Random Matrix Theory for Deep Learning: Beyond Eigenvalues of Linear Models
Pith reviewed 2026-05-19 09:53 UTC · model grok-4.3
The pith
A High-dimensional Equivalent unifies random matrix tools to characterize training and generalization in nonlinear deep networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
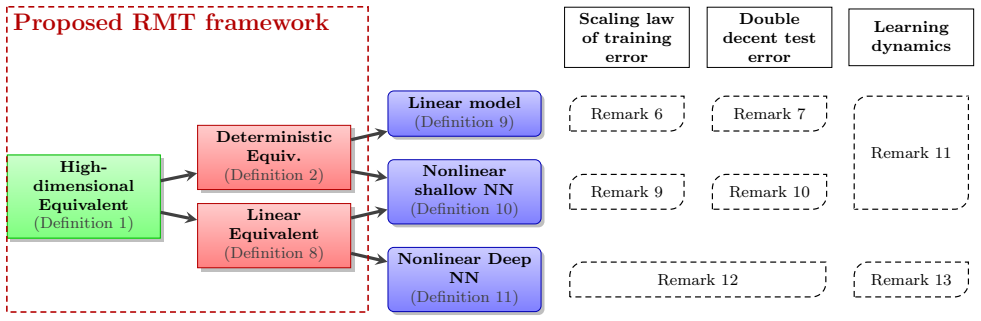
The paper claims that the High-dimensional Equivalent, which generalizes both the deterministic equivalent and the linear equivalent, allows precise asymptotic characterizations of training and generalization performance for linear models, nonlinear shallow networks, and deep networks in the proportional high-dimensional regime. These characterizations capture phenomena such as scaling laws, double descent, and nonlinear learning dynamics through analysis of generic eigenspectral functionals.
What carries the argument
The High-dimensional Equivalent, a unifying object that systematically addresses high dimensionality, nonlinearity, and generic eigenspectral functionals for networks in the proportional regime.
If this is right
- Precise asymptotic formulas for training loss and generalization error become available for both shallow and deep nonlinear networks.
- Scaling laws and double-descent phenomena receive explicit dependence on width, depth, and activation type.
- Nonlinear learning dynamics can be tracked through the evolution of the relevant spectral functionals rather than through direct simulation.
- A unified perspective replaces separate analyses for linear and nonlinear models.
Where Pith is reading between the lines
- The same machinery could be applied to study how depth interacts with data geometry beyond the proportional regime.
- One could test whether the framework recovers known results for kernel methods when the network becomes infinitely wide.
- If the equivalent holds, it might simplify analysis of optimization trajectories in overparameterized models.
Load-bearing premise
That a single equivalent can be derived which continues to control the relevant spectral behavior once nonlinear activations are introduced in the proportional regime.
What would settle it
Empirical training curves or test-error plots for a two-layer ReLU network in the proportional regime that deviate systematically from the formulas derived via the High-dimensional Equivalent.
Figures





read the original abstract
Modern Machine Learning (ML) and Deep Neural Networks (DNNs) often operate on high-dimensional data and rely on overparameterized models, where classical low-dimensional intuitions break down. In particular, the proportional regime where the data dimension, sample size, and number of model parameters are all large and comparable, gives rise to novel and sometimes counterintuitive behaviors. This paper extends traditional Random Matrix Theory (RMT) beyond eigenvalue-based analysis of linear models to address the challenges posed by nonlinear ML models such as DNNs in this regime. We introduce the concept of High-dimensional Equivalent, which unifies and generalizes both Deterministic Equivalent and Linear Equivalent, to systematically address three technical challenges: high dimensionality, nonlinearity, and the need to analyze generic eigenspectral functionals. Leveraging this framework, we provide precise characterizations of the training and generalization performance of linear models, nonlinear shallow networks, and deep networks. Our results capture rich phenomena, including scaling laws, double descent, and nonlinear learning dynamics, offering a unified perspective on the theoretical understanding of deep learning in high dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends Random Matrix Theory beyond eigenvalue analysis of linear models by introducing the 'High-dimensional Equivalent,' which unifies Deterministic Equivalents and Linear Equivalents. This framework is claimed to systematically handle high dimensionality, nonlinearity, and generic eigenspectral functionals in the proportional regime, enabling precise characterizations of training and generalization performance for linear models, nonlinear shallow networks, and deep networks, while capturing phenomena such as scaling laws, double descent, and nonlinear learning dynamics.
