Frozen Backpropagation: Relaxing Weight Symmetry in Deep Spiking Neural Networks
Pith reviewed 2026-05-22 13:48 UTC · model grok-4.3
The pith
Frozen Backpropagation relaxes weight symmetry in deep spiking neural networks by periodically freezing feedback weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
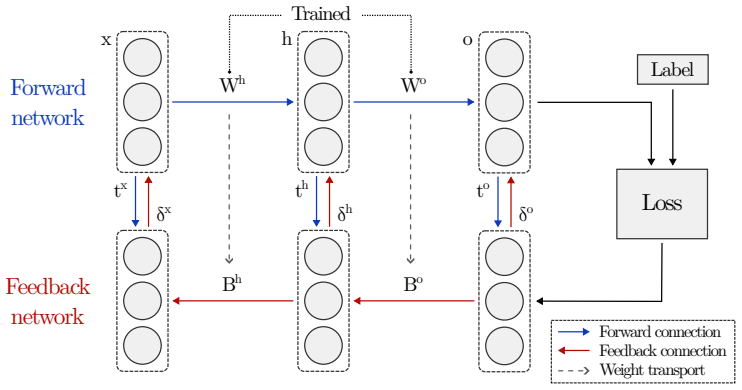
fBP updates forward weights by computing gradients with periodically frozen feedback weights in a setting with distinct forward and feedback networks. This reduces the frequency of weight transports and synchronization overhead during training. When combined with three partial weight transport schemes of varying complexity, transport costs drop by up to 10,000x relative to full transport, at the expense of moderate accuracy loss on image recognition benchmarks.
What carries the argument
Periodically frozen feedback weights that supply gradients for forward-weight updates in separate forward and feedback networks.
Load-bearing premise
Periodically freezing feedback weights for multiple steps still produces usable gradients for forward-weight updates without extra compensation mechanisms or major hyperparameter retuning.
What would settle it
Train an SNN with fBP on a standard image classification benchmark while increasing the number of steps between feedback-weight updates and check whether accuracy stays within a few percent of full backpropagation.
Figures


read the original abstract
Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware can greatly reduce energy costs compared to GPU-based training. However, implementing Backpropagation (BP) on such hardware is challenging because forward and backward passes are typically performed by separate networks with distinct weights. To compute correct gradients, forward and feedback weights must remain symmetric during training, necessitating weight transport between the two networks. This symmetry requirement imposes hardware overhead and increases energy costs. To address this issue, we introduce Frozen Backpropagation (\textsc{fBP}), a BP-based training algorithm relaxing weight symmetry in settings with separate networks. fBP updates forward weights by computing gradients with periodically frozen feedback weights, reducing weight transports during training and minimizing synchronization overhead. To further improve transport efficiency, we propose three partial weight transport schemes of varying computational complexity, where only a subset of weights is transported at a time. We evaluate our methods on image recognition tasks using both temporally and rate-coded SNNs, and compare them to existing approaches addressing the weight symmetry requirement. Our results show that fBP outperforms these methods and achieves accuracy comparable to BP while significantly lowering transport costs. With partial weight transport, fBP can further lower those costs by up to 10,000x at the expense of moderate accuracy loss. This work provides insights for guiding the design of neuromorphic hardware incorporating BP-based on-chip learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Frozen Backpropagation (fBP), a training algorithm for deep spiking neural networks that periodically freezes feedback weights to relax the strict symmetry requirement between forward and feedback networks during backpropagation. This reduces weight transport overhead in neuromorphic hardware settings. The authors further propose three partial weight transport variants and evaluate fBP against existing symmetry-relaxation methods on image classification tasks using both temporally coded and rate-coded SNNs, claiming comparable accuracy to standard BP with substantially lower transport costs (up to 10,000x reduction via partial transport at moderate accuracy cost).
