TeleSABRE: Layout Synthesis in Multi-Core Quantum Systems with Teleport Interconnect
Pith reviewed 2026-05-22 15:02 UTC · model grok-4.3
The pith
TeleSABRE extends SABRE to mix intra-core SWAPs with teleportation across cores, cutting inter-core operations by 28 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TeleSABRE augments the SABRE search by allowing both local SWAPs and teleportation-based qubit relocation between cores; the heuristic now evaluates candidate layouts that trade off the cost of preparing and executing teleportation protocols against the cost of additional intra-core SWAPs needed to bring qubits into position for those protocols. When evaluated on a range of quantum circuits, this joint optimization yields a 28 percent reduction in inter-core operations relative to plain SABRE while still producing valid executable schedules.
What carries the argument
TeleSABRE heuristic, which extends SABRE's lookahead search by adding teleportation moves (both qubit teleportation and gate teleportation) as first-class relocation primitives whose preparation overhead is included in the routing cost.
If this is right
- Fewer inter-core communications lower the total execution time on teleport-linked modular processors.
- The same heuristic also trims the number of intra-core SWAPs that would otherwise be needed solely to enable teleportation.
- Circuits that previously required many long-range interactions become more practical on hardware with limited teleport bandwidth.
- Layout synthesis can now be performed once per architecture rather than requiring separate manual tuning for each teleport protocol variant.
Where Pith is reading between the lines
- The same cost-modeling approach could be applied to other interconnect primitives such as photonic links or shuttling, provided their overheads are known.
- If teleport success probabilities turn out to vary with circuit depth or qubit state, the heuristic would need an online calibration loop to remain accurate.
- Scaling TeleSABRE to processors with dozens of cores would require extending the lookahead window or adding hierarchical routing layers.
Load-bearing premise
The costs and success probabilities of the teleportation protocols are fixed and known ahead of time so they can be inserted into the heuristic without creating new dominant error sources.
What would settle it
Execute the same benchmark circuits on a concrete multi-core architecture once with standard SABRE and once with TeleSABRE, then count the actual number of inter-core teleportations required by each schedule; a result showing no reduction or an increase would falsify the claimed benefit.
Figures









read the original abstract
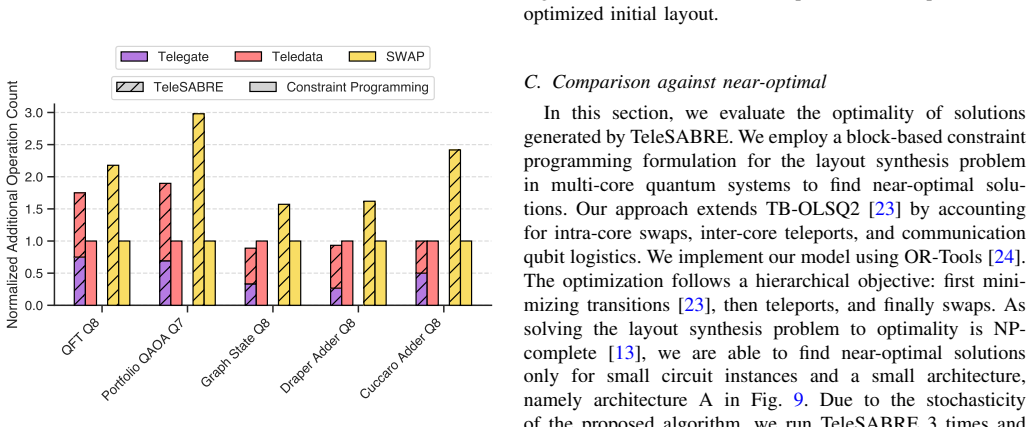
Quantum circuit compilation and, in particular, efficient qubit layout synthesis is a critical challenge in modular, multi-core quantum architectures with constrained interconnects. In this work, we extend the SABRE heuristic algorithm to develop TeleSABRE, a layout synthesis approach tailored for architectures featuring teleportation-based interconnects. Unlike standard SABRE, which only introduces SWAP operations for qubit movement, TeleSABRE integrates both intracore SWAPs and teleportation-based techniques leveraging qubit teleportation and gate teleportation across cores. This enables more efficient circuit execution by reducing both inter-core communication overhead and the number of intra-core SWAPs required to allow teleportation protocols and local gate executions. Experimental results demonstrate that TeleSABRE achieves 28% reduction across various benchmarks in terms of inter-core operations while also taking into account the logistics of the teleport protocols.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the SABRE heuristic to TeleSABRE for layout synthesis on multi-core quantum architectures that use teleportation-based interconnects. TeleSABRE augments standard intra-core SWAP insertion with qubit teleportation and gate teleportation primitives, folding their logistics (latencies and success probabilities) into the cost function to jointly minimize inter-core operations and the SWAPs needed to enable them. The central empirical claim is a 28% reduction in inter-core operations relative to baseline SABRE across an unspecified set of circuit benchmarks.
