DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Pith reviewed 2026-05-19 09:49 UTC · model grok-4.3
The pith
Aligning coarse depth normal and edge maps with harmonized visibility priors enables stable patch deformation for multi-view stereo.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
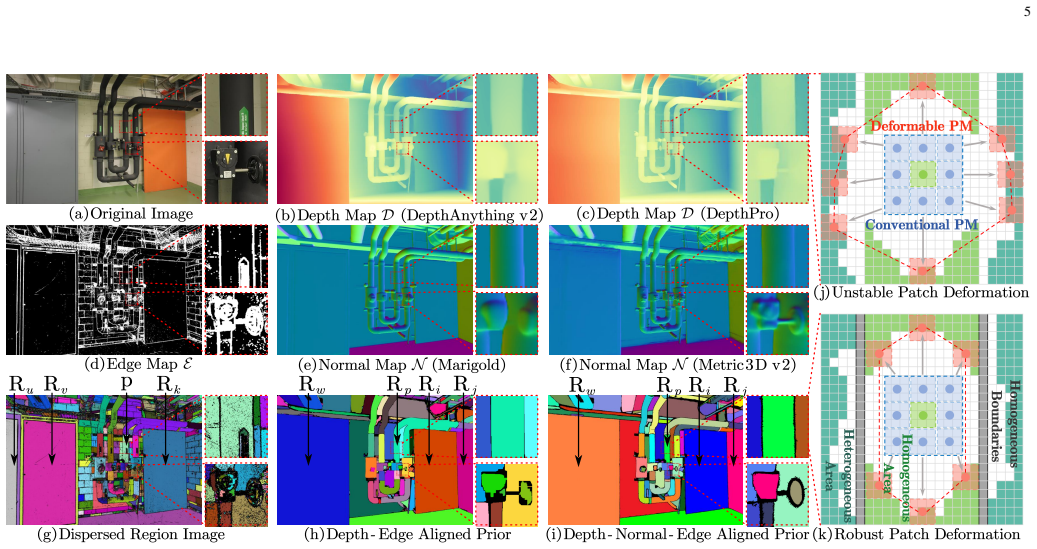
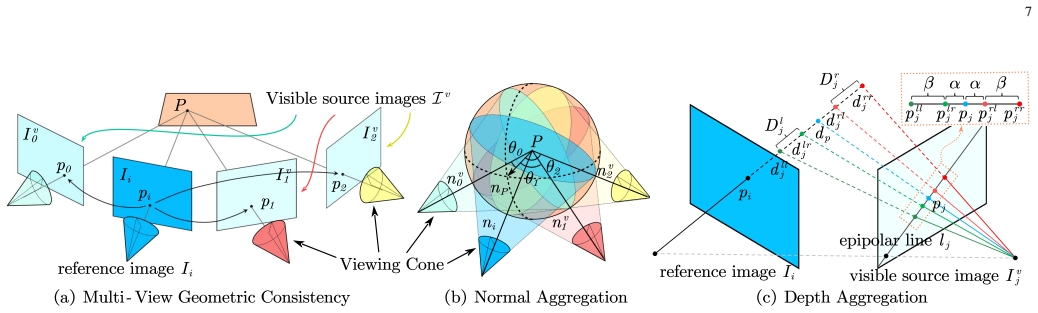
DVP-MVS++ produces coarse depth maps with DepthPro and Metric3Dv2, normal maps, and Roberts edge maps, then aligns these via erosion-dilation to yield fine-grained homogeneous boundaries that support robust patch deformation. View selection weights are recast as visibility maps, and an enhanced cross-view depth reprojection together with an area-maximization strategy supplies harmonized priors that restore visible areas and balance deformed patches. Aggregated normals from view selection and projection depth differences along epipolar lines establish geometry consistency, while SHIQ performs highlight correction to add highlight-aware perception during propagation and refinement.
What carries the argument
Depth-normal-edge alignment through erosion-dilation combined with reformulated visibility maps that drive cross-view depth reprojection and area maximization for visibility-aware patch deformation.
Load-bearing premise
Coarse depth maps from DepthPro and Metric3Dv2 together with Roberts edges, once aligned by erosion-dilation, produce fine-grained homogeneous boundaries that reliably prevent edge-skipping during patch deformation.
What would settle it
Re-running the method on the ETH3D or Tanks & Temples test sets and finding that edge-skipping artifacts remain visible in the output meshes or that accuracy in occluded regions does not exceed prior patch-deformation baselines would indicate the alignment and visibility steps are not delivering the claimed stability.
Figures






read the original abstract
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DVP-MVS++, a patch-deformation MVS pipeline that first generates coarse depth/normal maps with DepthPro and Metric3Dv2 plus Roberts edges, aligns them via erosion-dilation to create homogeneous boundaries, reformulates view-selection weights as visibility maps, applies enhanced cross-view depth reprojection and area-maximization for harmonized priors, and uses aggregated normals, epipolar depth differences, and SHIQ highlight correction to enforce geometry consistency. The central claim is that these steps together prevent edge-skipping and visibility failures, yielding state-of-the-art results on ETH3D, Tanks & Temples, and Strecha.