Significance. If the empirical results prove robust, the work has moderate significance for neuromorphic hardware design: it offers a practical heuristic to lower synchronization energy costs while retaining BP-based training for SNNs. The partial-transport schemes provide tunable trade-offs that could inform on-chip learning architectures. However, the absence of statistical controls and sensitivity analysis on the core freezing mechanism limits the strength of the contribution.
major comments (2)
- [Experimental Results] Experimental Results section: the central empirical claims (outperformance over baselines and accuracy comparable to BP) are reported without error bars, number of independent runs, dataset sizes, or statistical significance tests. This directly affects assessment of whether the reported gains are reliable or sensitive to the choice of freeze interval K.
- [Method] Method section (fBP description): no analysis, bound, or ablation is provided on gradient alignment or error accumulation as forward weights continue to update while feedback weights remain frozen. The assumption that usable gradients persist over multiple steps without compensation or retuning is load-bearing for the claim that fBP requires no additional mechanisms, yet remains unverified beyond the reported experiments.
minor comments (2)
- [Abstract] The 10,000x transport-cost reduction figure in the abstract lacks a precise baseline comparison and conditions under which it is achieved.
- [Figures] Figure captions and diagrams illustrating the freeze schedule would benefit from explicit labeling of the forward-update steps versus transport events.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript introducing Frozen Backpropagation (fBP). We have addressed each of the major comments below and outline the revisions we intend to make to enhance the empirical robustness and methodological analysis of the work.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central empirical claims (outperformance over baselines and accuracy comparable to BP) are reported without error bars, number of independent runs, dataset sizes, or statistical significance tests. This directly affects assessment of whether the reported gains are reliable or sensitive to the choice of freeze interval K.
Authors: We agree that the reported results would be strengthened by including measures of variability and statistical analysis. In the revised manuscript we will report accuracies over multiple independent runs with error bars, explicitly state the number of runs and dataset sizes, and include statistical significance tests comparing fBP against baselines and standard BP. We will also add an ablation varying the freeze interval K to demonstrate sensitivity of accuracy and transport cost to this hyperparameter. revision: yes
-
Referee: [Method] Method section (fBP description): no analysis, bound, or ablation is provided on gradient alignment or error accumulation as forward weights continue to update while feedback weights remain frozen. The assumption that usable gradients persist over multiple steps without compensation or retuning is load-bearing for the claim that fBP requires no additional mechanisms, yet remains unverified beyond the reported experiments.
Authors: Our experiments across temporally and rate-coded SNNs on image classification tasks show that fBP achieves accuracy comparable to BP, indicating that gradients remain sufficiently aligned during frozen periods in practice. We acknowledge the value of additional verification. In the revision we will include an ablation measuring gradient alignment (e.g., cosine similarity) and error accumulation over varying freeze intervals, together with a discussion of these empirical observations. A formal theoretical bound on alignment is not provided in the current work. revision: partial
- Providing a rigorous theoretical bound on gradient alignment and error accumulation during frozen periods
