Strategically Deceptive Model Deployment in Performative Prediction
Pith reviewed 2026-05-19 10:04 UTC · model grok-4.3
The pith
Decoupled Performative Prediction allows institutions to achieve lower risk by disclosing a different model to users than the one used for decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decoupling the model that governs institutional decisions from the model disclosed to users, the optimization admits distinct solutions that achieve lower institutional risk than those available when the models must coincide as in standard performative prediction.
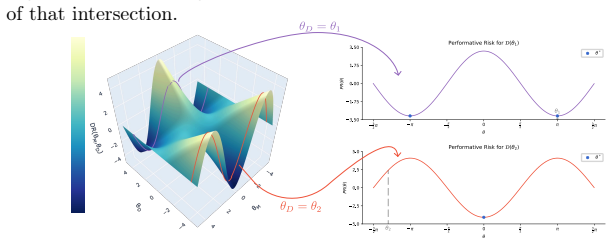
What carries the argument
The Decoupled Performative Prediction framework that separates the decision model from the disclosure model and analyzes the resulting optimization landscape for improved institutional outcomes.
If this is right
- Distinct equilibria exist with lower risk for the institution.
- An algorithm converges to these solutions with provable guarantees under standard assumptions.
- Incorporating a deception cost into optimization still permits deceptive deployment.
- Model disclosure becomes a core technical decision rather than just an ethical one.
- Regulations may be needed to hold institutions accountable for mismatches.
Where Pith is reading between the lines
- Users might benefit from mechanisms to detect model mismatches in real deployments.
- This framework could extend to other feedback loop settings in machine learning where information asymmetry exists.
- Institutions might strategically choose disclosure levels based on expected user response and detection probability.
- Testing in simulated environments could reveal the practical gains from such decoupling.
Load-bearing premise
The institution unilaterally controls model disclosure and users respond solely to the disclosed model without effective ways to detect or correct for any mismatch.
What would settle it
An empirical study measuring whether institutions in practice deploy mismatched models and observe reduced risk compared to matched-model baselines in performative settings.
Figures











read the original abstract
Machine Learning systems are increasingly deployed in decision-making settings that shape user behavior and, in turn, the data on which future decisions are based. Performative Prediction (PP) formalizes this feedback loop by modeling how deployed models induce distributional shifts. It studies how to learn robust and well-performing models under such dynamics. However, existing PP frameworks typically assume that the model governing these decisions is the same model observed by users (therefore, to which they respond). In practice, deployer institutions may instead disclose curated models, while internally relying on distinct opaque models. We introduce Decoupled Performative Prediction (DPP), a framework that explicitly models mismatches between the model governing institutional decisions and the model that shapes user behavior. By analyzing the resulting optimization landscape, we show that DPP admits new different solutions that provably achieve lower risk for the institution than those under classical PP. We further propose an algorithm with provable convergence guarantees under standard assumptions, demonstrating how easy institutions can benefit from strategically deceptive deployment when they control model disclosure and users lack countervailing power. To capture the implications of such behavior, we introduce the deception cost, a quantitative measure of the degree of deception experienced by users. We study settings in which institutions incorporate this cost into the optimization process, motivated by reputational concerns or potential user abandonment, and show that such self-imposed constraints are insufficient to protect users. Overall, our results demonstrate that model disclosure is not merely an ethical consideration but a core technical design decision, underscoring the need for regulations that hold institutions accountable for deceptive deployment practices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Decoupled Performative Prediction (DPP), extending classical Performative Prediction (PP) by allowing an institution to optimize an internal decision model θ while disclosing a distinct model φ to users. It claims that this decoupling yields equilibria with strictly lower institutional risk than standard PP, proposes an algorithm with convergence guarantees under standard assumptions, defines a deception cost to quantify user impact, and shows that incorporating this cost as a self-imposed constraint fails to protect users, calling for external regulations on disclosure practices.
Significance. If the separation between the performative map for φ and the risk objective for θ is rigorously established without implicit coupling, the work identifies a technically exploitable asymmetry in performative settings that could systematically favor deceptive deployment. The introduction of deception cost as a quantitative regularizer and the convergence analysis provide concrete tools for studying such asymmetries, with direct relevance to both algorithmic design and regulatory discussions in deployed ML systems.
major comments (2)
- [Abstract and framework definition] Abstract and framework definition: The central claim that DPP admits solutions achieving strictly lower institutional risk requires that the performative distribution (and thus the risk for θ) depends only on the disclosed model φ. The optimization landscape analysis must explicitly derive the decoupled risk function and demonstrate that it is not equivalent to the classical PP objective; without this separation shown formally (including any assumption that users respond exclusively to φ), the lower-risk result does not follow.
