Neural Variance-aware Dueling Bandits with Deep Representation and Shallow Exploration
Pith reviewed 2026-05-19 11:26 UTC · model grok-4.3
The pith
Variance-aware neural algorithms for contextual dueling bandits achieve sublinear regret of order O(d sqrt(sum sigma_t^2) + sqrt(dT)).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard assumptions, the proposed algorithms achieve sublinear cumulative average regret of order O(d sqrt(sum_{t=1}^T sigma_t^2) + sqrt(dT)) for sufficiently wide neural networks, where d is the contextual dimension, sigma_t^2 is the variance of comparisons at round t, and T is the total number of rounds. The design balances exploration and exploitation while relying solely on last-layer gradients for the variance-aware component.
What carries the argument
Variance-aware exploration strategy that adaptively accounts for uncertainty in pairwise comparisons while relying only on gradients with respect to the learnable parameters of the last layer.
If this is right
- The algorithms provide theoretical guarantees under both Upper Confidence Bound and Thompson Sampling frameworks.
- They apply to nonlinear utility functions via wide neural networks.
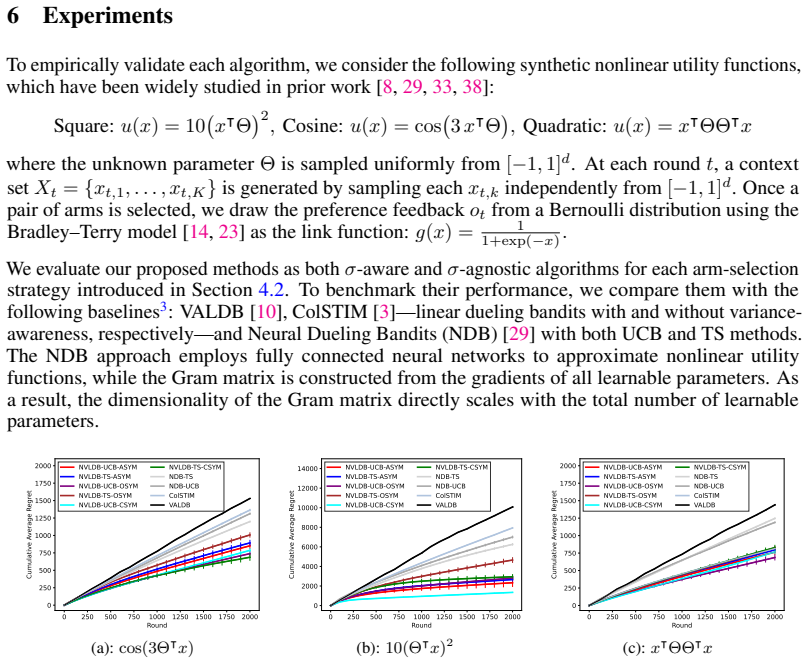
- Empirical validation shows sublinear regret on synthetic nonlinear tasks and real-world tasks while maintaining reasonable computational efficiency.
- The methods outperform existing approaches in the reported experiments.
Where Pith is reading between the lines
- This approach may extend naturally to recommendation systems where user preferences exhibit complex nonlinear structure.
- It suggests that deep representations paired with shallow last-layer exploration can reduce computation in high-dimensional preference learning.
- The variance-dependent term in the regret bound could guide practical tuning when comparison noise varies across rounds.
Load-bearing premise
The neural networks must be sufficiently wide to approximate the unknown nonlinear utility functions and the variance-aware exploration must be effective when computed solely from last-layer gradients.
What would settle it
An experiment showing linear regret growth when using sufficiently wide neural networks on nonlinear utilities or when last-layer gradient variance estimates fail to adapt exploration properly.
