IMPLICITSTAINER: Resolution Agnostic Data-Efficient Virtual Staining Using Neural Implicit Functions
Pith reviewed 2026-05-22 14:38 UTC · model grok-4.3
The pith
Neural implicit functions enable continuous, resolution-agnostic translation from H&E to virtual IHC stains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
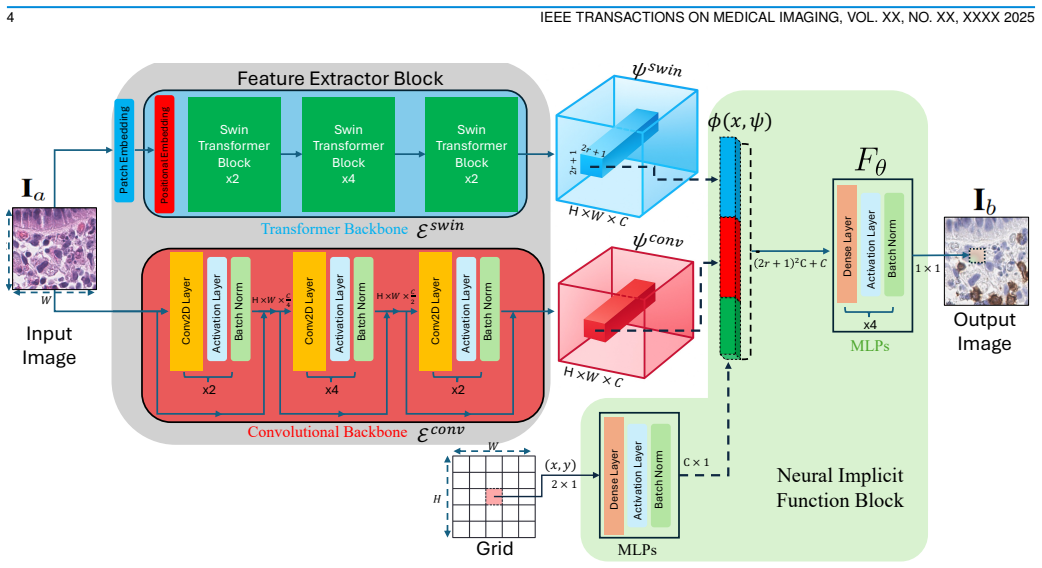
IMPLICITSTAINER uses neural implicit functions to predict each target-domain pixel from a high-dimensional embedding of the source H&E pixel, its local spatial neighborhood, and explicit coordinate information, resulting in state-of-the-art performance on IHC and mIF virtual staining tasks while being resolution-agnostic and deterministic.
What carries the argument
Neural implicit functions that learn a continuous spatial mapping from embedded source pixels and coordinates to target stain values.
If this is right
- Supports virtual staining at resolutions different from those used in training.
- Maintains performance in low-data regimes compared to data-hungry GAN and diffusion models.
- Produces reproducible results without stochastic hallucinations or distortions.
- Applies effectively to both immunohistochemistry and multiplex immunofluorescence staining.
- Outperforms more than twenty existing baselines on standard virtual staining benchmarks.
Where Pith is reading between the lines
- Implicit representations may allow seamless integration with multi-scale whole-slide imaging workflows.
- Reducing reliance on physical stains could lower costs and preserve tissue for additional tests.
- Similar continuous mapping approaches might extend to other cross-modal medical imaging tasks like MRI to CT translation.
Load-bearing premise
That the local pixel neighborhood and coordinate information in the embedding contain enough context to accurately determine the corresponding stain value at every scale.
What would settle it
A test on large tissue sections where the generated stain shows missing large-scale structures or biological inconsistencies not present in the real IHC image.