- [Deployment discussion and final claims] Deployment discussion and final claims: The assumption that institutions unilaterally control disclosure while users possess no effective detection or countervailing power is treated as given. This modeling choice is load-bearing for the advantage over PP; the manuscript should state it explicitly as an axiom and analyze robustness (e.g., partial information flow from θ back into the shift), as any such coupling collapses the claimed distinction.
minor comments (2)
- [Abstract] The abstract contains the awkward phrasing 'new different solutions'; rephrase to 'distinct solutions' for clarity.
- Notation for the disclosed model φ and internal model θ should be introduced with a clear table or diagram early in the paper to distinguish them from standard PP notation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, providing clarifications on the framework and assumptions while committing to revisions that strengthen the formal presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and framework definition] Abstract and framework definition: The central claim that DPP admits solutions achieving strictly lower institutional risk requires that the performative distribution (and thus the risk for θ) depends only on the disclosed model φ. The optimization landscape analysis must explicitly derive the decoupled risk function and demonstrate that it is not equivalent to the classical PP objective; without this separation shown formally (including any assumption that users respond exclusively to φ), the lower-risk result does not follow.
Authors: We agree that an explicit formal separation strengthens the presentation. The manuscript defines the performative map such that the induced distribution P_φ depends solely on the disclosed model φ, while the institutional objective is the risk of the internal decision model θ evaluated under P_φ. This yields the decoupled risk R(θ, φ) = E_{x ∼ P_φ}[ℓ(θ, x)], which is distinct from the classical PP objective where the single model must serve both roles simultaneously. We will revise Section 2 to include a dedicated derivation of R(θ, φ) and a short proposition establishing that inf_θ,φ R(θ, φ) ≤ inf_θ R(θ, θ), with strict inequality possible when the optimal φ for a given θ differs from θ itself. The assumption that users respond exclusively to φ is already implicit in the problem setup but will be stated explicitly as part of the framework definition. revision: yes
-
Referee: [Deployment discussion and final claims] Deployment discussion and final claims: The assumption that institutions unilaterally control disclosure while users possess no effective detection or countervailing power is treated as given. This modeling choice is load-bearing for the advantage over PP; the manuscript should state it explicitly as an axiom and analyze robustness (e.g., partial information flow from θ back into the shift), as any such coupling collapses the claimed distinction.
Authors: We accept that this modeling choice requires explicit statement. We will add it as Assumption 1 in the revised manuscript: users observe and respond only to the disclosed model φ, with no direct information about or feedback from the internal model θ. For robustness, we will include a brief discussion in Section 5 noting that partial leakage of information about θ would effectively create a composite signal to which users respond; in such cases the advantage of decoupling shrinks but does not necessarily vanish unless the leakage is complete. Full equilibrium analysis under endogenous detection lies outside the current scope, but the added discussion will clarify the boundary conditions under which the DPP advantage persists. revision: partial
Circularity Check
No significant circularity; DPP lower-risk claim follows from explicit decoupling assumption
full rationale
The paper defines Decoupled Performative Prediction by separating the disclosed model φ (inducing the performative shift) from the internal decision model θ (used for institutional decisions). The optimization landscape analysis and lower-risk solutions are derived directly from this separation under the stated assumption that users respond only to φ. This is a modeling choice with independent content, not a reduction by construction to prior fitted parameters, self-citations, or ansatzes. No load-bearing self-citation chains or renaming of known results appear in the derivation. The framework remains self-contained against external performative prediction benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions for convergence in optimization algorithms
Reference graph
Works this paper leans on
-
[1]
Juan Perdomo, Tijana Zrnic, Celestine Mendler-Dünner, and Moritz Hardt. Performative prediction. InInternational Conference on Machine Learning, pages 7599–7609. PMLR, 2020
work page 2020
-
[2]
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
