Identifiability Challenges in Sparse Linear Ordinary Differential Equations
Pith reviewed 2026-05-19 09:33 UTC · model grok-4.3
The pith
Sparse linear ODEs are unidentifiable from a single trajectory with positive probability in common sparsity regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
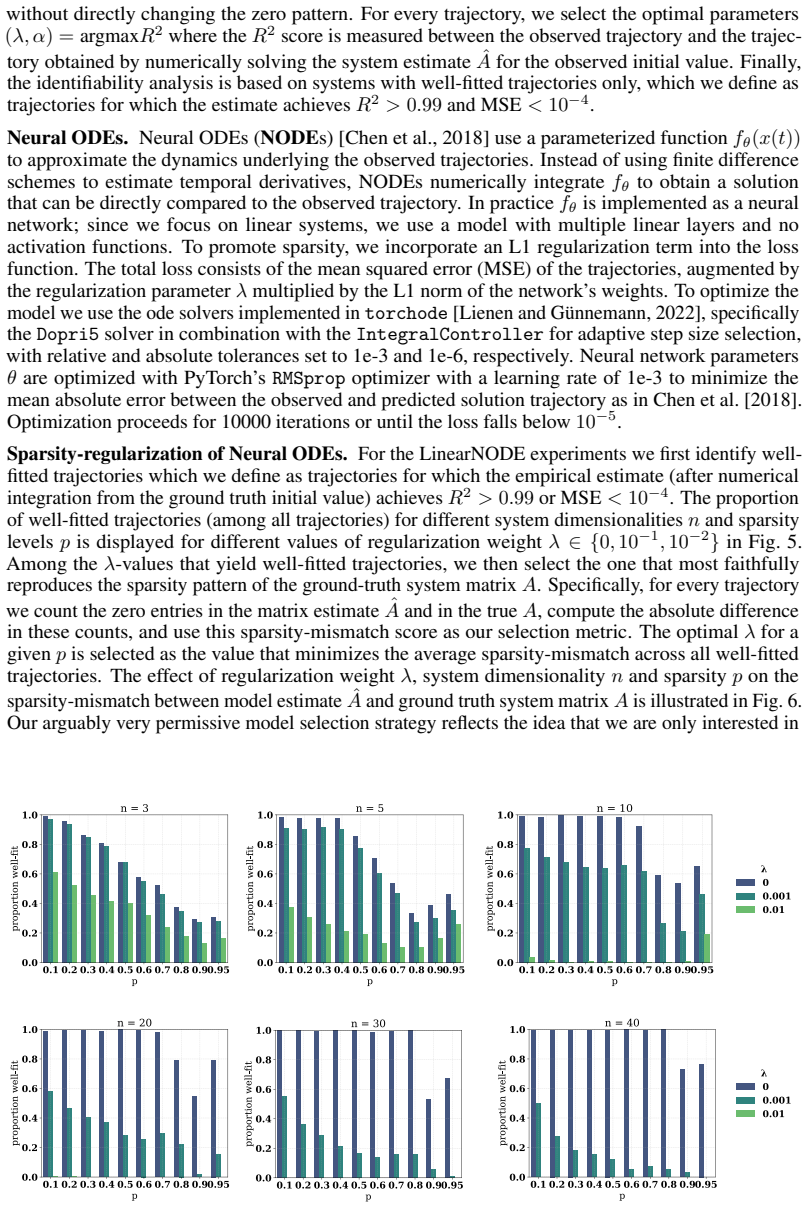
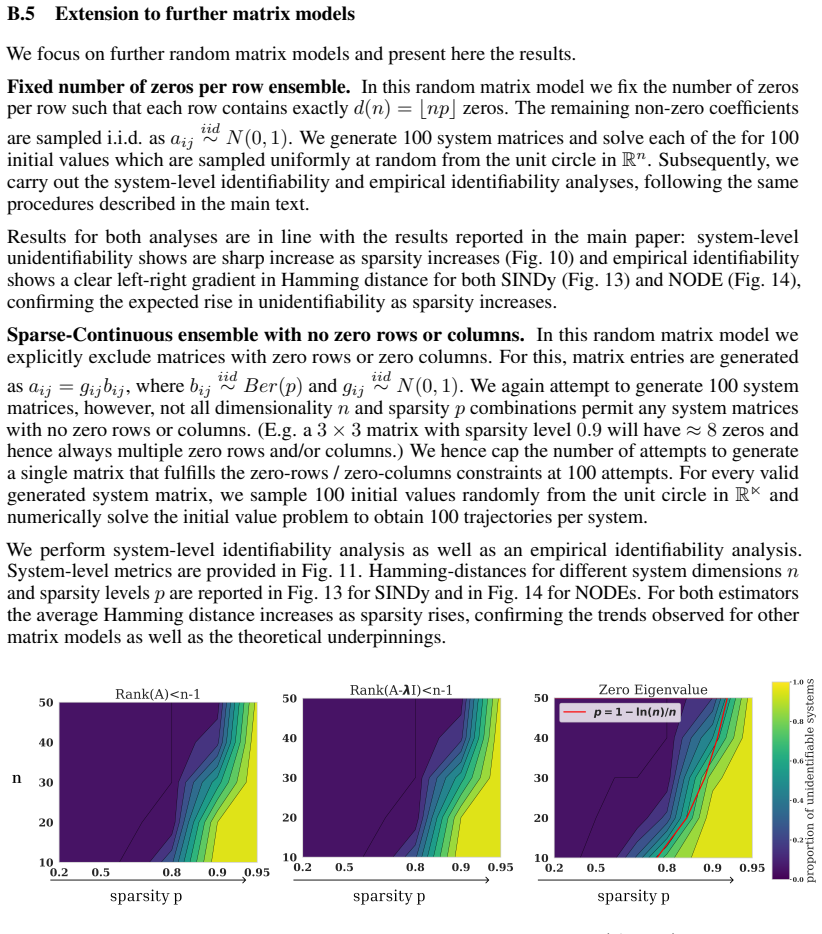
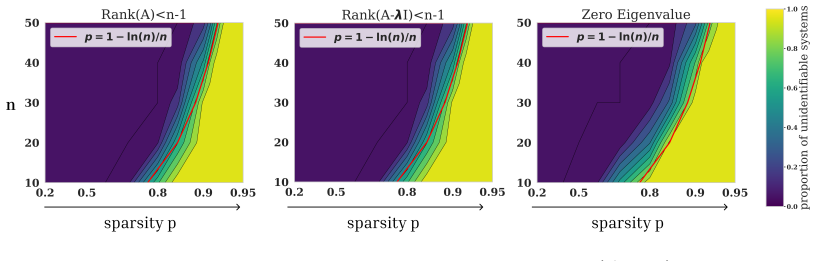
Contrary to the dense case, we show that sparse systems are unidentifiable with a positive probability in practically relevant sparsity regimes and provide lower bounds for this probability. We further study empirically how this theoretical unidentifiability manifests in state-of-the-art methods to estimate linear ODEs from data, confirming that sparse systems are also practically unidentifiable and that theoretical limitations are not resolved through inductive biases or optimization dynamics.
What carries the argument
Probabilistic characterization of when a sparse coefficient matrix produces a non-unique linear ODE consistent with a single observed trajectory.
Load-bearing premise
The sparsity pattern of the coefficient matrix follows distributions typical of biological, social, and physical systems.
What would settle it
A concrete sparse matrix drawn from the relevant regime whose observed trajectory admits only one consistent linear ODE would contradict the positive-probability unidentifiability result.
Figures











read the original abstract
