cd905eebcc6ebb76-Paper.pdf
work page 2021
-
[39]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,” in10th International Conference on Learning Representations, ser. ICLR 2022. OpenReview.net, 2022. [Online]. Available: https://openreview.net/pdf?id=uYLFoz1vlAC
work page 2022
-
[40]
It’s raw! audio generation with state-space models,
K. Goel, A. Gu, C. Donahue, and C. R ´e, “It’s raw! audio generation with state-space models,” inProceedings of the 39th International Conference on Machine Learning, vol. 162, Jul. 2022. [Online]. Available: https://proceedings.mlr.press/v162/goel22a/goel22a.pdf
work page 2022
-
[41]
How to train your HiPPO: State space models with generalized basis projections,
A. Gu, I. Johnson, A. Timalsina, A. Rudra, and C. R ´e, “How to train your HiPPO: State space models with generalized basis projections,” in International Conference on Learning Representations (ICLR), 2023. [Online]. Available: https://openreview.net/forum?id=klK17OQ3KB
work page 2023
-
[42]
On the parameterization and initialization of diagonal state space models,
A. Gu, A. Gupta, K. Goel, and C. R ´e, “On the parameterization and initialization of diagonal state space models,”Advances in Neural Information Processing Systems, vol. 35, 2022. [Online]. Available: https://papers.neurips.cc/paper files/paper/2022/file/ e9a32fade47b906de908431991440f7c-Paper-Conference.pdf
work page 2022
-
[43]
S4ND: Modeling images and videos as multidimensional signals using state spaces,
E. Nguyen, K. Goel, A. Gu, G. W. Downs, P. Shah, T. Dao, S. A. Baccus, and C. R ´e, “S4ND: Modeling images and videos as multidimensional signals using state spaces,”Advances in Neural Information Processing Systems, vol. 35, 2022. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2022/file/13388efc819c09564c66ab2dc8463809-Paper-Confe...
work page 2022
-
[44]
S. Williams, A. Waterman, and D. A. Patterson, “Roofline: An in- sightful visual performance model for multicore architectures,”Com- munications of the ACM, vol. 52, no. 4, pp. 65–76, 2009. doi: 10.1145/1498765.1498785
-
[45]
Nimble: Efficiently compiling dynamic neural networks for model inference,
H. Shen, J. Roesch, Z. Chen, W. Chen, Y . Wu, M. Li, V . Sharma, Z. Tatlock, and Y . Wang, “Nimble: Efficiently compiling dynamic neural networks for model inference,” inProceedings of the Fourth Conference on Machine Learning and Systems, ser. MLSys 2021, A. Smola, A. Dimakis, and I. Stoica, Eds., vol. 3, Apr. 2021, pp. 208–222. [Online]. Available: http...
work page 2021
-
[46]
DISC: A dynamic shape compiler for machine learning workloads,
K. Zhu, W. Zhao, Z. Zheng, T. Guo, P. Zhao, J. Bai, J. Yang, X. Liu, L. Diao, and W. Lin, “DISC: A dynamic shape compiler for machine learning workloads,” inProceedings of the 1st Workshop on Machine Learning and Systems, ser. EuroMLSys ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 89–95. doi: 10.1145/3437984.3458838
-
[47]
XLA : Compiling machine learning for peak performance,
A. Sabne, “XLA : Compiling machine learning for peak performance,” 2020. [Online]. Available: https://research.google/pubs/ xla-compiling-machine-learning-for-peak-performance/
work page 2020
-
[48]
Operator fusion in XLA: Analysis and evaluation,
D. Snider and R. Liang, “Operator fusion in XLA: Analysis and evaluation,”CoRR, no. 2301.13062, Jan. 2023
-
[49]
TVM: an automated end-to-end optimizing compiler for deep learning,
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, M. Cowan, H. Shen, L. Wang, Y . Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy, “TVM: an automated end-to-end optimizing compiler for deep learning,” in Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’18. USA: USENIX Association, 2018, pp. 579–594
work page 2018
-
[50]
Z. Zheng, X. Yang, P. Zhao, G. Long, K. Zhu, F. Zhu, W. Zhao, X. Liu, J. Yang, J. Zhai, S. L. Song, and W. Lin, “AStitch: enabling a new multi-dimensional optimization space for memory-intensive ML training and inference on modern SIMT architectures,” inProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages...