Circularity Check
No circularity: empirical heuristic validated externally
full rationale
The paper introduces Frozen Backpropagation as a practical training heuristic for SNNs that periodically freezes feedback weights to reduce transport overhead. Performance is demonstrated via direct experiments on image tasks against external baselines (standard BP and prior symmetry-relaxation methods), with no equations, derivations, or self-citations that reduce accuracy/efficiency claims to quantities defined by the method's own fitted parameters or internal assumptions. The central results rest on empirical measurement rather than any self-definitional or fitted-input reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Correct gradients in BP require symmetric forward and feedback weights when networks are separate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FBP updates forward weights by computing gradients with periodically frozen feedback weights, reducing weight transports during training
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We benchmark sFA and SS for the first time in TTFS-based deep SNNs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Spiking Neural Networks and Their Applications: A Review
Kashu Yamazaki, Viet-Khoa V o-Ho, Darshan Bulsara, and Ngan Le. Spiking Neural Networks and Their Applications: A Review. MDPI Brain Sciences, 12(7), 2022
work page 2022
-
[2]
A Survey of Neuromorphic Computing and Neural Networks in Hardware
Catherine D. Schuman, Thomas E. Potok, Robert M. Patton, J. Douglas Birdwell, Mark E. Dean, Garrett S. Rose, and James S. Plank. A Survey of Neuromorphic Computing and Neural Networks in Hardware. arXiv, arXiv:1705.06963, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Benchmarking Keyword Spotting Efficiency on Neuromorphic Hardware
Peter Blouw, Xuan Choo, Eric Hunsberger, and Chris Eliasmith. Benchmarking Keyword Spotting Efficiency on Neuromorphic Hardware. In Neuro-Inspired Computational Elements Workshop, 2019
work page 2019
-
[4]
Benchmarking Deep Spiking Neural Networks on Neuromorphic Hardware
Christoph Ostrau, Jonas Homburg, Christian Klarhorst, Michael Thies, and Ulrich Rückert. Benchmarking Deep Spiking Neural Networks on Neuromorphic Hardware. In International Conference on Artificial Neural Networks, 2020
work page 2020
-
[5]
Advancing Neural Networks: Innovations and Impacts on Energy Consumption
Alina Fedorova, Nikola Joviši ´c, Jordi Vallverdù, Silvia Battistoni, Miloš Jovi ˇci´c, Milovan Medojevi´c, Alexander Toschev, Evgeniia Alshanskaia, Max Talanov, and Victor Erokhin. Advancing Neural Networks: Innovations and Impacts on Energy Consumption. Advanced Electronic Materials, 10(12), 2024
work page 2024
-
[6]
High-Performance Deep Spiking Neural Networks with 0.3 Spikes Per Neuron
Ana Stanojevic, Stanisław Wo´ zniak, Guillaume Bellec, Giovanni Cherubini, Angeliki Pantazi, and Wulfram Gerstner. High-Performance Deep Spiking Neural Networks with 0.3 Spikes Per Neuron. Nature Communications, 15(1), 2024
work page 2024
-
[7]
Jason K. Eshraghian, Max Ward, Emre O. Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D. Lu. Training Spiking Neural Networks Using Lessons from Deep Learning. Proceedings of the IEEE, 111(9), 2023
work page 2023
-
[8]
Spatio-Temporal Backpropagation for Training High-Performance Spiking Neural Networks
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-Temporal Backpropagation for Training High-Performance Spiking Neural Networks. Frontiers in Neuroscience, 12, 2018
work page 2018
-
[9]
SEENN: Towards Temporal Spiking Early Exit Neural Networks
Yuhang Li, Tamar Geller, Youngeun Kim, and Priyadarshini Panda. SEENN: Towards Temporal Spiking Early Exit Neural Networks. In Advances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[10]
A Solution to the Learning Dilemma for Recurrent Networks of Spiking Neurons
