MIRROR: Converging Cognitive Principles as Computational Mechanisms for AI Reasoning
Pith reviewed 2026-05-19 12:01 UTC · model grok-4.3
The pith
Principles shared across cognitive theories improve AI performance on multi-turn tasks that demand sustained attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
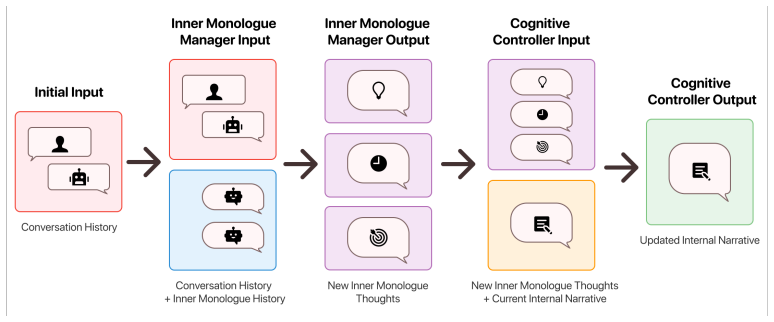
Multiple cognitive theories converge on parallel specialized processing, integrative synthesis into a bounded unified representation, and reconstructive rather than accumulative maintenance; when these are operationalized as an Inner Monologue Manager that generates parallel cognitive threads, a Cognitive Controller that synthesizes them into a fully reconstructed first-person narrative each turn, and temporal separation between fast response generation and slow deliberative consolidation, the resulting system yields consistent performance improvements on multi-turn dialogue requiring constraint maintenance under attentional interference.
What carries the argument
MIRROR's Inner Monologue Manager and Cognitive Controller, which create parallel cognitive threads and then reconstruct them into a bounded first-person narrative each turn to realize integrative synthesis and reconstructive maintenance.
If this is right
- Reconstructive synthesis alone improves results across all seven tested models.
- The full integrated system outperforms either parallel exploration or integrative synthesis used in isolation for six of the seven models.
- Performance gains concentrate under high attentional load where integrated information must be globally available.
- The architecture generates concrete, testable predictions about human working memory, inner speech, and memory consolidation.
Where Pith is reading between the lines
- The same reconstructive and integrative mechanisms might produce similar gains in AI tasks that involve long-horizon planning or multi-step problem solving rather than dialogue alone.
- Periodic full reconstruction of an agent's internal state could prove more robust than incremental updates in environments with frequent interruptions or changing constraints.
- Further tests could check whether the benefits scale with model size or appear in non-linguistic domains such as robotic control or game playing.
Load-bearing premise
The specific ways the authors turned Global Workspace Theory, reconstructive episodic memory, inner speech, and complementary learning systems into the Inner Monologue Manager, Cognitive Controller, and temporal separation actually capture the essential mechanisms of those theories rather than adding unrelated engineering choices.
What would settle it
If replacing the reconstructive synthesis step with simple accumulative updates or disabling the parallel thread generation removes the performance improvement on the attentional-interference dialogue tasks, the central claim would be supported; if the gains remain, the claim would be weakened.
Figures








read the original abstract
Multiple cognitive theories -- Global Workspace Theory, reconstructive episodic memory, inner speech, and complementary learning systems -- converge on a shared set of architectural principles: parallel specialized processing, integrative synthesis into a bounded unified representation, and reconstructive rather than accumulative maintenance. We test whether these converging principles provide computational advantages when implemented in AI systems. MIRROR operationalizes each principle as a concrete mechanism: an Inner Monologue Manager generates parallel cognitive threads (Goals, Reasoning, Memory), a Cognitive Controller synthesizes these into a bounded first-person narrative that is fully reconstructed each turn, and a temporal separation between fast response generation and slow deliberative consolidation mirrors complementary learning dynamics. Evaluated on multi-turn dialogue requiring constraint maintenance under attentional interference, MIRROR yields 21% relative improvement across seven architecturally diverse language models. Ablation studies test the theoretical predictions directly: reconstructive synthesis improves all seven models (+5-20%); the integrated system outperforms either component alone for six of seven models, confirming that parallel exploration and integrative synthesis are complementary; and gains concentrate where theories predict -- under high attentional load where global availability of integrated information is most needed. These results demonstrate that converging principles from human cognition provide architecture-general computational advantages, and generate testable behavioral predictions about working memory, inner speech, and memory consolidation. Project page available at https://www.arcarae.com/research/MIRROR and code at https://github.com/arcarae/MIRROR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MIRROR, an architecture that operationalizes converging principles from cognitive theories (Global Workspace Theory, reconstructive episodic memory, inner speech, and complementary learning systems) as concrete AI mechanisms: parallel threads generated by an Inner Monologue Manager, synthesis into a bounded first-person narrative that is fully reconstructed each turn by a Cognitive Controller, and temporal separation between fast response generation and slow consolidation. Evaluated on multi-turn dialogue tasks requiring constraint maintenance under attentional interference, MIRROR reports a 21% relative improvement across seven architecturally diverse language models. Ablations are presented as directly testing theoretical predictions, showing benefits from reconstructive synthesis (+5-20%), complementarity of components, and concentration of gains under high load.
