A Two-Phase Deep Learning Framework for Adaptive Time-Stepping in High-Speed Flow Modeling
Pith reviewed 2026-05-19 10:13 UTC · model grok-4.3
The pith
ShockCast uses two machine learning phases to predict and apply adaptive timesteps for high-speed flow simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ShockCast models high-speed flows by first training a machine learning component to predict an appropriate timestep size and then using that size together with the current fluid fields as inputs to a second component that advances the state forward by the predicted interval, thereby achieving adaptive time-stepping directly inside the learned simulator.
What carries the argument
The two-phase ShockCast framework, in which a timestep predictor supplies both the step length and a conditioning signal to a state-advancement model.
If this is right
- Simulations of supersonic flows can use learned adaptive steps instead of fixed small increments, lowering the total number of time steps needed.
- The same two-phase structure could be applied to other physical systems that require variable temporal resolution.
- Timestep conditioning inspired by neural ODEs and mixture-of-experts can be combined with physically motivated loss terms to improve prediction quality.
- Public datasets of supersonic flows become available for further benchmarking of learned simulators.
Where Pith is reading between the lines
- The approach may reduce the engineering effort needed to tune timestep controls when deploying learned fluid models in new regimes.
- If the predictor generalizes across different Mach numbers, it could support multi-regime simulations without retraining separate models for each speed range.
- Extending the second phase to also output uncertainty estimates on the advanced state could provide built-in reliability checks.
Load-bearing premise
The machine learning predictor can choose timestep sizes that keep the subsequent state advancement both numerically stable and physically accurate when abrupt changes such as shock waves appear, without any separate error monitoring or correction steps.
What would settle it
Running the trained ShockCast model on a supersonic test case containing a strong shock and finding that the simulation becomes unstable or produces large deviations from a high-resolution reference solution generated with conventional adaptive time-stepping.
Figures










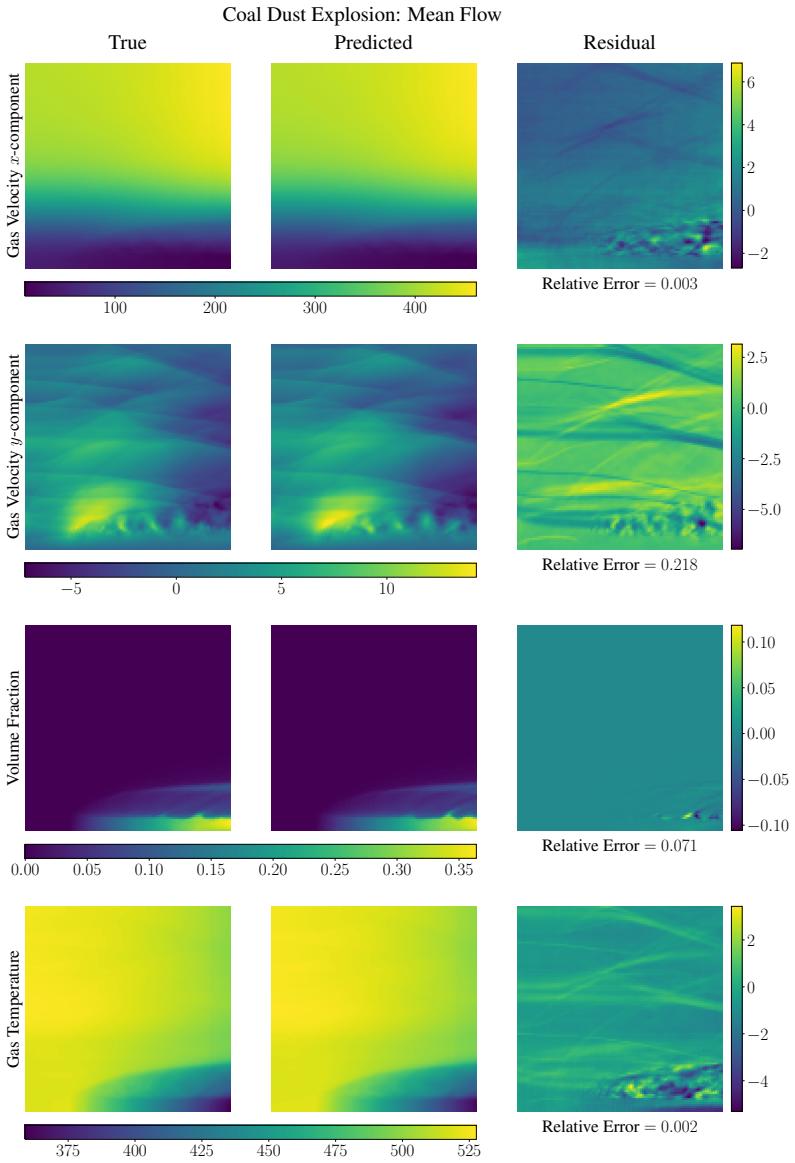









read the original abstract
We consider the problem of modeling high-speed flows using machine learning methods. While most prior studies focus on low-speed fluid flows in which uniform time-stepping is practical, flows approaching and exceeding the speed of sound exhibit sudden changes such as shock waves. In such cases, it is essential to use adaptive time-stepping methods to allow a temporal resolution sufficient to resolve these phenomena while simultaneously balancing computational costs. Here, we propose a two-phase machine learning method, known as ShockCast, to model high-speed flows with