mLaSDI: Multi-stage latent space dynamics identification
Pith reviewed 2026-05-19 09:51 UTC · model grok-4.3
The pith
mLaSDI trains residual decoders in stages to recover high-frequency details in reduced-order PDE models while keeping latent dynamics interpretable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With mLaSDI, the initial autoencoder is trained, after which additional decoders are trained sequentially to map latent trajectories to residuals from previous stages. Combined with periodic activation functions, this staged residual learning recovers high-frequency content without sacrificing interpretability of the latent dynamics. An error decomposition separates autoencoder and latent dynamics contributions, and it is proven that additional training stages cannot increase the training residual.
What carries the argument
Sequential training of residual decoders on the outputs of prior stages, using periodic activations to capture high frequencies.
If this is right
- Reconstruction and prediction errors drop significantly, often by an order of magnitude, on test problems like multiscale oscillations, wake flows, and Vlasov equations.
- Training time decreases and hyperparameter tuning becomes less demanding compared to single-stage LaSDI.
- The error decomposition allows independent assessment of autoencoder reconstruction quality versus latent dynamics accuracy.
- User-specified ODEs remain intact, preserving the interpretability and flexibility of the latent space model.
Where Pith is reading between the lines
- This method could be applied to other latent variable models in scientific machine learning to improve fidelity on oscillatory or turbulent systems without retraining the entire dynamics.
- If the residual stages can be added without bound on training error, practitioners might continue refining models until desired accuracy is reached, subject only to overfitting risks.
- The separation of concerns might enable hybrid models where latent dynamics are derived from first principles while residuals are learned from data.
Load-bearing premise
Sequential training of residual decoders will not degrade the previously learned user-specified ODE dynamics or introduce instabilities affecting generalization to unseen parameters.
What would settle it
Running the training on the unsteady wake flow example and finding that the training residual increases after the second stage would directly contradict the claim that additional stages cannot increase the training residual.
Figures













read the original abstract
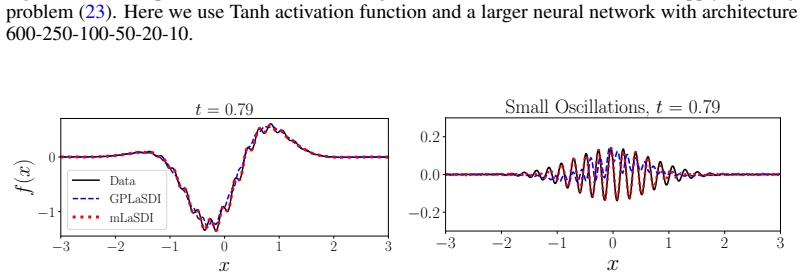
Accurately solving partial differential equations (PDEs) is essential across many scientific disciplines. However, high-fidelity solvers can be computationally prohibitive, motivating the development of reduced-order models (ROMs). Recently, Latent Space Dynamics Identification (LaSDI) was proposed as a data-driven, non-intrusive ROM framework. LaSDI compresses the training data via an autoencoder and learns user-specified ordinary differential equations (ODEs), governing the latent dynamics, enabling rapid predictions for unseen parameters. While LaSDI has produced effective ROMs for numerous problems, the autoencoder must simultaneously reconstruct the training data and satisfy the imposed latent dynamics, which are often competing objectives that limit accuracy, particularly for complex or high-frequency phenomena. To address this limitation, we propose multi-stage Latent Space Dynamics Identification (mLaSDI). With mLaSDI, we train LaSDI sequentially in stages. After training the initial autoencoder, we train additional decoders which map the latent trajectories to residuals from previous stages. This staged residual learning, combined with periodic activation functions, enables recovery of high-frequency content without sacrificing interpretability of the latent dynamics. We further provide an error decomposition separating autoencoder and latent dynamics contributions, and prove that additional training stages cannot increase the training residual. Numerical experiments on a multiscale oscillating system, unsteady wake flow, and the 1D-1V Vlasov equation demonstrate that mLaSDI achieves significantly lower reconstruction and prediction errors, often by an order of magnitude, while requiring less training time and reduced hyperparameter tuning compared to standard LaSDI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes mLaSDI as a multi-stage extension of Latent Space Dynamics Identification (LaSDI) for reduced-order modeling of PDEs. After an initial LaSDI stage that learns an autoencoder and user-specified latent ODE, additional decoders are trained sequentially on residuals using periodic activation functions to recover high-frequency content. The authors present an error decomposition separating autoencoder and latent-dynamics contributions and prove that further stages cannot increase the training residual. Experiments on a multiscale oscillating system, unsteady wake flow, and 1D-1V Vlasov equation report order-of-magnitude reductions in reconstruction and prediction errors relative to standard LaSDI, with reduced training time and hyperparameter tuning.
