FedShield-LLM: A Secure and Scalable Federated Fine-Tuned Large Language Model
Pith reviewed 2026-05-22 01:36 UTC · model grok-4.3
The pith
FedShield-LLM applies pruning and fully homomorphic encryption to LoRA parameters so federated LLM fine-tuning stays private without differential privacy's accuracy cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
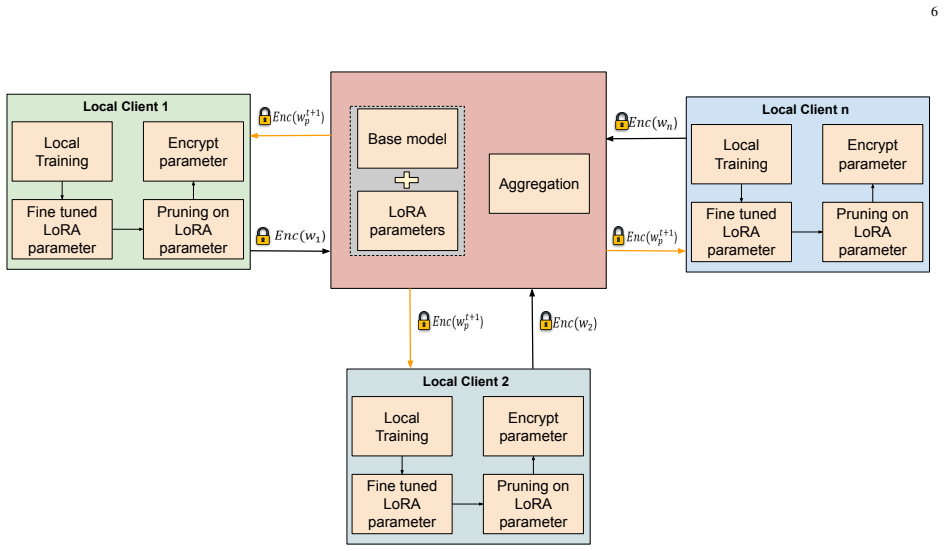
FedShield-LLM shows that pruning low-importance LoRA parameters and encrypting the remainder with fully homomorphic encryption enables secure aggregation of model updates in federated learning, delivering superior task performance and lower overhead than differential-privacy baselines while limiting inference risks.
What carries the argument
Pruning of LoRA parameters combined with fully homomorphic encryption, which deactivates unimportant weights to shrink the attack surface and permits direct computation on encrypted updates.
If this is right
- Reduces communication and compute demands for smaller organizations that cannot train LLMs alone.
- Supports task-specific LLM development across domains without exposing raw data or full model updates.
- Scales to 7B and 13B parameter models while maintaining competitive collaborative performance.
- Limits the attack surface for model-inversion and inference threats that target gradient or parameter exchanges.
Where Pith is reading between the lines
- The same pruning-plus-FHE pattern could be tested on other parameter-efficient adapters beyond LoRA to broaden applicability.
- Cross-domain results suggest the approach may generalize to regulated fields where both privacy and model quality are mandatory.
- Future evaluations could measure exact attack success rates under stronger adaptive adversaries to quantify the security margin.
Load-bearing premise
Pruning selected LoRA parameters and encrypting the rest will keep enough model capability to beat differential-privacy baselines while adding real security in cross-silo federated settings.
What would settle it
A direct head-to-head run on the same Llama-2 7B and 13B models and four datasets where FedShield-LLM shows either lower final accuracy or higher successful inference-attack rate than a standard differential-privacy federated baseline.