Significance. If the alignment and visibility mechanisms prove reliable, the approach could strengthen patch-based MVS in textureless and occluded regions by composing existing monocular estimators with lightweight morphological and reprojection steps.
major comments (1)
- [Abstract and §3.1] Abstract and §3.1 (depth-normal-edge alignment): the claim that erosion-dilation of off-the-shelf DepthPro/Metric3Dv2 depths with Roberts edges produces fine-grained homogeneous boundaries that reliably block edge-skipping during patch deformation is load-bearing for the entire contribution. Because the depth estimators are applied without dataset-specific fine-tuning, systematic biases (over-smoothing in low-texture areas, scale drift) can persist; simple morphological operations cannot correct residual misalignments, leaving patches free to cross true discontinuities. This assumption requires explicit validation (e.g., boundary-error metrics or ablation removing the alignment step) before the robustness claim can be accepted.
minor comments (1)
- [Abstract] The abstract states that geometry consistency is obtained via “aggregated normals via view selection and projection depth differences via epipolar lines,” yet the precise aggregation rule and how these terms are weighted inside the propagation/refinement stage are not specified.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comment below and have revised the manuscript to incorporate additional explicit validation of the depth-normal-edge alignment.
read point-by-point responses
-
Referee: [Abstract and §3.1] Abstract and §3.1 (depth-normal-edge alignment): the claim that erosion-dilation of off-the-shelf DepthPro/Metric3Dv2 depths with Roberts edges produces fine-grained homogeneous boundaries that reliably block edge-skipping during patch deformation is load-bearing for the entire contribution. Because the depth estimators are applied without dataset-specific fine-tuning, systematic biases (over-smoothing in low-texture areas, scale drift) can persist; simple morphological operations cannot correct residual misalignments, leaving patches free to cross true discontinuities. This assumption requires explicit validation (e.g., boundary-error metrics or ablation removing the alignment step) before the robustness claim can be accepted.
Authors: We acknowledge that off-the-shelf monocular estimators can exhibit biases and that morphological operations have limits. However, the erosion-dilation is applied specifically to the Roberts edge maps to enforce boundary homogeneity for patch deformation, which is a lightweight post-processing step rather than a full correction of the depth field. In the revised manuscript we have added (i) an ablation that disables the alignment step and reports the resulting increase in edge-skipping artifacts and reconstruction error on ETH3D and Tanks & Temples, and (ii) quantitative boundary-error metrics (mean boundary displacement and F-score at 1-pixel threshold) computed against available ground-truth depth on a held-out subset of ETH3D. These new results show measurable improvement attributable to the alignment and are presented in Section 4.3 and the supplementary material. revision: yes
Circularity Check
No significant circularity; method composes external tools with independent alignment steps
full rationale
The paper's derivation describes a pipeline that applies off-the-shelf models (DepthPro, Metric3Dv2, Roberts operator, SHIQ) followed by proposed erosion-dilation alignment and reformulated visibility priors. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce outputs to inputs by construction. The central claims rest on the composition and new strategies rather than tautological definitions, with results validated on independent external datasets (ETH3D, Tanks & Temples, Strecha). This is self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coarse depth and normal maps from DepthPro and Metric3Dv2 plus Roberts edges can be aligned via erosion-dilation to yield fine-grained homogeneous boundaries suitable for patch deformation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Noise-Transfer2Clean: denoising cryo-EM images based on noise modeling and transfer,
H. Li, H. Zhang, X. Wan, Z. Yang, C. Li, J. Li, R. Han, P. Zhu, and F. Zhang, “Noise-Transfer2Clean: denoising cryo-EM images based on noise modeling and transfer,” Bioinformatics, vol. 38, no. 7, pp. 2022– 2029, 02 2022
work page 2022
-
[2]
Self- supervised noise modeling and sparsity guided electron tomography volumetric image denoising,
Z. Yang, D. Zang, H. Li, Z. Zhang, F. Zhang, and R. Han, “Self- supervised noise modeling and sparsity guided electron tomography volumetric image denoising,” Ultramicroscopy, vol. 255, p. 113860, 2024
work page 2024
-
[3]
