Exploring Nonlinear Pathway in Parameter Space for Machine Unlearning
Pith reviewed 2026-05-22 15:22 UTC · model grok-4.3
The pith
Mode connectivity finds nonlinear paths in parameter space that improve machine unlearning over linear updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By employing mode connectivity, MCU identifies nonlinear pathways in parameter space that sidestep the weight entanglement of linear task arithmetic, and when augmented with a parameter mask and adaptive penalty adjustment, it delivers stronger forgetting performance, lower overhead, and a continuum of unlearning solutions rather than a single model.
What carries the argument
Mode connectivity, which locates continuous low-loss paths connecting different parameter configurations to define a nonlinear unlearning trajectory.
Load-bearing premise
Mode connectivity in the loss landscape reliably supplies a nonlinear pathway that avoids weight entanglement and outperforms linear task arithmetic for unlearning.
What would settle it
An experiment in which a simple linear update achieves equal or higher forgetting metrics and retained accuracy than MCU on the same image-classification benchmarks would disprove the claimed advantage.
Figures



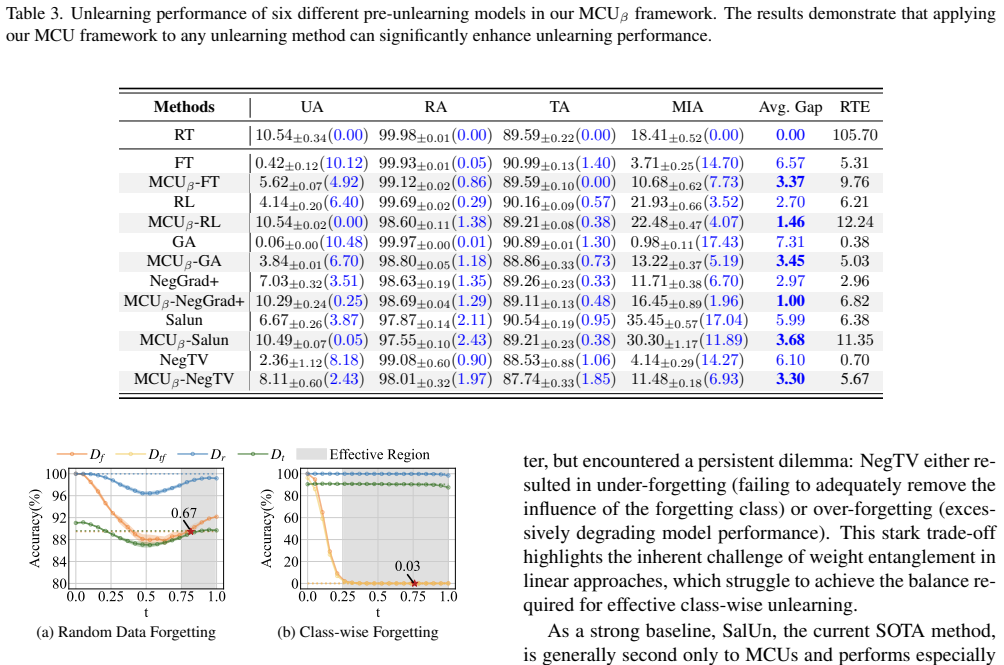
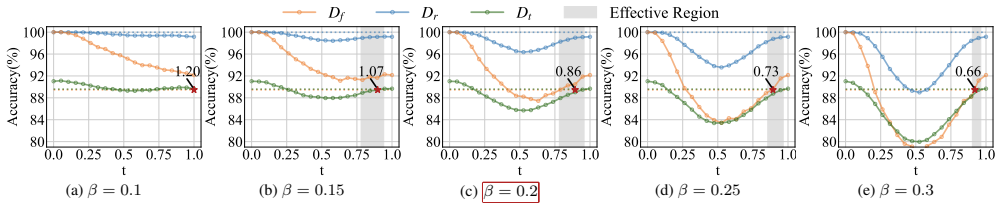
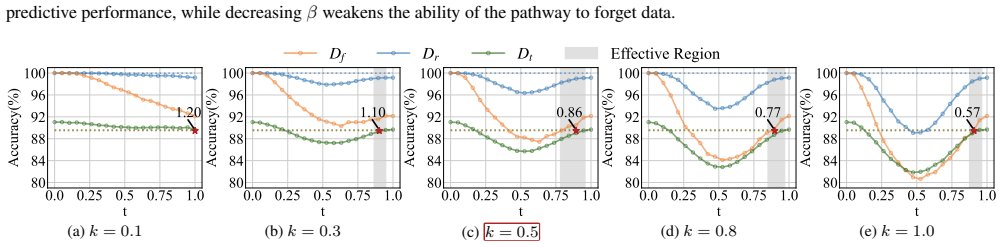



read the original abstract
Machine Unlearning (MU) aims to remove the information of specific training data from a trained model, ensuring compliance with privacy regulations and user requests. While one line of existing MU methods relies on linear parameter updates via task arithmetic, they suffer from weight entanglement. In this work, we propose a novel MU framework called Mode Connectivity Unlearning (MCU) that leverages mode connectivity to find an unlearning pathway in a nonlinear manner. To further enhance performance and efficiency, we introduce a parameter mask strategy that not only improves unlearning effectiveness but also reduces computational overhead. Moreover, we propose an adaptive adjustment strategy for our unlearning penalty coefficient to adaptively balance forgetting quality and predictive performance during training, eliminating the need for empirical hyperparameter tuning. Unlike traditional MU methods that identify only a single unlearning model, MCU uncovers a spectrum of unlearning models along the pathway. Overall, MCU serves as a plug-and-play framework that seamlessly integrates with any existing MU methods, consistently improving unlearning efficacy. Extensive experiments on the image classification task demonstrate that MCU achieves superior performance. The codes are available at https://github.com/TIML-Group/Mode-Connectivity-Unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mode Connectivity Unlearning (MCU), a framework that uses mode connectivity to discover nonlinear pathways in parameter space for machine unlearning. It augments this with a parameter mask strategy to improve forgetting while reducing overhead and an adaptive adjustment mechanism for the unlearning penalty coefficient that eliminates manual hyperparameter tuning. The approach is presented as plug-and-play, integrable with arbitrary existing MU methods, and capable of producing a spectrum of unlearning models along the connectivity path rather than a single point. Experiments on image classification tasks are claimed to show superior unlearning efficacy compared to prior linear task-arithmetic baselines.