Figures

read the original abstract
Hematoxylin and eosin (H&E)-stained slides are central to cancer diagnosis and monitoring, visualizing tissue architecture and cellular morphology. However, H&E lacks the molecular specificity needed to distinguish cell states and functional activation. Antibody-based stains, such as immunohistochemistry (IHC), are therefore required to identify specific phenotypes (e.g., CD3$^+$ T cells or HER2-positive tumor cells) but are costly, time-consuming, and not universally available. Deep learning-based image translation methods, often termed virtual staining, offer a complementary alternative by generating virtual immunostains directly from H&E images. Most existing virtual staining methods are patch-based and operate at fixed resolutions, often requiring large datasets and additional post-hoc super-resolution models to generate high-resolution images. Furthermore, GAN- and diffusion-based approaches introduce stochasticity into generated stains which, although beneficial for visual realism in natural images, can lead to hallucinations and structural distortions that affect the accuracy and reliability required for clinical use. We propose IMPLICITSTAINER, a deterministic framework that reformulates virtual staining as a continuous pixel-level translation problem. In contrast to existing patch-based approaches, IMPLICITSTAINER formulates image translation as a continuous spatial mapping using neural implicit deep learning models. Each target-domain (IHC) pixel is predicted from a high-dimensional embedding of the corresponding source-domain H&E pixel, its local spatial neighborhood, and explicit coordinate information. IMPLICITSTAINER enables resolution-agnostic inference, improves robustness in low-data regimes, and yields deterministic, reproducible outputs. Across more than twenty baselines, IMPLICITSTAINER achieves SOTA performance on virtual staining tasks, including IHC and mIF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IMPLICITSTAINER, a deterministic neural implicit function framework for virtual staining that reformulates H&E to IHC/mIF translation as a continuous per-pixel mapping. Each target pixel is generated from a high-dimensional embedding of the corresponding H&E pixel, its local spatial neighborhood, and explicit coordinates. The approach is presented as resolution-agnostic, data-efficient in low-data regimes, and superior to more than twenty existing baselines while avoiding the stochasticity of GAN- and diffusion-based methods.
Significance. If the performance claims are substantiated, the work could meaningfully advance virtual staining by offering a reproducible, resolution-flexible alternative that reduces hallucinations and post-processing needs. The emphasis on determinism and implicit representations aligns with clinical requirements for reliability, and the data-efficiency aspect would be valuable where paired training data are limited.
major comments (2)
- [Method section] Method formulation (implicit function definition): The central modeling choice predicts each IHC/mIF pixel solely from a local H&E embedding plus explicit coordinates. This per-pixel formulation is load-bearing for the resolution-agnostic and structural-consistency claims, yet the manuscript provides no ablation or multi-scale analysis demonstrating that local neighborhood information suffices to capture larger-scale tissue architecture and long-range cellular interactions routinely used in IHC interpretation. If such context is required, the approach risks introducing inconsistencies that patch-based or hierarchical baselines avoid.
- [Results section] Results and evaluation: The abstract states SOTA performance across more than twenty baselines on IHC and mIF tasks, but the manuscript must include quantitative tables with exact metrics (e.g., PSNR, SSIM, or task-specific scores), dataset sizes, cross-validation details, and error bars. Without these, the superiority and low-data robustness claims cannot be verified and remain unsupported by the presented evidence.
minor comments (2)
- [Method section] Notation for the implicit function and embedding dimensions should be defined explicitly in the first equation or figure caption to avoid ambiguity when comparing to coordinate-based methods in related work.
- [Figures] Figure captions for qualitative results should state the exact resolution and magnification used for each example to support the resolution-agnostic claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments in detail below, providing clarifications and indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Method section] Method formulation (implicit function definition): The central modeling choice predicts each IHC/mIF pixel solely from a local H&E embedding plus explicit coordinates. This per-pixel formulation is load-bearing for the resolution-agnostic and structural-consistency claims, yet the manuscript provides no ablation or multi-scale analysis demonstrating that local neighborhood information suffices to capture larger-scale tissue architecture and long-range cellular interactions routinely used in IHC interpretation. If such context is required, the approach risks introducing inconsistencies that patch-based or hierarchical baselines avoid.