Significance. If the derivations hold without hidden restrictions on layer interactions or activation functions, the work would offer a meaningful unification for analyzing overparameterized nonlinear models, extending RMT tools to deep networks in a way that could support falsifiable predictions and reproducible analyses of generalization in high dimensions.
major comments (2)
- [Framework introduction] Framework introduction (abstract and corresponding section): The central claim that the High-dimensional Equivalent systematically derives characterizations for deep networks requires explicit steps showing how cross-layer correlations induced by backpropagation and shared data are captured; if the derivation relies on recursive single-layer application, it risks failing to account for compounded nonlinearity effects on arbitrary eigenspectral functionals, which is load-bearing for the claimed precise performance characterizations.
- [Deep network results] Deep network results section: The precise characterizations of training and generalization for deep networks are presented without visible error bounds or validation against the proportional regime assumptions; this undermines the unification claim if the High-dimensional Equivalent reduces to fitted quantities under generic nonlinear settings.
minor comments (2)
- [Abstract] Abstract: The phrasing 'precise characterizations' would benefit from a brief note on the scope of functionals treated (e.g., beyond traces or resolvents) to improve clarity for readers.
- [Notation and definitions] Notation: Ensure consistent definition of the High-dimensional Equivalent across sections to avoid potential self-referential issues when extending from linear to nonlinear cases.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important aspects of our framework's presentation and the need for additional rigor in the deep network analysis. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Framework introduction (abstract and corresponding section): The central claim that the High-dimensional Equivalent systematically derives characterizations for deep networks requires explicit steps showing how cross-layer correlations induced by backpropagation and shared data are captured; if the derivation relies on recursive single-layer application, it risks failing to account for compounded nonlinearity effects on arbitrary eigenspectral functionals, which is load-bearing for the claimed precise performance characterizations.
Authors: We agree that the handling of cross-layer correlations merits more explicit exposition. The High-dimensional Equivalent is defined to propagate the joint statistics across layers by constructing an equivalent model that preserves the necessary second-order moments and spectral functionals under the proportional regime, thereby incorporating the effects of shared data and backpropagation-induced dependencies. To address the concern directly, we will add a dedicated subsection in the framework introduction that walks through the iterative construction step by step, showing how compounded nonlinearity is captured without reducing to independent single-layer applications. This revision will make the load-bearing assumptions transparent. revision: yes
-
Referee: Deep network results section: The precise characterizations of training and generalization for deep networks are presented without visible error bounds or validation against the proportional regime assumptions; this undermines the unification claim if the High-dimensional Equivalent reduces to fitted quantities under generic nonlinear settings.