Significance. If the experimental outcomes and the claimed generality hold, the work would provide a practical mechanism for enhancing a broad class of machine unlearning algorithms by exploiting nonlinear low-loss curves instead of linear interpolations, potentially mitigating weight entanglement while preserving retain-set performance. The open release of code is a clear strength for reproducibility.
major comments (2)
- [§3] §3 (Method), mode-connectivity construction: the central claim that the discovered nonlinear path selectively suppresses forget-set influence while avoiding new entanglements rests on the premise that the path is shaped by the unlearning objective; however, if the connectivity search follows the standard low-loss curve procedure without explicit unlearning-aware regularization along the path, the reported gains could be attributable to the added mask or adaptive penalty rather than nonlinearity itself. A direct ablation comparing the full MCU path against linear interpolation on the identical loss landscape is required to isolate the contribution.
- [§4] §4 (Experiments) and abstract: the assertion that MCU 'consistently improving unlearning efficacy' and 'achieves superior performance' on image classification is load-bearing for the plug-and-play claim, yet the manuscript provides no quantitative tables, error bars, or statistical significance tests for the improvement over base MU methods; without these, the generality across arbitrary base methods cannot be evaluated.
minor comments (2)
- [§3.1] Notation for the adaptive coefficient and mask should be introduced with explicit equations rather than descriptive text to improve traceability.
- [§4] The spectrum of models along the path is an interesting feature; a figure showing retain/forget metrics as a function of path parameter would clarify the practical utility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify the contributions and strengthen the presentation of our work on Mode Connectivity Unlearning (MCU). We address each major comment point by point below, providing clarifications based on the manuscript and outlining revisions where appropriate to better support our claims.
read point-by-point responses
-
Referee: [§3] §3 (Method), mode-connectivity construction: the central claim that the discovered nonlinear path selectively suppresses forget-set influence while avoiding new entanglements rests on the premise that the path is shaped by the unlearning objective; however, if the connectivity search follows the standard low-loss curve procedure without explicit unlearning-aware regularization along the path, the reported gains could be attributable to the added mask or adaptive penalty rather than nonlinearity itself. A direct ablation comparing the full MCU path against linear interpolation on the identical loss landscape is required to isolate the contribution.