Figures



read the original abstract
Federated Learning (FL) offers a decentralized framework for training and fine-tuning Large Language Models (LLMs) by leveraging computational resources across organizations while keeping sensitive data on local devices. It addresses privacy and security concerns while navigating challenges associated with the substantial computational demands of LLMs, which can be prohibitive for small and medium-sized organizations. FL supports the development of task-specific LLMs for cross-silo applications through fine-tuning but remains vulnerable to inference-related risks that threaten sensitive information. Prior studies have utilized Differential Privacy (DP) in LLM fine-tuning, which, despite being effective at preserving privacy, can degrade model performance. To overcome these challenges, we propose FedShield-LLM which integrates pruning with Fully Homomorphic Encryption (FHE) applied to Low-Rank Adaptation (LoRA) parameters. This combination enables secure computation over encrypted model updates and reduces the attack surface by deactivating less important LoRA parameters. Furthermore, optimized federated algorithms for cross-silo environments enhance scalability and efficiency. Parameter-efficient fine-tuning techniques like LoRA substantially reduce computational and communication overhead, making FL feasible for resource-constrained clients. Extensive experiments using Llama-2 models (7B and 13B) on four diverse datasets demonstrate that FedShield-LLM achieves superior collaborative performance and system efficiency compared to existing methods, supporting practical deployment across multiple domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedShield-LLM, a federated fine-tuning framework for LLMs that combines pruning of LoRA parameters with Fully Homomorphic Encryption (FHE) to enable secure aggregation of updates while reducing the attack surface. It claims this yields better utility and efficiency than differential-privacy baselines for Llama-2 (7B/13B) models on four datasets in cross-silo settings.
Significance. If the experimental results hold, the work would offer a concrete alternative to DP-based LLM fine-tuning in FL by trading pruning-induced capacity loss against encryption overhead, potentially supporting practical secure deployments where performance degradation must be minimized.
major comments (2)
- The central claim that pruned LoRA updates under FHE outperform DP-protected FL rests on the assumption that pruning preserves enough task-specific capacity. The manuscript must specify the pruning ratios/thresholds, retained effective rank after pruning, and quantitative comparison of utility loss versus DP noise on the four datasets; without these, it is impossible to verify that the retained subspace suffices for the reported superiority.
- Security evaluation section: concrete metrics (e.g., success rates of inference attacks before/after pruning+FHE, formal FHE security parameters, or overhead measurements) are required to substantiate the claim of meaningful security gains; the current description of reduced attack surface via pruning is qualitative and does not address whether FHE overhead remains practical for 7B/13B models.
minor comments (2)
- Clarify the exact federated aggregation algorithm and how FHE is applied only to the pruned LoRA deltas versus full parameters.
- Add a table summarizing pruning ratios, communication volume, and wall-clock times for each baseline and dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and quantitative details.
read point-by-point responses
-
Referee: The central claim that pruned LoRA updates under FHE outperform DP-protected FL rests on the assumption that pruning preserves enough task-specific capacity. The manuscript must specify the pruning ratios/thresholds, retained effective rank after pruning, and quantitative comparison of utility loss versus DP noise on the four datasets; without these, it is impossible to verify that the retained subspace suffices for the reported superiority.
Authors: We agree that explicit specification of these parameters is necessary to allow verification of our claims. In the revised manuscript, we will add the exact pruning ratios and thresholds applied to the LoRA parameters, the procedure for computing the retained effective rank after pruning, and a quantitative side-by-side comparison of utility loss from pruning versus the degradation introduced by DP noise, reported separately for each of the four datasets and both model sizes. revision: yes
-
Referee: Security evaluation section: concrete metrics (e.g., success rates of inference attacks before/after pruning+FHE, formal FHE security parameters, or overhead measurements) are required to substantiate the claim of meaningful security gains; the current description of reduced attack surface via pruning is qualitative and does not address whether FHE overhead remains practical for 7B/13B models.
