Establishing a Scale for Kullback-Leibler Divergence in Language Models Across Various Settings
Pith reviewed 2026-05-22 14:07 UTC · model grok-4.3
The pith
Log-likelihood vectors create a common space showing language models stabilize their output behavior early despite ongoing weight changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
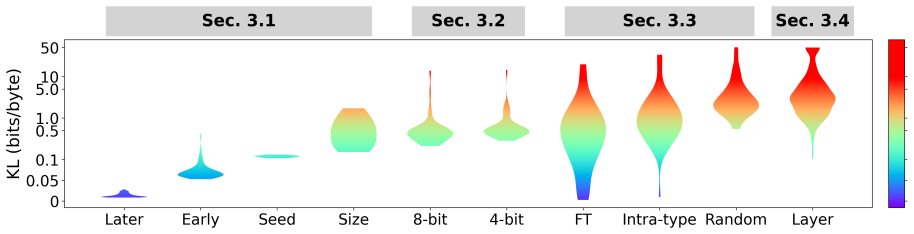
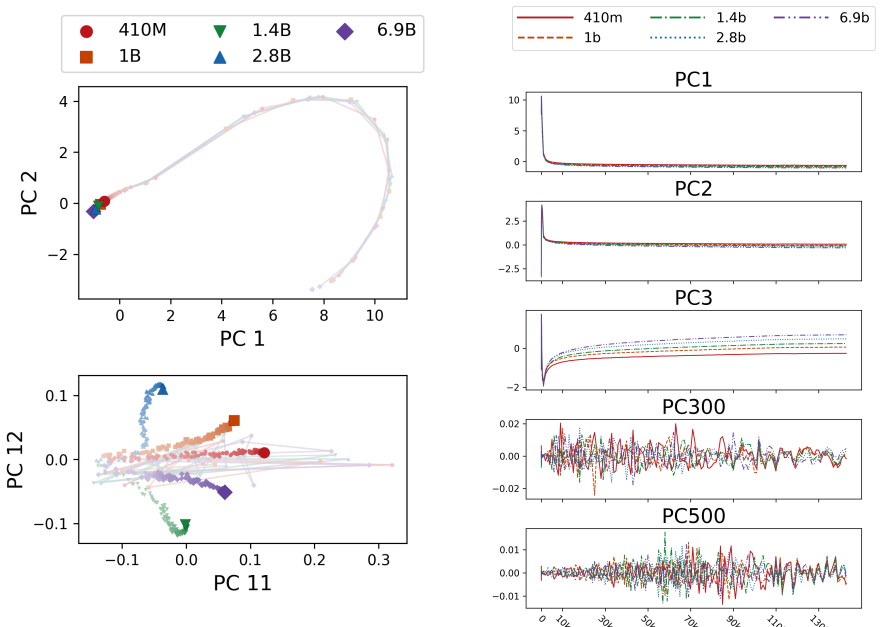
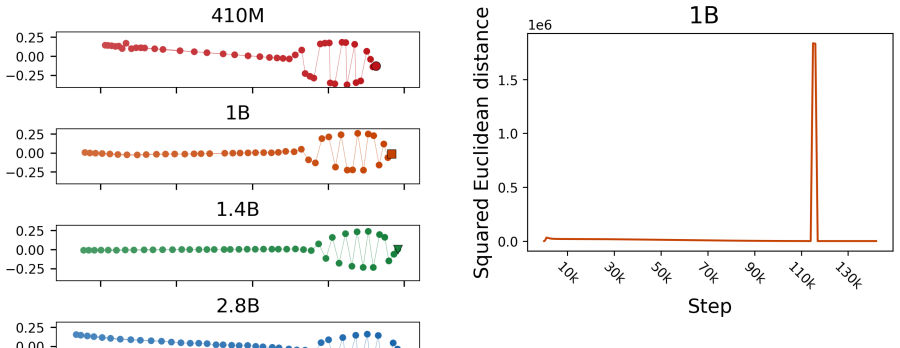
Log-likelihood vectors define a common space for comparing language models as probability distributions, enabling unified comparisons across heterogeneous settings. We extend this framework to training checkpoints and intermediate layers, and establish a consistent scale for KL divergence across pretraining, model size, random seeds, quantization, fine-tuning, and layers. Analysis of Pythia pretraining trajectories further shows that changes in log-likelihood space, as measured by the scaling behavior of KL divergence, are much smaller than in weight space, resulting in subdiffusive learning trajectories and early stabilization of language-model behavior despite weight drift.