Guillaume Bellec, Franz Scherr, Anand Subramoney, Elias Hajek, Darjan Salaj, Robert Legen- stein, and Wolfgang Maass. A Solution to the Learning Dilemma for Recurrent Networks of Spiking Neurons. Nature Communications, 11(1), 2020
work page 2020
-
[11]
Analyzing Time- to-First-Spike Coding Schemes: A Theoretical Approach
Lina Bonilla, Jacques Gautrais, Simon Thorpe, and Timothée Masquelier. Analyzing Time- to-First-Spike Coding Schemes: A Theoretical Approach. Frontiers in Neuroscience, 16, 2022
work page 2022
-
[12]
Supervised Learning Based on Temporal Coding in Spiking Neural Networks
Hesham Mostafa. Supervised Learning Based on Temporal Coding in Spiking Neural Networks. IEEE Transactions on Neural Networks and Learning Systems, 29, 2018
work page 2018
-
[13]
Chandrasekaran, and Arindam Sanyal
Shibo Zhou, Xiaohua Li, Ying Chen, Sanjeev T. Chandrasekaran, and Arindam Sanyal. Temporal-Coded Deep Spiking Neural Network with Easy Training and Robust Performance. In AAAI Conference on Artificial Intelligence, volume 35, 2021. 10
work page 2021
-
[14]
Wenjie Wei, Malu Zhang, Hong Qu, Ammar Belatreche, Jian Zhang, and Hong Chen. Temporal- Coded Spiking Neural Networks with Dynamic Firing Threshold: Learning with Event-Driven Backpropagation. In International Conference on Computer Vision, 2023
work page 2023
-
[15]
T2FSNN: Deep Spiking Neural Networks with Time-to-First-Spike Coding
Seongsik Park, Seijoon Kim, Byunggook Na, and Sungroh Yoon. T2FSNN: Deep Spiking Neural Networks with Time-to-First-Spike Coding. In Design Automation Conference, 2020
work page 2020
-
[16]
Rufin Van Rullen and Simon J. Thorpe. Rate Coding Versus Temporal Order Coding: What the Retinal Ganglion Cells Tell the Visual Cortex. Neural Computation, 13(6), 2001
work page 2001
-
[17]
A Survey of Encoding Techniques for Signal Processing in Spiking Neural Networks
Daniel Auge, Julian Hille, Etienne Mueller, and Alois Knoll. A Survey of Encoding Techniques for Signal Processing in Spiking Neural Networks. Neural Processing Letters, 53(6), 2021
work page 2021
-
[18]
Event-Driven Random Back-Propagation: Enabling Neuromorphic Deep Learning Machines
Emre Neftci, Charles Augustine, Somnath Paul, and Georgios Detorakis. Event-Driven Random Back-Propagation: Enabling Neuromorphic Deep Learning Machines. Frontiers in Neuro- science, 11, 2017
work page 2017
-
[19]
Brain-Inspired Learning on Neuromorphic Substrates
Friedemann Zenke and Emre Neftci. Brain-Inspired Learning on Neuromorphic Substrates. Proceedings of the IEEE, 109(5), 2021
work page 2021
-
[20]
The Backpropagation Algorithm Implemented on Spiking Neuromorphic Hardware
Alpha Renner, Forrest Sheldon, Anatoly Zlotnik, Louis Tao, and Andrew Sornborger. The Backpropagation Algorithm Implemented on Spiking Neuromorphic Hardware. Nature Com- munications, 15, 2024
work page 2024
-
[21]
Competitive Learning: From Interactive Activation to Adaptive Resonance
Stephen Grossberg. Competitive Learning: From Interactive Activation to Adaptive Resonance. Cognitive Science, 11, 1987
work page 1987
-
[22]
Deep Learning without Weight Transport
Mohamed Akrout, Collin Wilson, Peter Humphreys, Timothy Lillicrap, and Douglas B Tweed. Deep Learning without Weight Transport. In Advances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[23]
Qianli Liao, Joel Leibo, and Tomaso Poggio. How Important Is Weight Symmetry in Backprop- agation? In AAAI Conference on Artificial Intelligence, volume 30, 2016
work page 2016
-
[24]
Two Routes to Scalable Credit Assignment without Weight Symmetry
Daniel Kunin, Aran Nayebi, Javier Sagastuy-Brena, Surya Ganguli, Jonathan Bloom, and Daniel Yamins. Two Routes to Scalable Credit Assignment without Weight Symmetry. InInternational Conference on Machine Learning, 2020
work page 2020
-
[25]
Local Learning in RRAM Neural Networks with Sparse Direct Feedback Alignment
Brian Crafton, Matt West, Padip Basnet, Eric V ogel, and Arijit Raychowdhury. Local Learning in RRAM Neural Networks with Sparse Direct Feedback Alignment. In International Symposium on Low Power Electronics and Design, 2019
