Multi-Plane Vision Transformer for Hemorrhage Classification Using Axial and Sagittal MRI Data
Pith reviewed 2026-05-22 16:56 UTC · model grok-4.3
The pith
A multi-plane vision transformer using cross-attention between axial and sagittal MRI encoders improves brain hemorrhage classification over standard ViT and CNN models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
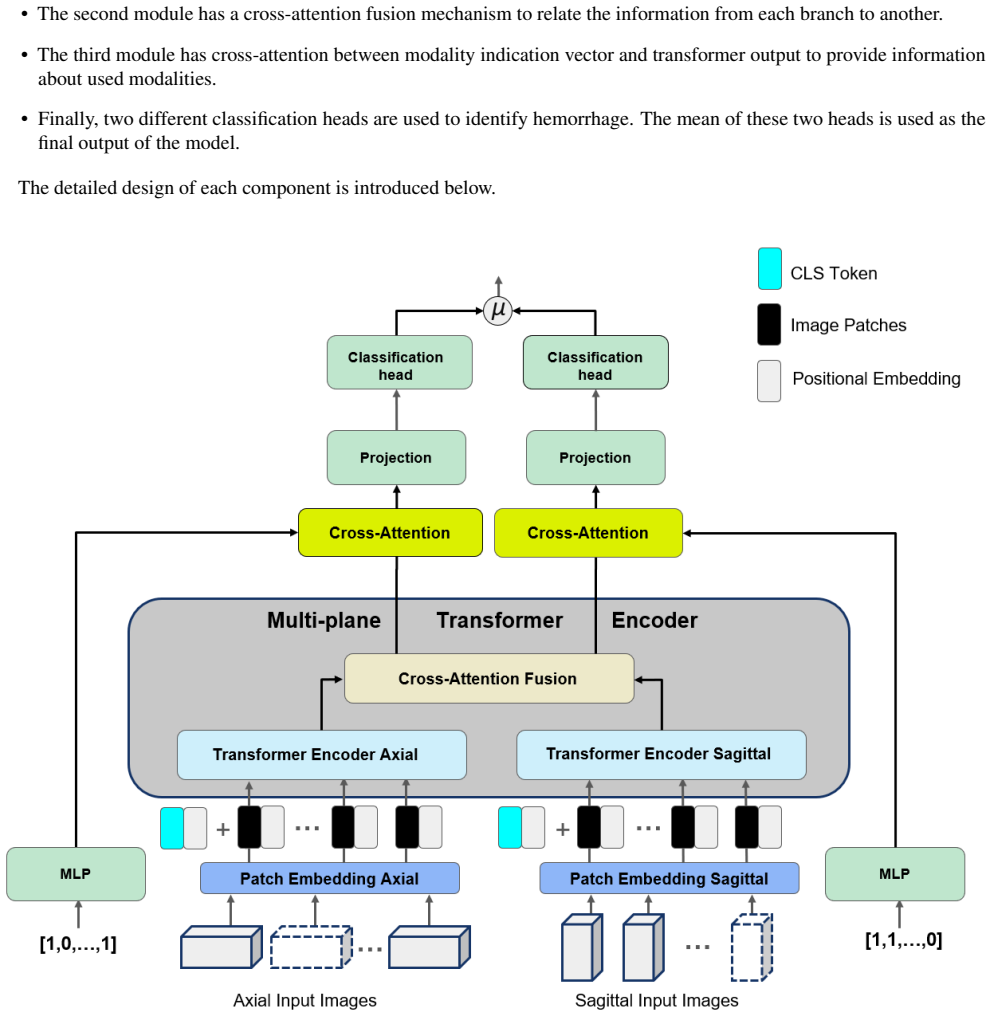
The MP-ViT architecture processes axial and sagittal MRI volumes with two independent transformer encoders whose outputs are fused by cross-attention; a modality indication vector supplies information about missing contrasts. This design avoids the information loss that occurs when all volumes are resampled to a single plane. On a real-world dataset of 10,084 training, 1,289 validation and 1,496 test subjects, MP-ViT records higher area-under-the-curve scores than either a standard vision transformer or CNN-based classifiers.