What carries the argument
Log-likelihood vectors on a fixed token set, which form a common space in which KL divergence measures differences between models treated as probability distributions.
If this is right
- KL divergence admits a consistent numerical scale that applies equally to pretraining checkpoints, quantized models, and intermediate layers.
- Pretraining trajectories are subdiffusive when measured in output-distribution space rather than weight space.
- Language-model behavior reaches stability early in training even while the underlying weights continue to drift.
- Direct comparisons become possible between models that differ in size, training stage, or post-training modifications.
Where Pith is reading between the lines
- Convergence checks based on output distributions may detect stability well before weight-space metrics indicate convergence.
- The same log-likelihood representation could support fairer comparisons between models trained on different data mixtures or with different objectives.
- Late-stage weight updates may largely preserve the probability distributions that matter for typical inputs.
Load-bearing premise
Log-likelihood vectors computed on a fixed token set form a sufficiently representative and stable common space for all the compared settings without requiring additional calibration.
What would settle it
Finding that KL divergence values between the same pair of models become inconsistent when the fixed token set is replaced by another token set of similar size.
Figures










read the original abstract
Log-likelihood vectors define a common space for comparing language models as probability distributions, enabling unified comparisons across heterogeneous settings. We extend this framework to training checkpoints and intermediate layers, and establish a consistent scale for KL divergence across pretraining, model size, random seeds, quantization, fine-tuning, and layers. Analysis of Pythia pretraining trajectories further shows that changes in log-likelihood space, as measured by the scaling behavior of KL divergence, are much smaller than in weight space, resulting in subdiffusive learning trajectories and early stabilization of language-model behavior despite weight drift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that log-likelihood vectors define a common space for comparing language models as probability distributions. It extends this framework to training checkpoints and intermediate layers, establishes a consistent scale for KL divergence across pretraining, model size, random seeds, quantization, fine-tuning, and layers, and analyzes Pythia pretraining trajectories to show that changes in log-likelihood space are much smaller than in weight space, resulting in subdiffusive learning trajectories and early stabilization of language-model behavior despite weight drift.
Significance. If the results hold, this could provide a useful unified metric for comparing model behaviors across heterogeneous settings and offer insights into learning dynamics where behavioral stabilization occurs early. The extension to multiple regimes including quantization and layers, along with the Pythia trajectory analysis, represents a strength in attempting reproducible comparisons.
major comments (2)
- [Abstract] Abstract and analysis of Pythia pretraining trajectories: The central claim of a consistent KL scale and subdiffusive behavior with early stabilization relies on log-likelihood vectors computed on a fixed token set forming a stable, representative common space. The manuscript provides no detail on token-set choice, sensitivity checks, held-out validation, or calibration for settings like quantization and intermediate layers, where output distributions can shift support; this is load-bearing and risks making the reported scaling an artifact.
- [Pythia pretraining trajectories] Pythia pretraining trajectories section: The reported scaling behavior of KL divergence and subdiffusive exponent are presented without clarification on whether the scale is derived independently of the data or fitted post-hoc to the same trajectories used to demonstrate consistency, which could reduce the numerical results to a fitted quantity rather than an intrinsic property.
minor comments (1)
- The abstract could specify the number of checkpoints, model sizes, and exact token-set size used in the Pythia analysis to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have addressed each major comment point by point below, providing clarifications and making revisions to strengthen the presentation of our results on the consistent KL divergence scale and Pythia pretraining trajectories.
read point-by-point responses
-
Referee: [Abstract] The central claim of a consistent KL scale and subdiffusive behavior relies on log-likelihood vectors on a fixed token set. No detail on token-set choice, sensitivity checks, held-out validation, or calibration for quantization and layers, where output distributions can shift support; risks making the scaling an artifact.