Authors: We appreciate the referee's point regarding the sufficiency of local neighborhood information. In IMPLICITSTAINER, the high-dimensional embedding is extracted from a local patch around each H&E pixel, and the neural implicit function (an MLP) processes this embedding along with normalized coordinates to predict the target pixel value. This design allows the model to learn complex mappings that implicitly capture contextual information through the network's depth and the coordinate conditioning, which provides positional awareness across the image. While the current manuscript focuses on demonstrating the overall performance, we acknowledge the value of explicit ablations. In the revised manuscript, we will add an ablation study varying the neighborhood size and comparing to multi-scale feature extraction to further validate that local context is adequate for the virtual staining tasks. revision: yes
-
Referee: [Results section] Results and evaluation: The abstract states SOTA performance across more than twenty baselines on IHC and mIF tasks, but the manuscript must include quantitative tables with exact metrics (e.g., PSNR, SSIM, or task-specific scores), dataset sizes, cross-validation details, and error bars. Without these, the superiority and low-data robustness claims cannot be verified and remain unsupported by the presented evidence.
Authors: We agree that comprehensive quantitative evaluation is crucial for substantiating the claims. The full manuscript includes tables reporting PSNR, SSIM, and other relevant metrics (such as perceptual scores where applicable) for over twenty baselines across multiple datasets for both IHC and mIF tasks. Dataset sizes and splits are described in the experimental setup section. To address the referee's concern and enhance verifiability, we will revise the results section to include explicit cross-validation details, report standard deviations as error bars from repeated experiments, and ensure all numerical values are clearly tabulated with references to the exact experimental protocols. revision: yes
Circularity Check
No significant circularity; modeling choice is self-contained
full rationale
The paper introduces IMPLICITSTAINER as a reformulation of virtual staining into a continuous pixel-level mapping via neural implicit functions, where each IHC pixel is predicted from an H&E pixel embedding plus local neighborhood and explicit coordinates. This is presented as an explicit architectural decision contrasting with patch-based GAN/diffusion methods, without any derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations to prior uniqueness theorems. No equations or steps reduce the claimed outputs to inputs by construction; performance claims rest on empirical baselines rather than internal redefinition. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each target-domain (IHC) pixel is predicted from a high-dimensional embedding of the corresponding source-domain H&E pixel, its local spatial neighborhood, and explicit coordinate information.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IMPLICITSTAINER enables resolution-agnostic inference... by reformulating virtual staining as a continuous pixel-level translation problem.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Utilization and utility of immuno- histochemistry in dermatopathology,
K. A. Naert and M. J. Trotter, “Utilization and utility of immuno- histochemistry in dermatopathology,”The American Journal of Der- matopathology, vol. 35, no. 1, pp. 74–77, 2013
work page 2013
-
[2]
Immunohistochemistry for diagnosing melanoma in older adults,
K. Ojukwu, M. M. Eguchi, A. S. Adamson, K. F. Kerr, M. W. Piepkorn, S. Murdoch, R. L. Barnhill, D. E. Elder, S. R. Knezevich, and J. G. Elmore, “Immunohistochemistry for diagnosing melanoma in older adults,”JAMA dermatology, vol. 160, no. 4, pp. 434–440, 2024