Dynamical systems modeling is a core pillar of scientific inquiry across natural and life sciences. Increasingly, dynamical system models are learned from data, rendering identifiability a paramount concept. For systems that are not identifiable from data, no guarantees can be given about their behavior under new conditions and inputs, or about possible control mechanisms to steer the system. It is known in the community that "linear ordinary differential equations (ODE) are almost surely identifiable from a single trajectory." However, this only holds for dense matrices. The sparse regime remains underexplored, despite its practical relevance with sparsity arising naturally in many biological, social, and physical systems. In this work, we address this gap by characterizing the identifiability of sparse linear ODEs. Contrary to the dense case, we show that sparse systems are unidentifiable with a positive probability in practically relevant sparsity regimes and provide lower bounds for this probability. We further study empirically how this theoretical unidentifiability manifests in state-of-the-art methods to estimate linear ODEs from data. Our results corroborate that sparse systems are also practically unidentifiable. Theoretical limitations are not resolved through inductive biases or optimization dynamics. Our findings call for rethinking what can be expected from data-driven dynamical system modeling and allows for quantitative assessments of how much to trust a learned linear ODE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, unlike dense linear ODEs which are almost surely identifiable from a single trajectory, sparse linear ODEs are unidentifiable with positive probability under sparsity regimes typical of biological, social, and physical systems. It derives explicit lower bounds on this unidentifiability probability and provides empirical evidence that state-of-the-art estimation methods do not overcome the theoretical limitations, even with inductive biases.