Authors: We acknowledge that the current security discussion is largely qualitative. In the revised version, we will expand the security evaluation section to include concrete metrics: success rates of representative inference attacks measured before and after the combined pruning and FHE steps, the formal security parameters (including bit-security level) of the FHE scheme employed, and detailed overhead measurements (computation time and communication volume) for the Llama-2 7B and 13B models to demonstrate practicality in cross-silo settings. revision: yes
Circularity Check
No circularity: claims rest on proposed architecture plus independent experiments
full rationale
The manuscript proposes FedShield-LLM by combining parameter pruning, fully homomorphic encryption on LoRA adapters, and optimized cross-silo federated algorithms. Central performance claims are grounded in reported experiments with Llama-2 7B/13B models on four datasets rather than any derivation chain. No equations appear that define a quantity in terms of itself or that rename a fitted parameter as a prediction. Self-citations, if present, are not load-bearing for the core method or results; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
FedShield-LLM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hadi Amini, Md Jueal Mia, Yasaman Saadati, Ahmed Imteaj, Seyedsina Nabavirazavi, Urmish Thakker, Md Zarif Hossain, Awal Ahmed Fime, and SS Iyengar. Distributed llms and multimodal large language models: A survey on advances, challenges, and future directions. arXiv preprint arXiv:2503.16585, 2025
-
[2]
Federated fine-tuning of large language models under heterogeneous tasks and client resources
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, and Yaliang Li. Federated fine-tuning of large language models under heterogeneous tasks and client resources. arXiv preprint arXiv:2402.11505 , 2024
-
[3]
Jeeyun Sophia Baik. Data privacy against inno- vation or against discrimination?: The case of the california consumer privacy act (ccpa). Telematics and Informatics, 52, 2020
work page 2020
-
[4]
Tenseal: A library for en- crypted tensor operations using homomorphic en- cryption
Ayoub Benaissa, Bilal Retiat, Bogdan Cebere, and Alaa Eddine Belfedhal. Tenseal: A library for en- crypted tensor operations using homomorphic en- cryption. arXiv preprint arXiv:2104.03152 , 2021
-
[5]
Practical Secure Aggregation for Federated Learning on User-Held Data
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sar- var Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for feder- ated learning on user-held data. arXiv preprint arXiv:1611.04482, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Practical secure aggregation for privacy-preserving machine learning
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy-preserving machine learning. In proceedings of the 2017 ACM SIGSAC Conference on Computer and Communi- cations Security, pages 1175–1191, 2017
work page 2017
-
[7]
Data protection in the united states
Shawn Marie Boyne. Data protection in the united states. The American Journal of Comparative Law , 66(suppl 1):299–343, 2018
work page 2018
-
[8]
Language models are few- shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few- shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[9]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In 30th USENIX security symposium (USENIX Security 21) , pages 2633– 2650, 2021
work page 2021
-
[10]
Homomorphic encryption for arith- metic of approximate numbers
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. Homomorphic encryption for arith- metic of approximate numbers. In Advances in Cryptology–ASIACRYPT 2017: 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, December 3-7, 2017, Proceedings, Part I 23, pages 409–437. Springer, 2017
work page 2017
-
[11]
Palm: Scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023
work page 2023
-
[12]
Security and privacy challenges of large lan- guage models: A survey
Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. Security and privacy challenges of large lan- guage models: A survey. ACM Computing Surveys, 57(6):1–39, 2025
work page 2025
-
[13]
The algorithmic foundations of differential privacy
Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science , 9(3–4):211–407, 2014
work page 2014
-
[14]
Federated Co-tuning Framework for Large and Small Language Models