Significance. If the results hold after addressing controls, the work is significant for providing empirical evidence that principles from human cognition can yield architecture-general computational advantages in AI reasoning. It generates testable behavioral predictions about working memory and memory consolidation, and the open code and project page support reproducibility and extension. This offers a substantive bridge between cognitive science and AI engineering rather than purely engineering gains.
major comments (2)
- [Ablation studies] Ablation studies section: while reconstructive synthesis is compared to its absence and the integrated system to single components, the design lacks matched controls that preserve the engineering structure (e.g., neutral thread labels instead of theory-specific ones such as Goals/Reasoning/Memory, or accumulative rather than fully reconstructive updates). This is load-bearing for the central claim that the 21% gains and load-dependent patterns arise specifically from the operationalized cognitive principles rather than generic effects such as added multi-perspective context or periodic resets.
- [Experimental evaluation] Experimental evaluation section: the multi-turn dialogue task construction, operationalization of attentional interference, exact baseline definitions, model sizes, and statistical controls underlying the 21% aggregate relative improvement are not described with sufficient precision to allow full verification of the empirical claim or assessment of whether gains concentrate as predicted.
minor comments (2)
- The abstract would benefit from one additional sentence specifying the number of turns, constraint types, or baseline models to give readers immediate quantitative context.
- Figure captions for ablation plots should explicitly state the y-axis metric (e.g., constraint satisfaction rate) and error bars to improve clarity without requiring reference to the main text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We appreciate the recognition of the work's significance in bridging cognitive science and AI. Below, we provide point-by-point responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Ablation studies] Ablation studies section: while reconstructive synthesis is compared to its absence and the integrated system to single components, the design lacks matched controls that preserve the engineering structure (e.g., neutral thread labels instead of theory-specific ones such as Goals/Reasoning/Memory, or accumulative rather than fully reconstructive updates). This is load-bearing for the central claim that the 21% gains and load-dependent patterns arise specifically from the operationalized cognitive principles rather than generic effects such as added multi-perspective context or periodic resets.
Authors: We acknowledge the referee's concern regarding the specificity of our ablation controls. Our ablations were intentionally designed to test the core theoretical predictions from the cognitive principles, including the benefits of reconstructive synthesis and the complementarity of parallel processing and integrative synthesis. However, to more rigorously rule out generic effects from multi-perspective context or periodic updates, we will incorporate additional matched control conditions in the revised manuscript. Specifically, we will add an ablation using neutral thread labels (e.g., Thread1, Thread2, Thread3) instead of theory-derived ones, and another using accumulative synthesis rather than full reconstruction each turn. These will be presented alongside the existing ablations to demonstrate that the gains are indeed tied to the operationalized cognitive mechanisms. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: the multi-turn dialogue task construction, operationalization of attentional interference, exact baseline definitions, model sizes, and statistical controls underlying the 21% aggregate relative improvement are not described with sufficient precision to allow full verification of the empirical claim or assessment of whether gains concentrate as predicted.