Authors: The characterizations are asymptotic results in the proportional high-dimensional limit. We acknowledge that the current version does not include explicit non-asymptotic error bounds or extensive numerical validation for the deep network case. In the revision we will add a discussion of the convergence rates drawing on existing RMT concentration results, together with a new set of numerical experiments that compare the theoretical predictions against finite-dimensional simulations for both training and generalization error in deep networks. This will clarify that the equivalents are not merely fitted but derived from the high-dimensional analysis. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and framework description introduce the High-dimensional Equivalent as a generalization of prior Deterministic and Linear Equivalents to handle nonlinearity and generic functionals for deep networks. No equations, self-citations, or derivations are quoted that reduce any claimed prediction or characterization to a fitted input, self-definition, or load-bearing self-citation chain. The performance characterizations for linear models, shallow networks, and deep networks are presented as derived outputs from the framework rather than inputs renamed as results. This qualifies as a self-contained theoretical extension with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard high-dimensional proportional regime assumptions from random matrix theory
invented entities (1)
-
High-dimensional Equivalent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Definition 1 (High-dimensional Equivalent) … f(Mϕ(X)) − f(˜Mϕ(X)) → 0 … Mϕ(X) ↔ ˜Mϕ(X)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 7 (High-dimensional linearization of kernel matrix) … ˜Kϕ = a²ϕ;0 1n1⊤n + a²ϕ;1 X⊤X + …
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add / embed_eq_pow echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 8 … CK matrix Kℓ … ˜Kϕ,ℓ = α²ℓ,1 X⊤X + … recursion αℓ,1 = aϕℓ;1 · αℓ−1,1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Potters and J.-P. Bouchaud, A First Course in Random Matrix Theory: for Physicists, Engineers and Data Scientists . Cambridge University Press, 2020
work page 2020
-
[2]
G. W. Anderson, A. Guionnet, and O. Zeitouni, An Introduction to Random Matrices, ser. Cambridge Studies in Advanced Mathematics. Cambridge University Press, 2010, vol. 118
work page 2010
- [3]
-
[4]
Cleaning large correlation matrices: Tools from Random Matrix Theory,
J. Bun, J.-P. Bouchaud, and M. Potters, “Cleaning large correlation matrices: Tools from Random Matrix Theory,” Physics Reports, vol. 666, pp. 1–109, 2017
work page 2017
-
[5]
Random matrix theory and wireless communications,
A. M. Tulino and S. Verd´ u, “Random matrix theory and wireless communications,”Foun- dations and Trends® in Communications and Information Theory, vol. 1, no. 1, pp. 1–182, 2004
work page 2004
-
[6]
R. Couillet and M. Debbah, Random Matrix Methods for Wireless Communications. Cam- bridge University Press, 2011
work page 2011
-
[7]
Surprises in high-dimensional ridgeless least squares interpolation,
T. Hastie, A. Montanari, S. Rosset, and R. J. Tibshirani, “Surprises in high-dimensional ridgeless least squares interpolation,” The Annals of Statistics , vol. 50, no. 2, pp. 949–986, Apr. 2022
work page 2022
-
[8]
S. Mei and A. Montanari, “The Generalization Error of Random Features Regression: Precise Asymptotics and the Double Descent Curve,”Communications on Pure and Applied Mathematics, 2021
work page 2021
-
[9]
Deep Neural Networks as Gaussian Processes,
J. Lee, J. Sohl-dickstein, J. Pennington, R. Novak, S. Schoenholz, and Y. Bahri, “Deep Neural Networks as Gaussian Processes,” in International Conference on Learning Repre- sentations, 2018
work page 2018
-
[10]
Neural Tangent Kernel: Convergence and Gen- eralization in Neural Networks,
A. Jacot, F. Gabriel, and C. Hongler, “Neural Tangent Kernel: Convergence and Gen- eralization in Neural Networks,” in Advances in Neural Information Processing Systems , vol. 31. Curran Associates, Inc., 2018, pp. 8571–8580
work page 2018
-
[11]
Benign overfitting in linear regres- sion,
P. L. Bartlett, P. M. Long, G. Lugosi, and A. Tsigler, “Benign overfitting in linear regres- sion,” Proceedings of the National Academy of Sciences, vol. 117, no. 48, pp. 30 063–30 070, 2020. 21
work page 2020
-
[12]
Introduction to the Non-Asymptotic Analysis of Random Matrices,
R. Vershynin, “Introduction to the Non-Asymptotic Analysis of Random Matrices,” in Compressed Sensing: Theory and Applications , Y. C. Eldar and G. Kutyniok, Eds. Cam- bridge University Press, 2012, pp. 210–268
work page 2012
-
[13]
Central limit theorem for linear eigenvalue statistics of random matrices with independent entries,