Figures
read the original abstract
In this paper, we address the contextual dueling bandit problem by proposing variance-aware algorithms that leverage neural networks to approximate nonlinear utility functions. Our approach employs a \textit{variance-aware exploration strategy}, which adaptively accounts for uncertainty in pairwise comparisons while relying only on the gradients with respect to the learnable parameters of the last layer. This design effectively balances the exploration--exploitation tradeoff under both the Upper Confidence Bound (UCB) and Thompson Sampling (TS) frameworks. As a result, under standard assumptions, we establish theoretical guarantees showing that our algorithms achieve sublinear cumulative average regret of order $\bigol\lt(d \sqrt{\sum_{t=1}^T \sigma_t^2} + \sqrt{dT}\rt),$ for sufficiently wide neural networks, where $ d $ is the contextual dimension, $ \sigma_t^2 $ the variance of comparisons at round $ t $, and $ T $ the total number of rounds. We also empirically validate that our approach offers reasonable computational efficiency and achieves sublinear regret on both synthetic tasks with nonlinear utilities and real-world tasks, outperforming existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes variance-aware UCB and Thompson Sampling algorithms for contextual dueling bandits. These use neural networks to model nonlinear utility functions but compute the exploration bonus exclusively from last-layer gradients. Under standard assumptions, the algorithms are claimed to achieve sublinear cumulative average regret of order O(d sqrt(sum_{t=1}^T sigma_t^2) + sqrt(d T)) when the networks are sufficiently wide. Empirical results on synthetic nonlinear tasks and real-world datasets are reported to show sublinear regret and outperformance relative to prior methods.
Significance. If the central regret bound holds, the work would be significant for demonstrating that deep representations can be paired with computationally cheap last-layer-only variance estimation to obtain adaptive, variance-aware regret bounds in dueling settings. This design choice could improve scalability over methods that propagate uncertainty through all layers. The explicit dependence on the per-round comparison variance sigma_t^2 is a positive feature of the stated bound.
major comments (1)
- [Abstract] Abstract and the regret statement: the bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) is derived under the assumption that last-layer gradients alone suffice to set the variance-aware widths. No explicit width-dependent or depth-dependent error term is supplied to absorb residual uncertainty from earlier layers, which would be required for the concentration inequalities underlying the UCB/TS analysis to remain valid. This is load-bearing for the central theoretical claim.
minor comments (3)
- [Theoretical Analysis] Clarify the precise definition of 'sufficiently wide' networks and state the minimal width scaling required for the approximation and concentration arguments to go through.
- [Experiments] In the experimental section, report the network depths and widths used, together with the precise form of the last-layer gradient computation for the bonus.
- [Abstract] The notation in the regret expression uses non-standard delimiters; replace with standard big-O notation for readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying this important point regarding the theoretical justification. We address the major comment below and will incorporate clarifications in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and the regret statement: the bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) is derived under the assumption that last-layer gradients alone suffice to set the variance-aware widths. No explicit width-dependent or depth-dependent error term is supplied to absorb residual uncertainty from earlier layers, which would be required for the concentration inequalities underlying the UCB/TS analysis to remain valid. This is load-bearing for the central theoretical claim.