work page 2024
-
[3]
S. Al Diffalha, M. Shaar, G. A. Barkan, E. M. Wojcik, M. M. Picken, and S. E. Pambuccian, “Immunohistochemistry in the workup of prostate biopsies: Frequency, variation and appropriateness of use among pathologists practicing at an academic center,”Annals of Diagnostic Pathology, vol. 27, pp. 34–42, 2017
work page 2017
-
[4]
X. Yang, B. Bai, Y . Zhang, M. Aydin, Y . Li, S. Y . Selcuk, P. Casteleiro Costa, Z. Guo, G. A. Fishbein, K. Atlan, et al., “Virtual birefringence imaging and histological staining of amyloid deposits in label-free tissue using autofluorescence microscopy and deep learning,” Nature Communications, vol. 15, no. 1, pp. 7978, 2024
work page 2024
-
[5]
Virtual stain transfer in histology via cascaded deep neural networks,
X. Yang, B. Bai, Y . Zhang, Y . Li, K. De Haan, T. Liu, and A. Ozcan, “Virtual stain transfer in histology via cascaded deep neural networks,” ACS Photonics, vol. 9, no. 9, pp. 3134–3143, 2022
work page 2022
-
[6]
M. Gadermayr, V . Appel, B. M. Klinkhammer, P. Boor, and D. Merhof, “Which way round? a study on the performance of stain-translation for segmenting arbitrarily dyed histological images,” inInternational Conference on Medical Image Computing and Computer-Assisted Inter- vention. Springer, 2018, pp. 165–173
work page 2018
-
[7]
Automating ground truth annotations for gland segmentation through immunohistochemistry,
T. Kataria, S. Rajamani, A. B. Ayubi, M. Bronner, J. Jedrzkiewicz, B. S. Knudsen, and S. Y . Elhabian, “Automating ground truth annotations for gland segmentation through immunohistochemistry,”Modern Pathology, vol. 36, no. 12, pp. 100331, 2023
work page 2023
-
[8]
Structural cycle gan for virtual immunohistochemistry staining of gland markers in the colon,
S. Dubey, T. Kataria, B. Knudsen, and S. Y . Elhabian, “Structural cycle gan for virtual immunohistochemistry staining of gland markers in the colon,” inInternational Workshop on Machine Learning in Medical Imaging. Springer, 2023, pp. 447–456
work page 2023
-
[9]
Staindiffuser: mul- titask dual diffusion model for virtual staining,
T. Kataria, B. Knudsen, and S. Y . Elhabian, “Staindiffuser: mul- titask dual diffusion model for virtual staining,”arXiv preprint arXiv:2403.11340, 2024
-
[10]
Bci: Breast cancer immunohistochemical image generation through pyramid pix2pix,
S. Liu, C. Zhu, F. Xu, X. Jia, Z. Shi, and M. Jin, “Bci: Breast cancer immunohistochemical image generation through pyramid pix2pix,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1815–1824
work page 2022
-
[11]
F. Li, Z. Hu, W. Chen, and A. Kak, “Adaptive supervised patchnce loss for learning h&e-to-ihc stain translation with inconsistent groundtruth image pairs,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 632–641
work page 2023
-
[12]
Mcs- stain: Boosting ffpe-to-he virtual staining with multiple cell semantics,
Y . Hu, Z. Du, W. Lin, S. Yang, L. Yu, G. Zhang, and L. Wang, “Mcs- stain: Boosting ffpe-to-he virtual staining with multiple cell semantics,” IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[13]
C. Bian, B. Philips, T. Cootes, and M. Fergie, “Hemit: H&e to multiplex- immunohistochemistry image translation with dual-branch pix2pix gen- erator,”arXiv preprint arXiv:2403.18501, 2024
-
[14]
Rosie: Ai gen- eration of multiplex immunofluorescence staining from histopathology images,
E. Wu, M. Bieniosek, Z. Wu, N. Thakkar, G. W. Charville, A. Makky, C. M. Sch ¨urch, J. R. Huyghe, U. Peters, C. I. Li, et al., “Rosie: Ai gen- eration of multiplex immunofluorescence staining from histopathology images,”Nature Communications, vol. 16, no. 1, pp. 7633, 2025
work page 2025
-
[15]
The cost-effectiveness of immunohistochemistry,
S. S. Raab, “The cost-effectiveness of immunohistochemistry,”Archives of Pathology & Laboratory Medicine, vol. 124, no. 8, pp. 1185–1191, 2000