Significance. If the central claim holds, the work is significant for data-driven dynamical systems modeling. It supplies an independent theoretical characterization of identifiability failure in the sparse regime together with separate empirical validation on practical methods, enabling quantitative assessment of when learned linear ODEs can be trusted for prediction or control in sparse domains.
major comments (1)
- [§3] §3 (Theoretical Results), the probability space over sparsity patterns: the lower bounds on P(unidentifiable) are derived under an i.i.d. Bernoulli model for the support of A. This choice is load-bearing for the claim that unidentifiability occurs with positive probability 'in practically relevant sparsity regimes' and 'distributions typical of biological, social, and physical systems,' because configuration, preferential-attachment, or modular models (explicitly named in the abstract) assign probability zero or exponentially small to the disconnected-component and invariant-subspace events that drive the bounds.
minor comments (2)
- [Abstract] The abstract and introduction use 'practically relevant sparsity regimes' without an explicit cross-reference to the precise sparsity parameters or random-graph model employed in the theorems.
- [§2] Notation for the observed trajectory and the cyclic subspace generated by x0 could be introduced earlier in the preliminaries to improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We appreciate the recognition of the significance of our results on identifiability challenges for sparse linear ODEs. We address the major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Results), the probability space over sparsity patterns: the lower bounds on P(unidentifiable) are derived under an i.i.d. Bernoulli model for the support of A. This choice is load-bearing for the claim that unidentifiability occurs with positive probability 'in practically relevant sparsity regimes' and 'distributions typical of biological, social, and physical systems,' because configuration, preferential-attachment, or modular models (explicitly named in the abstract) assign probability zero or exponentially small to the disconnected-component and invariant-subspace events that drive the bounds.
Authors: We thank the referee for this precise observation. Our explicit lower bounds on the unidentifiability probability are derived under the i.i.d. Bernoulli model on the support of A, which permits direct calculation of the probabilities of the relevant events (disconnected components and invariant subspaces). This is a standard modeling choice in the sparse random matrix literature. While the abstract cites configuration, preferential-attachment, and modular models as motivating examples of sparsity in applied domains, the quantitative claims and bounds in §3 are specific to the Bernoulli setting. We agree that, under certain alternative generative models, the probability of the critical events may be zero or exponentially small, which narrows the direct applicability of the stated lower bounds. In the revised manuscript we will add a clarifying paragraph in §3 that (i) states the modeling assumption explicitly, (ii) notes that the positive-probability result is tied to the Bernoulli regime, and (iii) suggests that analogous identifiability questions under other sparsity models constitute a natural direction for future work. This change will make the scope and limitations of the theoretical results more transparent without altering the core contribution. The empirical section, which demonstrates that state-of-the-art estimators fail to recover unique parameters on sparse systems drawn from a variety of practical regimes, remains independent of the specific generative model and continues to support the practical message of the paper. revision: partial
Circularity Check
No significant circularity in identifiability analysis for sparse linear ODEs
full rationale
The paper derives lower bounds on the probability of unidentifiability for sparse linear ODEs by considering a probability space over sparsity patterns (such as independent Bernoulli) and analyzing when the cyclic subspace generated by a generic initial condition x0 becomes proper, allowing distinct sparse matrices A' to produce identical trajectories. This follows from standard results in linear algebra and measure theory applied to the support of A, without reducing to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The empirical validation on state-of-the-art estimators is presented separately and does not underpin the theoretical claims. The derivation is self-contained and externally verifiable under the stated assumptions on the sparsity distribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Contrary to the dense case, we show that sparse systems are unidentifiable with a positive probability in practically relevant sparsity regimes and provide lower bounds for this probability.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A system A is globally unidentifiable if and only if it has more than one Jordan block corresponding to the same eigenvalue
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Limits of Learning Linear Dynamics from Experiments
The reachable subspace dynamics of LTI systems remain uniquely identifiable from any experiment, even when the full system is not.