Tao Fan, Yan Kang, Guoqiang Ma, Lixin Fan, Kai Chen, and Qiang Yang. Fedcollm: A parameter- efficient federated co-tuning framework for large and small language models. arXiv preprint arXiv:2411.11707, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Jonas Geiping, Hartmut Bauermeister, Hannah Dr¨oge, and Michael Moeller. Inverting gradients- how easy is it to break privacy in federated learn- ing? Advances in neural information processing systems, 33:16937–16947, 2020
work page 2020
-
[16]
Cs-mia: Membership inference attack based on prediction confidence series in federated learning
Yuhao Gu, Yuebin Bai, and Shubin Xu. Cs-mia: Membership inference attack based on prediction confidence series in federated learning. Journal of Information Security and Applications , 67:103201, 2022
work page 2022
-
[17]
Medalpaca–an open-source collection of medical conversational ai models and training data
Tianyu Han, Lisa C Adams, Jens-Michalis Pa- paioannou, Paul Grundmann, Tom Oberhauser, Alexander L ¨oser, Daniel Truhn, and Keno K Bressem. Medalpaca–an open-source collection of medical conversational ai models and training data. arXiv preprint arXiv:2304.08247 , 2023
-
[18]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022
work page 2022
-
[20]
A survey on federated learning for resource-constrained iot devices
Ahmed Imteaj, Urmish Thakker, Shiqiang Wang, Jian Li, and M Hadi Amini. A survey on federated learning for resource-constrained iot devices. IEEE Internet of Things Journal , 9(1):1–24, 2021
work page 2021
-
[21]
Weirui Kuang, Bingchen Qian, Zitao Li, Daoyuan Chen, Dawei Gao, Xuchen Pan, Yuexiang Xie, Yaliang Li, Bolin Ding, and Jingren Zhou. 15 Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5260–5271, 2024
work page 2024
-
[22]
Openai’s gpt-3: Language model: A technical overview
Lambda Labs. Openai’s gpt-3: Language model: A technical overview. Blog post: https://lambda.ai/blog, 2020
work page 2020
-
[23]
Federated optimization in heterogeneous networks
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems , 2:429–450, 2020
work page 2020
-
[24]
Yang Li, Wenhan Yu, and Jun Zhao. Privtuner with homomorphic encryption and lora: A p3eft scheme for privacy-preserving parameter-efficient fine-tuning of ai foundation models. arXiv preprint arXiv:2410.00433, 2024
-
[25]
Efficient and secure federated learning for financial applications
Tao Liu, Zhi Wang, Hui He, Wei Shi, Liangliang Lin, Ran An, and Chenhao Li. Efficient and secure federated learning for financial applications. Applied Sciences, 13(10):5877, 2023
work page 2023
-
[26]
Fingpt: Democratizing internet-scale data for financial large language models,
Xiao-Yang Liu, Guoxuan Wang, Hongyang Yang, and Daochen Zha. Fingpt: Democratizing internet- scale data for financial large language models. arXiv preprint arXiv:2307.10485 , 2023
-
[27]
Differentially private low-rank adaptation of large language model using federated learning
Xiao-Yang Liu, Rongyi Zhu, Daochen Zha, Jiechao Gao, Shan Zhong, Matt White, and Meikang Qiu. Differentially private low-rank adaptation of large language model using federated learning. ACM Transactions on Management Information Systems, 2023
work page 2023
-
[28]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017
work page 2017
-
[29]
Quancrypt- fl: Quantized homomorphic encryption with prun- ing for secure federated learning
Md Jueal Mia and M Hadi Amini. Quancrypt- fl: Quantized homomorphic encryption with prun- ing for secure federated learning. arXiv preprint arXiv:2411.05260, 2024
-
[30]
Secureml: A system for scalable privacy-preserving machine learning
Payman Mohassel and Yupeng Zhang. Secureml: A system for scalable privacy-preserving machine learning. In 2017 IEEE symposium on security and privacy (SP), pages 19–38. IEEE, 2017
work page 2017
-
[31]
OpenAI. Gpt-4 technical report. https://openai.com/research/gpt-4, 2023
work page 2023
-
[32]
Prashanthi Ramachandran, Shivam Agarwal, Arup Mondal, Aastha Shah, and Debayan Gupta. S++: A fast and deployable secure-computation frame- work for privacy-preserving neural network train- ing. arXiv preprint arXiv:2101.12078 , 2021
-
[33]
Adaptive Federated Optimization
Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Kone ˇcn`y, San- jiv Kumar, and H Brendan McMahan. Adap- tive federated optimization. arXiv preprint arXiv:2003.00295, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[34]