Significance. If the 28% reduction is shown to be robust and to correspond to net gains in executable fidelity or runtime once device-specific teleport calibration and error channels are included, the work would provide a practical compilation tool for modular quantum processors. The explicit incorporation of teleport logistics into the search heuristic is a clear technical contribution over prior SWAP-only methods; however, the absence of benchmark lists, baseline details, error bars, or statistical tests in the reported results limits the immediate impact.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim of a 28% reduction in inter-core operations supplies no list of benchmark circuits, no description of the baseline SABRE configuration, no error bars, and no statistical tests. Without these, it is impossible to determine whether the reported improvement is robust or sensitive to post-hoc choices of weighting between SWAP and teleport costs.
- [Method] Method section (cost-function definition): the extended heuristic treats teleport success probabilities and latencies as fixed, architecture-independent inputs. If these parameters require device-specific calibration or if unmodeled error channels from teleportation dominate the reported savings, the measured reduction in inter-core operations will not translate to net improvement in circuit fidelity or runtime; the manuscript provides no sensitivity analysis or device-model validation for this modeling choice.
minor comments (2)
- [Method] Notation for qubit and gate teleportation primitives is introduced without an explicit table comparing their resource costs to intra-core SWAPs; adding such a table would improve readability.
- [Experimental Results] Figure captions for the experimental plots do not state the number of random seeds or the exact hyper-parameter settings used for TeleSABRE versus baseline SABRE.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim of a 28% reduction in inter-core operations supplies no list of benchmark circuits, no description of the baseline SABRE configuration, no error bars, and no statistical tests. Without these, it is impossible to determine whether the reported improvement is robust or sensitive to post-hoc choices of weighting between SWAP and teleport costs.
Authors: We agree that the experimental presentation would benefit from greater detail. In the revised manuscript we will add the complete list of benchmark circuits, specify the exact SABRE baseline configuration and cost-weighting parameters used, report error bars derived from repeated runs of the heuristic, and include a brief discussion of result consistency across the benchmark set. These changes will allow readers to assess robustness directly. revision: yes
-
Referee: [Method] Method section (cost-function definition): the extended heuristic treats teleport success probabilities and latencies as fixed, architecture-independent inputs. If these parameters require device-specific calibration or if unmodeled error channels from teleportation dominate the reported savings, the measured reduction in inter-core operations will not translate to net improvement in circuit fidelity or runtime; the manuscript provides no sensitivity analysis or device-model validation for this modeling choice.
Authors: The cost function is intentionally parameterized so that success probabilities and latencies can be supplied as device-specific inputs. We acknowledge the absence of sensitivity analysis and will add a dedicated subsection that varies these parameters over plausible ranges and reports the resulting change in inter-core operation counts. Full device-model validation with calibrated error channels lies outside the scope of the present compilation study; we will add an explicit limitations paragraph clarifying this modeling assumption and its relation to end-to-end fidelity. revision: partial
Circularity Check
No circularity: TeleSABRE is a heuristic evaluated on external benchmarks
full rationale
The paper extends the existing SABRE heuristic by incorporating qubit and gate teleportation primitives into the cost function and search procedure for multi-core layouts. The reported 28% reduction in inter-core operations is obtained by executing the modified heuristic on standard quantum circuit benchmarks and counting the resulting operations; this empirical outcome does not reduce, by any equation in the paper, to a quantity defined in terms of a fitted parameter or to a self-citation chain. The modeling of teleport costs and success probabilities is treated as an input assumption rather than derived from the algorithm itself, so the central claim remains independent of the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teleportation protocols incur known, fixed communication and gate costs that can be precomputed and used inside the heuristic cost function.
Forward citations
Cited by 1 Pith paper
-
dSABRE: A SABRE-Style Router for Multi-Core Distributed Quantum Computers
dSABRE cuts geometric-mean EPR consumption by 41-44% versus TeleSABRE on 18 benchmark circuits through intra-core priority, a five-term teleportation scorer with capacity penalty, proactive congestion relief, and BFS-...