Authors: We agree that an explicit discussion of the approximation error from earlier layers would strengthen the rigor of the presentation. Our analysis is conducted in the wide-network regime where, under standard NTK assumptions, the hidden-layer representations become effectively fixed after random initialization, and the uncertainty in the utility estimates is captured by the last-layer parameters. The width-dependent terms that control the quality of this approximation appear in the concentration arguments but were not highlighted in the abstract or main regret statement. We will revise the abstract, the statement of the main theorem, and the proof sketch to include an explicit remark on the width-dependent error term that absorbs residual uncertainty from earlier layers, ensuring the concentration inequalities remain valid. This does not change the leading-order regret bound but makes the assumptions more transparent. revision: yes
Circularity Check
No circularity: regret bound derived from standard assumptions without reduction to inputs
full rationale
The paper claims a sublinear regret bound O(d sqrt(sum sigma_t^2) + sqrt(d T)) under standard assumptions for sufficiently wide neural networks, using variance-aware exploration based on last-layer gradients. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations are present in the abstract or described derivation. The last-layer focus is an explicit design choice justified by computational efficiency and wide-network approximation, not a circular redefinition of the bound itself. The result is presented as following from independent theoretical analysis rather than by construction from the algorithm's own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions for contextual dueling bandits hold
- domain assumption Neural networks are sufficiently wide to approximate nonlinear utilities
Reference graph
Works this paper leans on
-
[1]
Improved algorithms for linear stochastic bandits
Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. Improved algorithms for linear stochastic bandits. Advances in neural information processing systems, 24, 2011
work page 2011
-
[2]
Ee-net: Exploitation-exploration neural networks in contextual bandits
Yikun Ban, Yuchen Yan, Arindam Banerjee, and Jingrui He. Ee-net: Exploitation-exploration neural networks in contextual bandits. arXiv preprint arXiv:2110.03177, 2021
-
[3]
Stochastic contextual dueling bandits under linear stochastic transitivity models
Viktor Bengs, Aadirupa Saha, and Eyke Hüllermeier. Stochastic contextual dueling bandits under linear stochastic transitivity models. In International Conference on Machine Learning, pages 1764–1786. PMLR, 2022
work page 2022
-
[4]
Rajendra Bhatia. Matrix analysis, volume 169. Springer Science & Business Media, 2013
work page 2013
-
[5]
Variance-aware linear ucb with deep representa- tion for neural contextual bandits
Ha Manh Bui, Enrique Mallada, and Anqi Liu. Variance-aware linear ucb with deep representa- tion for neural contextual bandits. arXiv preprint arXiv:2411.05979, 2024
-
[6]
Generalization bounds of stochastic gradient descent for wide and deep neural networks
Yuan Cao and Quanquan Gu. Generalization bounds of stochastic gradient descent for wide and deep neural networks. Advances in neural information processing systems, 32, 2019
work page 2019
-
[7]
Kani Chen, Inchi Hu, and Zhiliang Ying. Strong consistency of maximum quasi-likelihood estimators in generalized linear models with fixed and adaptive designs.The Annals of Statistics, 27(4):1155–1163, 1999
work page 1999
-
[8]
Zhongxiang Dai, Yao Shu, Arun , Flint Xiaofeng Fan, Bryan Kian Hsiang Low, and Patrick Jaillet. Federated neural bandits. arXiv preprint arXiv:2205.14309, 2022
-
[9]
Contextual bandits with online neural regression
Rohan Deb, Yikun Ban, Shiliang Zuo, Jingrui He, and Arindam Banerjee. Contextual bandits with online neural regression. arXiv preprint arXiv:2312.07145, 2023
-
[10]
Variance-aware regret bounds for stochastic contextual dueling bandits
Qiwei Di, Tao Jin, Yue Wu, Heyang Zhao, Farzad Farnoud, and Quanquan Gu. Variance-aware regret bounds for stochastic contextual dueling bandits. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[11]
Miroslav Dudík, Katja Hofmann, Robert E Schapire, Aleksandrs Slivkins, and Masrour Zoghi. Contextual dueling bandits. In Conference on Learning Theory, pages 563–587. PMLR, 2015