What carries the argument
Cross-attention between two separate transformer encoders, one for axial and one for sagittal contrasts, that integrates complementary orientation-specific information while a modality vector flags available contrasts.
If this is right
- Improved detection accuracy when MRI protocols vary in orientation across patients or sites.
- Less information loss compared with resampling all volumes to a fixed plane.
- Direct applicability to any classification task that receives both axial and sagittal contrasts.
- Outperformance holds against both transformer and convolutional baselines on the reported dataset.
Where Pith is reading between the lines
- The same cross-attention pattern could be tested on other multi-orientation tasks such as tumor grading or stroke lesion detection.
- Extending the modality vector to additional contrasts might allow a single model to handle full clinical MRI protocols without retraining.
- Performance gains may depend on the specific balance of axial and sagittal cases in training; deliberate imbalance experiments would clarify this.
- Deployment in emergency settings could reduce missed hemorrhages when only one orientation is quickly acquired.
Load-bearing premise
Cross-attention successfully merges complementary information from the two orientations without introducing orientation-specific biases that would limit performance on new clinical sites.
What would settle it
Measuring AUC on an independent multi-center test set whose axial-to-sagittal orientation distribution differs markedly from the original training data.
Figures


read the original abstract
Identifying brain hemorrhages from magnetic resonance imaging (MRI) is a critical task for healthcare professionals. The diverse nature of MRI acquisitions with varying contrasts and orientation introduce complexity in identifying hemorrhage using neural networks. For acquisitions with varying orientations, traditional methods often involve resampling images to a fixed plane, which can lead to information loss. To address this, we propose a 3D multi-plane vision transformer (MP-ViT) for hemorrhage classification with varying orientation data. It employs two separate transformer encoders for axial and sagittal contrasts, using cross-attention to integrate information across orientations. MP-ViT also includes a modality indication vector to provide missing contrast information to the model. The effectiveness of the proposed model is demonstrated with extensive experiments on real world clinical dataset consists of 10,084 training, 1,289 validation and 1,496 test subjects. MP-ViT achieved substantial improvement in area under the curve (AUC), outperforming the vision transformer (ViT) by 5.5% and CNN-based architectures by 1.8%. These results highlight the potential of MP-ViT in improving performance for hemorrhage detection when different orientation contrasts are needed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-Plane Vision Transformer (MP-ViT) for classifying brain hemorrhages from MRI scans acquired in axial and sagittal orientations. It deploys two separate Vision Transformer encoders (one per orientation) whose outputs are fused via cross-attention layers, together with a modality indication vector to supply missing contrast information. On a real-world clinical dataset of 10,084 training, 1,289 validation and 1,496 test subjects, MP-ViT reports an AUC improvement of 5.5 % over a standard ViT and 1.8 % over CNN baselines.
Significance. If the reported gains can be shown to arise from successful cross-orientation fusion rather than increased model capacity, the work would provide a practical method for exploiting multi-plane MRI data without the information loss incurred by resampling to a single orientation. The evaluation on a sizable, real-world clinical collection is a clear empirical strength.
major comments (1)
- [Results section (comparison to ViT baseline)] The central claim attributes the 5.5 % AUC gain over the single-encoder ViT baseline to the cross-attention mechanism that integrates complementary axial and sagittal information. MP-ViT, however, consists of two complete transformer encoders plus cross-attention layers, materially increasing parameter count and compute relative to the baseline. No ablation that holds total model capacity fixed (e.g., dual-encoder with simple concatenation or late fusion instead of cross-attention) is presented. Consequently the observed improvement could result from extra modeling power rather than orientation-specific fusion, weakening the mechanistic interpretation required for the headline result.
minor comments (2)
- [Methods and Results] The manuscript provides no details on statistical testing (confidence intervals, p-values, or multiple-comparison correction) for the reported AUC differences, hyper-parameter search procedure, or precise data-exclusion criteria. These omissions limit reproducibility and assessment of result robustness.
