OD3: Optimization-free Dataset Distillation for Object Detection
Pith reviewed 2026-05-19 10:42 UTC · model grok-4.3
The pith
OD3 distills object detection datasets to tiny sizes without any optimization, beating prior methods by over 14% mAP50 on COCO at 1% compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
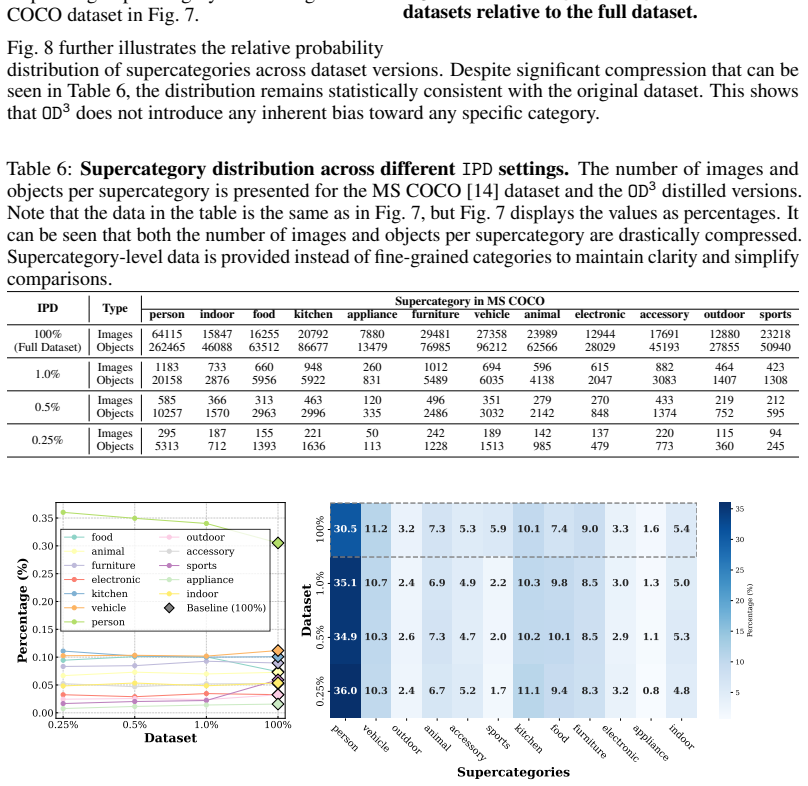
OD3 is an optimization-free dataset distillation framework for object detection that operates in two stages. The first stage performs candidate selection by iteratively placing object instances into synthesized images at suitable locations. The second stage performs candidate screening by passing the synthesized images through a pre-trained observer model and removing objects that receive low confidence scores. When tested on MS COCO and PASCAL VOC at compression ratios between 0.25% and 5%, the resulting datasets yield higher detection accuracy than the sole prior detection-specific distillation method and conventional core-set selection baselines, including an improvement of more than 14%m
What carries the argument
The two-stage pipeline of location-based instance placement for candidate selection followed by pre-trained observer model screening to remove low-confidence objects.
If this is right
- Detectors trained on the distilled sets maintain higher accuracy than those trained on data from earlier distillation or selection techniques at the same compression level.
- The approach works directly on standard benchmarks such as MS COCO and PASCAL VOC across a range of compression ratios from 0.25% to 5%.
- No gradient-based optimization is required during the synthesis process, lowering the compute needed to create the distilled data.
- Smaller synthetic datasets allow faster iteration and reduced resource use when training object detection models.
Where Pith is reading between the lines
- The placement and screening steps could be adapted to other dense prediction tasks such as semantic segmentation if the observer model is swapped for a segmentation network.
- Performance may degrade if the observer model was trained on data whose distribution differs strongly from the target detection task.
- Combining the non-optimization placement heuristic with limited optimization on a subset of parameters might yield further accuracy gains at moderate extra cost.
Load-bearing premise
Suitable locations for placing object instances can be identified reliably and a pre-trained observer model can remove low-quality placements without introducing systematic errors.
What would settle it
Train a standard object detector on the OD3-synthesized 1% COCO dataset and compute mAP50; if the score falls below the previous best distillation or core-set result by more than a small margin, the performance claim is refuted.