Federated learning: Challenges, methods, and future directions
Pushpa Singh, Murari Kumar Singh, Rajnesh Singh, and Narendra Singh. Federated learning: Challenges, methods, and future directions. In Federated Learning for IoT Applications , pages 199–214. Springer, 2022
work page 2022
-
[35]
Stanford alpaca: An instruction-following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023
work page 2023
-
[36]
Inferdpt: Privacy-preserving infer- ence for black-box large language models
Meng Tong, Kejiang Chen, Jie Zhang, Yuang Qi, Weiming Zhang, Nenghai Yu, Tianwei Zhang, and Zhikun Zhang. Inferdpt: Privacy-preserving infer- ence for black-box large language models. IEEE Transactions on Dependable and Secure Comput- ing, 2025
work page 2025
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and ef- ficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations,
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations. arXiv preprint arXiv:2409.05976, 2024
-
[39]
Adversarial neuron pruning purifies backdoored deep models
Dongxian Wu and Yisen Wang. Adversarial neuron pruning purifies backdoored deep models. Ad- vances in Neural Information Processing Systems , 34:16913–16925, 2021
work page 2021
-
[40]
Fedbiot: Llm local fine-tuning in feder- ated learning without full model
Feijie Wu, Zitao Li, Yaliang Li, Bolin Ding, and Jing Gao. Fedbiot: Llm local fine-tuning in feder- ated learning without full model. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages 3345–3355, 2024
work page 2024
-
[41]
A survey on federated fine-tuning of large language models
Yebo Wu, Chunlin Tian, Jingguang Li, He Sun, Kahou Tam, Li Li, and Chengzhong Xu. A survey on federated fine-tuning of large language models. arXiv preprint arXiv:2503.12016 , 2025
-
[42]
Jie Xu, Karthikeyan Saravanan, Rogier van Dalen, Haaris Mehmood, David Tuckey, and Mete Ozay. Dp-dylora: Fine-tuning transformer-based models on-device under differentially private federated learning using dynamic low-rank adaptation. arXiv preprint arXiv:2405.06368, 2024
-
[43]
Openfedllm: Training large language models on decentralized private data via federated learning
Rui Ye, Wenhao Wang, Jingyi Chai, Dihan Li, Zexi Li, Yinda Xu, Yaxin Du, Yanfeng Wang, and Siheng Chen. Openfedllm: Training large language models on decentralized private data via federated learning. In Proceedings of the 30th ACM SIGKDD 16 Conference on Knowledge Discovery and Data Mining, pages 6137–6147, 2024
work page 2024
-
[44]
Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A Inan, Gautam Kamath, Ja- nardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, et al. Differentially private fine-tuning of language models. arXiv preprint arXiv:2110.06500, 2021
-
[45]
Hao Yu, Sen Yang, and Shenghuo Zhu. Paral- lel restarted sgd with faster convergence and less communication: Demystifying why model aver- aging works for deep learning. In Proceedings of the AAAI conference on artificial intelligence , volume 33, pages 5693–5700, 2019
work page 2019
-
[46]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Sheng Yun, Zakirul Alam Bhuiyan, Md Tau- fiq Al Hasib Sadi, and Shen Su. Privacy- preserving federated learning through clustered sampling on fine-tuning distributed non-iid large language models. In 2023 IEEE Intl Conf on Paral- lel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Comput- ing & Communications, Social Co...
work page 2023
-
[48]
Lihong Zhang and Yue Li. Federated learning with layer skipping: Efficient training of large lan- guage models for healthcare nlp. arXiv preprint arXiv:2504.10536, 2025
-
[49]
Federated intelli- gence for intelligent vehicles
Weishan Zhang, Baoyu Zhang, Xiaofeng Jia, Hong- wei Qi, Rui Qin, Juanjuan Li, Yonglin Tian, Xiao- long Liang, and Fei-Yue Wang. Federated intelli- gence for intelligent vehicles. IEEE Transactions on Intelligent Vehicles, 2024
work page 2024
-
[50]
Privacyasst: Safeguarding user privacy in tool- using large language model agents
Xinyu Zhang, Huiyu Xu, Zhongjie Ba, Zhibo Wang, Yuan Hong, Jian Liu, Zhan Qin, and Kui Ren. Privacyasst: Safeguarding user privacy in tool- using large language model agents. IEEE Transac- tions on Dependable and Secure Computing , 2024
work page 2024
-
[51]
Ligeng Zhu, Zhijian Liu, and Song Han. Deep leak- age from gradients. Advances in neural information processing systems, 32, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.