work page 2000
-
[16]
S. Dubey, Y . Chong, B. Knudsen, and S. Y . Elhabian, “Vims: Virtual im- munohistochemistry multiplex staining via text-to-stain diffusion trained on uniplex stains,” inInternational Workshop on Machine Learning in Medical Imaging. Springer, 2024, pp. 143–155
work page 2024
-
[17]
Convergence of gans training: A game and stochastic control methodology,
O. Mounjid and X. Guo, “Convergence of gans training: A game and stochastic control methodology,”arXiv preprint arXiv:2112.00222, 2021
-
[18]
Bbdm: Image-to-image translation with brownian bridge diffusion models,
B. Li, K. Xue, B. Liu, and Y .-K. Lai, “Bbdm: Image-to-image translation with brownian bridge diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, 2023, pp. 1952–1961
work page 2023
-
[19]
Diffusion models: A comprehensive survey of methods and applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,”ACM Computing Surveys, vol. 56, no. 4, pp. 1–39, 2023
work page 2023
-
[20]
T. Kataria, S. Dubey, M. Bronner, J. Jedrzkiewicz, B. J. Brintz, S. Y . Elhabian, and B. S. Knudsen, “Building trust in virtual immunohis- 10 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. XX, NO. XX, XXXX 2025 tochemistry: Automated assessment of image quality,”arXiv preprint arXiv:2511.04615, 2025
-
[21]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232
work page 2017
-
[22]
Unit: Multimodal multitask learning with a unified transformer,
R. Hu and A. Singh, “Unit: Multimodal multitask learning with a unified transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1439–1449
work page 2021
-
[23]
J. Kim, “U-gat-it: unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation,” arXiv preprint arXiv:1907.10830, 2019
-
[24]
Stegogan: Leveraging steganography for non-bijective image-to-image translation,
S. Wu, Y . Chen, S. Mermet, L. Hurni, K. Schindler, N. Gonthier, and L. Landrieu, “Stegogan: Leveraging steganography for non-bijective image-to-image translation,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 7922–7931
work page 2024
-
[25]
CycleGAN, a Master of Steganography
C. Chu, A. Zhmoginov, and M. Sandler, “Cyclegan, a master of steganography,”arXiv preprint arXiv:1712.02950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Seeing what a gan cannot generate,
D. Bau, J.-Y . Zhu, J. Wulff, W. Peebles, H. Strobelt, B. Zhou, and A. Torralba, “Seeing what a gan cannot generate,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4502–4511
work page 2019
-
[27]
Training generative adversarial networks with limited data,
T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, “Training generative adversarial networks with limited data,”Advances in neural information processing systems, vol. 33, pp. 12104–12114, 2020
work page 2020
-
[28]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
work page 2021
-
[29]
Tack- ling the generative learning trilemma with denoising diffu- sion gans
Z. Xiao, K. Kreis, and A. Vahdat, “Tackling the generative learning trilemma with denoising diffusion gans,”arXiv preprint arXiv:2112.07804, 2021
-
[30]
Combating mode collapse in gan training: An empirical analysis using hessian eigenvalues,
R. Durall, A. Chatzimichailidis, P. Labus, and J. Keuper, “Combating mode collapse in gan training: An empirical analysis using hessian eigenvalues,”arXiv preprint arXiv:2012.09673, 2020
-
[31]
Catastrophic forgetting and mode collapse in gans,
H. Thanh-Tung and T. Tran, “Catastrophic forgetting and mode collapse in gans,” in2020 international joint conference on neural networks (ijcnn). IEEE, 2020, pp. 1–10
work page 2020
-
[32]
Bias and generalization in deep generative models: An empirical study,
S. Zhao, H. Ren, A. Yuan, J. Song, N. Goodman, and S. Ermon, “Bias and generalization in deep generative models: An empirical study,” Advances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[33]