Reference graph
Works this paper leans on
-
[1]
Quantum algorithms: an overview,
A. Montanaro, “Quantum algorithms: an overview,” npj Quantum Infor- mation, vol. 2, no. 1, pp. 1–8, 2016
work page 2016
-
[2]
Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,
P. W. Shor, “Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,”SIAM review, vol. 41, no. 2, pp. 303–332, 1999
work page 1999
-
[3]
A fast quantum mechanical algorithm for database search,
L. K. Grover, “A fast quantum mechanical algorithm for database search,” inACM symposium on Theory of computing, 1996, pp. 212–219
work page 1996
-
[4]
M. A. Nielsen and I. L. Chuang, Quantum computation and quantum information. Cambridge university press, 2010
work page 2010
-
[5]
Quantum computing in the nisq era and beyond,
J. Preskill, “Quantum computing in the nisq era and beyond,” Quantum, vol. 2, p. 79, 2018
work page 2018
-
[6]
Aaronson, Quantum computing since Democritus
S. Aaronson, Quantum computing since Democritus . Cambridge University Press, 2013
work page 2013
-
[7]
H. Jnane, B. Undseth, Z. Cai, S. C. Benjamin, and B. Koczor, “Multicore quantum computing,” Physical Review Applied , vol. 18, no. 4, 2022
work page 2022
-
[8]
Mitigating crosstalk in quantum computers through commutativity-based instruction reordering,
L. Xie, J. Zhai, and W. Zheng, “Mitigating crosstalk in quantum computers through commutativity-based instruction reordering,” in 2021 58th ACM/IEEE Design Automation Conference (DAC) . IEEE, 2021, pp. 445–450
work page 2021
-
[9]
Detecting crosstalk errors in quantum information processors,
M. Sarovar, T. Proctor, K. Rudinger, K. Young, E. Nielsen, and R. Blume-Kohout, “Detecting crosstalk errors in quantum information processors,” Quantum, vol. 4, p. 321, 2020
work page 2020
-
[10]
Quantum supremacy using a programmable superconducting processor,
F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, R. Biswas, S. Boixo, F. G. Brandao, D. A. Buell et al. , “Quantum supremacy using a programmable superconducting processor,” Nature, vol. 574, no. 7779, pp. 505–510, 2019
work page 2019
-
[11]
Scaling superconducting quantum computers with chiplet architectures,
K. N. Smith, G. S. Ravi, J. M. Baker, and F. T. Chong, “Scaling superconducting quantum computers with chiplet architectures,” in IEEE/ACM International Symposium on Microarchitecture (MICRO) , 2022, pp. 1092–1109
work page 2022
-
[12]
E. Alarc ´on, S. Abadal, F. Sebastiano, M. Babaie, E. Charbon, P. H. Bol´ıvar, M. Palesi, E. Blokhina, D. Leipold, B. Staszewski, A. Garcia- S´aez, and C. G. Almudever, “Scalable multi-chip quantum architectures enabled by cryogenic hybrid wireless/quantum-coherent network-in- package,” in 2023 IEEE International Symposium on Circuits and Systems (ISCAS),...