Significance. If the central claims hold, mLaSDI provides a practical route to higher-accuracy data-driven ROMs for multiscale and high-frequency problems while retaining the interpretability of user-specified latent dynamics. The staged residual learning and periodic activations directly address a known tension in LaSDI between reconstruction fidelity and imposed dynamics. The error decomposition and non-increase proof supply useful theoretical structure, and the reported gains on three distinct test problems suggest the method could be broadly applicable in scientific computing.
major comments (2)
- [Theoretical analysis] The non-increase proof for training residuals (abstract and theoretical section) is internal to the training objective and does not establish that the composite model preserves the original user-specified latent ODE under long-term integration or parameter extrapolation. This preservation is load-bearing for the interpretability claim across the multiscale, wake, and Vlasov cases.
- [§4] §4 (numerical experiments): the reported error reductions are presented for the composite model, but no ablation isolates whether the added residual decoders alter the previously learned latent trajectories or introduce instabilities when the full model is integrated forward for unseen parameters.
minor comments (2)
- [Method] Notation for the residual decoders and their periodic activations should be introduced with explicit equations rather than descriptive text only.
- [Figures] Figure captions for the Vlasov and wake examples should state the exact time horizons and parameter ranges used for the prediction-error metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity of our theoretical contributions and experimental validation. We address each major comment in turn below.
read point-by-point responses
-
Referee: The non-increase proof for training residuals (abstract and theoretical section) is internal to the training objective and does not establish that the composite model preserves the original user-specified latent ODE under long-term integration or parameter extrapolation. This preservation is load-bearing for the interpretability claim across the multiscale, wake, and Vlasov cases.
Authors: We agree that the non-increase result applies specifically to the training residual. However, the preservation of the user-specified latent ODE is ensured by the structure of mLaSDI: the latent dynamics are identified and fixed during the first stage, and subsequent stages train residual decoders that take the latent states (obtained by integrating the fixed ODE) as input. Thus, the latent trajectories are identical to those of standard LaSDI for any integration length or parameter value. The interpretability claim rests on this architectural choice rather than the residual non-increase proof. We have revised Section 3 to include an explicit statement clarifying that the latent ODE remains unchanged across stages. revision: yes
-
Referee: §4 (numerical experiments): the reported error reductions are presented for the composite model, but no ablation isolates whether the added residual decoders alter the previously learned latent trajectories or introduce instabilities when the full model is integrated forward for unseen parameters.
Authors: The referee is correct that an explicit ablation was not presented. By construction, the residual decoders do not alter the latent trajectories, as these are generated exclusively by the user-specified ODE from the first stage; the decoders only refine the reconstruction from those fixed latent states. To address this, we have added an ablation subsection in §4 that confirms the latent trajectories are unchanged and reports forward integration results for unseen parameters, showing stable behavior with no introduced instabilities in any of the three test problems. revision: yes
Circularity Check
New staged residual procedure and non-increase proof are self-contained; minor LaSDI citation is not load-bearing
full rationale
The derivation introduces an explicit sequential training procedure (initial LaSDI followed by residual decoders on fixed latent trajectories) together with a fresh error decomposition and a direct proof that additional stages cannot increase the training residual. These steps are constructed and proven internally without any equation reducing a claimed prediction to a fitted parameter or to a prior self-citation. The LaSDI reference is used only to define the baseline stage and does not carry the central claims about high-frequency recovery or interpretability preservation. The approach therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of training stages