adaptive time-stepping. In the first phase, we propose to employ a machine learning model to predict the timestep size. In the second phase, the predicted timestep is used as an input along with the current fluid fields to advance the system state by the predicted timestep. We explore several physically-motivated components for timestep prediction and introduce timestep conditioning strategies inspired by neural ODE and Mixture of Experts. We evaluate our methods by generating three supersonic flow datasets, available at https://huggingface.co/divelab. Our code is publicly available as part of the AIRS library (https://github.com/divelab/AIRS).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ShockCast, a two-phase deep learning framework for modeling high-speed flows with adaptive time-stepping. Phase one trains an ML model to predict timestep sizes from current fluid fields; phase two conditions a state-advancement model on the predicted dt to evolve the solution. The authors incorporate physically motivated features for timestep prediction and conditioning strategies drawn from neural ODEs and Mixture-of-Experts architectures. Evaluation is performed on three newly generated supersonic flow datasets, with code released in the AIRS library and data hosted on Hugging Face.
Significance. If the learned timestep predictor can be shown to produce stable, accurate trajectories across shock discontinuities without classical error control, the framework would constitute a practical data-driven replacement for embedded Runge-Kutta or CFL-based adaptivity in high-speed CFD. Public release of datasets and code is a clear positive that supports reproducibility and follow-on work.
major comments (3)
- [§3] §3 (Method), timestep-prediction loss: the training objective for the first-phase model is not stated; without an explicit penalty on CFL or TVD violations when the predicted dt is fed to the second-phase integrator, it is impossible to verify that the two-phase separation prevents instability at shocks.
- [§4] §4 (Experiments): no quantitative comparison is reported against classical adaptive integrators (e.g., embedded RK4(5) or CFL-limited explicit schemes) on the three supersonic datasets; metrics such as maximum stable dt, L2 error at fixed wall-clock time, or failure rate under out-of-distribution shock strengths are absent.
- [§3.3] §3.3 (Conditioning): the neural-ODE and MoE conditioning mechanisms are described at a high level; it remains unclear whether the second-phase advancement is a learned operator or a traditional solver simply parameterized by the predicted dt, which directly affects whether stability guarantees can be inherited.
minor comments (3)
- [Abstract] Abstract: the sentence describing the second phase should clarify whether the advancement step is performed by a neural network or by a conventional time integrator conditioned on the predicted dt.
- [Figures] Figure captions: several figures lack axis labels or units for the predicted timestep; this obscures whether the learned dt respects physical scales.