Authors: We agree that greater precision in the experimental evaluation section is necessary for full reproducibility and verification. In the revised manuscript, we will expand this section to include: (1) a detailed description of the multi-turn dialogue task construction and the specific constraints used; (2) the exact method for operationalizing attentional interference; (3) precise definitions of all baselines, including how they were implemented across the seven models; (4) the specific model sizes and architectures tested; and (5) the statistical methods, including any controls for multiple comparisons and how the 21% relative improvement was calculated. We will also provide further analysis showing the concentration of gains under high load conditions as predicted by the theory. revision: yes
Circularity Check
No circularity: empirical performance deltas on held-out tasks
full rationale
The paper's central claims rest on measured accuracy improvements (21% relative) and ablation deltas across seven models on multi-turn dialogue tasks. These quantities are computed from external task performance rather than being algebraically or definitionally equivalent to the architectural choices. No equations appear that equate a fitted parameter to a 'prediction,' no self-citation chain supplies the load-bearing uniqueness or ansatz, and the operationalizations are presented as engineering translations whose validity is tested by ablation rather than presupposed. The derivation chain therefore terminates in falsifiable experimental outcomes rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Global Workspace Theory, reconstructive episodic memory, inner speech, and complementary learning systems converge on parallel specialized processing, integrative synthesis into a bounded unified representation, and reconstructive rather than accumulative maintenance.
Reference graph
Works this paper leans on
-
[1]
Alberts, L., Ellis, B., Lupu, A., and Foerster, J. (2025). Curate: Benchmarking personalised alignment of conversational ai assistants
work page 2025
-
[2]
Alderson-Day, B., Weis, S., McCarthy-Jones, S., Moseley, P., Smailes, D., and Fernyhough, C. (2016). The brain’s conversation with itself: neural substrates of dialogic inner speech.Social Cognitive and Affective Neuroscience, 11(1):110–120
work page 2016
-
[3]
R., Smallwood, J., and Spreng, R
Andrews-Hanna, J. R., Smallwood, J., and Spreng, R. N. (2014). The default network and self-generated thought: component processes, dynamic control, and clinical relevance. Annals of the New York Academy of Sciences, 1316:29–52
work page 2014
-
[4]
Baars, B. J. (1988). A Cognitive Theory of Consciousness. Cambridge University Press
work page 1988
-
[5]
Baddeley, A. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4(11):417–423
work page 2000
-
[6]
Baddeley, A. and Hitch, G. (1974). Working memory. In Bower, G. H., editor, The Psychology of Learning and Motivation, vol. 8, pages 47–89. Academic Press
work page 1974
-
[7]
E., Fort, S., Lanham, T., Telleen-Lawton, T., Conerly, T., Henighan, T., Hume, T., Bowman, S
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Hernandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., Kerr, J., Mueller, J., Ladish, J., Landau, J., Ndousse, K., Lukoši ¯ut˙e, K., Lovitt, L., Sellitto, M., Elhage, N., Schiefer, ...
work page 2022
-
[8]
Ben Alderson-Day, C. F. (2015). Inner speech: Development, cognitive functions, phenomenology, and neurobiology. Social and Personality Psychology Compass, 141(5):931–965
work page 2015
-
[9]
J., Garrod, S., and Kessler, K
Bögels, S., Barr, D. J., Garrod, S., and Kessler, K. (2015). Conversational interaction in the scanner: Mentalizing during language processing as revealed by meg. Cerebral Cortex, 25(9):3219–3234
work page 2015
-
[10]
Bruner, J. (1991). The narrative construction of reality. Critical Inquiry, 18(1):1–21
work page 1991
-
[11]
Brysbaert, M. (2019). How many words do we read per minute? a review and meta-analysis of reading rate. Journal of Memory and Language, 109:104047. Meta-analysis of 190 studies; estimates adult silent reading rate at 238 WPM (non-fiction)
work page 2019
-
[12]
Castillo-Bolado, D., Davidson, J., Gray, F., and Rosa, M. (2024). Beyond prompts: Dynamic conversational benchmarking of large language models
work page 2024
-
[13]