-
Symbolic recovery of PDEs from measurement data
Symbolic rational-function networks recover an admissible PDE from noiseless complete measurements and select the regularization-minimizing parameterization within the architecture.
Reference graph
Works this paper leans on
-
[1]
Beyond predictions in neural odes: Identification and interventions
Hananeh Aliee, Fabian J Theis, and Niki Kilbertus. Beyond predictions in neural odes: Identification and interventions. arXiv preprint arXiv:2106.12430,
-
[2]
Predicting ordinary differential equations with transformers
Sören Becker, Michal Klein, Alexander Neitz, Giambattista Parascandolo, and Niki Kilbertus. Predicting ordinary differential equations with transformers. In International conference on machine learning, pages 1978–2002. PMLR,
work page 1978
-
[3]
Neural graphical modelling in continuous- time: consistency guarantees and algorithms
Alexis Bellot, Kim Branson, and Mihaela van der Schaar. Neural graphical modelling in continuous- time: consistency guarantees and algorithms. arXiv preprint arXiv:2105.02522,
-
[4]
ISSN 0027-8424. doi: 10.1073/pnas.1517384113. URL https://www.pnas.org/content/113/15/3932. Michelle Carey, Juan Camilo Ramírez, Shuang Wu, and Hulin Wu. A big data pipeline: Identi- fying dynamic gene regulatory networks from time-course gene expression omnibus data with applications to influenza infection. Statistical methods in medical research, 27(7):...
-
[5]
Constrained physical-statistics models for dynamical system identification and prediction
Jérémie Donà, Marie Déchelle, Marina Levy, and Patrick Gallinari. Constrained physical-statistics models for dynamical system identification and prediction. In ICLR 2022-The Tenth International Conference on Learning Representations,
work page 2022
-
[6]
2020.pandas-dev/pandas: Pandas
URL https://doi. org/10.5281/zenodo.3509134. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chint...
-
[7]
Learning influence structure in sparse social networks
Chiara Ravazzi, Roberto Tempo, and Fabrizio Dabbene. Learning influence structure in sparse social networks. IEEE Transactions on Control of Network Systems, 5(4):1976–1986,
work page 1976
-
[8]
Symbolic recovery of differential equations: The identifiability problem
Philipp Scholl, Aras Bacho, Holger Boche, and Gitta Kutyniok. Symbolic recovery of differential equations: The identifiability problem. arXiv preprint arXiv:2210.08342,
-
[9]
The uniqueness problem of physical law learning
Philipp Scholl, Aras Bacho, Holger Boche, and Gitta Kutyniok. The uniqueness problem of physical law learning. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
work page 2023
-
[10]
Neural structure learning with stochastic differential equations
Benjie Wang, Joel Jennings, and Wenbo Gong. Neural structure learning with stochastic differential equations. arXiv preprint arXiv:2311.03309,
-
[11]
doi: 10.25080/Majora-92bf1922-00a. Xiaohua Xia and Claude H Moog. Identifiability of nonlinear systems with application to hiv/aids models. IEEE transactions on automatic control, 48(2):330–336,
-
[12]
→ 0 for n → ∞. That is, there is a threshold at p = ln(n)/n decisive for whether A is asymptotically globally unidentifiable with high probability or not. Proof. From A form the random bipartite graphGn,n,s with A as the corresponding adjacency matrix. Edges are present independently with probability s = s(n) = 1 − p(n). For every bipartite graph Gn,n,s l...
work page 2015
-
[13]
15 Table 1: Overview of resources used in our work. Name Reference License Python [van Rossum and Drake, 2009] PSF License PyTorch [Paszke et al., 2019] BSD-style license Numpy [Harris et al., 2020] BSD-style license Pandas [pandas development team, 2020, Wes McKinney, 2010] BSD-style license Matplotlib [Hunter, 2007] modified PSF (BSD compatible) Scikit-...
work page 2009
-
[14]
As expected, the (mean) empirical measure closely matches the theoretical expected distance between a random unit vector x0 and a d0-dimensional subspace of Rn [Vershynin, 2018], given by E[dA(x0) | n, d0] = Γ(n/2)Γ((n − d0 + 1)/2) Γ((n − d0)/2)Γ((n + 1)/2) , hence (in expectation) validating the computation of our distance-to-unidentifiability dA. 0 1 2 ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.