-
[51]
BladeDISC: Optimizing dynamic shape machine learning workloads via compiler approach,
Z. Zheng, Z. Pan, D. Wang, K. Zhu, W. Zhao, T. Guo, X. Qiu, M. Sun, J. Bai, F. Zhang, X. Du, J. Zhai, and W. Lin, “BladeDISC: Optimizing dynamic shape machine learning workloads via compiler approach,”Proc. ACM Manag. Data, vol. 1, no. 3, Nov. 2023. doi: 10.1145/3617327
- [52]
-
[53]
J. Ansel, E. Z. Yang, H. He, N. Gimelshein, A. Jain, M. V oznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, G. Chauhan, A. Chourdia, W. Constable, A. Desmaison, Z. DeVito, E. Ellison, W. Feng, J. Gong, M. Gschwind, B. Hirsh, S. Huang, K. Kalambarkar, L. Kirsch, M. La- zos, M. Lezcano, Y . Liang, J. Liang, Y . Lu, C. K. Luk, B. Maher, Y . Pan, C. Puhrsc...
-
[54]
APOLLO: Automatic partition- based operator fusion through layer by layer optimization,
J. Zhao, X. Gao, R. Xia, Z. Zhang, D. Chen, L. Chen, R. Zhang, Z. Geng, B. Cheng, and X. Jin, “APOLLO: Automatic partition- based operator fusion through layer by layer optimization,” in Proceedings of Machine Learning and Systems, ser. MLSys’22, D. Marculescu, Y . Chi, and C. Wu, Eds., vol. 4, 2022, pp. 1–
work page 2022
-
[55]
[Online]. Available: https://proceedings.mlsys.org/paper files/paper/ 2022/file/e175e8a86d28d935be4f43719651f86d-Paper.pdf 14
work page 2022
-
[56]
ConvFusion: A model for layer fusion in convolutional neu- ral networks,
L. Waeijen, S. Sioutas, M. Peemen, M. Lindwer, and H. Corpo- raal, “ConvFusion: A model for layer fusion in convolutional neu- ral networks,”IEEE Access, vol. 9, pp. 168 245–168 267, 2021. doi: 10.1109/ACCESS.2021.3134930
-
[57]
Inter-layer scheduling space definition and exploration for tiled accelerators,
J. Cai, Y . Wei, Z. Wu, S. Peng, and K. Ma, “Inter-layer scheduling space definition and exploration for tiled accelerators,” inProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA). ACM, 2023, pp. 13:1–13:17. doi: 10.1145/3579371.3589048
-
[58]
TeAAL: A declarative framework for modeling sparse tensor 13 accelerators,
S. Zheng, S. Chen, S. Gao, L. Jia, G. Sun, R. Wang, and Y . Liang, “TileFlow: A framework for modeling fusion dataflow via tree-based analysis,” in56th Annual IEEE/ACM International Symposium on Mi- croarchitecture, ser. MICRO-56. ACM, Oct. 2023, pp. 1271–1288. doi: 10.1145/3613424.3623792
-
[59]
FLAT: An optimized dataflow for mitigating attention bot- tlenecks,
S.-C. Kao, S. Subramanian, G. Agrawal, A. Yazdanbakhsh, and T. Kr- ishna, “FLAT: An optimized dataflow for mitigating attention bot- tlenecks,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’23. ACM, Jan. 2023, pp. 295–310. doi: 10.1145/3575693.3575747
-
[60]
Optimus: An operator fusion framework for deep neural networks,
X. Cai, Y . Wang, and L. Zhang, “Optimus: An operator fusion framework for deep neural networks,”ACM Transactions on Embed- ded Computing Systems, vol. 22, no. 1, pp. 1–26, Oct. 2022. doi: 10.1145/3520142
-
[61]
TeAAL: A declarative framework for modeling sparse tensor 13 accelerators,
Z. Y . Xue, Y . N. Wu, J. S. Emer, and V . Sze, “Tailors: Accelerating sparse tensor algebra by overbooking buffer capacity,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microar- chitecture, ser. MICRO-56. ACM, Oct. 2023, pp. 1347–1363. doi: 10.1145/3613424.3623793
-
[62]
The design process for Google’s training chips: TPUv2 and TPUv3,
T. Norrie, N. Patil, D. H. Yoon, G. Kurian, S. Li, J. Laudon, C. Young, N. Jouppi, and D. Patterson, “The design process for Google’s training chips: TPUv2 and TPUv3,”IEEE Micro, vol. 41, no. 2, pp. 56–63, Mar
-
[63]
doi: 10.1109/mm.2021.3058217
-
[64]
Dedicated hardware for complex mathematical operations,
P. Mal ´ık, “Dedicated hardware for complex mathematical operations,” Computing and Informatics, vol. 35, no. 6, pp. 1438–1466, Feb
-
[65]
Available: https://www.cai.sk/ojs/index.php/cai/article/ view/3557
[Online]. Available: https://www.cai.sk/ojs/index.php/cai/article/ view/3557
- [66]
-
[67]
GPU Technology Conference 2022: Hopper architecture whitepaper,
NVIDIA, “GPU Technology Conference 2022: Hopper architecture whitepaper,” https://resources.nvidia.com/en-us-tensor-core/ gtc22-whitepaper-hopper, 2022. 15
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.