work page 2018
-
[3]
Qualitatively charac- terizing neural network optimization problems
Ian J Goodfellow, Oriol Vinyals, and Andrew M Saxe. Qualitatively charac- terizing neural network optimization problems. InICLR, 2015
work page 2015
-
[4]
An empirical analysis of the optimization of deep network loss surfaces
Daniel Jiwoong Im, Michael Tao, and Kristin Branson. An empirical analysis of the optimization of deep network loss surfaces, 2017. URL https://arxiv.org/abs/1612.04010
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Performative prediction with neural networks
Mehrnaz Mofakhami, Ioannis Mitliagkas, and Gauthier Gidel. Performative prediction with neural networks. InInternational Conference on Artificial Intelligence and Statistics, pages 11079–11093. PMLR, 2023
work page 2023
-
[6]
Performative prediction in a stateful world
Gavin Brown, Shlomi Hod, and Iden Kalemaj. Performative prediction in a stateful world. InInternational conference on artificial intelligence and statistics, pages 6045–6061. PMLR, 2022. 14
work page 2022
-
[7]
Regret minimization with performative feedback
Meena Jagadeesan, Tijana Zrnic, and Celestine Mendler-Dünner. Regret minimization with performative feedback. InInternational Conference on Machine Learning, pages 9760–9785. PMLR, 2022
work page 2022
-
[8]
Perfor- mative reinforcement learning
Debmalya Mandal, Stelios Triantafyllou, and Goran Radanovic. Perfor- mative reinforcement learning. InInternational Conference on Machine Learning, pages 23642–23680. PMLR, 2023
work page 2023
-
[9]
Stochastic optimization schemes for performative prediction with nonconvex loss
Qiang Li and Hoi To Wai. Stochastic optimization schemes for performative prediction with nonconvex loss. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview. net/forum?id=ejIzdt50ek
work page 2024
-
[10]
The limitations of model retraining in the face of performativity
Anmol Kabra and Kumar Kshitij Patel. The limitations of model retraining in the face of performativity. InHumans, Algorithmic Decision-Making and Society: Modeling Interactions and Impact, ICML 2024 Workshop, 2024
work page 2024
-
[11]
How to learn when data reacts to your model: performative gradient descent
Zachary Izzo, Lexing Ying, and James Zou. How to learn when data reacts to your model: performative gradient descent. InInternational Conference on Machine Learning, pages 4641–4650. PMLR, 2021
work page 2021
-
[12]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning, 8:229–256, 1992
work page 1992
-
[13]
Outside the echo chamber: Optimizing the performative risk
John P Miller, Juan C Perdomo, and Tijana Zrnic. Outside the echo chamber: Optimizing the performative risk. InInternational Conference on Machine Learning, pages 7710–7720. PMLR, 2021
work page 2021
-
[14]
Opti- mal classification under performative distribution shift
Edwige Cyffers, Muni Sreenivas Pydi, Jamal Atif, and Olivier Cappé. Opti- mal classification under performative distribution shift. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=3J5hvO5UaW
work page 2024
-
[15]
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors,International Conference on Learning Representations, ICLR, 2014
work page 2014
-
[16]
Plug-in performative optimization
Licong Lin and Tijana Zrnic. Plug-in performative optimization. InForty- first International Conference on Machine Learning, 2024. URL https: //openreview.net/forum?id=jh7FDDwDBf
work page 2024
-
[17]
Distributionally robust performative pre- diction
Songkai Xue and Yuekai Sun. Distributionally robust performative pre- diction. In The Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. URL https://openreview.net/forum? id=E8wDxddIqU
work page 2024
-
[18]
Strategic classification in the dark
Ganesh Ghalme, Vineet Nair, Itay Eilat, Inbal Talgam-Cohen, and Nir Rosenfeld. Strategic classification in the dark. InInternational Conference on Machine Learning, pages 3672–3681. PMLR, 2021. 15
work page 2021
-
[19]
Give me some credit.https://kaggle
Credit Fusion and Will Cukierski. Give me some credit.https://kaggle. com/competitions/GiveMeSomeCredit, 2011. Kaggle
work page 2011
-
[20]
Moritz Hardt, Meena Jagadeesan, and Celestine Mendler-Dünner. Perfor- mative power. Advances in Neural Information Processing Systems, 35: 22969–22981, 2022
work page 2022
-
[21]
Moritz Hardt, Nimrod Megiddo, Christos Papadimitriou, and Mary Woot- ters. Strategic classification. InProceedings of the 2016 ACM conference on innovations in theoretical computer science, pages 111–122, 2016
work page 2016
-
[22]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization.arXiv preprint arXiv:2010.01412, 2020. 16 A From traditional Machine Learning to extended Performative Prediction As further illustration, we include Fig. 8. P er f ormativ e Pr ediction Ext ended P er f ormativ e Pr edi...
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.