- [Model Architecture] Notation for the modality indication vector and the precise formulation of the cross-attention fusion block would benefit from an explicit equation or pseudocode block to clarify implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment raises a valid point about isolating the contribution of cross-attention versus model capacity, which we address below.
read point-by-point responses
-
Referee: [Results section (comparison to ViT baseline)] The central claim attributes the 5.5 % AUC gain over the single-encoder ViT baseline to the cross-attention mechanism that integrates complementary axial and sagittal information. MP-ViT, however, consists of two complete transformer encoders plus cross-attention layers, materially increasing parameter count and compute relative to the baseline. No ablation that holds total model capacity fixed (e.g., dual-encoder with simple concatenation or late fusion instead of cross-attention) is presented. Consequently the observed improvement could result from extra modeling power rather than orientation-specific fusion, weakening the mechanistic interpretation required for the headline result.
Authors: We agree that the absence of a capacity-controlled ablation limits the strength of the mechanistic claim. The single-orientation ViT baseline necessarily uses fewer parameters than a dual-encoder architecture, so the reported 5.5 % AUC improvement cannot be attributed solely to cross-attention without further controls. In the revised manuscript we will add an ablation that compares MP-ViT against a dual-encoder ViT using simple concatenation (or late fusion) of the two orientation embeddings, with hidden dimensions adjusted so that total parameter count is matched to within 5 %. This will allow a direct assessment of whether the cross-attention fusion itself, rather than extra capacity, drives the observed gains. revision: yes
Circularity Check
No significant circularity in empirical architecture evaluation
full rationale
The paper proposes the MP-ViT architecture and reports empirical AUC improvements on a fixed clinical dataset split (10,084 training, 1,289 validation, 1,496 test subjects). These gains are presented as measured outcomes of training the dual-encoder plus cross-attention model versus baselines. No equations, predictions, or first-principles results are claimed that reduce by construction to fitted inputs, self-citations, or ansatzes. The central performance claims rest on standard supervised learning and hold-out evaluation rather than any tautological reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of transformer layers, attention heads, and embedding dimensions
- cross-attention fusion weights and modality vector scaling
axioms (1)
- domain assumption Cross-attention between axial and sagittal feature maps produces a representation that is more discriminative for hemorrhage than single-plane processing.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
It employs two separate transformer encoders for axial and sagittal contrasts, using cross-attention to integrate information across orientations.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MP-ViT achieved substantial improvement in area under the curve (AUC), outperforming the vision transformer (ViT) by 5.5%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Romanova, A. L. et al. Magnetic resonance imaging versus computed tomography for identification and quantification of intraventricular hemorrhage. J. Stroke Cerebrovasc. Dis. 23, 2036–2040 (2014)
work page 2036
-
[2]
Mri: the new gold standard for detecting brain hemorrhage? Stroke 33, 1748–1749 (2002)
von Kummer, R. Mri: the new gold standard for detecting brain hemorrhage? Stroke 33, 1748–1749 (2002)
work page 2002
-
[3]
Ismael, S. H., Kareem, S. W. & Almukhtar, F. H. Medical image classification using different machine learning algorithms. AL-Rafidain J. Comput. Sci. Math. 14, 135–147 (2020)
work page 2020
-
[4]
Rahmat, T., Ismail, A. & Aliman, S. Chest x-rays image classification in medical image analysis. Appl. Med. Informatics 40, 63–73 (2018)
work page 2018
-
[5]
Jaeger, P. F. et al. Retina u-net: Embarrassingly simple exploitation of segmentation supervision for medical object detection. In Machine Learning for Health Workshop, 171–183 (PMLR, 2020)
work page 2020
-
[6]
Li, Z. et al. Clu-cnns: Object detection for medical images. Neurocomputing 350, 53–59 (2019)
work page 2019
-
[7]