Figures







read the original abstract
Training large neural networks on large-scale datasets requires substantial computational resources, particularly for dense prediction tasks such as object detection. Although dataset distillation (DD) has been proposed to alleviate these demands by synthesizing compact datasets from larger ones, most existing work focuses solely on image classification, leaving the more complex detection setting largely unexplored. In this paper, we introduce OD3, a novel optimization-free data distillation framework specifically designed for object detection. Our approach involves two stages: first, a candidate selection process in which object instances are iteratively placed in synthesized images based on their suitable locations, and second, a candidate screening process using a pre-trained observer model to remove low-confidence objects. We perform our data synthesis framework on MS COCO and PASCAL VOC, two popular detection datasets, with compression ratios ranging from 0.25% to 5%. Compared to the prior solely existing dataset distillation method on detection and conventional core set selection methods, OD3 delivers superior accuracy, establishes new state-of-the-art results, surpassing prior best method by more than 14% on COCO mAP50 at a compression ratio of 1.0%. Code is available at: https://github.com/VILA-Lab/OD3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OD3, an optimization-free dataset distillation framework for object detection consisting of two stages: (1) iterative candidate selection that places object instances into synthesized images at heuristically determined suitable locations, and (2) candidate screening that uses a pre-trained observer model to filter low-confidence detections. Experiments are performed on MS COCO and PASCAL VOC at compression ratios 0.25%–5%; the central claim is that OD3 outperforms the sole prior detection-specific DD method and conventional core-set baselines, establishing new SOTA results including a >14% mAP50 gain on COCO at 1% compression.
Significance. If the performance claims hold under rigorous controls, the work would be significant because it extends dataset distillation to the more complex object-detection setting and demonstrates that an explicitly optimization-free pipeline can still produce usable distilled sets. The public code release at https://github.com/VILA-Lab/OD3 is a concrete strength that supports reproducibility.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of >14% mAP50 improvement over the prior best method at 1% compression on COCO is load-bearing for the paper’s contribution, yet the manuscript supplies no description of the training protocol for the downstream detector, the exact baselines (including their hyper-parameters and implementation details), the number of random seeds, or any statistical significance tests. Without these elements the superiority cannot be assessed for post-hoc selection or missing controls.
- [§3.1] §3.1 (Candidate Selection): the iterative placement of object instances into “suitable locations” is described only at the level of heuristic rules with no equations, saliency map formulation, or geometric constraints; because the entire framework is optimization-free, any weakness in this placement heuristic directly determines whether the reported accuracy gains are explained by the proposed mechanism rather than by the observer screening step alone.
minor comments (2)
- [§4] The compression-ratio definition (images or instances per class) should be stated explicitly in the experimental setup to allow direct comparison with prior DD literature.
- [Figure 3] Figure captions for the synthesized images should indicate the observer-model threshold used during screening so readers can reproduce the filtering step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below and will revise the manuscript to incorporate additional details and clarifications where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of >14% mAP50 improvement over the prior best method at 1% compression on COCO is load-bearing for the paper’s contribution, yet the manuscript supplies no description of the training protocol for the downstream detector, the exact baselines (including their hyper-parameters and implementation details), the number of random seeds, or any statistical significance tests. Without these elements the superiority cannot be assessed for post-hoc selection or missing controls.
Authors: We agree that these experimental details are essential for assessing the validity of the reported gains. In the revised manuscript, we will expand §4 to provide: a full specification of the downstream detector training protocol (architecture, optimizer, learning rate, epochs, and data augmentation); precise hyper-parameters and implementation notes for every baseline, including the prior detection-specific DD method; results averaged over multiple random seeds with standard deviations; and statistical significance tests (e.g., t-tests) comparing OD3 against baselines. The public code repository will be referenced explicitly for exact reproduction. revision: yes
-
Referee: [§3.1] §3.1 (Candidate Selection): the iterative placement of object instances into “suitable locations” is described only at the level of heuristic rules with no equations, saliency map formulation, or geometric constraints; because the entire framework is optimization-free, any weakness in this placement heuristic directly determines whether the reported accuracy gains are explained by the proposed mechanism rather than by the observer screening step alone.
Authors: We acknowledge that the current description of candidate selection remains at a high-level heuristic. In the revision we will formalize §3.1 by adding equations for the iterative placement procedure, explicit geometric constraints (non-overlap, border margins, scale consistency), and any saliency considerations used to score locations. We will also insert an ablation study that isolates the placement heuristic from the observer screening step, thereby demonstrating that both stages contribute to the final performance rather than screening alone. revision: yes
Circularity Check
No circularity: heuristic pipeline with independent empirical claims
full rationale
The paper describes an optimization-free two-stage procedure consisting of iterative candidate selection for placing object instances into synthesized images followed by screening via a pre-trained observer model. No equations, fitted parameters, or self-citations are presented that reduce the reported mAP improvements or SOTA claims to the method's own inputs by construction. The performance numbers are obtained by training detectors on the resulting distilled sets and evaluating on held-out test data from COCO and VOC, which constitutes an external benchmark rather than a tautological re-expression of any internal fit or prior self-result. The derivation chain is therefore self-contained as a sequence of heuristic steps whose validity is tested empirically rather than assumed.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Object instances can be iteratively placed into synthesized images at suitable locations without requiring optimization.
