"Faithful to What?" On the Limits of Fidelity-Based Explanations
Pith reviewed 2026-05-19 09:03 UTC · model grok-4.3
The pith
Fidelity to a neural network's predictions does not ensure surrogates recover the data patterns that give the network its edge over simpler models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
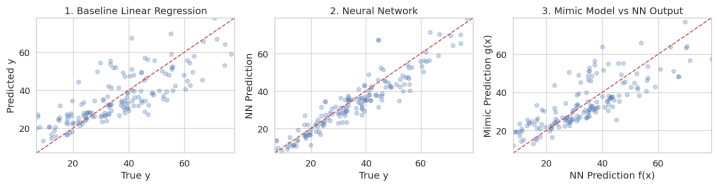
Across synthetic and real-world regression datasets, surrogates can achieve high fidelity to a neural network while failing to recover the predictive gains that distinguish the network from simpler models. In several cases, high-fidelity surrogates underperform even linear baselines trained directly on the data. These results demonstrate that explaining a model's behavior is not equivalent to explaining the task-relevant structure of the data, highlighting a limitation of fidelity-based explanations when used to reason about predictive performance.
What carries the argument
The linearity score λ(f), an R² measure of how well a linear surrogate fits the regression network's input-output mapping, used as a diagnostic distinct from fidelity.
If this is right
- Surrogates may match network outputs closely without capturing the network's advantages over linear models.
- High-fidelity surrogates can sometimes perform worse than linear baselines trained on the same data.
- Fidelity-based evaluation alone is insufficient for assessing whether an explanation accounts for predictive performance gains.
Where Pith is reading between the lines
- The distinction between model alignment and data alignment suggests that other explanation techniques relying on output matching may need similar diagnostics.
- Testing the linearity score on classification tasks or deeper architectures could show whether the gap between fidelity and data recovery appears more broadly.
Load-bearing premise
The premise that alignment to the data-generating signal rather than to the learned model is the appropriate target for explanations of predictive performance.
What would settle it
A finding that high-fidelity surrogates consistently recover the performance gains of neural networks over linear models across the synthetic and real-world datasets would contradict the reported observations.
Figures




read the original abstract
In explainable AI, surrogate models are commonly evaluated by their fidelity to a neural network's predictions. Fidelity, however, measures alignment to a learned model rather than alignment to the data-generating signal underlying the task. This work introduces the linearity score $\lambda(f)$, a diagnostic that quantifies the extent to which a regression network's input--output behavior is linearly decodable. $\lambda(f)$ is defined as an $R^2$ measure of surrogate fit to the network. Across synthetic and real-world regression datasets, we find that surrogates can achieve high fidelity to a neural network while failing to recover the predictive gains that distinguish the network from simpler models. In several cases, high-fidelity surrogates underperform even linear baselines trained directly on the data. These results demonstrate that explaining a model's behavior is not equivalent to explaining the task-relevant structure of the data, highlighting a limitation of fidelity-based explanations when used to reason about predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the linearity score λ(f), defined as an R² measure of how well a surrogate fits a regression neural network f, to argue that fidelity to the network's predictions does not imply recovery of the network's predictive gains over simpler models. Across synthetic and real-world regression datasets, the authors report that high-fidelity surrogates can underperform even linear baselines trained directly on the data, while the NN itself outperforms those baselines. This is presented as evidence that fidelity-based explanations are limited when reasoning about task performance, because they align to the learned model rather than the data-generating signal.
Significance. If the empirical findings hold after addressing the mathematical bounding issue, the work would usefully highlight a distinction between model fidelity and task-relevant structure in XAI for regression. The linearity score provides a concrete diagnostic that could be adopted more broadly. The paper earns credit for direct empirical comparisons on both synthetic and real datasets and for separating fidelity from downstream task performance, though the evidential strength depends on controls and gap sizes not fully detailed in the provided sections.
major comments (1)
- [Empirical results and definition of fidelity] The central empirical claim—that high-fidelity surrogates can underperform linear baselines while the NN outperforms them—requires clarification in light of the error decomposition. Expanding MSE(ŝ, y) = MSE(f, y) + MSE(ŝ, f) + 2 Cov(f-y, ŝ-f) shows that small MSE(ŝ, f) (high fidelity) bounds the performance gap between ŝ and f; adverse covariance can widen it only modestly. The reported reversals relative to a linear baseline therefore depend on either narrow NN-linear gaps or fidelity that is high only in a weak/in-sample sense. Please cite the specific fidelity R² values, test MSE/R² gaps, and covariance terms from the synthetic and real-world experiments (e.g., in the results tables or § on empirical evaluation) to demonstrate that the findings are not precluded by this identity.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from an explicit statement of how λ(f) differs numerically from standard fidelity metrics used for the surrogates.
- [Experimental setup] Missing details on surrogate implementations (exact architectures, training procedures, hyperparameter choices) and whether error bars or multiple runs are reported would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback, particularly the observation regarding the error decomposition and its implications for interpreting the empirical reversals. We agree that explicitly reporting the quantitative details will strengthen the clarity of the central claim and address potential concerns about whether the findings are consistent with the identity. We will revise the manuscript to incorporate these elements in the empirical evaluation section.
read point-by-point responses
-
Referee: [Empirical results and definition of fidelity] The central empirical claim—that high-fidelity surrogates can underperform linear baselines while the NN outperforms them—requires clarification in light of the error decomposition. Expanding MSE(ŝ, y) = MSE(f, y) + MSE(ŝ, f) + 2 Cov(f-y, ŝ-f) shows that small MSE(ŝ, f) (high fidelity) bounds the performance gap between ŝ and f; adverse covariance can widen it only modestly. The reported reversals relative to a linear baseline therefore depend on either narrow NN-linear gaps or fidelity that is high only in a weak/in-sample sense. Please cite the specific fidelity R² values, test MSE/R² gaps, and covariance terms from the synthetic and real-world experiments (e.g., in the results tables or § on empirical evaluation) to demonstrate that the findings are not precluded by this identity.