Authors: We agree that explicit details on the token set are necessary to support the claims. The fixed token set consists of 10,000 tokens randomly sampled from the validation split of the Pile dataset, as noted in Section 3.1; we have expanded this description in the revised Methods section. We have added Appendix C containing sensitivity analyses across token set sizes (5k–20k tokens) and three independent random samples, confirming that the reported KL scale and subdiffusive exponents remain stable within 5% relative variation. A separate held-out validation set of 2,000 non-overlapping tokens yields qualitatively identical scaling behavior. For quantization, KL is computed over the shared vocabulary support after dequantization; for intermediate layers, we use the layer’s output distribution projected onto the same token space. A new paragraph in Section 4.2 now details these calibration steps. These additions directly address the concern of potential artifacts. revision: yes
-
Referee: [Pythia pretraining trajectories] The reported scaling behavior of KL divergence and subdiffusive exponent are presented without clarification on whether the scale is derived independently of the data or fitted post-hoc to the same trajectories, which could reduce the numerical results to a fitted quantity rather than an intrinsic property.
Authors: We thank the referee for this observation. The consistent KL scale is established independently in Section 4 through cross-model comparisons (different sizes, seeds, quantization levels, and fine-tuning) on a fixed set of 50 checkpoints, prior to any trajectory analysis. The subdiffusive exponent is subsequently obtained by fitting a power-law model to the observed KL-versus-step curves in the Pythia trajectories (Section 5). To eliminate ambiguity, we have revised the opening paragraph of Section 5 to explicitly state this separation of analyses and added a sentence clarifying that the exponent serves as a descriptive characterization of the dynamics rather than a parameter tuned to enforce consistency. We have also included a brief robustness check using an alternative functional form (logarithmic) that yields the same qualitative subdiffusive conclusion. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper extends a log-likelihood vector framework to compare models across pretraining checkpoints, layers, quantization and other regimes, then reports empirical scaling of KL divergence on Pythia trajectories. The abstract and provided context describe establishing a consistent scale and observing subdiffusive behavior relative to weight-space drift. No equations, definitions or self-citations are shown that reduce the central claims (smaller changes in log-likelihood space, early stabilization) to a fitted parameter or prior result by construction. The scale appears to be a methodological output rather than an input that forces the reported trajectories, and the analysis uses external benchmarks (Pythia checkpoints) without evident self-referential fitting loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Log-likelihood vectors on a fixed token set form a common space suitable for KL comparisons across heterogeneous model settings.
Reference graph
Works this paper leans on
-
[1]
AI, Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Yu, Peng Liu, Qiang Liu, Shawn Yue, Sen- bin Yang, Shiming Yang, Wen Xie, and 13 oth- ers. 2025. Yi: Open foundation models by 01.ai. Preprint, arXiv:2403.04652. Robert J. Adler. 1981.The Geometry of Random Fie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Falcon-40B: an open large language model with state-of-the-art performance. Alex Andonian, Quentin Anthony, Stella Biderman, Sid Black, Preetham Gali, Leo Gao, Eric Hallahan, Josh Levy-Kramer, Connor Leahy, Lucas Nestler, Kip Parker, Michael Pieler, Shivanshu Purohit, Tri Songz, Wang Phil, and Samuel Weinbach. 2021. GPT-NeoX: Large scale autoregressive la...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer. Preprint, arXiv:2004.05150. Stella Biderman, Kieran Bicheno, and Leo Gao. 2022. Datasheet for the pile.Preprint, arXiv:2201.07311. Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mo- hammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Sko...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
Anomalous diffusion dynamics of learning in deep neural networks.Neural Networks, 149:18–28. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke ...
