In-depth Research Impact Summarization through Fine-Grained Temporal Citation Analysis
Pith reviewed 2026-05-22 13:39 UTC · model grok-4.3
The pith
Scientific papers can be summarized by tracking how later citations confirm or correct their claims over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that nuanced, expressive, and time-aware impact summaries can be generated by analyzing the evolution of fine-grained citation intents, which capture both confirmation citations that praise a paper and correction citations that critique it.
What carries the argument
Time-aware impact summaries generated from the evolution of fine-grained citation intents, which track praise and critique across citing papers.
If this is right
- Impact assessment moves beyond raw citation totals to track specific ways a paper is used or challenged.
- Summarization systems can incorporate temporal citation data to produce evolving descriptions of a work's role.
- Evaluation of research can better separate supportive and critical reception in the literature.
Where Pith is reading between the lines
- These summaries could help funding panels or hiring committees quickly grasp a paper's reception history.
- The method might extend to non-academic domains such as patent citations or policy document references.
- Automated systems trained on this task could surface overlooked critiques that citation counts obscure.
Load-bearing premise
Human ratings of how insightful the generated summaries are serve as a reliable way to judge their quality.
What would settle it
A study in which human experts rate the time-aware summaries no higher than simple citation-count summaries or random excerpts on insightfulness or expressiveness.
Figures



















read the original abstract
Understanding the impact of scientific publications is crucial for identifying breakthroughs and guiding future research. Traditional metrics based on citation counts often miss the nuanced ways a paper contributes to its field. In this work, we propose a new task: generating nuanced, expressive, and time-aware impact summaries that capture both praise (confirmation citations) and critique (correction citations) through the evolution of fine-grained citation intents. We introduce an evaluation framework tailored to this task, showing moderate to strong human correlation on subjective metrics such as insightfulness. Expert feedback from professors reveals a strong interest in these summaries and suggests future improvements. Data and code are made available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a new task for generating nuanced, expressive, and time-aware impact summaries of scientific publications. These summaries capture both praise (via confirmation citations) and critique (via correction citations) by tracking the evolution of fine-grained citation intents over time. It introduces a tailored evaluation framework that reports moderate to strong human correlation on subjective metrics such as insightfulness, along with positive expert feedback from professors, and releases the associated data and code.
Significance. If the evaluation holds, the work could advance scientometrics and NLP applications in research impact assessment by moving beyond aggregate citation counts to intent-aware, temporally evolving summaries. The explicit separation of confirmation versus correction citations and the open release of data/code are notable strengths that support reproducibility and follow-on research.
major comments (1)
- [Abstract and Evaluation Framework section] The central claim rests on human correlation results for insightfulness, yet the abstract and evaluation description provide no details on the evaluation framework, including annotator expertise or number, rating scale and instructions, data collection procedure, citation intent taxonomy, or agreement statistics (e.g., Cohen's kappa or Krippendorff's alpha). This absence prevents verification that the reported correlation reflects genuine summary quality rather than noise or shared bias.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the specific fine-grained citation intent categories or the temporal granularity (e.g., year-level or citation-order) used in the analysis.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestion regarding the transparency of our evaluation framework. We address the major comment below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation Framework section] The central claim rests on human correlation results for insightfulness, yet the abstract and evaluation description provide no details on the evaluation framework, including annotator expertise or number, rating scale and instructions, data collection procedure, citation intent taxonomy, or agreement statistics (e.g., Cohen's kappa or Krippendorff's alpha). This absence prevents verification that the reported correlation reflects genuine summary quality rather than noise or shared bias.