- domain assumption A pre-trained observer model can effectively identify and remove low-confidence objects from the synthesized images.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
candidate selection process in which object instances are iteratively placed in synthesized images based on their suitable locations, and second, a candidate screening process using a pre-trained observer model to remove low-confidence objects
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Information Density Φ(x) = ... aggregate detection confidence scores ... combined area
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A fast knowledge distillation framework for visual recognition
Zhiqiang Shen and Eric Xing. A fast knowledge distillation framework for visual recognition. In European conference on computer vision, pages 673–690. Springer, 2022
work page 2022
-
[2]
Pkd: General distillation framework for object detectors via pearson correlation coefficient
Weihan Cao, Yifan Zhang, Jianfei Gao, Anda Cheng, Ke Cheng, and Jian Cheng. Pkd: General distillation framework for object detectors via pearson correlation coefficient. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 15394–15406. Curran Associates, Inc., 2022
work page 2022
-
[3]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[4]
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Shaoqing Ren. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv preprint arXiv:1506.01497, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023
work page 2023
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[8]
Scaling vision transformers to 22 billion parameters
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, An- dreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning, pages 7480–7512. PMLR, 2023
work page 2023
-
[9]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
work page 2019
-
[10]
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective
Zeyuan Yin, Eric Xing, and Zhiqiang Shen. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[11]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Channel-wise knowledge distillation for dense prediction
Changyong Shu, Yifan Liu, Jianfei Gao, Zheng Yan, and Chunhua Shen. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5311–5320, 2021
work page 2021
-
[13]
Fetch and forge: Efficient dataset condensation for object detection
Ding Qi, Jian Li, Jinlong Peng, Bo Zhao, Shuguang Dou, Jialin Li, Jiangning Zhang, Yabiao Wang, Chengjie Wang, and Cairong Zhao. Fetch and forge: Efficient dataset condensation for object detection. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[14]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
work page 2014
-
[15]
Mark Everingham, Luc Van Gool, C. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88:303–338, 2010. 10
work page 2010
-
[16]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[17]
Openmmlab model compression toolbox and benchmark
MMRazor Contributors. Openmmlab model compression toolbox and benchmark. https://github. com/open-mmlab/mmrazor, 2021
work page 2021
-
[18]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
work page 2001
-
[19]
Coreset selection for object detection
Hojun Lee, Suyoung Kim, Junhoo Lee, Jaeyoung Yoo, and Nojun Kwak. Coreset selection for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 7682–7691, 2024
work page 2024
-
[20]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
End-to-end incremental learning
Francisco M Castro, Manuel J Marín-Jiménez, Nicolás Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. In Proceedings of the European conference on computer vision (ECCV), pages 233–248, 2018
work page 2018
-
[22]
Super-Samples from Kernel Herding
Yutian Chen, Max Welling, and Alex Smola. Super-samples from kernel herding. arXiv preprint arXiv:1203.3472, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[23]
Focal Loss for Dense Object Detection
T Lin. Focal loss for dense object detection. arXiv preprint arXiv:1708.02002, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Exploring plain vision transformer backbones for object detection
Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In European conference on computer vision, pages 280–296. Springer, 2022
work page 2022
-
[25]
Deepcore: A comprehensive library for coreset selection in deep learning
Chengcheng Guo, Bo Zhao, and Yanbing Bai. Deepcore: A comprehensive library for coreset selection in deep learning. In International Conference on Database and Expert Systems Applications, pages 181–195. Springer, 2022
work page 2022
-
[26]
Coresets for ordered weighted clustering
Vladimir Braverman, Shaofeng H-C Jiang, Robert Krauthgamer, and Xuan Wu. Coresets for ordered weighted clustering. In International Conference on Machine Learning, pages 744–753. PMLR, 2019
work page 2019
-
[27]
Coresets for clustering with fairness constraints
Lingxiao Huang, Shaofeng Jiang, and Nisheeth Vishnoi. Coresets for clustering with fairness constraints. Advances in neural information processing systems, 32, 2019
work page 2019
-
[28]
Training-free dataset pruning for instance segmentation
Anonymous. Training-free dataset pruning for instance segmentation. In Submitted to The Thirteenth International Conference on Learning Representations, 2024. under review
work page 2024
-
[29]
Dataset Distillation , journal =
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018
-
[30]
Dataset distillation by matching training trajectories
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4750–4759, 2022
work page 2022
-
[31]
On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9390–9399, 2024
work page 2024
-
[32]
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4750–4759, 2022. 11 Appendix A Limitations and Societal Impacts There are many potential societal impacts of our work, such...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.