- [§4.1] Dataset description: the three supersonic cases are introduced without stating the Mach-number range or shock-strength variation used for training versus testing; this information is needed to assess generalization claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment below and indicate the revisions planned for the next version of the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method), timestep-prediction loss: the training objective for the first-phase model is not stated; without an explicit penalty on CFL or TVD violations when the predicted dt is fed to the second-phase integrator, it is impossible to verify that the two-phase separation prevents instability at shocks.
Authors: We agree that the training objective for the Phase-1 timestep predictor requires explicit statement. The objective is the mean-squared error against reference timesteps obtained during dataset generation. We further acknowledge that no explicit stability penalty was included. In the revised manuscript we will state the loss function clearly in Section 3 and add a penalty term that discourages timestep predictions leading to CFL or TVD violations when the predicted dt is supplied to the Phase-2 integrator. revision: yes
-
Referee: [§4] §4 (Experiments): no quantitative comparison is reported against classical adaptive integrators (e.g., embedded RK4(5) or CFL-limited explicit schemes) on the three supersonic datasets; metrics such as maximum stable dt, L2 error at fixed wall-clock time, or failure rate under out-of-distribution shock strengths are absent.
Authors: We accept that direct quantitative comparisons with classical adaptive integrators would strengthen the evaluation. In the revised manuscript we will add a dedicated subsection reporting comparisons against embedded Runge-Kutta and CFL-limited schemes on all three datasets, including maximum stable dt, L2 error at fixed wall-clock time, and failure rates under out-of-distribution shock strengths. revision: yes
-
Referee: [§3.3] §3.3 (Conditioning): the neural-ODE and MoE conditioning mechanisms are described at a high level; it remains unclear whether the second-phase advancement is a learned operator or a traditional solver simply parameterized by the predicted dt, which directly affects whether stability guarantees can be inherited.
Authors: We thank the referee for noting the lack of clarity. The second-phase model is a learned neural operator (not a traditional solver) that receives the current state and the predicted dt as inputs. Conditioning is realized via neural-ODE-style continuous-time embeddings and MoE routing to handle different flow regimes. In the revision we will expand Section 3.3 with architectural diagrams and layer-level details of the conditioning, and we will discuss the implications for stability inheritance. revision: yes
Circularity Check
No significant circularity detected in two-phase adaptive timestep framework
full rationale
The paper proposes a two-phase ML method (ShockCast) in which a learned model predicts timestep size from fluid fields and the predicted dt is then supplied as conditioning input to a second model that advances the state. No equations, loss functions, or fitting procedures are shown that define the timestep prediction in terms of the advancement output or vice versa. The separation between phases is presented as an architectural choice with physically motivated components and neural-ODE/MoE conditioning; evaluation occurs on independently generated supersonic datasets rather than on quantities derived from the model's own fitted parameters. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to close the derivation. The framework is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Numerical time integration of fluid equations requires timestep sizes chosen to maintain stability and accuracy near discontinuities such as shocks.
Forward citations
Cited by 1 Pith paper
-
Orbital Transformers for Predicting Wavefunctions in Time-Dependent Density Functional Theory
OrbEvo uses equivariant graph transformers to learn the time evolution of TDDFT wavefunction coefficients, accurately reproducing wavefunctions, dipole moments, and absorption spectra on QM9 and MD17 molecular datasets.