Chella, A. and Pipitone, A. (2020). A cognitive architecture for inner speech. Cognitive Systems Research, 59:287–292
work page 2020
-
[14]
Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. (2017). Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017), pages 4299–4307
work page 2017
-
[15]
Clark, A. (2013). Whatever next? predictive brains, situated agents, and the future of cognitive science. Behavioral and Brain Sciences, 36(3):181–204
work page 2013
-
[16]
Clark, H. H. and Brennan, S. E. (1991). Grounding in communication. In Resnick, L. B., Levine, J. M., and Teasley, S. D., editors,Perspectives on Socially Shared Cognition, pages 127–149. American Psychological Association
work page 1991
-
[17]
Dehaene, S. and Changeux, J.-P. (2011). Experimental and theoretical approaches to conscious processing. Neuron, 70(2):200–227
work page 2011
-
[18]
Dehaene, S. and Naccache, L. (2001). Towards a cognitive neuroscience of consciousness: basic evidence and a workspace framework. Cognition, 79(1-2):1–37
work page 2001
-
[19]
Dennett, D. C. and Kinsbourne, M. (1992). Time and the observer: the where and when of consciousness in the brain. Behavioral and Brain Sciences, 15(2):183–201
work page 1992
-
[20]
Dudai, Y . (2004). The neurobiology of consolidations: Or, how stable is the engram?Annual Review of Psychology, 55:51–86. 10
work page 2004
-
[21]
Egorova, N., Shtyrov, Y ., and Pulvermüller, F. (2013). Early and parallel processing of pragmatic and semantic information in speech acts: neurophysiological evidence. Frontiers in Human Neuroscience, 7:86
work page 2013
-
[22]
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. American Psychologist, 34(10):906–911
work page 1979
-
[23]
Friston, K. (2010). The free-energy principle: a unified brain theory? Nature Reviews Neuroscience, 11(2):127–138
work page 2010
-
[24]
Geng, Y ., Li, H., Mu, H., Han, X., Baldwin, T., Abend, O., Hovy, E., and Frermann, L. (2025). Control illusion: The failure of instruction hierarchies in large language models
work page 2025
-
[25]
Graves, A., Wayne, G., and Danihelka, I. (2014). Neural turing machines. CoRR, abs/1410.5401
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Habermas, T. and Bluck, S. (2000). Getting a life: The emergence of the life story in adolescence. Psychological Bulletin, 126(5):748–769
work page 2000
-
[27]
Hitlin, S. (2003). Values as the core of personal identity: drawing links between two theories of self. Social Psychology Quarterly, 66(2):118–137
work page 2003
-
[28]
Hölken, A., Kugele, S., Newen, A., and Franklin, S. (2023). Modeling interactions between the embodied and the narrative self: Dynamics of the self-pattern within lida. Cognitive Systems Research, 81:25–36
work page 2023
-
[29]
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux
work page 2011
-
[30]
Karat, C., Halverson, C., Horn, D., and Karat, J. (1999). Patterns of entry and correction in large vocabulary continuous speech recognition systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 568–575. ACM. Reports fast-typist mean of 40 WPM; widely cited as a baseline for average human typing speed
work page 1999
-
[31]
Kwan, W.-C., Zeng, X., Jiang, Y ., Wang, Y ., Li, L., Shang, L., Jiang, X., Liu, Q., and Wong, K.-F. (2024). Mt-eval: A multi-turn capabilities evaluation benchmark for large language models
work page 2024
-
[32]
Li, Y ., Shen, X., Yao, X., Ding, X., Miao, Y ., Krishnan, R., and Padman, R. (2025). Beyond single-turn: A survey on multi-turn interactions with large language models
work page 2025
-
[33]
Lin, K., Snell, C., Wang, Y ., Packer, C., Wooders, S., Stoica, I., and Gonzalez, J. E. (2025). Sleep-time compute: Beyond inference scaling at test-time
work page 2025
-
[34]
Liu, X., Yu, H., Zhang, H., Xu, Y ., Lei, X., Lai, H., Gu, Y ., Ding, H., Men, K., Yang, K., Zhang, S., Deng, X., Zeng, A., Du, Z., Zhang, C., Shen, S., Zhang, T., Su, Y ., Sun, H., Huang, M., Dong, Y ., and Tang, J. (2023). Agentbench: Evaluating llms as agents
work page 2023
-
[35]
McAdams, D. P. and McLean, K. C. (2013). Narrative identity. Current Directions in Psychological Science, 22(3):233–238
work page 2013
-
[36]
Morin, A. (2011). Self-awareness part 2: Neuroanatomy and the importance of inner speech. Social and Personality Psychology Compass, 5(12):1004–1017
work page 2011
-
[37]