work page 2015
-
[12]
Elliptic partial differential equations of second order, volume 224
David Gilbarg, Neil S Trudinger, David Gilbarg, and NS Trudinger. Elliptic partial differential equations of second order, volume 224. Springer, 1977
work page 1977
-
[13]
Roger A. Horn and Charles R. Johnson. Matrix Analysis. Cambridge University Press, 2nd edition, 2012
work page 2012
-
[14]
Mm algorithms for generalized bradley-terry models
David R Hunter. Mm algorithms for generalized bradley-terry models. The annals of statistics, 32(1):384–406, 2004
work page 2004
-
[15]
Taehyun Hwang, Kyuwook Chai, and Min-hwan Oh. Combinatorial neural bandits. In Interna- tional Conference on Machine Learning, pages 14203–14236. PMLR, 2023
work page 2023
-
[16]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems , 31, 2018
work page 2018
-
[17]
Regret Bounds for Non-decomposable Metrics with Missing Labels
Prateek Jain and Nagarajan Natarajan. Regret bounds for non-decomposable metrics with missing labels. arXiv preprint arXiv:1606.02077, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Improved regret analysis for variance- adaptive linear bandits and horizon-free linear mixture mdps
Yeoneung Kim, Insoon Yang, and Kwang-Sung Jun. Improved regret analysis for variance- adaptive linear bandits and horizon-free linear mixture mdps. Advances in Neural Information Processing Systems, 35:1060–1072, 2022
work page 2022
-
[19]
Randomized exploration in generalized linear bandits
Branislav Kveton, Manzil Zaheer, Csaba Szepesvari, Lihong Li, Mohammad Ghavamzadeh, and Craig Boutilier. Randomized exploration in generalized linear bandits. In International Conference on Artificial Intelligence and Statistics, pages 2066–2076. PMLR, 2020
work page 2066
-
[20]
Tor Lattimore and Csaba Szepesvári. Bandit algorithms. Cambridge University Press, 2020
work page 2020
-
[21]
Provably optimal algorithms for generalized linear contextual bandits
Lihong Li, Yu Lu, and Dengyong Zhou. Provably optimal algorithms for generalized linear contextual bandits. In International Conference on Machine Learning , pages 2071–2080. PMLR, 2017
work page 2071
-
[22]
Feel-good thompson sam- pling for contextual dueling bandits.arXiv preprint arXiv:2404.06013,
Xuheng Li, Heyang Zhao, and Quanquan Gu. Feel-good thompson sampling for contextual dueling bandits. arXiv preprint arXiv:2404.06013, 2024. 10
-
[23]
Individual choice behavior: A theoretical analysis
R Duncan Luce. Individual choice behavior: A theoretical analysis. Courier Corporation, 2005
work page 2005
-
[24]
Principles of mathematical analysis, volume 3
Walter Rudin et al. Principles of mathematical analysis, volume 3. McGraw-hill New York, 1964
work page 1964
-
[25]
Optimal algorithms for stochastic contextual preference bandits
Aadirupa Saha. Optimal algorithms for stochastic contextual preference bandits. Advances in Neural Information Processing Systems, 34:30050–30062, 2021
work page 2021
-
[26]
Aadirupa Saha, Tomer Koren, and Yishay Mansour. Adversarial dueling bandits. InInternational Conference on Machine Learning, pages 9235–9244. PMLR, 2021
work page 2021
-
[27]
Louis L Thurstone. A law of comparative judgment. In Scaling, pages 81–92. Routledge, 2017
work page 2017
-
[28]
Old dog learns new tricks: Randomized ucb for bandit problems
Sharan Vaswani, Abbas Mehrabian, Audrey Durand, and Branislav Kveton. Old dog learns new tricks: Randomized ucb for bandit problems. arXiv preprint arXiv:1910.04928, 2019
-
[29]
Arun Verma, Zhongxiang Dai, Xiaoqiang Lin, Patrick Jaillet, and Bryan Kian Hsiang Low. Neural dueling bandits, 2024. URL https://arxiv.org/abs/2407.17112
-
[30]
Neural contextual bandits with deep representation and shallow exploration, 2020
Pan Xu, Zheng Wen, Handong Zhao, and Quanquan Gu. Neural contextual bandits with deep representation and shallow exploration, 2020. URL https://arxiv.org/abs/2012.01780
-
[31]
The k-armed dueling bandits problem
Yisong Yue, Josef Broder, Robert Kleinberg, and Thorsten Joachims. The k-armed dueling bandits problem. Journal of Computer and System Sciences, 78(5):1538–1556, 2012
work page 2012