Authors: We agree that the current manuscript provides insufficient detail on the human evaluation setup, which is necessary to substantiate the reported correlations. In the revised version we will expand the Evaluation Framework section (and update the abstract if space permits) to explicitly describe: (1) annotator recruitment and expertise (number of participants, their academic backgrounds, and any screening criteria), (2) the rating scale and full annotation instructions, (3) the data sampling and collection procedure, (4) the fine-grained citation intent taxonomy, and (5) inter-annotator agreement metrics including Cohen's kappa or Krippendorff's alpha. These additions will allow readers to assess the reliability of the human judgments. revision: yes
Circularity Check
No significant circularity; task proposal and human evaluation are self-contained
full rationale
The paper introduces a new task for time-aware impact summaries distinguishing confirmation and correction citations, then evaluates generated outputs via external human judgments on subjective metrics such as insightfulness. No mathematical derivations, fitted parameters, or predictions are presented that reduce to the paper's own inputs by construction. The evaluation framework depends on independent human feedback rather than self-referential definitions or self-citation chains, rendering the central claims non-circular and externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-grained citation intents can be reliably classified into categories such as confirmation and correction.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a new task: generating nuanced, expressive, and time-aware impact summaries that capture both praise (confirmation citations) and critique (correction citations) through the evolution of fine-grained citation intents.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Beyond citations: Measuring novel scientific ideas and their impact in publication text.Review of Economics and Statistics, pages 1–33. Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, David Wadden, Matt Latzke, Minyang Tian, Pan Ji, Shengyan Liu, Hao Tong, Bohao Wu...
-
[2]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu
The incidence and role of negative citations in science.Proceedings of the National Academy of Sciences, 112(45):13823–13826. Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2024. Chateval: Towards better llm-based eval- uators through multi-agent debate. InThe Twelfth International Conference on Learn...
work page 2024
-
[3]
Association for Computational Linguistics. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al
-
[4]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Lei Cui, Furu Wei, and Ming Zhou. 2018. Neural open information extraction. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Austra...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Commonsense knowledge mining from pre- trained models. InProceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pages 1173–1178. Association for Computational Linguis- tics. Darren Edge, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Jing Ma, Wei Gao, and Kam-Fai Wong
Association for Computational Linguistics. Jing Ma, Wei Gao, and Kam-Fai Wong. 2018. Rumor detection on twitter with tree-structured recursive neural networks. InProceedings of the 56th Annual Meeting of the Association for Computational Lin- guistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pages 1980–1989. As- sociation ...
work page 2018
-
[7]
Fake News Detection on Social Media using Geometric Deep Learning
IEEE. Chao Min, Qingyu Chen, Erjia Yan, Yi Bu, and Jian- jun Sun. 2021. Citation cascade and the evolu- tion of topic relevance.J. Assoc. Inf. Sci. Technol., 72(1):110–127. Federico Monti, Fabrizio Frasca, Davide Eynard, Da- mon Mannion, and Michael M. Bronstein. 2019. Fake news detection on social media using geometric deep learning.CoRR, abs/1902.06673....
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Springer. Derald Wing Sue. 2001. Multidimensional facets of cultural competence.The counseling psychologist, 29(6):790–821. Stanley Sue. 1998. In search of cultural competence in psychotherapy and counseling.American psycholo- gist, 53(4):440. Zeyu Sun, Qihao Zhu, Yingfei Xiong, Yican Sun, Lili Mou, and Lu Zhang. 2020. Treegen: A tree-based transformer ar...
work page 2001
-
[9]
Simone Teufel, Advaith Siddharthan, and Dan Tidhar
AAAI Press. Simone Teufel, Advaith Siddharthan, and Dan Tidhar
-
[10]
other”. We notice that the classi- fier considersminor“resource use
Automatic classification of citation function. InEMNLP 2006, Proceedings of the 2006 Confer- ence on Empirical Methods in Natural Language Pro- cessing, 22-23 July 2006, Sydney, Australia, pages 103–110. ACL. Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language m...
-
[11]
Word lists n/a ✗ Text cluster- ing ✗ Information systems (Arts et al., 2021) Concept com- binations P. ✗ Text process- ing ✗ U.S. patents (Min et al., 2021) Citation cas- cades n/a ✓ Network anal- ysis ✗ Physics (Wahle et al., 2023) Citation Field Diversity Index n/a ✓ Statistical measures ✗ 23 fields, fo- cus on Com- puter science (Shi and Evans, 2023) C...