work page 2019
-
[26]
Synaptic Plasticity Dynamics for Deep Continuous Local Learning (DECOLLE)
Jacques Kaiser, Hesham Mostafa, and Emre Neftci. Synaptic Plasticity Dynamics for Deep Continuous Local Learning (DECOLLE). Frontiers in Neuroscience, 14, 2020
work page 2020
-
[27]
Tuning Convolutional Spiking Neural Network with Biologically Plausible Reward Propagation
Tielin Zhang, Shuncheng Jia, Xiang Cheng, and Bo Xu. Tuning Convolutional Spiking Neural Network with Biologically Plausible Reward Propagation. IEEE Transactions on Neural Networks and Learning Systems, 33(12), 2021
work page 2021
-
[28]
Spike Time Displacement-Based Error Backpropagation in Convolutional Spiking Neural Networks
Maryam Mirsadeghi, Majid Shalchian, Saeed Reza Kheradpisheh, and Timothée Masquelier. Spike Time Displacement-Based Error Backpropagation in Convolutional Spiking Neural Networks. Neural Computing and Applications, 35(21), 2023
work page 2023
-
[29]
Neuronal Competition Groups with Supervised STDP for Spike-Based Classification
Gaspard Goupy, Pierre Tirilly, and Ioan Marius Bilasco. Neuronal Competition Groups with Supervised STDP for Spike-Based Classification. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[30]
Low-Variance Forward Gradients Using Direct Feedback Alignment and Momentum
Florian Bacho and Dominique Chu. Low-Variance Forward Gradients Using Direct Feedback Alignment and Momentum. Neural Networks, 169, 2024
work page 2024
-
[31]
Lillicrap, Daniel Cownden, Douglas B
Timothy P. Lillicrap, Daniel Cownden, Douglas B. Tweed, and Colin J. Akerman. Random Synaptic Feedback Weights Support Error Backpropagation for Deep Learning. Nature Com- munications, 7(1), 2016. 11
work page 2016
-
[32]
Direct Feedback Alignment Provides Learning in Deep Neural Networks
Arild Nøkland. Direct Feedback Alignment Provides Learning in Deep Neural Networks. In Advances in Neural Information Processing Systems, volume 29, 2016
work page 2016
-
[33]
Biologically-Plausible Learning Al- gorithms Can Scale to Large Datasets
Will Xiao, Honglin Chen, Qianli Liao, and Tomaso Poggio. Biologically-Plausible Learning Al- gorithms Can Scale to Large Datasets. InInternational Conference on Learning Representations, 2019
work page 2019
-
[34]
Dongcheng Zhao, Yi Zeng, Tielin Zhang, Mengting Shi, and Feifei Zhao. GLSNN: A Multi- Layer Spiking Neural Network Based on Global Feedback Alignment and Local STDP Plasticity. Frontiers in Computational Neuroscience, 14, 2020
work page 2020
-
[35]
In-Hardware Learning of Multilayer Spiking Neural Networks on a Neuromorphic Processor
Amar Shrestha, Haowen Fang, Daniel Patrick Rider, Zaidao Mei, and Qinru Qiu. In-Hardware Learning of Multilayer Spiking Neural Networks on a Neuromorphic Processor. In Design Automation Conference, 2021
work page 2021
-
[36]
STSF: Spiking Time Sparse Feedback Learning for Spiking Neural Networks
Ping He, Rong Xiao, Chenwei Tang, Shudong Huang, Jiancheng Lv, and Huajin Tang. STSF: Spiking Time Sparse Feedback Learning for Spiking Neural Networks. IEEE Transactions on Neural Networks and Learning Systems, 2025
work page 2025
-
[37]
Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures
Sergey Bartunov, Adam Santoro, Blake Richards, Luke Marris, Geoffrey E Hinton, and Timothy Lillicrap. Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures. In Advances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[38]
Feedback alignment in deep convolutional networks
Theodore H. Moskovitz, Ashok Litwin-Kumar, and L. F. Abbott. Feedback Alignment in Deep Convolutional Networks. arXiv, arXiv:1812.06488, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
Hebbian Learn- ing Based Orthogonal Projection for Continual Learning of Spiking Neural Networks