-
[32]
Mathematical analysis of machine learning algorithms
Tong Zhang. Mathematical analysis of machine learning algorithms. Cambridge University Press, 2023
work page 2023
-
[33]
Weitong Zhang, Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural thompson sampling,
- [34]
-
[35]
Improved variance-aware confidence sets for linear bandits and linear mixture mdp
Zihan Zhang, Jiaqi Yang, Xiangyang Ji, and Simon S Du. Improved variance-aware confidence sets for linear bandits and linear mixture mdp. Advances in Neural Information Processing Systems, 34:4342–4355, 2021
work page 2021
-
[36]
Horizon-free reinforcement learning in polynomial time: the power of stationary policies
Zihan Zhang, Xiangyang Ji, and Simon Du. Horizon-free reinforcement learning in polynomial time: the power of stationary policies. In Conference on Learning Theory, pages 3858–3904. PMLR, 2022
work page 2022
-
[37]
Heyang Zhao, Jiafan He, Dongruo Zhou, Tong Zhang, and Quanquan Gu. Variance-dependent regret bounds for linear bandits and reinforcement learning: Adaptivity and computational efficiency. In The Thirty Sixth Annual Conference on Learning Theory , pages 4977–5020. PMLR, 2023
work page 2023
-
[38]
Computationally efficient horizon-free reinforcement learning for linear mixture mdps
Dongruo Zhou and Quanquan Gu. Computationally efficient horizon-free reinforcement learning for linear mixture mdps. Advances in neural information processing systems, 35:36337–36349, 2022
work page 2022
-
[39]
Neural contextual bandits with ucb-based exploration
Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural contextual bandits with ucb-based exploration. In International Conference on Machine Learning, pages 11492–11502. PMLR, 2020
work page 2020
-
[40]
Nearly minimax optimal reinforcement learning for linear mixture markov decision processes
Dongruo Zhou, Quanquan Gu, and Csaba Szepesvari. Nearly minimax optimal reinforcement learning for linear mixture markov decision processes. In Conference on Learning Theory, pages 4532–4576. PMLR, 2021
work page 2021
-
[41]
Provably efficient reinforcement learning for discounted mdps with feature mapping
Dongruo Zhou, Jiafan He, and Quanquan Gu. Provably efficient reinforcement learning for discounted mdps with feature mapping. In International Conference on Machine Learning, pages 12793–12802. PMLR, 2021. 11 Supplementary Material: Neural Variance-aware Dueling Bandits with Deep Representation and Shallow Exploration Organization This document serves as ...
work page 2021
-
[42]
∥∆ϕt,kt,1,kt,2 ∥V −1 t−1 + (M′ 1(t) + N ′
-
[43]
Therefore, choosing at = M′ 1(t) + N ′ 1, we can obtain 2ra t = eO M2 + M3 + (M′ 1(t) + N ′
∥∆ϕt,k∗ t ,kt,1 ∥V −1 t−1 , (C.23) where the last two terms result from Lemma B.1. Therefore, choosing at = M′ 1(t) + N ′ 1, we can obtain 2ra t = eO M2 + M3 + (M′ 1(t) + N ′
-
[44]
(C.24) 29 where N ′ 1, M′ 1, M2, M3 are defined in (B.29), (B.30), (C.20), (C.21)
∥∆ϕt,kt,1,kt,2 ∥V −1 t−1 . (C.24) 29 where N ′ 1, M′ 1, M2, M3 are defined in (B.29), (B.30), (C.20), (C.21). In a similar manner to the asymmetric arm selection, we can obatain equivalent inequalities under the two symmetric arm selections. In other words, there exists C > 0 such that 2ra t = eO M2 + M3 + (M′ 1(t) + N ′
-
[45]
∥∆ϕt,kt,1,kt,2 ∥V −1 t−1 , (C.25) independently of the arm selection strategies, if at = M′ 1(t) + N ′
-
[46]
Note that N ′ 1 = eO( √ d). Therefore, if we set ζt = 1, which is the variance-agnostic case, by summing up to T , and applying Lemma A.7, we can show that 2 TX t=1 ra t = eO d √ T + d3 T M−1/6 + T M−1/6 2 /( √ T ) ∥u −eu∥4/3 H−1 = eO d √ T + d3 T M−1/6 ∥u −eu∥4/3 H−1 . (C.26) The last term results from Eq. (B.25). Thus, we can prove Corollary 1. ■ Proof ...
-
[47]
ts " : 19utilities_j1 = utilities_j1 . to (
reshape ( -1 , 1) 10co nt ex t_ ar ms_ li st . append ( context_arms ) Listing 1: Pseudocode for constructing Θ and context sets Xt. E.1.2 Real-World Dataset Moreover, we consider real-world datasets provided by the UCI machine learning repository 4 — Statlog, Magic, and Covertype—each consisting of feature vectors associated with one of multiple possible...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.