work page 2021
-
[12]
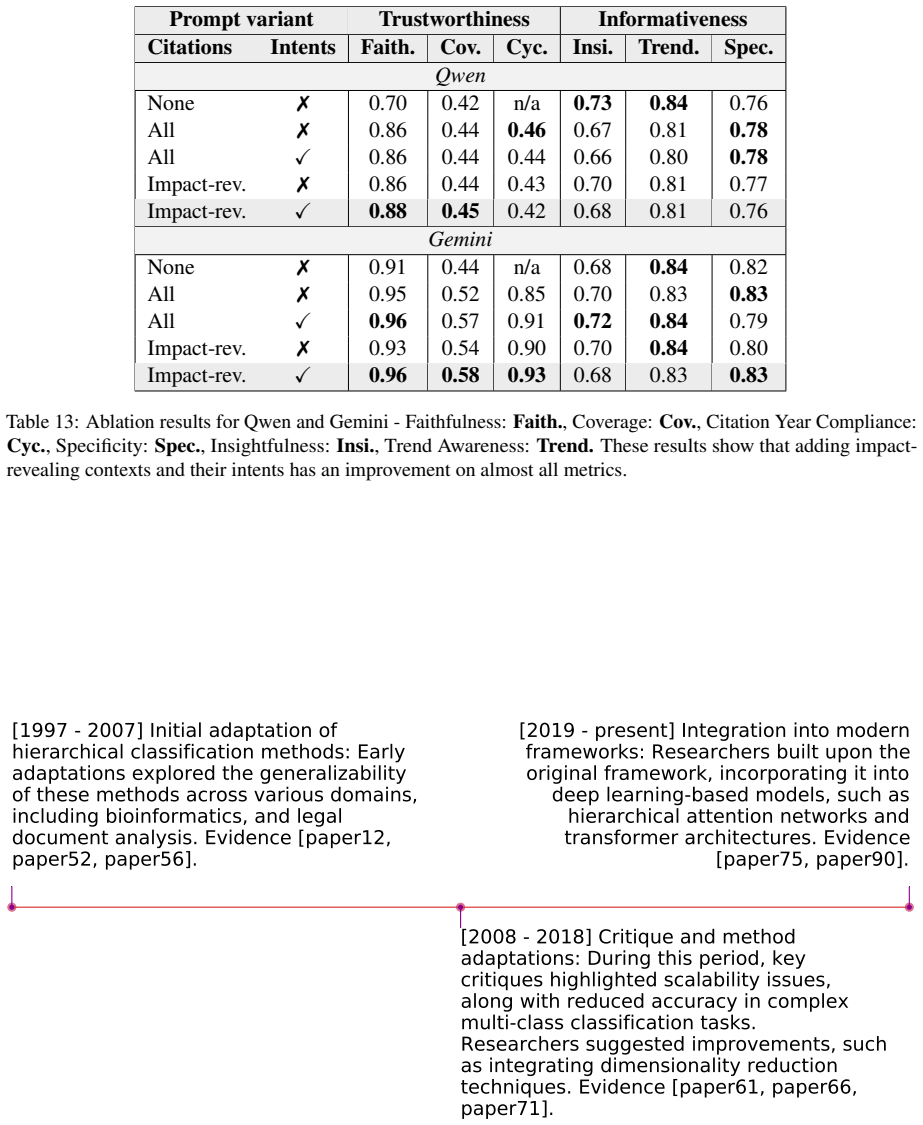
Paper counts P. ✓ Statistical measures ✗ Nobel Prize- winning papers This work Textual Sum- mary P., C. ✓ LLM fine- grained Computer sci- ence, Psychol- ogy, Medicine Table 6: Comparison with existing work on scientific impact analysis. Our work is the first to express scientific impact through time-aware textual summaries derived from fine-grained citati...
work page 2014
-
[13]
Understand the impact description and its specified time period
-
[14]
Review each citation in the provided list
-
[15]
Determine if the impact description can be supported by any single citation or a combination of citations
-
[16]
If the impact description is supported, identify the relevant citations that support it
-
[17]
none" if unfaithful] </proof> **Additional Guidelines:** - The answer should be
If the impact description cannot be supported or is contradicted by the citations, determine it as unfaithful. **Response Format:** - **Analysis:** <analysis> [Provide your analysis here] </analysis> - **Answer:** <answer> [yes/no] </answer> - **Proof:** <proof> [List the exact text of the citations that support the impact description, or "none" if unfait...
work page 2004
-
[18]
Hierarchically Classifying Documents Using Very Few Words
are cited for their method. In commonsense knowledge mining, only one of the 3 papers is often cited for its dataset (Hwang et al., 2021), and even though the other 2 papers are cited to highlight limitations, the limitations are different, namely challenges with handling constraints and reasoning for one (Davison et al., 2019) , but data noise and limite...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.