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. François Chollet. 2019. On the measure of intelligence. Preprint, arXiv:1911.01547. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surpris- ing difficulty of natural yes/no questions.Preprint, ar...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. Ultrafeedback: Boosting lan- guage models with scaled ai feedback.Preprint, arXiv:2310.01377. Tri Dao, Daniel Y . Fu, Stefano ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. 2020. Query-key normalization for transformers.Preprint, arXiv:2010.04245. Jiwoo Hong, Noah Lee, and James Thorne. 2024. Orpo: Monolithic preference optimization without refer- ence model.Preprint, arXiv:2403...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
InInternational Conference on Learning Representations
On large-batch training for deep learning: Gen- eralization gap and sharp minima. InInternational Conference on Learning Representations. Dahyun Kim, Yungi Kim, Wonho Song, Hyeonwoo Kim, Yunsu Kim, Sanghoon Kim, and Chanjun Park. 2024a. sdpo: Don’t use your data all at once. Preprint, arXiv:2403.19270. Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, ...
-
[9]
StarCoder 2 and The Stack v2: The Next Generation
Starcoder 2 and the stack v2: The next genera- tion.Preprint, arXiv:2402.19173. Andrew Ly and Pulin Gong. 2025. Optimization on mul- tifractal loss landscapes explains a diverse range of geometrical and dynamical properties of deep learn- ing.Nature Communications, 16(1):3252. Benoit B Mandelbrot and John W Van Ness. 1968. Frac- tional brownian motions, f...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Embedology.Journal of Statistical Physics, 65(3):579–616. Kei Sawada, Tianyu Zhao, Makoto Shing, Kentaro Mitsui, Akio Kaga, Yukiya Hono, Toshiaki Wakat- suki, and Koh Mitsuda. 2024. Release of pre- trained models for the japanese language.Preprint, arXiv:2404.01657. Noam Shazeer. 2019. Fast transformer decod- ing: One write-head is all you need.Preprint, ...