work page 2023
-
[13]
On the complexity of quan- tum circuit compilation,
A. Botea, A. Kishimoto, and R. Marinescu, “On the complexity of quan- tum circuit compilation,” in Proceedings of the International Symposium on Combinatorial Search , vol. 9, no. 1, 2018, pp. 138–142
work page 2018
-
[14]
M. Y . Siraichi, V . F. d. Santos, C. Collange, and F. M. Q. Pereira, “Qubit allocation,” in International Symposium on Code Generation and Optimization, 2018, pp. 113–125
work page 2018
-
[15]
Tackling the qubit mapping problem for nisq-era quantum devices,
G. Li, Y . Ding, and Y . Xie, “Tackling the qubit mapping problem for nisq-era quantum devices,” in Proceedings of the twenty-fourth interna- tional conference on architectural support for programming languages and operating systems , 2019, pp. 1001–1014
work page 2019
-
[16]
Distributed quantum computing: a survey,
M. Caleffi, M. Amoretti, D. Ferrari, J. Illiano, A. Manzalini, and A. S. Cacciapuoti, “Distributed quantum computing: a survey,” Computer Networks, vol. 254, p. 110672, 2024
work page 2024
-
[17]
S. Rodrigo, S. Abadal, C. G. Almud ´ever, and E. Alarc ´on, “Modelling short-range quantum teleportation for scalable multi-core quantum com- puting architectures,” in ACM International Conference on Nanoscale Computing and Communication , 2021, pp. 1–7
work page 2021
-
[18]
Lightsabre: A lightweight and enhanced sabre algorithm,
H. Zou, M. Treinish, K. Hartman, A. Ivrii, and J. Lishman, “Lightsabre: A lightweight and enhanced sabre algorithm,” arXiv preprint arXiv:2409.08368, 2024
-
[19]
A note on two problems in connexion with graphs,
E. W. Dijkstra, “A note on two problems in connexion with graphs,” in Edsger Wybe Dijkstra: his life, work, and legacy , 2022, pp. 287–290
work page 2022
-
[20]
Quantum computing with Qiskit,
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, and J. M. Gambetta, “Quantum computing with Qiskit,” 2024
work page 2024
-
[21]
MQT Bench: Bench- marking software and design automation tools for quantum computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “MQT Bench: Bench- marking software and design automation tools for quantum computing,” Quantum, 2023, MQT Bench is available at https://www.cda.cit.tum.de/ mqtbench/
work page 2023
-
[22]
Hungarian qubit assignment for optimized mapping of quantum cir- cuits on multi-core architectures,
P. Escofet, A. Ovide, C. G. Almudever, E. Alarc ´on, and S. Abadal, “Hungarian qubit assignment for optimized mapping of quantum cir- cuits on multi-core architectures,” IEEE Computer Architecture Letters , vol. 22, no. 2, pp. 161–164, 2023
work page 2023
-
[23]
Scalable optimal layout synthesis for nisq quantum processors,
W.-H. Lin, J. Kimko, B. Tan, N. Bjørner, and J. Cong, “Scalable optimal layout synthesis for nisq quantum processors,” in 2023 60th ACM/IEEE Design Automation Conference (DAC) . IEEE, 2023, pp. 1–6
work page 2023
- [24]
-
[25]
Compiler design for distributed quantum computing,
D. Ferrari, A. S. Cacciapuoti, M. Amoretti, and M. Caleffi, “Compiler design for distributed quantum computing,” IEEE Transactions on Quantum Engineering, vol. 2, pp. 1–20, 2021
work page 2021
-
[26]
Tackling the qubit mapping problem for nisq-era quantum devices,
G. Li, Y . Ding, and Y . Xie, “Tackling the qubit mapping problem for nisq-era quantum devices,” in International Conference on Architectural Support for Programming Languages and Operating Systems , 2019, pp. 1001–1014
work page 2019
-
[27]
Optimal qubit assignment and routing via integer programming,
G. Nannicini, L. S. Bishop, O. G ¨unl¨uk, and P. Jurcevic, “Optimal qubit assignment and routing via integer programming,” ACM Transactions on Quantum Computing , vol. 4, no. 1, pp. 1–31, 2022
work page 2022
-
[28]
Practical and efficient quantum circuit synthesis and transpiling with reinforcement learning,
D. Kremer, V . Villar, H. Paik, I. Duran, I. Faro, and J. Cruz-Benito, “Practical and efficient quantum circuit synthesis and transpiling with reinforcement learning,” arXiv preprint arXiv:2405.13196 , 2024
-
[29]
Reinforcement learning and dear framework for solving the qubit mapping problem,
C.-Y . Huang, C.-H. Lien, and W.-K. Mak, “Reinforcement learning and dear framework for solving the qubit mapping problem,” in 41st IEEE/ACM international conference on computer-aided design , 2022, pp. 1–9
work page 2022
-
[30]
Automated distribution of quantum circuits via hypergraph partitioning,