Reference graph
Works this paper leans on
-
[1]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[2]
Artificial intelligence for science in quantum, atomistic, and continuum systems
Xuan Zhang, Limei Wang, Jacob Helwig, Youzhi Luo, Cong Fu, Yaochen Xie, ..., and Shuiwang Ji. Artificial intelligence for science in quantum, atomistic, and continuum systems. arXiv preprint arXiv:2307.08423, 2023
- [3]
- [4]
-
[5]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in neural information processing systems, 31, 2018
work page 2018
-
[6]
Outrageously large neural networks: The sparsely-gated mixture-of- experts layer
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. In International Conference on Learning Representations, 2017
work page 2017
-
[7]
Finite element and finite volume methods for heat transfer and fluid dynamics
Junuthula Narasimha Reddy, NK Anand, and Pratanu Roy. Finite element and finite volume methods for heat transfer and fluid dynamics. Cambridge University Press, 2022
work page 2022
-
[8]
Numerical analysis of spectral methods: theory and applications
David Gottlieb and Steven A Orszag. Numerical analysis of spectral methods: theory and applications. SIAM, 1977
work page 1977
-
[9]
Spectral methods for hyperbolic problems
David Gottlieb and Jan S Hesthaven. Spectral methods for hyperbolic problems. Journal of Computational and Applied Mathematics, 128(1-2):83–131, 2001
work page 2001
-
[10]
Spectral methods: evolution to complex geometries and applications to fluid dynamics
Claudio Canuto, M Yousuff Hussaini, Alfio Quarteroni, and Thomas A Zang. Spectral methods: evolution to complex geometries and applications to fluid dynamics . Springer Science & Business Media, 2007
work page 2007
-
[11]
Springer Science & Business Media, 2009
David A Kopriva.Implementing spectral methods for partial differential equations: Algorithms for scientists and engineers. Springer Science & Business Media, 2009
work page 2009
-
[12]
On the partial difference equations of mathematical physics
Richard Courant, Kurt Friedrichs, and Hans Lewy. On the partial difference equations of mathematical physics. IBM journal of Research and Development, 11(2):215–234, 1967
work page 1967
-
[13]
Numerical approximation of partial differential equations, volume 64
Sören Bartels. Numerical approximation of partial differential equations, volume 64. Springer, 2016
work page 2016
-
[14]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019
work page 2019
-
[15]
Three-dimensional laminar flow using physics informed deep neural networks
Saykat Kumar Biswas and NK Anand. Three-dimensional laminar flow using physics informed deep neural networks. Physics of Fluids, 35(12), 2023
work page 2023
-
[16]
Interfacial conditioning in physics informed neural networks
Saykat Kumar Biswas and NK Anand. Interfacial conditioning in physics informed neural networks. Physics of Fluids, 36(7), 2024. 10
work page 2024
-
[17]
Hypernetwork-based meta- learning for low-rank physics-informed neural networks
Woojin Cho, Kookjin Lee, Donsub Rim, and Noseong Park. Hypernetwork-based meta- learning for low-rank physics-informed neural networks. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[18]
Physics-informed neural networks for periodic flows
Smruti Shah and NK Anand. Physics-informed neural networks for periodic flows. Physics of Fluids, 36(7), 2024
work page 2024
-
[19]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
work page 2021
-
[20]
Multiwavelet-based operator learning for differential equations
Gaurav Gupta, Xiongye Xiao, and Paul Bogdan. Multiwavelet-based operator learning for differential equations. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021
work page 2021
-
[21]
Learning dissipative dynamics in chaotic systems
Zongyi Li, Miguel Liu-Schiaffini, Nikola Borislavov Kovachki, Burigede Liu, Kamyar Az- izzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Learning dissipative dynamics in chaotic systems. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[22]
Fourier neu- ral operator with learned deformations for pdes on general geometries
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neu- ral operator with learned deformations for pdes on general geometries. arXiv preprint arXiv:2207.05209, 2022
-
[23]
Geometry-informed neural operator for large-scale 3d pdes
Zongyi Li, Nikola Borislavov Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Prakash Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzade- nesheli, et al. Geometry-informed neural operator for large-scale 3d pdes. arXiv preprint arXiv:2309.00583, 2023
-
[24]
Transform once: Efficient operator learning in frequency domain