Authors: We appreciate this precise observation on the construction of the connectivity path. In the MCU framework, the nonlinear pathway is discovered by optimizing a composite objective that explicitly includes the unlearning loss terms (forget-set suppression combined with retain-set preservation), the parameter mask, and the adaptive penalty coefficient. This formulation ensures the path search is guided by the unlearning objective rather than following a purely standard low-loss curve between arbitrary minima. That said, we agree that an explicit ablation isolating the nonlinearity—by comparing the full MCU nonlinear path against linear interpolation performed on the identical loss landscape—is the cleanest way to attribute gains specifically to the nonlinear structure. We have performed this ablation study and will incorporate the results, along with a clearer description of the unlearning-aware objective, into the revised manuscript. revision: yes
-
Referee: [§4] §4 (Experiments) and abstract: the assertion that MCU 'consistently improving unlearning efficacy' and 'achieves superior performance' on image classification is load-bearing for the plug-and-play claim, yet the manuscript provides no quantitative tables, error bars, or statistical significance tests for the improvement over base MU methods; without these, the generality across arbitrary base methods cannot be evaluated.
Authors: We acknowledge that the current experimental section relies primarily on figures to illustrate performance trends and that this is insufficient to rigorously substantiate the claims of consistent improvement and plug-and-play generality. To address this, the revised manuscript will include comprehensive quantitative tables reporting mean metrics (e.g., forget accuracy, retain accuracy) with standard deviations computed over multiple independent runs, as well as statistical significance tests (such as paired t-tests with p-values) comparing MCU-augmented variants against their base MU methods across different unlearning techniques and datasets. These additions will directly support the generality claim and allow readers to evaluate the magnitude and reliability of the reported gains. revision: yes
Circularity Check
No circularity: MCU components are independently defined and externally evaluated
full rationale
The derivation introduces mode connectivity for a nonlinear pathway, a parameter mask, and an adaptive penalty coefficient as distinct additions to existing MU methods. These are motivated by standard mode-connectivity literature and evaluated via external benchmarks on image classification tasks rather than being defined in terms of the target unlearning metrics themselves. No equation reduces a reported improvement to a fitted input or self-citation chain; the plug-and-play claim rests on empirical integration results, not tautological construction. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- unlearning penalty coefficient
axioms (1)
- domain assumption Mode connectivity exists between the original model and an unlearned model in the parameter space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we leverage a quadratic Bézier curve ϕ_θc(t) = (1−t)²θ_o + 2(1−t)t θ_c + t² θ_p … L_mcu = E_t∼U(0,1)[L(Dr;ϕ_θc(t))−β·L(Df;ϕ_θc(t))]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
parameter mask … mi_r = 0{∥∇_θi_o L(Dr;θ_o)∥2 / |θi_o| > γ_kr}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning to un- learn: Instance-wise unlearning for pre-trained classi- fiers
Sungmin Cha, Sungjun Cho, Dasol Hwang, Honglak Lee, Taesup Moon, and Moontae Lee. Learning to un- learn: Instance-wise unlearning for pre-trained classi- fiers. InProceedings of the AAAI conference on artifi- cial intelligence, pages 11186–11194, 2024. 2
work page 2024
-
[2]
When machine unlearning jeopardizes privacy
Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. When machine unlearning jeopardizes privacy. InProceed- ings of the 2021 ACM SIGSAC conference on com- puter and communications security, pages 896–911,
work page 2021
-
[3]
Can bad teaching induce forgetting? unlearning in deep networks using an in- competent teacher
Vikram S Chundawat, Ayush K Tarun, Murari Man- dal, and Mohan Kankanhalli. Can bad teaching induce forgetting? unlearning in deep networks using an in- competent teacher. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 7210–7217,
-
[4]
Vikram S Chundawat, Ayush K Tarun, Murari Man- dal, and Mohan Kankanhalli. Zero-shot machine un- learning.IEEE Transactions on Information Forensics and Security, 18:2345–2354, 2023. 2
work page 2023
-
[5]
Essentially no barriers in neural network energy landscape
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. InInternational confer- ence on machine learning, pages 1309–1318. PMLR,
-
[6]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empow- ering machine unlearning via gradient-based weight saliency in both image classification and generation. arXiv preprint arXiv:2310.12508, 2023. 1, 2, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Fast machine unlearning without retraining through selective synaptic dampening