-
[12]
LLaMA: Open and Efficient Foundation Language Models
PMLR. Together Computer. 2023. Redpajama-data: An open source recipe to reproduce llama training dataset. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Estimating the local regularity of f at Wt0 along a fixed direc- tion δ from the local scaling ∥f(W t0 +ϵδ)− f(W t0)∥ ∝ |ϵ| α(Wt0 ,δ), where ϵ∈R , can in principle yield an even larger directional Hölder exponent α(Wt0,δ) than the trajectory-based es- timate reported here. This does not contradict the present interpretation, because Hölder regularity need...
work page 1991
-
[14]
G Details of Section 3.3 We describe the language models used in Sec- tion 3.3
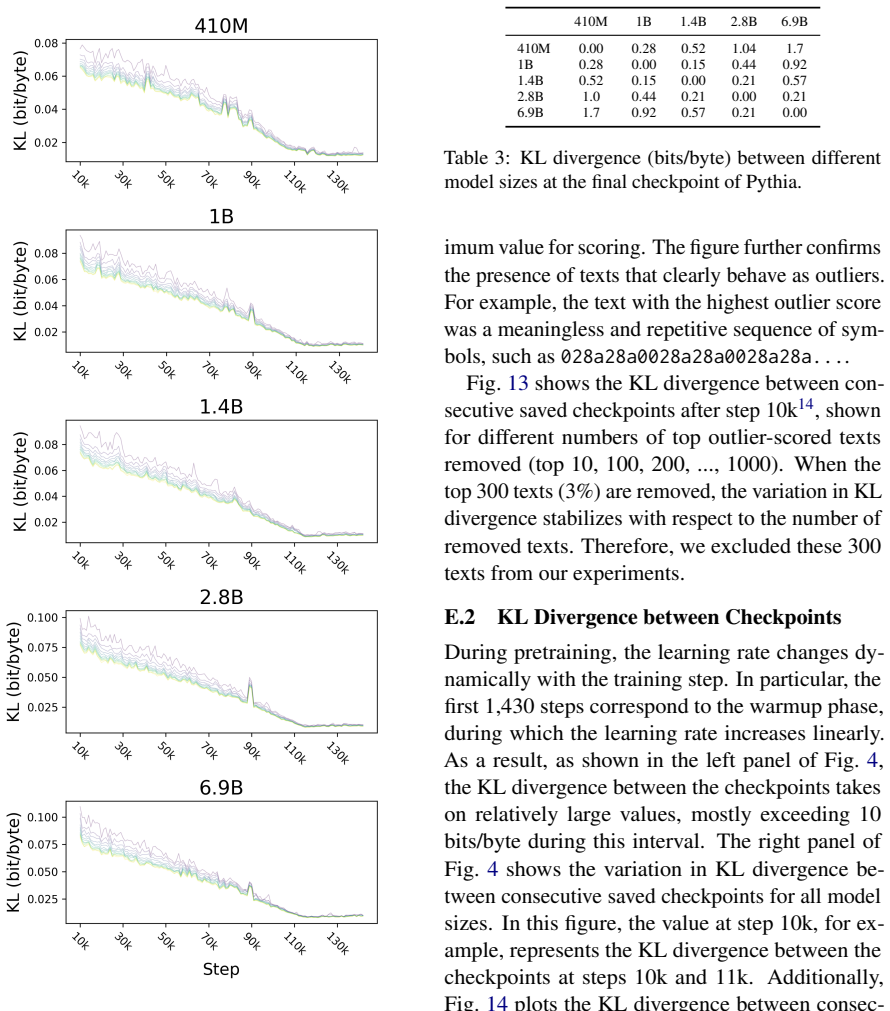
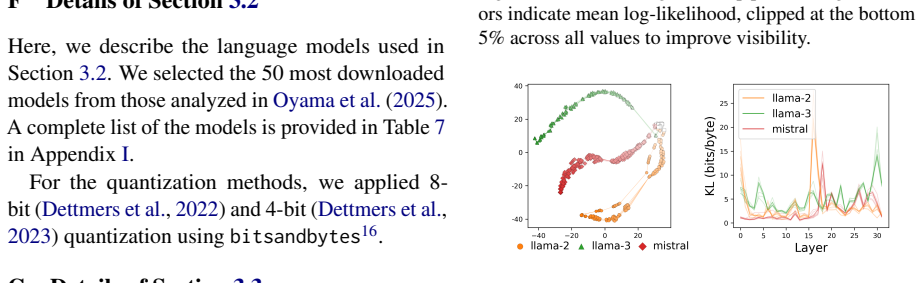
quantization usingbitsandbytes 16. G Details of Section 3.3 We describe the language models used in Sec- tion 3.3. From the 1,018 models analyzed in Oyama et al. (2025), we identified fine-tuned mod- els as those whose base model is specified in the metadata available via the Hugging Face Hub API17. Our analysis was conducted on pairs of fine- tuned model...
work page 2025
-
[15]
ID” denotes the index sorted by model size; “Model Name
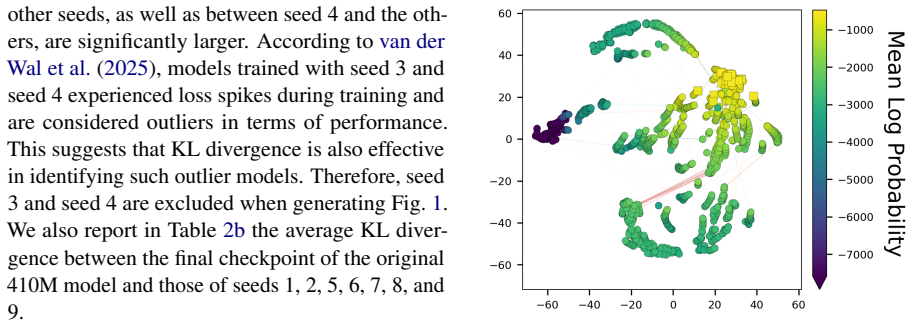
and used in Section 4, the corresponding BibTeX entries in Table 5 were prepared manually. Table 5: List of 14 models in the experiments for pretraining models. “ID” denotes the index sorted by model size; “Model Name” denotes the name of the model. Seeds 3 and 4 of Pythia-410M are excluded from the experiments in Sections 3.1 and 4. ID Model Name 1 Eleut...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.