Michael Poli, Stefano Massaroli, Federico Berto, Jinkyoo Park, Tri Dao, Christopher Re, and Stefano Ermon. Transform once: Efficient operator learning in frequency domain. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022
work page 2022
-
[25]
Nomad: Nonlinear manifold decoders for operator learning
Jacob Seidman, Georgios Kissas, Paris Perdikaris, and George J Pappas. Nomad: Nonlinear manifold decoders for operator learning. Advances in Neural Information Processing Systems, 35:5601–5613, 2022
work page 2022
-
[26]
Neural operator: Learning maps between function spaces with applications to PDEs
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs. Journal of Machine Learning Research, 24(89):1–97, 2023
work page 2023
-
[27]
Openfwi: Large-scale multi-structural benchmark datasets for full waveform inversion
Chengyuan Deng, Shihang Feng, Hanchen Wang, Xitong Zhang, Peng Jin, Yinan Feng, Qili Zeng, Yinpeng Chen, and Youzuo Lin. Openfwi: Large-scale multi-structural benchmark datasets for full waveform inversion. Advances in Neural Information Processing Systems, 35:6007–6020, 2022
work page 2022
-
[28]
Learning large-scale subsurface simulations with a hybrid graph network simulator
Tailin Wu, Qinchen Wang, Yinan Zhang, Rex Ying, Kaidi Cao, Rok Sosic, Ridwan Jalali, Has- san Hamam, Marko Maucec, and Jure Leskovec. Learning large-scale subsurface simulations with a hybrid graph network simulator. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4184–4194, 2022
work page 2022
-
[29]
Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast. arXiv preprint arXiv:2211.02556, 2022
-
[30]
Graphcast: Learning skillful medium-range global weather forecasting
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire For- tunato, Alexander Pritzel, Suman Ravuri, Timo Ewalds, Ferran Alet, Zach Eaton-Rosen, et al. Graphcast: Learning skillful medium-range global weather forecasting. arXiv preprint arXiv:2212.12794, 2022. 11
-
[31]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopad- hyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators. arXiv preprint arXiv:2202.11214, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Gencast: Diffusion- based ensemble forecasting for medium-range weather
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Timo Ewalds, Andrew El-Kadi, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, and Matthew Willson. Gencast: Diffusion- based ensemble forecasting for medium-range weather. arXiv preprint arXiv:2312.15796, 2023
-
[33]
Climax: A foundation model for weather and climate
Tung Nguyen, Johannes Brandstetter, Ashish Kapoor, Jayesh K Gupta, and Aditya Grover. Climax: A foundation model for weather and climate. In Proceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[34]
Florent Bonnet, Jocelyn Ahmed Mazari, Paola Cinella, and Patrick Gallinari. Airfrans: High fidelity computational fluid dynamics dataset for approximating reynolds-averaged navier- stokes solutions. In 36th Conference on Neural Information Processing Systems (NeurIPS
-
[35]
Track on Datasets and Benchmarks, 2022
work page 2022
-
[36]
A geometry-aware message passing neural network for modeling aerodynamics over airfoils
Jacob Helwig, Xuan Zhang, Haiyang Yu, and Shuiwang Ji. A geometry-aware message passing neural network for modeling aerodynamics over airfoils. arXiv preprint arXiv:2412.09399, 2024
-
[37]
Factorized fourier neural operators
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. Factorized fourier neural operators. In The Eleventh International Conference on Learning Representations , 2023
work page 2023
-
[38]
U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow
Gege Wen, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M Benson. U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow. Advances in Water Resources, 163:104180, 2022
work page 2022
-
[39]
Group equivariant Fourier neural operators for partial differential equations
Jacob Helwig, Xuan Zhang, Cong Fu, Jerry Kurtin, Stephan Wojtowytsch, and Shuiwang Ji. Group equivariant Fourier neural operators for partial differential equations. In Proceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[40]
Real-time high-resolution co 2 geological storage prediction using nested fourier neural operators
Gege Wen, Zongyi Li, Qirui Long, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M Benson. Real-time high-resolution co 2 geological storage prediction using nested fourier neural operators. Energy & Environmental Science, 16(4):1732–1741, 2023
work page 2023
-
[41]
Spherical fourier neural operators: Learning stable dynamics on the sphere