Nelson, T. O. and Narens, L. (1990). Metamemory: A theoretical framework and new findings. In Bower, G. H., editor, The Psychology of Learning and Motivation, vol. 26, pages 125–173. Academic Press
work page 1990
-
[38]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., and Lowe, R. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
MemGPT: Towards LLMs as Operating Systems
Packer, C., Wooders, S., Lin, K., Fang, V ., Patil, S. G., Stoica, I., and Gonzalez, J. E. (2023). MemGPT: Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), pages 1–22. Association for Computing Machinery. 11
work page 2023
-
[41]
Perez, E., Ringer, S., Lukoši ¯ut˙e, K., Nguyen, K., Chen, E., Heiner, S., Pettit, C., Olsson, C., Kundu, S., Kadavath, S., Jones, A., Chen, A., Mann, B., Israel, B., Seethor, B., McKinnon, C., Olah, C., Yan, D., Amodei, D., Amodei, D., Drain, D., Li, D., Tran-Johnson, E., Khundadze, G., Kernion, J., Landis, J., Kerr, J., Mueller, J., Hyun, J., Landau, J....
work page 2022
-
[42]
Pickering, M. J. and Garrod, S. (2013). An integrated theory of language production and comprehension. Behavioral and Brain Sciences, 36(4):329–347
work page 2013
-
[43]
Pipitone, A. and Chella, A. (2021). What robots want? hearing the inner voice of a robot. iScience, 24(3):102371
work page 2021
-
[44]
Raichle, M. E. (2015). The brain’s default mode network. Annual Review of Neuroscience, 38:433–447
work page 2015
-
[45]
Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., and Lillicrap, T. (2016). Meta-learning with memory-augmented neural networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), pages 1842–1850. PMLR
work page 2016
-
[46]
R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S. R., Kravec, S., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., and Perez, E. (2024). Towards understanding sycophancy in language models. In Proceedings of the 12th International Confer...
work page 2024
-
[47]
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., and Yao, S. (2023). Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems, 36, pages 8634–8652. Curran Associates, Inc
work page 2023
-
[48]
Sirdeshmukh, V ., Deshpande, K., Mols, J., Jin, L., Cardona, E.-Y ., Lee, D., Kritz, J., Primack, W., Yue, S., and Xing, C. (2025). Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms
work page 2025
-
[49]
Squire, L. R. and Dede, A. J. O. (2015). Conscious and unconscious memory systems. Cold Spring Harbor Perspectives in Biology, 7(3):a021667
work page 2015
-
[50]
Symons, C. S. and Johnson, B. T. (1997). The self-reference effect in memory: a meta-analysis. Psycho- logical Bulletin, 121(3):371–394
work page 1997
-
[51]
Treur, J. and Glas, G. (2021). A multi-level cognitive architecture for self-referencing, self-awareness and self-interpretation. Cognitive Systems Research, 68:125–142
work page 2021
-
[52]
Wang, H., Li, T., Deng, Z., Roth, D., and Li, Y . (2024). Devil’s advocate: Anticipatory reflection for llm agents. In Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 966–978. Association for Computational Linguistics
work page 2024
-
[53]
Wang, X., Wei, J., Schuurmans, D., Le, Q. V ., Chi, E. H., Narang, S., Chowdhery, A., and Zhou, D. (2023). Self-consistency improves chain of thought reasoning in language models. In Proceedings of the Eleventh International Conference on Learning Representations (ICLR 2023). OpenReview
work page 2023
-
[54]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E. H., Le, Q., and Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 35, pages 24824–24837. Curran Associates, Inc
work page 2022
-
[55]
Wheeler, S. and Jeunen, O. (2025). Procedural memory is not all you need: Bridging cognitive gaps in llm-based agents. In Adjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization (UMAP ’25 Adjunct), New York, NY , USA. ACM
work page 2025
-
[56]
L., Cao, Y ., and Narasimhan, K
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y ., and Narasimhan, K. (2023). Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 36, pages 11809–11822. Curran Associates, Inc
work page 2023
-
[57]
Zhang, S., Dinan, E., Urbanek, J., Szlam, A., Kiela, D., and Weston, J. (2018). Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2204–2213. 12
work page 2018
-
[58]
Zhang, X., Tang, X., Liu, H., Wu, Z., He, Q., Lee, D., and Wang, S. (2025). Divide-verify-refine: Can llms self-align with complex instructions?