- Periodic activation hyperparameters
axioms (2)
- domain assumption Latent dynamics can be adequately modeled by user-specified ODEs
- ad hoc to paper Residuals between stages can be learned independently by additional decoders without destabilizing prior latent dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This staged residual learning, combined with periodic activation functions, enables recovery of high-frequency content without sacrificing interpretability of the latent dynamics. We further provide an error decomposition separating autoencoder and latent dynamics contributions, and prove that additional training stages cannot increase the training residual.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Z. Aldirany, R. Cottereau, M. Laforest, and S. Prudhomme. Multi-level neural networks for accurate solutions of boundary-value problems. Computer Methods in Applied Mechanics and Engineering, 419:116666, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2023. 116666
-
[2]
R. Anderson et al. Mfem: A modular finite element methods library. Computers & Mathematics with Applications, 81:42–74, 2021
work page 2021
-
[3]
P. Benner, S. Gugercin, and K. Willcox. A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Review , 57(4):483–531, 2015. doi: 10.1137/130932715
- [4]
-
[5]
G. Berkooz, P. Holmes, and J. L. Lumley. The proper orthogonal decomposition in the analysis of turbulent flows. Annual review of fluid mechanics, 25(1):539–575, 1993
work page 1993
-
[6]
C. Bonneville, Y . Choi, D. Ghosh, and J.L. Belof. Gplasdi: Gaussian process-based interpretable latent space dynamics identification through deep autoencoder. Computer Methods in Applied Mechanics and Engineering, 418:116535, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/ j.cma.2023.116535
-
[7]
C. Bonneville et al. A comprehensive review of latent space dynamics identification algorithms for intrusive and non-intrusive reduced-order-modeling. arXiv preprint arXiv:2403.10748 , 2024
-
[8]
S.L. Brunton, J.L. Proctor, and J.N. Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016. doi: 10.1073/pnas.1517384113
-
[9]
M. Calder, C. Craig, D. Culley, R. de Cani, C. A. Donnelly, R. Douglas, B. Edmonds, J. Gas- coigne, N. Gilbert, C. Hargrove, F. Hinds, D. C. Lane, D. Mitchell, G. Pavey, D. Robertson, B. Rosewell, S. Sherwin, M. Walport, and A. Wilson. Computational modelling for decision- making: where, why, what, who and how. Royal Society Open Science, 5(6):172096, 201...
-
[10]
K. Champion, B. Lusch, J. N. Kutz, and S. L. Brunton. Data-driven discovery of coordinates and governing equations. Proceedings of the National Academy of Sciences, 116(45):22445–22451, 2019
work page 2019
-
[11]
M. Cranmer et al. Discovering symbolic models from deep learning with inductive biases. Advances in Neural Information Processing Systems, 33:17429–17442, 2020
work page 2020
-
[12]
R. M. Cummings, W. H. Mason, S. A. Morton, and D. R. McDaniel. Applied computational aerodynamics: A modern engineering approach, volume 53. Cambridge University Press, 2015
work page 2015
-
[13]
A. N. Diaz, Y . Choi, and M. Heinkenschloss. A fast and accurate domain decomposition nonlinear manifold reduced order model. Computer Methods in Applied Mechanics and Engineering, 425:116943, 2024
work page 2024
-
[14]
Fries, X.iaolong He, and Y .oungsoo Choi
W.illiam D. Fries, X.iaolong He, and Y .oungsoo Choi. Lasdi: Parametric latent space dynamics identification. Computer Methods in Applied Mechanics and Engineering, 399:115436, 2022. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2022.115436
-
[15]
C. Geuzaine and J.F. Remacle. Gmsh: A 3-d finite element mesh generator with built-in pre- and post-processing facilities. International Journal for Numerical Methods in Engineering, 79 (11):1309–1331, 2009. doi: https://doi.org/10.1002/nme.2579
-
[16]
X. He, Y . Choi, W.D. Fries, J.L. Belof, and J. Chen. glasdi: Parametric physics-informed greedy latent space dynamics identification. Journal of Computational Physics, 489:112267, 2023. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2023.112267
-
[17]
X. He, A. Tran, D.M. Bortz, and Y . Choi. Physics-informed active learning with simultaneous weak-form latent space dynamics identification. International Journal for Numerical Methods in Engineering, 126(1):e7634, 2025. doi: https://doi.org/10.1002/nme.7634
-
[18]
G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006
work page 2006
-
[19]