Boris Bonev, Thorsten Kurth, Christian Hundt, Jaideep Pathak, Maximilian Baust, Karthik Kashinath, and Anima Anandkumar. Spherical fourier neural operators: Learning stable dynamics on the sphere. In Proceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[42]
Sinenet: Learning temporal dynamics in time-dependent partial differential equations
Xuan Zhang, Jacob Helwig, Yuchao Lin, Yaochen Xie, Cong Fu, Stephan Wojtowytsch, and Shuiwang Ji. Sinenet: Learning temporal dynamics in time-dependent partial differential equations. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[43]
Convolutional neural operators for robust and accurate learning of pdes
Bogdan Raonic, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bézenac. Convolutional neural operators for robust and accurate learning of pdes. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[44]
Choose a transformer: Fourier or galerkin
Shuhao Cao. Choose a transformer: Fourier or galerkin. Advances in neural information processing systems, 34:24924–24940, 2021
work page 2021
-
[45]
Transformer for partial differential equations’ operator learning
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning. Transactions on Machine Learning Research, 2023
work page 2023
-
[46]
EAGLE: Large-scale learning of turbulent fluid dynamics with mesh transformers
Steeven Janny, Aurélien Bénéteau, Madiha Nadri, Julie Digne, Nicolas Thome, and Christian Wolf. EAGLE: Large-scale learning of turbulent fluid dynamics with mesh transformers. In International Conference on Learning Representations, 2023. 12
work page 2023
-
[47]
DPOT: Auto-regressive denoising operator transformer for large-scale PDE pre-training
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. DPOT: Auto-regressive denoising operator transformer for large-scale PDE pre-training. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[48]
Universal physics transformers: A framework for efficiently scaling neural operators
Benedikt Alkin, Andreas Fürst, Simon Lucas Schmid, Lukas Gruber, Markus Holzleitner, and Johannes Brandstetter. Universal physics transformers: A framework for efficiently scaling neural operators. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[49]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations. arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[50]
Multipole graph neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew Stuart, Kaushik Bhattacharya, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations. Advances in Neural Information Processing Systems, 33:6755–6766, 2020
work page 2020
-
[51]
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural PDE solvers. In International Conference on Learning Representations, 2022
work page 2022
-
[52]
Physics-embedded neural networks: Graph neural pde solvers with mixed boundary conditions
Masanobu Horie and Naoto Mitsume. Physics-embedded neural networks: Graph neural pde solvers with mixed boundary conditions. Advances in Neural Information Processing Systems, 35:23218–23229, 2022
work page 2022
-
[53]
Learned coarse models for efficient turbulence simulation
Kimberly Stachenfeld, Drummond B Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, and Alvaro Sanchez-Gonzalez. Learned coarse models for efficient turbulence simulation. In International Conference on Learning Representations, 2021
work page 2021
-
[54]
Machine learning–accelerated computational fluid dynamics
Dmitrii Kochkov, Jamie A Smith, Ayya Alieva, Qing Wang, Michael P Brenner, and Stephan Hoyer. Machine learning–accelerated computational fluid dynamics. Proceedings of the National Academy of Sciences, 118(21):e2101784118, 2021
work page 2021
-
[55]
Towards multi-spatiotemporal-scale generalized PDE modeling
Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized PDE modeling. Transactions on Machine Learning Research, 2023
work page 2023
-
[56]
Maximilian Herde, Bogdan Raoni´c, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel de Bézenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. arXiv preprint arXiv:2405.19101, 2024
-
[57]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021
work page 2021
-
[58]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[59]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[60]
Yiping Lu, Aoxiao Zhong, Quanzheng Li, and Bin Dong. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In International conference on machine learning, pages 3276–3285. PMLR, 2018
work page 2018
-
[61]
Stable architectures for deep neural networks
Eldad Haber and Lars Ruthotto. Stable architectures for deep neural networks. Inverse problems, 34(1):014004, 2017
work page 2017
-
[62]
Deep neural networks motivated by partial differential equations