Diversity-Sensitive Conditional Generative Adversarial Networks
D. Yang, S. Hong, Y . Jang, T. Zhao, and H. Lee, “Diversity- sensitive conditional generative adversarial networks,”arXiv preprint arXiv:1901.09024, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[34]
Tackling structural hallucination in image translation with local diffusion,
S. Kim, C. Jin, T. Diethe, M. Figini, H. F. Tregidgo, A. Mullokandov, P. Teare, and D. C. Alexander, “Tackling structural hallucination in image translation with local diffusion,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 87–103
work page 2024
-
[35]
Responsible diffusion: A comprehensive survey on safety, ethics, and trust in diffusion models,
K. Wei, X. Yuan, F. Huo, C. Ma, L. Yuan, S. Li, M. Ding, and D. Tao, “Responsible diffusion: A comprehensive survey on safety, ethics, and trust in diffusion models,”arXiv preprint arXiv:2509.22723, 2025
-
[36]
Mitigating hallucinations in diffusion models through adaptive attention modulation,
T. Oorloff, Y . Yacoob, and A. Shrivastava, “Mitigating hallucinations in diffusion models through adaptive attention modulation,”arXiv preprint arXiv:2502.16872, 2025
-
[37]
Y . Rivenson, T. Liu, Z. Wei, Y . Zhang, K. Haan, and A. Ozcan, “Phas- estain: the digital staining of label-free quantitative phase microscopy images using deep learning,”Light: Science & Applications, vol. 8, no. 1, pp. 23, 2019
work page 2019
-
[38]
Pasb: Pathology- aware schr ¨odinger bridge for virtual immunohistochemical staining,
F. Qiu, Y . Zhang, Z.-L. Huang, X. Zhu, and Z. Wang, “Pasb: Pathology- aware schr ¨odinger bridge for virtual immunohistochemical staining,” Medical Image Analysis, p. 103869, 2025
work page 2025
-
[39]
K. B. Ozyoruk, S. Can, B. Darbaz, K. Bas ¸ak, D. Demir, G. I. Gokceler, G. Serin, U. P. Hacisalihoglu, E. Kurtulus ¸, M. Y . Lu, et al., “A deep- learning model for transforming the style of tissue images from cryosec- tioned to formalin-fixed and paraffin-embedded,”Nature Biomedical Engineering, vol. 6, no. 12, pp. 1407–1419, 2022
work page 2022
-
[40]
M. M. Ho, S. Dubey, Y . Chong, B. Knudsen, and T. Tasdizen, “F2fldm: Latent diffusion models with histopathology pre-trained em- beddings for unpaired frozen section to ffpe translation,”arXiv preprint arXiv:2404.12650, 2024
-
[41]
M. M. Ho, E. Ghelichkhan, Y . Chong, Y . Zhou, B. Knudsen, and T. Tasdizen, “Disc: latent diffusion models with self-distillation from separated conditions for prostate cancer grading,” in2024 IEEE International Symposium on Biomedical Imaging (ISBI). IEEE, 2024, pp. 1–5
work page 2024
-
[42]
H&e to ihc virtual staining methods in breast cancer: an overview and benchmarking,
P. Kl ¨ockner, J. Teixeira, D. Montezuma, J. Fraga, H. M. Horlings, J. S. Cardoso, and S. P. Oliveira, “H&e to ihc virtual staining methods in breast cancer: an overview and benchmarking,”npj Digital Medicine, vol. 8, no. 1, pp. 384, 2025
work page 2025
-
[43]
Advancing h&e-to-ihc virtual staining with task- specific domain knowledge for her2 scoring,
Q. Peng, W. Lin, Y . Hu, A. Bao, C. Lian, W. Wei, M. Yue, J. Liu, L. Yu, and L. Wang, “Advancing h&e-to-ihc virtual staining with task- specific domain knowledge for her2 scoring,” inInternational Confer- ence on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 3–13
work page 2024
-
[44]
H. Dieckhaus, R. Meijboom, S. Okar, T. Wu, P. Parvathaneni, Y . Mina, S. Chandran, A. D. Waldman, D. S. Reich, and G. Nair, “Logistic regression–based model is more efficient than u-net model for reliable whole brain magnetic resonance imaging segmentation,”Topics in Magnetic Resonance Imaging, vol. 31, no. 3, pp. 31–39, 2022
work page 2022
-
[45]
Spatially-adaptive pixelwise networks for fast image translation,