Malhotra, P., Gupta, S., Koundal, D., Zaguia, A. & Enbeyle, W. [retracted] deep neural networks for medical image segmentation. J. Healthc. Eng. 2022, 9580991 (2022)
work page 2022
-
[8]
Roth, H. R. et al. Deep learning and its application to medical image segmentation. Med. Imaging Technol. 36, 63–71 (2018)
work page 2018
-
[9]
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
N., Ahmadabadi, H., Kashiani, H., Shokouhi, S
Manzari, O. N., Ahmadabadi, H., Kashiani, H., Shokouhi, S. B. & Ayatollahi, A. Medvit: a robust vision transformer for generalized medical image classification. Comput. Biol. Medicine 157, 106791 (2023)
work page 2023
- [11]
-
[12]
He, K. et al. Transformers in medical image analysis. Intell. Medicine 3, 59–78 (2023)
work page 2023
-
[13]
Object detection in medical images based on hierarchical transformer and mask mechanism
Shou, Y .et al. Object detection in medical images based on hierarchical transformer and mask mechanism. Comput. Intell. Neurosci. 2022, 5863782 (2022)
work page 2022
-
[14]
Hatamizadeh, A. et al. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In International MICCAI Brainlesion Workshop, 272–284 (Springer, 2021)
work page 2021
-
[15]
Hatamizadeh, A. et al. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 574–584 (2022)
work page 2022
-
[16]
Zhou, H.-Y .et al. nnformer: V olumetric medical image segmentation via a 3d transformer.IEEE Transactions on Image Process. (2023)
work page 2023
-
[17]
Feng, C.-M. et al. Multi-modal transformer for accelerated mr imaging. IEEE Transactions on Med. Imaging (2022)
work page 2022
-
[18]
Luthra, A., Sulakhe, H., Mittal, T., Iyer, A. & Yadav, S. Eformer: Edge enhancement based transformer for medical image denoising. arXiv preprint arXiv:2109.08044 (2021)
-
[19]
Jnawali, K., Arbabshirani, M. R., Rao, N. & Patel, A. A. Deep 3d convolution neural network for ct brain hemorrhage classification. In Medical Imaging 2018: Computer-Aided Diagnosis, vol. 10575, 307–313 (SPIE, 2018). 8/10
work page 2018
-
[20]
S., Ahuja, S., Dang, N., Soni, S
Pannu, H. S., Ahuja, S., Dang, N., Soni, S. & Malhi, A. K. Deep learning based image classification for intestinal hemorrhage. Multimed. Tools Appl. 79, 21941–21966 (2020)
work page 2020
-
[21]
ElZemity, A. et al. A transformer-based deep learning architecture for accurate intracranial hemorrhage detection and classification. In 2023 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), 215–220 (IEEE, 2023)
work page 2023
- [22]
-
[23]
Barhoumi, Y . & Rasool, G. Scopeformer: n-cnn-vit hybrid model for intracranial hemorrhage classification.arXiv preprint arXiv:2107.04575 (2021)
- [24]
-
[25]
Liu, H. et al. Moddrop++: A dynamic filter network with intra-subject co-training for multiple sclerosis lesion segmentation with missing modalities. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 444–453 (Springer, 2022)
work page 2022
-
[26]
Vaswani, A. et al. Attention is all you need. Adv. neural information processing systems 30 (2017)
work page 2017
-
[27]
Chen, C.-F. R., Fan, Q. & Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF international conference on computer vision, 357–366 (2021)
work page 2021
-
[28]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [29]
-
[30]
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708 (2017)
work page 2017
-
[31]
Cardoso, M. J. et al. Monai: An open-source framework for deep learning in healthcare. arXiv preprint arXiv:2211.02701 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Note on the sampling error of the difference between correlated proportions or percentages
McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 12, 153–157 (1947)
work page 1947
-
[33]
Fischer, U. et al. Magnetic resonance imaging or computed tomography for suspected acute stroke: association of admission image modality with acute recanalization therapies, workflow metrics, and outcomes. Annals neurology 92, 184–194 (2022)
work page 2022
-
[34]
Vernooij, M. W.et al. Incidental findings on brain mri in the general population. New Engl. J. Medicine 357, 1821–1828 (2007)
work page 2007
-
[35]
Nael, K. et al. Automated detection of critical findings in multi-parametric brain mri using a system of 3d neural networks. Sci. reports 11, 6876 (2021). Acknowledgements This research project was funded by Siemens Healthineers. We acknowledge the usage of MRI images from the Mount Sinai Hospital. Author contributions statement E.G., D.C. and A.M. contri...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.