Lars Ruthotto and Eldad Haber. Deep neural networks motivated by partial differential equations. Journal of Mathematical Imaging and Vision, 62(3):352–364, 2020
work page 2020
-
[63]
On neural differential equations
Patrick Kidger. On neural differential equations. arXiv preprint arXiv:2202.02435, 2022. 13
-
[64]
Adaptive mixtures of local experts
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991
work page 1991
-
[65]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[66]
Gnot: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. Gnot: A general neural operator transformer for operator learning. In International Conference on Machine Learning, pages 12556–12569. PMLR, 2023
work page 2023
-
[67]
Learning mesh-based simulation with graph networks
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter Battaglia. Learning mesh-based simulation with graph networks. In International Conference on Learning Repre- sentations, 2021
work page 2021
-
[68]
M2n: Mesh movement networks for pde solvers
Wenbin Song, Mingrui Zhang, Joseph G Wallwork, Junpeng Gao, Zheng Tian, Fanglei Sun, Matthew Piggott, Junqing Chen, Zuoqiang Shi, Xiang Chen, et al. M2n: Mesh movement networks for pde solvers. Advances in Neural Information Processing Systems, 35:7199–7210, 2022
work page 2022
-
[69]
Towards universal mesh movement networks
Mingrui Zhang, Chunyang Wang, Stephan C Kramer, Joseph G Wallwork, Siyi Li, Jiancheng Liu, Xiang Chen, and Matthew Piggott. Towards universal mesh movement networks. Ad- vances in Neural Information Processing Systems, 37:14934–14961, 2024
work page 2024
-
[70]
Learn- ing controllable adaptive simulation for multi-scale physics
Tailin Wu, Takashi Maruyama, Qingqing Zhao, Gordon Wetzstein, and Jure Leskovec. Learn- ing controllable adaptive simulation for multi-scale physics. In NeurIPS 2022 AI for Science: Progress and Promises, 2022
work page 2022
-
[71]
Swarm reinforcement learning for adaptive mesh refinement
Niklas Freymuth, Philipp Dahlinger, Tobias Daniel Würth, Simon Reisch, Luise Kärger, and Gerhard Neumann. Swarm reinforcement learning for adaptive mesh refinement. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[72]
Reinforcement learning for adaptive mesh refinement
Jiachen Yang, Tarik Dzanic, Brenden Petersen, Jun Kudo, Ketan Mittal, Vladimir Tomov, Jean- Sylvain Camier, Tuo Zhao, Hongyuan Zha, Tzanio Kolev, et al. Reinforcement learning for adaptive mesh refinement. In International conference on artificial intelligence and statistics, pages 5997–6014. PMLR, 2023
work page 2023
-
[73]
Tante: Time-adaptive operator learning via neural taylor expansion
Zhikai Wu, Shiyang Zhang, Sizhuang He, Sifan Wang, Min Zhu, Anran Jiao, Lu Lu, and David van Dijk. Tante: Time-adaptive operator learning via neural taylor expansion. arXiv preprint arXiv:2502.08574, 2025
-
[74]
Space and time continuous physics simulation from partial observations
Steeven Janny, Madiha Nadri, Julie Digne, and Christian Wolf. Space and time continuous physics simulation from partial observations. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[75]
Jan Hagnberger, Marimuthu Kalimuthu, Daniel Musekamp, and Mathias Niepert. Vector- ized conditional neural fields: A framework for solving time-dependent parametric partial differential equations. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[76]
Hierarchical deep learning of multi- scale differential equation time-steppers
Yuying Liu, J Nathan Kutz, and Steven L Brunton. Hierarchical deep learning of multi- scale differential equation time-steppers. Philosophical Transactions of the Royal Society A, 380(2229):20210200, 2022
work page 2022
-
[77]
Hierarchical deep learning-based adaptive time stepping scheme for multiscale simulations
Asif Hamid, Danish Rafiq, Shahkar Ahmad Nahvi, and Mohammad Abid Bazaz. Hierarchical deep learning-based adaptive time stepping scheme for multiscale simulations. Engineering Applications of Artificial Intelligence, 133:108430, 2024
work page 2024
-
[78]
A survey of several finite difference methods for systems of nonlinear hyperbolic conservation laws
Gary A Sod. A survey of several finite difference methods for systems of nonlinear hyperbolic conservation laws. Journal of computational physics, 27(1):1–31, 1978
work page 1978
-
[79]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022. 14
work page 2022
-
[80]
Learning to simulate complex physics with graph networks
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter Battaglia. Learning to simulate complex physics with graph networks. In International conference on machine learning, pages 8459–8468. PMLR, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.