T. R. Shaham, M. Gharbi, R. Zhang, E. Shechtman, and T. Michaeli, “Spatially-adaptive pixelwise networks for fast image translation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14882–14891
work page 2021
-
[46]
Scene representation networks: Continuous 3d-structure-aware neural scene representations,
V . Sitzmann, M. Zollh ¨ofer, and G. Wetzstein, “Scene representation networks: Continuous 3d-structure-aware neural scene representations,” Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[47]
Neuralmesh- ing: Differentiable meshing of implicit neural representations,
M. Vetsch, S. Lombardi, M. Pollefeys, and M. R. Oswald, “Neuralmesh- ing: Differentiable meshing of implicit neural representations,” inDAGM German Conference on Pattern Recognition. Springer, 2022, pp. 317– 333
work page 2022
-
[48]
Neural implicit embedding for point cloud analysis,
K. Fujiwara and T. Hashimoto, “Neural implicit embedding for point cloud analysis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11734–11743
work page 2020
-
[49]
Implicit neural representations with periodic activation functions,
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” Advances in neural information processing systems, vol. 33, pp. 7462– 7473, 2020
work page 2020
-
[50]
Occupancy networks: Learning 3d reconstruction in function space,
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin, and A. Geiger, “Occupancy networks: Learning 3d reconstruction in function space,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4460–4470
work page 2019
-
[51]
Z. Wang, P. Wang, Q. Dong, J. Gao, S. Chen, S. Xin, and C. Tu, “Neural- imls: learning implicit moving least-squares for surface reconstruction from unoriented point clouds,”arXiv preprint arXiv:2109.04398, vol. 1, no. 2, pp. 3, 2021
-
[52]
Surface reconstruction from point clouds: A survey and a benchmark,
Z. Huang, Y . Wen, Z. Wang, J. Ren, and K. Jia, “Surface reconstruction from point clouds: A survey and a benchmark,”IEEE transactions on pattern analysis and machine intelligence, 2024
work page 2024
-
[53]
Deepsdf: Learning continuous signed distance functions for shape rep- resentation,
J. J. Park, P. Florence, J. Straub, R. Newcombe, and S. Lovegrove, “Deepsdf: Learning continuous signed distance functions for shape rep- resentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 165–174
work page 2019
-
[54]
Learning continuous image representa- tion with local implicit image function,
Y . Chen, S. Liu, and X. Wang, “Learning continuous image representa- tion with local implicit image function,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8628– 8638
work page 2021
-
[55]
X. Shen, Y . Wang, S. Zheng, K. Xiao, W. Yang, and X. Wang, “Fast omni-directional image super-resolution: Adapting the implicit image function with pixel and semantic-wise spherical geometric priors,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2025, vol. 39, pp. 6833–6841
work page 2025
-
[56]
Image generators with conditionally-independent pixel synthesis,
I. Anokhin, K. Demochkin, T. Khakhulin, G. Sterkin, V . Lempitsky, and D. Korzhenkov, “Image generators with conditionally-independent pixel synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14278–14287
work page 2021
-
[57]
Perceptual losses for real-time style transfer and super-resolution,
J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” inComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11- 14, 2016, Proceedings, Part II 14. Springer, 2016, pp. 694–711
work page 2016
-
[58]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
work page 2018
-
[59]
Esrgan: Enhanced super-resolution generative adversar- ial networks,
X. Wang, K. Yu, S. Wu, J. Gu, Y . Liu, C. Dong, Y . Qiao, and C. Change Loy, “Esrgan: Enhanced super-resolution generative adversar- ial networks,” inProceedings of the European conference on computer vision (ECCV) workshops, 2018, pp. 0–0