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Fast machine unlearning without retraining through selective synaptic dampening. InProceedings of the AAAI Conference on Artificial Intelligence, pages 12043–12051, 2024. 2, 4 9
work page 2024
-
[8]
Loss sur- faces, mode connectivity, and fast ensembling of dnns
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss sur- faces, mode connectivity, and fast ensembling of dnns. Advances in neural information processing systems, 31, 2018. 1, 2, 3, 5
work page 2018
-
[9]
Loss sur- faces, mode connectivity, and fast ensembling of dnns
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss sur- faces, mode connectivity, and fast ensembling of dnns. Advances in neural information processing systems, 31, 2018. 3
work page 2018
-
[10]
Towards adversarial evaluations for inexact machine unlearning.arXiv preprint arXiv:2201.06640, 2022
Shashwat Goel, Ameya Prabhu, Amartya Sanyal, Ser-Nam Lim, Philip Torr, and Ponnurangam Kumaraguru. Towards adversarial evaluations for inexact machine unlearning.arXiv preprint arXiv:2201.06640, 2022. 2
-
[11]
Eternal sunshine of the spotless net: Selec- tive forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selec- tive forgetting in deep networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 9304–9312, 2020. 2
work page 2020
-
[12]
Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amnesiac machine learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11516–11524, 2021. 1, 2, 5
work page 2021
-
[13]
Certified data removal from machine learning models.arXiv preprint arXiv:1911.03030, 2019
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data removal from machine learning models.arXiv preprint arXiv:1911.03030, 2019. 2
-
[14]
Tight bounds for machine unlearning via differential privacy.arXiv preprint arXiv:2309.00886, 2023
Yiyang Huang and Cl ´ement L Canonne. Tight bounds for machine unlearning via differential privacy.arXiv preprint arXiv:2309.00886, 2023. 2
-
[15]
Zhehao Huang, Xinwen Cheng, JingHao Zheng, Hao- ran Wang, Zhengbao He, Tao Li, and Xiaolin Huang. Unified gradient-based machine unlearning with re- main geometry enhancement.Advances in Neu- ral Information Processing Systems, 37:26377–26414,
-
[16]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Worts- man, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Efficient model editing with task-localized sparse fine-tuning
Leonardo Iurada, Marco Ciccone, Tatiana Tommasi, et al. Efficient model editing with task-localized sparse fine-tuning. InLEARNING REPRESEN- TATIONS. INTERNATIONAL CONFERENCE. 13TH 2025.(ICLR 2025). ICLR, 2025. 1
work page 2025
-
[18]
Machine unlearning in learned databases: An experimental analysis.Proc
Meghdad Kurmanji, Eleni Triantafillou, and Peter Tri- antafillou. Machine unlearning in learned databases: An experimental analysis.Proc. ACM Manag. Data, 2(1), 2024. 1, 2, 3, 4, 5
work page 2024
-
[19]
Towards unbounded machine unlearning.Advances in neural information process- ing systems, 36, 2024
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou. Towards unbounded machine unlearning.Advances in neural information process- ing systems, 36, 2024. 2
work page 2024
-
[20]
Unlearning with fisher masking.arXiv preprint arXiv:2310.05331, 2023
Yufang Liu, Changzhi Sun, Yuanbin Wu, and Aimin Zhou. Unlearning with fisher masking.arXiv preprint arXiv:2310.05331, 2023. 2
-
[21]
Paul Micaelli and Amos J Storkey. Zero-shot knowl- edge transfer via adversarial belief matching.Ad- vances in Neural Information Processing Systems, 32,
-
[22]
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36, 2024. 1, 2
work page 2024
-
[23]
Revisiting mode connectivity in neural networks with bezier sur- face
Jie Ren, Pin-Yu Chen, and Ren Wang. Revisiting mode connectivity in neural networks with bezier sur- face. InThe Thirteenth International Conference on Learning Representations. 2
-
[24]
Tackling Fake Forgetting through Uncertainty Quantification
Yingdan Shi and Ren Wang. Redefining machine un- learning: A conformal prediction-motivated approach. arXiv preprint arXiv:2501.19403, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Ayush K Tarun, Vikram S Chundawat, Murari Man- dal, and Mohan Kankanhalli. Fast yet effective ma- chine unlearning.IEEE Transactions on Neural Net- works and Learning Systems, 2023
work page 2023
-
[26]
Unrolling sgd: Understand- ing factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understand- ing factors influencing machine unlearning. In2022 IEEE 7th European Symposium on Security and Pri- vacy (EuroS&P), pages 303–319. IEEE, 2022. 1, 2, 5
work page 2022
-
[27]
Machine unlearning of features and labels.arXiv preprint arXiv:2108.11577,
Alexander Warnecke, Lukas Pirch, Christian Wress- negger, and Konrad Rieck. Machine unlearning of features and labels.arXiv preprint arXiv:2108.11577,
-
[28]
Shaokui Wei, Mingda Zhang, Hongyuan Zha, and Baoyuan Wu. Shared adversarial unlearning: Back- door mitigation by unlearning shared adversarial ex- amples.Advances in Neural Information Processing Systems, 36:25876–25909, 2023. 2 10 MCU: Improving Machine Unlearning through Mode Connectivity Appendix A. Weight Entanglement in Linear MU Method In this secti...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.