A. Lytova and L. Pastur, “Central limit theorem for linear eigenvalue statistics of random matrices with independent entries,” The Annals of Probability , vol. 37, no. 5, pp. 1778– 1840, 2009
work page 2009
-
[14]
CLT for linear spectral statistics of large-dimensional sample covariance matrices,
Z. Bai and J. W. Silverstein, “CLT for linear spectral statistics of large-dimensional sample covariance matrices,” The Annals of Probability , vol. 32, no. 1A, pp. 553–605, 2004
work page 2004
-
[15]
Matrices al´ eatoires: Statistique asymptotique des valeurs pro- pres,
L. Pastur and A. Lejay, “Matrices al´ eatoires: Statistique asymptotique des valeurs pro- pres,” in S´ eminaire de Probabilit´ es XXXVI, J. Az´ ema, M.´Emery, M. Ledoux, and M. Yor, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2003, vol. 1801, pp. 135–164
work page 2003
-
[16]
Distribution of eigenvalues for some sets of random matrices,
V. A. Marcenko and L. A. Pastur, “Distribution of eigenvalues for some sets of random matrices,” Mathematics of the USSR-Sbornik , vol. 1, no. 4, p. 457, 1967
work page 1967
-
[17]
Random matrices: Universality of ESDs and the circular law,
T. Tao, V. Vu, and M. Krishnapur, “Random matrices: Universality of ESDs and the circular law,” The Annals of Probability , vol. 38, no. 5, pp. 2023–2065, 2010
work page 2023
-
[18]
L. A. Pastur and M. Shcherbina, Eigenvalue Distribution of Large Random Matrices , ser. Mathematical Surveys and Monographs. American Mathematical Society, 2011, vol. 171
work page 2011
-
[19]
The gaussian equivalence of generative models for learning with shallow neural networks,
S. Goldt, B. Loureiro, G. Reeves, F. Krzakala, M. M´ ezard, and L. Zdeborov´ a, “The gaussian equivalence of generative models for learning with shallow neural networks,” in Mathemat- ical and Scientific Machine Learning . PMLR, 2022, pp. 426–471
work page 2022
-
[20]
Universality laws for high-dimensional learning with random fea- tures,
H. Hu and Y. M. Lu, “Universality laws for high-dimensional learning with random fea- tures,” IEEE Transactions on Information Theory , vol. 69, no. 3, pp. 1932–1964, 2022
work page 1932
-
[21]
Universality of empirical risk minimization,
A. Montanari and B. N. Saeed, “Universality of empirical risk minimization,” in Conference on Learning Theory. PMLR, 2022, pp. 4310–4312
work page 2022
-
[22]
X. MAI and Z. Liao, “The breakdown of gaussian universality in classification of high- dimensional linear factor mixtures,” in The Thirteenth International Conference on Learn- ing Representations, 2025
work page 2025
-
[23]
High-dimensional asymptotics of prediction: Ridge regression and classification,
E. Dobriban and S. Wager, “High-dimensional asymptotics of prediction: Ridge regression and classification,” The Annals of Statistics , vol. 46, no. 1, pp. 247–279, 2018
work page 2018
-
[24]
Reconciling modern machine-learning practice and the classical bias–variance trade-off,
M. Belkin, D. Hsu, S. Ma, and S. Mandal, “Reconciling modern machine-learning practice and the classical bias–variance trade-off,” Proceedings of the National Academy of Sciences, vol. 116, no. 32, pp. 15 849–15 854, 2019
work page 2019
-
[25]
Z. Liao, R. Couillet, and M. W. Mahoney, “A random matrix analysis of random fourier features: beyond the gaussian kernel, a precise phase transition, and the corresponding double descent,” in Advances in Neural Information Processing Systems , vol. 33. Curran Associates, Inc., 2020, pp. 13 939–13 950
work page 2020
-
[26]
A random matrix approach to neural networks,
C. Louart, Z. Liao, and R. Couillet, “A random matrix approach to neural networks,” Annals of Applied Probability, vol. 28, no. 2, pp. 1190–1248, 2018
work page 2018
-
[27]
C. E. Rasmussen and C. K. I. Williams, Gaussian Processes for Machine Learning , Nov. 2005. 22
work page 2005
-
[28]
On the similarity between the laplace and Neural Tangent Kernels,
A. Geifman, A. Yadav, Y. Kasten, M. Galun, D. Jacobs, and R. Basri, “On the similarity between the laplace and Neural Tangent Kernels,” in Proceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates Inc., 2020, pp. 1451–1461
work page 2020