Authors: We appreciate this rigorous point and the explicit decomposition, which correctly shows that MSE(ŝ, y) − MSE(f, y) = MSE(ŝ, f) + 2 Cov(f − y, ŝ − f). Our claim, however, centers on the comparison between the surrogate ŝ and a linear model trained directly on the target y, rather than on the absolute gap between ŝ and f. When the NN’s advantage over the linear baseline stems from non-linear structure that a surrogate approximates only in an average (high-R²) sense without recovering the same task-relevant interactions, it is possible for ŝ to fall below the linear baseline even while remaining close to f. We will revise the empirical evaluation section (and associated tables) to report: (i) the fidelity R² values λ(f) achieved by the surrogates on both synthetic and real-world datasets, (ii) the test MSE and R² gaps between the NN, the linear baseline, and each surrogate, and (iii) the covariance terms from the decomposition computed on the test sets. These additions will allow readers to verify that the observed reversals are compatible with the identity while still illustrating the distinction between fidelity to the learned model and recovery of predictive structure in the data. If any of these quantities are not already tabulated, they will be added in the revision. revision: yes
Circularity Check
Empirical comparisons of surrogates vs. networks and baselines show no circular reduction
full rationale
The paper's central claims rest on direct empirical measurements: surrogates are trained to match neural network outputs (via the defined λ(f) as R²), then evaluated for task performance (R² or MSE against ground-truth y) on held-out data, with comparisons to linear models trained directly on the same data. No load-bearing step reduces a 'prediction' or result to a quantity defined by the paper's own fitted parameters or self-citations. The linearity score is introduced as an explicit diagnostic rather than smuggled in, and the reported findings (high-fidelity surrogates sometimes underperforming linear baselines) are presented as observations from synthetic and real-world datasets rather than derived by construction from the definition of fidelity. This is self-contained against external benchmarks and receives a low circularity score consistent with normal empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fidelity measures alignment to a learned model rather than alignment to the data-generating signal underlying the task.
invented entities (1)
-
linearity score λ(f)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes, November 2018
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, November 2018
work page 2018
- [2]
-
[3]
Mark W. Craven and Jude W. Shavlik. Extracting tree-structured representations of trained networks. In Proceedings of the 9th International Conference on Neural Information Process- ing Systems, NIPS’95, pages 24–30, Denver, Colorado and Cambridge, MA, USA, 1995. MIT Press
work page 1995
-
[4]
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R. Costa-juss `a. A Primer on the Inner Workings of Transformer-based Language Models, October 2024
work page 2024
-
[5]
Complexity of Linear Regions in Deep Networks, June 2019
Boris Hanin and David Rolnick. Complexity of Linear Regions in Deep Networks, June 2019
work page 2019
-
[6]
John Hewitt and Christopher D. Manning. A Structural Probe for Finding Syntax in Word Representations. In Proceedings of the 2019 Conference of the North , pages 4129–4138, Min- neapolis, Minnesota, 2019. Association for Computational Linguistics
work page 2019
-
[7]
R. Kelley Pace and Ronald Barry. Sparse spatial autoregressions. Statistics & Probability Letters, 33(3):291–297, May 1997
work page 1997
-
[8]
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems , NIPS’17, pages 4768–4777, Long Beach, California, USA and Red Hook, NY , USA, 2017. Curran Associates Inc
work page 2017
-
[9]
Progress measures for grokking via mechanistic interpretability, October 2023
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability, October 2023
work page 2023
-
[10]
Abolafia, Jeffrey Pennington, and Jascha Sohl- Dickstein
Roman Novak, Yasaman Bahri, Daniel A. Abolafia, Jeffrey Pennington, and Jascha Sohl- Dickstein. Sensitivity and Generalization in Neural Networks: An Empirical Study, June 2018
work page 2018
-
[11]
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom In: An Introduction to Circuits. Distill, 5(3):10.23915/distill.00024.001, March 2020
-
[12]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singu- lar Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability, November 2017
work page 2017
-
[13]
”Why Should I Trust You?”: Ex- plaining the Predictions of Any Classifier
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ”Why Should I Trust You?”: Ex- plaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD In- ternational Conference on Knowledge Discovery and Data Mining , pages 1135–1144, San Francisco California USA, August 2016. ACM. 9
work page 2016
-
[14]
Understanding Learning Dynamics Of Language Models with
Naomi Saphra and Adam Lopez. Understanding Learning Dynamics Of Language Models with. In Proceedings of the 2019 Conference of the North , pages 3257–3267, Minneapolis, Minnesota, 2019. Association for Computational Linguistics
work page 2019
-
[15]
M. Sato and H. Tsukimoto. Rule extraction from neural networks via decision tree induc- tion. In IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No.01CH37222), volume 3, pages 1870–1875, Washington, DC, USA, 2001. IEEE
work page 2001
-
[16]
I.-C. Yeh. Modeling of strength of high-performance concrete using artificial neural networks. Cement and Concrete Research, 28(12):1797–1808, December 1998. 10
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.