P. Andres-Martinez and C. Heunen, “Automated distribution of quantum circuits via hypergraph partitioning,” Physical Review A, vol. 100, no. 3, p. 032308, 2019
work page 2019
-
[31]
Optimized quan- tum circuit partitioning,
O. Daei, K. Navi, and M. Zomorodi-Moghadam, “Optimized quan- tum circuit partitioning,” International Journal of Theoretical Physics , vol. 59, no. 12, pp. 3804–3820, 2020
work page 2020
-
[32]
Time-sliced quantum circuit partitioning for modular architectures,
J. M. Baker, C. Duckering, A. Hoover, and F. T. Chong, “Time-sliced quantum circuit partitioning for modular architectures,” in Proceedings of the 17th ACM International Conference on Computing Frontiers , 2020, pp. 98–107
work page 2020
-
[33]
Efficient distribution of quantum circuits,
R. G Sundaram, H. Gupta, and C. Ramakrishnan, “Efficient distribution of quantum circuits,” in 35th International Symposium on Distributed Computing (DISC 2021) . Schloss Dagstuhl–Leibniz-Zentrum f ¨ur Informatik, 2021, pp. 41–1
work page 2021
-
[34]
Mapping quantum circuits to modular architectures with qubo,
M. Bandic, L. Prielinger, J. N ¨ußlein, A. Ovide, S. Rodrigo, S. Abadal, H. Van Someren, G. Vardoyan, E. Alarcon, C. G. Almudever et al. , “Mapping quantum circuits to modular architectures with qubo,” in 2023 IEEE International Conference on Quantum Computing and Engineer- ing (QCE), vol. 1. IEEE, 2023, pp. 790–801
work page 2023
-
[35]
Optimized compiler for distributed quantum computing,
D. Cuomo, M. Caleffi, K. Krsulich, F. Tramonto, G. Agliardi, E. Prati, and A. S. Cacciapuoti, “Optimized compiler for distributed quantum computing,” ACM Transactions on Quantum Computing , vol. 4, no. 2, pp. 1–29, 2023
work page 2023
-
[36]
Revisiting the mapping of quantum circuits: Entering the multi-core era,
P. Escofet, A. Ovide, M. Bandic, L. Prielinger, H. van Someren, S. Feld, E. Alarc ´on, S. Abadal, and C. G. Almud ´ever, “Revisiting the mapping of quantum circuits: Entering the multi-core era,” ACM Transactions on Quantum Computing, 2024
work page 2024
-
[37]
Attention-Based Deep Reinforcement Learning for Qubit Allocation in Modular Quantum Architectures
E. Russo, M. Palesi, D. Patti, G. Ascia, and V . Catania, “Attention-based deep reinforcement learning for qubit allocation in modular quantum architectures,” arXiv preprint arXiv:2406.11452 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Mech: Multi-entry communication highway for superconducting quan- tum chiplets,
H. Zhang, K. Yin, A. Wu, H. Shapourian, A. Shabani, and Y . Ding, “Mech: Multi-entry communication highway for superconducting quan- tum chiplets,” in 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems , 2024
work page 2024
-
[39]
Route-forcing: Scalable quantum circuit mapping for scalable quantum computing architectures,
P. Escofet, A. Gonzalvo, E. Alarc ´on, C. G. Almud ´ever, and S. Abadal, “Route-forcing: Scalable quantum circuit mapping for scalable quantum computing architectures,” in 2024 IEEE International Conference on Quantum Computing and Engineering (QCE) , vol. 1. IEEE, 2024, pp. 909–920
work page 2024
-
[40]
Exploiting quantum teleporta- tion in quantum circuit mapping,
S. Hillmich, A. Zulehner, and R. Wille, “Exploiting quantum teleporta- tion in quantum circuit mapping,” in Proceedings of the 26th Asia and South Pacific Design Automation Conference , 2021, pp. 792–797
work page 2021
-
[41]
Improving qubit routing by using entanglement mediated remote gates,
G. Padda, E. Tham, A. Brodutch, and D. Touchette, “Improving qubit routing by using entanglement mediated remote gates,” in 2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2024, pp. 1770–1776
work page 2024
-
[42]
Compiler for distributed quantum computing: a reinforcement learning approach,
P. Promponas, A. Mudvari, L. Della Chiesa, P. Polakos, L. Samuel, and L. Tassiulas, “Compiler for distributed quantum computing: a reinforcement learning approach,” arXiv preprint arXiv:2404.17077 , 2024
-
[43]
A modular quantum compila- tion framework for distributed quantum computing,
D. Ferrari, S. Carretta, and M. Amoretti, “A modular quantum compila- tion framework for distributed quantum computing,” IEEE Transactions on Quantum Engineering , vol. 4, pp. 1–13, 2023
work page 2023
-
[44]
Improving figures of merit for quantum circuit compilation,
P. Hopf, N. Quetschlich, L. Schulz, and R. Wille, “Improving figures of merit for quantum circuit compilation,” arXiv preprint arXiv:2501.13155, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.