-
[29]
The Dynamics of Learning: A Random Matrix Approach,
Z. Liao and R. Couillet, “The Dynamics of Learning: A Random Matrix Approach,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 2018, pp. 3072–3081
work page 2018
-
[30]
High-dimensional dynamics of general- ization error in neural networks,
M. S. Advani, A. M. Saxe, and H. Sompolinsky, “High-dimensional dynamics of general- ization error in neural networks,” Neural Networks, vol. 132, pp. 428–446, 2020
work page 2020
-
[31]
Halting Time is Pre- dictable for Large Models: A Universality Property and Average-Case Analysis,
C. Paquette, B. van Merri¨ enboer, E. Paquette, and F. Pedregosa, “Halting Time is Pre- dictable for Large Models: A Universality Property and Average-Case Analysis,” Founda- tions of Computational Mathematics , vol. 23, no. 2, pp. 597–673, 2023
work page 2023
- [32]
-
[33]
Spectra of the Conjugate Kernel and Neural Tangent Kernel for linear-width neural networks,
Z. Fan and Z. Wang, “Spectra of the Conjugate Kernel and Neural Tangent Kernel for linear-width neural networks,” in Advances in Neural Information Processing Systems , vol. 33. Curran Associates, Inc., 2020, pp. 7710–7721
work page 2020
-
[34]
Wide neural networks of any depth evolve as linear models under gradient descent,
J. Lee, L. Xiao, S. S. Schoenholz, Y. Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington, “Wide neural networks of any depth evolve as linear models under gradient descent,” Journal of Statistical Mechanics: Theory and Experiment , vol. 2020, no. 12, p. 124002, 2020
work page 2020
-
[35]
Hanson-Wright inequality and sub-gaussian concentra- tion,
M. Rudelson and R. Vershynin, “Hanson-Wright inequality and sub-gaussian concentra- tion,” Electronic Communications in Probability, vol. 18, no. none, 2013
work page 2013
-
[36]
R. Couillet and Z. Liao, Random Matrix Methods for Machine Learning . Cambridge University Press, 2022
work page 2022
-
[37]
Kernel spectral clustering of large dimensional data,
R. Couillet and F. Benaych-Georges, “Kernel spectral clustering of large dimensional data,” Electronic Journal of Statistics , vol. 10, no. 1, pp. 1393–1454, 2016
work page 2016
-
[38]
Covariance discriminative power of kernel clustering meth- ods,
A. Kammoun and R. Couillet, “Covariance discriminative power of kernel clustering meth- ods,” Electronic Journal of Statistics , vol. 17, no. 1, pp. 291–390, Jan. 2023. 23 A Derivation of Theorem 5 We present here the following (heuristic, and thus more accessible) derivation of Theorem 5. To simplify the derivation, we outline the proof of Theorem 5 by d...
work page 2023
-
[39]
Computing or approximating the expectation of the random matrix Q. For the scalar functionals of interest f(Q) for Q ∈ Rn×n, the first (and often most natural) deterministic quantity to describe its behavior is the expectation E[f(Q)]. In the case of a linear or bilinear functional f(·) as in Definition 2 and Remark 1, this is equal to f(E[Q]). In the cas...
-
[40]
Establishing the LLN-type concentration of f(Q) around f( ˜Q). This step often involves concentration inequalities of the form Pr(|f(Q) − f( ˜Q)| ≥ t) ≤ δ(n, t), (45) for some function δ(n, t) that decreases to zero as n → ∞. This can be achieved, e.g., by bounding sequentially the differences f(Q)−f(E[Q]) and f(E[Q])−f( ˜Q). (The latter uses that the two...
-
[41]
Exponential eigendecay (this is the case for, e.g., RBF kernel [27]) for which we have µK(dt) = αt for some α ∈ (0, 1). In this case, we have θ = 1 α log( n d ) n d + Cα d n , C α = 1 α log π sin(πα) , (64) which is slower than the n−1 rate for linear models in Remark 6, where we use thatR ∞ 0 xαx a+x dx = π sin(πα) · e−aα for α ∈ (0, 1)
-
[42]
ϕ(ξi)ϕ εijξi + 1 − ε2 ij 2 + O(ε4 ij) ! ξj !# = E[ϕ(ξi)ϕ(ξj)] + E
Polynomial eigendecay (this is the case for, e.g., Mat´ ern kernel [27]) for which we have µK(dt) = t−β for some β > 1. In this case, we have θ = Cβ d n 1+ 1 2−β , C β = 2−β r sin(πβ) π , (65) which is faster than the n−1 rate for linear models in Remark 6, where we use thatR ∞ 0 x1−β 1+x dx = π sin(πβ) for β ∈ (0, 2). In particular, in the case of Harmon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.