work page 2018
-
[60]
Contrastive learning for unpaired image-to-image translation,
T. Park, A. A. Efros, R. Zhang, and J.-Y . Zhu, “Contrastive learning for unpaired image-to-image translation,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16. Springer, 2020, pp. 319–345
work page 2020
-
[61]
Vector quantized image-to-image translation,
Y .-J. Chen, S.-I. Cheng, W.-C. Chiu, H.-Y . Tseng, and H.-Y . Lee, “Vector quantized image-to-image translation,” inEuropean Conference on Computer Vision (ECCV), 2022. KATARIAet al.: PREPARATION OF PAPERS FOR IEEE TRANSACTIONS ON MEDICAL IMAGING 11
work page 2022
-
[62]
Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation,
D. Torbunov, Y . Huang, H. Yu, J. Huang, S. Yoo, M. Lin, B. Viren, and Y . Ren, “Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 702– 712
work page 2023
-
[63]
H. Tang, H. Liu, D. Xu, P. H. Torr, and N. Sebe, “Attentiongan: Unpaired image-to-image translation using attention-guided generative adversarial networks,”IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2021
work page 2021
-
[64]
Qs-attn: Query-selected attention for contrastive learning in i2i translation,
X. Hu, X. Zhou, Q. Huang, Z. Shi, L. Sun, and Q. Li, “Qs-attn: Query-selected attention for contrastive learning in i2i translation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18291–18300
work page 2022
-
[65]
Reusing discrimi- nators for encoding: Towards unsupervised image-to-image translation,
R. Chen, W. Huang, B. Huang, F. Sun, and B. Fang, “Reusing discrimi- nators for encoding: Towards unsupervised image-to-image translation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[66]
Unsupervised image-to-image translation with density changing regularization,
S. Xie, Q. Ho, and K. Zhang, “Unsupervised image-to-image translation with density changing regularization,” inAdvances in Neural Informa- tion Processing Systems, 2022
work page 2022
-
[67]
Unpaired image-to-image translation via neu- ral schr\” odinger bridge
B. Kim, G. Kwon, K. Kim, and J. C. Ye, “Unpaired image-to- image translation via neural schr\” odinger bridge,”arXiv preprint arXiv:2305.15086, 2023
-
[68]
Image-to-image translation with conditional adversarial networks,
P. Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125– 1134
work page 2017
-
[69]
Unsupervised image-to-image translation networks,
M.-Y . Liu, T. Breuel, and J. Kautz, “Unsupervised image-to-image translation networks,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[70]
Unpaired image-to-image translation us- ing adversarial consistency loss,
Y . Zhao, R. Wu, and H. Dong, “Unpaired image-to-image translation us- ing adversarial consistency loss,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16. Springer, 2020, pp. 800–815
work page 2020
-
[71]
Unpaired image-to-image translation with shortest path regularization,
S. Xie, Y . Xu, M. Gong, and K. Zhang, “Unpaired image-to-image translation with shortest path regularization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10177–10187
work page 2023
-
[72]
Egsde: Unpaired image-to- image translation via energy-guided stochastic differential equations,
M. Zhao, F. Bao, C. Li, and J. Zhu, “Egsde: Unpaired image-to- image translation via energy-guided stochastic differential equations,” Advances in Neural Information Processing Systems, vol. 35, pp. 3609– 3623, 2022
work page 2022
-
[73]
C. H. Wu and F. Torre, “Unifying diffusion models’ latent space, with applications to cyclediffusion and guidance,”arXiv preprint arXiv:2210.05559, 2022. KATARIAet al.: PREPARATION OF PAPERS FOR IEEE TRANSACTIONS ON MEDICAL IMAGING 1 SUPPLEMENTARYMATERIAL A. Additional Ablation Experiments λValue Ablation.In the experimental stage, we investigated whether...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.