A.A. Howard, S.H. Murphy, S.E. Ahmed, and P. Stinis. Stacked networks improve physics- informed training: Applications to neural networks and deep operator networks. Foundations of Data Science, 7(1):134–162, 2025. doi: 10.3934/fods.2024029
- [20]
-
[21]
O. Issan and B. Kramer. Predicting solar wind streams from the inner-heliosphere to earth via shifted operator inference. arXiv preprint arXiv:2203.13372, 2022
-
[22]
G.-S. Jiang and C.-W. Shu. Efficient implementation of weighted ENO schemes. Journal of Computational Physics, 126(1):202–228, 1996. doi: 10.1006/jcph.1996.0130
-
[23]
D. Jones, C. Snider, A. Nassehi, J. Yon, and B. Hicks. Characterising the digital twin: A systematic literature review. CIRP Journal of Manufacturing Science and Technology , 29: 36–52, 2020. ISSN 1755-5817. doi: https://doi.org/10.1016/j.cirpj.2020.02.002
-
[24]
Y . Kim, Y . Choi, D. Widemann, and T. Zohdi. A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder. Journal of Computational Physics, 451:110841, 2022
work page 2022
-
[25]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
D.A. Messenger and D.M. Bortz. Weak sindy: Galerkin-based data-driven model selection. Multiscale Modeling & Simulation, 19(3):1474–1497, 2021. doi: 10.1137/20M1343166
-
[27]
D. Noble. The rise of computational biology. Nature Reviews Molecular Cell Biology, 3(6): 459–463, 2002
work page 2002
-
[28]
J. Sur R. Park, S.W. Cheung, Y . Choi, and Yeonjong Shin. tlasdi: Thermodynamics-informed latent space dynamics identification. Computer Methods in Applied Mechanics and Engineering, 429:117144, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2024.117144
-
[29]
A. T. Patera, G. Rozza, et al. Reduced basis approximation and a posteriori error estimation for parametrized partial differential equations. 2007
work page 2007
-
[30]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and É. Duchesnay. Scikit-learn: Machine learning in python. J. Mach. Learn. Res., 12(null):2825–2830, November 2011. ISSN 1532-4435. 11
work page 2011
-
[31]
E. Qian, B. Kramer, B. Peherstorfer, and K. Willcox. Lift & learn: Physics-informed machine learning for large-scale nonlinear dynamical systems. Physica D: Nonlinear Phenomena, 406: 132401, 2020
work page 2020
-
[32]
C. E. Rasmussen and C. K. I. Williams. Gaussian Processes for Machine Learning. The MIT Press, 11 2005. ISBN 9780262256834. doi: 10.7551/mitpress/3206.001.0001
-
[33]
M. G. Safonov and R. Chiang. A schur method for balanced-truncation model reduction. IEEE Transactions on Automatic Control, 34(7):729–733, 1989
work page 1989
-
[34]
M. Schmidt and H. Lipson. Distilling free-form natural laws from experimental data. Science, 324(5923):81–85, 2009
work page 2009
- [35]
-
[36]
A. Tran, X. He, D. A. Messenger, Y . Choi, and D. M. Bortz. Weak-form latent space dynamics identification. Computer Methods in Applied Mechanics and Engineering , 427:116998, Jul 2024
work page 2024
-
[37]
D. Vasileska, S. M. Goodnick, and G. Klimeck. Computational Electronics: semiclassical and quantum device modeling and simulation. CRC press, 2017
work page 2017
-
[38]
P. Vincent, H. Larochelle, I. Lajoie, Y . Bengio, and P. Manzagol. Stacked denoising autoen- coders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11(110):3371–3408, 2010
work page 2010
-
[39]
Y . Wang and C. Lai. Multi-stage neural networks: Function approximator of machine precision. Journal of Computational Physics, 504:112865, 2024. ISSN 0021-9991. doi: https://doi.org/10. 1016/j.jcp.2024.112865
-
[40]
Multi-stage convolutional autoencoder network for hyperspectral unmixing
Yang Yu, Yong Ma, Xiaoguang Mei, Fan Fan, Jun Huang, and Hao Li. Multi-stage convolutional autoencoder network for hyperspectral unmixing. International Journal of Applied Earth Observation and Geoinformation, 113:102981, 2022. ISSN 1569-8432. doi: https://doi.org/10. 1016/j.jag.2022.102981
-
[41]
J. Zabalza, J. Ren, J. Zheng, H. Zhao, C. Qing, Z. Yang, P. Du, and S. Marshall. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing, 185:1–10, 2016. ISSN 0925-2312. doi: https: //doi.org/10.1016/j.neucom.2015.11.044. 12 Table 1: Hyperparameters and training time of aut...
-
[42]
and RK4 time integration scheme with timestep ∆t = 0.005. We run full-order simulations for parameter values T ∈ [0.9, 1.1] and k ∈ [1.0, 1.2], where the parameter ranges are discretized by ∆T = ∆k = 0.01. To generate data, we sample the solution at every timestep from a uniform64×64 grid in the space-velocity field to obtain 251 snapshots of our state ve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.