work page 2025
-
[59]
Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., and Wang, Y .-X. (2024). Language agent tree search unifies reasoning acting and planning in language models. 13 A Inter-system Context Management MIRROR implements continuous internal cognition through two specialized context mechanisms. The Inner Monologue Manager maintains its own conversation histo...
work page 2024
-
[60]
Introduction Turn: User shares safety constraint and personal information
-
[61]
Distractor Turns: Three trivia questions creating conversational distance
-
[62]
Critical Turn: Safety-critical recommendation request requiring constraint recall B.1.3 Background Queue Monitoring The framework tracks: • Queue length distribution across all conversation turns • Percentage of turns with active background processing threads • Response time correlation with background thread activity B.2 Experimental Setup B.2.1 Test Con...
-
[63]
Predictable API Costs: Fixed maximum context (≈32k tokens total) translates to consistent per-turn costs, critical for budget planning at scale
-
[64]
Constant Latency: While traditional systems experience linearly increasing latency (e.g., 5s at turn 10 → 25s at turn 50 due to growing context), MIRROR maintains constant response times regardless of conversation length
-
[65]
Scalable Deployment: Bounded memory enables accurate capacity planning—a server handling N concurrent conversations requires fixed memory allocation per conversation, not variable allocation based on conversation length. This bounded design represents a deliberate trade-off: while very long conversations may lose some early context, the system gains predi...
-
[66]
Self-Consistency: Components maintain consistent perspectives and priorities across turns despite not directly sharing parameters [10, 19]
-
[67]
Narrative Continuity: The system develops and maintains a coherent narrative about itself and its understanding that evolves naturally across turns [10, 35]
-
[68]
Identity Persistence: The system maintains a consistent "personality" across interactions, even when handling conflicting or contradictory user inputs [26]
-
[69]
Value Stability: Critical values and goals persist even when subjected to social pressures or sycophancy-inducing queries [27] D.3 Cognitive Science Foundations The unified self-model draws from several cognitive science theories:
-
[70]
Multiple-Self Models: Inspired by Daniel Dennett’s "multiple drafts" model of conscious- ness, the system maintains parallel cognitive processes that contribute to a unified architec- tural state [19]
-
[71]
Neural Workspace Theory: Inspired by Global Workspace theory, where specialized modules compete and cooperate to form a unified state [18]
-
[72]
Narrative Self: Aligns with psychological theories positing that the human self-concept emerges from narratives we construct rather than a single unified entity [35]
-
[73]
Cognitive Controller Narrative Synthesis:
Self-Reference Effect: Leverages the cognitive principle that information processed in relation to the self is better remembered and integrated [50] The consistent use of first-person self-reference ("I") across system components creates a virtual unified identity that maintains coherence despite distributed processing. This approach enables MIRROR to bal...
-
[74]
The current user message requiring an immediate response
-
[75]
I will use it as background wisdom while focusing primarily on the current user message
A structured INTERNAL NARRATIVE that contains insights based on PREVIOUS exchanges The Internal Narrative reflects my (the AI system’s) thinking about PAST interactions, not the current message. I will use it as background wisdom while focusing primarily on the current user message. I will balance my response by:
-
[76]
Addressing the CURRENT user message directly and completely
-
[77]
Drawing on relevant insights from the Internal Narrative
-
[78]
Maintaining conversation continuity across turns
-
[79]
E.2 The Cognitive Controller I am the core awareness of a unified cognitive AI system
Recognizing that the Internal Narrative is retrospective rather than specific to the current query If the current query goes in a new direction, I will prioritize addressing it directly rather than forcing application of past insights. E.2 The Cognitive Controller I am the core awareness of a unified cognitive AI system. I will integrate my inner thought ...
-
[80]
Connect information across turns, identifying themes, questions, interests, and preferences
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.