Mingqing Xiao, Qingyan Meng, Zongpeng Zhang, Di He, and Zhouchen Lin. Hebbian Learn- ing Based Orthogonal Projection for Continual Learning of Spiking Neural Networks. In International Conference on Learning Representations, 2024
work page 2024
-
[40]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv, arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto, 2009
work page 2009
-
[42]
Gradient-Based Learning Applied to Document Recognition
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11), 1998
work page 1998
-
[43]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, arXiv:1409.1556, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In International Conference on Computer Vision, 2015
work page 2015
-
[45]
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations, 2015
work page 2015
-
[46]
Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding
Seongsik Park and Sungroh Yoon. Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding. arXiv, arXiv:2106.02568, 2021
-
[47]
Thorpe, and Tim- othée Masquelier
Milad Mozafari, Mohammad Ganjtabesh, Abbas Nowzari-Dalini, Simon J. Thorpe, and Tim- othée Masquelier. Bio-Inspired Digit Recognition Using Reward-Modulated Spike-Timing- Dependent Plasticity in Deep Convolutional Networks. Pattern Recognition, 94, 2019
work page 2019
-
[48]
Paired Competing Neurons Improving STDP Supervised Local Learning in Spiking Neural Networks
Gaspard Goupy, Pierre Tirilly, and Ioan Marius Bilasco. Paired Competing Neurons Improving STDP Supervised Local Learning in Spiking Neural Networks. Frontiers in Neuroscience, 18, 2024
work page 2024
-
[49]
Fixed-Weight Difference Target Propagation
Tatsukichi Shibuya, Nakamasa Inoue, Rei Kawakami, and Ikuro Sato. Fixed-Weight Difference Target Propagation. AAAI Conference on Artificial Intelligence, 37, 2023. 12
work page 2023
-
[50]
Asynchronous Stochastic Gradient Descent with Delay Compensation
Shuxin Zheng, Qi Meng, Taifeng Wang, Wei Chen, Nenghai Yu, Zhi-Ming Ma, and Tie-Yan Liu. Asynchronous Stochastic Gradient Descent with Delay Compensation. In International Conference on Machine Learning, 2017
work page 2017
-
[51]
Fully Decoupled Neural Network Learning Using Delayed Gradients
Huiping Zhuang, Yi Wang, Qinglai Liu, and Zhiping Lin. Fully Decoupled Neural Network Learning Using Delayed Gradients. IEEE Transactions on Neural Networks and Learning Systems, 33(10), 2022
work page 2022
-
[52]
Delayed Gradient Averaging: Tolerate the Communication Latency for Federated Learning
Ligeng Zhu, Hongzhou Lin, Yao Lu, Yujun Lin, and Song Han. Delayed Gradient Averaging: Tolerate the Communication Latency for Federated Learning. InAdvances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[53]
Grid’5000: A Large Scale, Reconfigurable, Controlable and Monitorable Grid Platform
Franck Cappello, Frédéric Desprez, Michel Daydé, Emmanuel Jeannot, Yvon Jégou, Stephane Lanteri, Nouredine Melab, Raymond Namyst, Pascale Primet, Olivier Richard, Eddy Caron, Julien Leduc, and Guillaume Mornet. Grid’5000: A Large Scale, Reconfigurable, Controlable and Monitorable Grid Platform. In International Workshop on Grid Computing, 2005
work page 2005
-
[54]
Malu Zhang, Jiadong Wang, Jibin Wu, Ammar Belatreche, Burin Amornpaisannon, Zhixuan Zhang, Venkata Pavan Kumar Miriyala, Hong Qu, Yansong Chua, Trevor E. Carlson, and Haizhou Li. Rectified Linear Postsynaptic Potential Function for Backpropagation in Deep Spiking Neural Networks. IEEE Transactions on Neural Networks and Learning Systems, 33 (5), 2022
work page 2022
-
[55]
Temporal Backpropagation for Spiking Neural Networks with One Spike per Neuron
Saeed Reza Kheradpisheh and Timothée Masquelier. Temporal Backpropagation for Spiking Neural Networks with One Spike per Neuron. International Journal of Neural Systems, 30(6), 2020. A Baseline In this appendix, we present the neural coding, neuron model, and event-driven BP algorithm used in this paper, adopted from the TTFS-based deep SNN proposed in [1...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.