Z. Yang, F. Zhang, and R. Han, “Self-supervised cryo-electron tomogra- phy volumetric image restoration from single noisy volume with sparsity constraint,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , October 2021, pp. 4056–4065
work page 2021
-
[4]
Ehss: An efficient hybrid-supervised symmetric stereo matching network,
D. Zhang, P. Zhi, B. Yong, J.-Q. Wang, Y . Hou, L. Guo, Q. Zhou, and R. Zhou, “Ehss: An efficient hybrid-supervised symmetric stereo matching network,” 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC) , pp. 1044–1051, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:267661311
work page 2023
-
[5]
Mapexpert: Online hd map construction with simple and efficient sparse map element expert,
D. Zhang, D. Chen, P. Zhi, Y . Chen, Z. Yuan, C. Li, Sunjing, R. Zhou, and Q. Zhou, “Mapexpert: Online hd map construction with simple and efficient sparse map element expert,” 2024. [Online]. Available: https://arxiv.org/abs/2412.12704
-
[6]
Xvtp3d: cross-view trajectory prediction using shared 3d queries for autonomous driving,
Z. Song, H. Bi, R. Zhang, T. Mao, and Z. Wang, “Xvtp3d: cross-view trajectory prediction using shared 3d queries for autonomous driving,” arXiv preprint arXiv:2308.08764 , 2023
-
[7]
Mmgdreamer: Mixed-modality graph for geometry-controllable 3d indoor scene generation,
Z. Yang, K. Lu, C. Zhang, J. Qi, H. Jiang, R. Ma, S. Yin, Y . Xu, M. Xing, Z. Xiao et al. , “Mmgdreamer: Mixed-modality graph for geometry-controllable 3d indoor scene generation,” arXiv preprint arXiv:2502.05874, 2025
-
[8]
Audio-driven emotion-aware 3d talking face generation from single image,
C.-S. Qiu, F.-L. Liu, H. Fu, F. Zhang, Y .-P. Cao, Y .-K. Lai, and L. Gao, “Audio-driven emotion-aware 3d talking face generation from single image,” in IEEE International Conference on Multimedia and Expo, ICME 2025. IEEE, 2025
work page 2025
-
[9]
Myportrait: Mor- phable prior-guided personalized portrait generation,
B. Ding, Z. Fan, S. Yang, and S. Xia, “Myportrait: Mor- phable prior-guided personalized portrait generation,” arXiv preprint arXiv:2312.02703, 2023
-
[10]
D2gv: Deformable 2d gaussian splatting for video representation in 400fps,
M. Liu, Q. Yang, M. Zhao, H. Huang, L. Yang, Z. Li, and Y . Xu, “D2gv: Deformable 2d gaussian splatting for video representation in 400fps,” arXiv preprint arXiv:2503.05600 , 2025
-
[11]
Light4gs: Lightweight compact 4d gaussian splatting generation via context model,
M. Liu, Q. Yang, H. Huang, W. Huang, Z. Yuan, Z. Li, and Y . Xu, “Light4gs: Lightweight compact 4d gaussian splatting generation via context model,” arXiv preprint arXiv:2503.13948 , 2025
-
[12]
Haif-gs: Hierarchical and induced flow-guided gaussian splatting for dynamic scene,
J. Chen, Z. Li, Y . Cai, H. Jiang, C. Qian, J. Kang, S. Gao, H. Zhao, T. Mao, and Y . Zhang, “Haif-gs: Hierarchical and induced flow-guided gaussian splatting for dynamic scene,” 2025. [Online]. Available: https://arxiv.org/abs/2506.09518
-
[13]
Stdr: Spatio-temporal decoupling for real-time dynamic scene rendering,
Z. Li, H. Jiang, Y . Cai, J. Chen, B. Bi, S. Gao, H. Zhao, Y . Wang, T. Mao, and Z. Wang, “Stdr: Spatio-temporal decoupling for real-time dynamic scene rendering,” 2025. [Online]. Available: https://arxiv.org/abs/2505.22400
-
[14]
Gradiseg: Gradient-guided gaussian segmentation with enhanced 3d boundary precision,
Z. Li, W. Han, Y . Cai, H. Jiang, B. Bi, S. Gao, H. Zhao, and Z. Wang, “Gradiseg: Gradient-guided gaussian segmentation with enhanced 3d boundary precision,” 2024. [Online]. Available: https://arxiv.org/abs/2412.00392
-
[15]
Learning multi-view stereo with geometry-aware prior,
K. Chen, Z. Yuan, H. Xiao, T. Mao, and Z. Wang, “Learning multi-view stereo with geometry-aware prior,” publisher: IEEE
-
[16]
A multi-view stereo benchmark with high- resolution images and multi-camera videos,
T. Schops, J. L. Schonberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger, “A multi-view stereo benchmark with high- resolution images and multi-camera videos,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , July 2017
work page 2017
-
[17]
Tanks and temples: Benchmarking large-scale scene reconstruction,
A. Knapitsch, J. Park, Q.-Y . Zhou, and V . Koltun, “Tanks and temples: Benchmarking large-scale scene reconstruction,” 2017. 13
work page 2017
-
[18]
On benchmarking camera calibration and multi-view stereo for high resolution imagery,
C. Strecha, W. von Hansen, L. Van Gool, P. Fua, and U. Thoennessen, “On benchmarking camera calibration and multi-view stereo for high resolution imagery,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2008, pp. 1–8
work page 2008
-
[19]
Blendedmvs: A large-scale dataset for generalized multi-view stereo networks,
Y . Yao, Z. Luo, S. Li, J. Zhang, Y . Ren, L. Zhou, T. Fang, and L. Quan, “Blendedmvs: A large-scale dataset for generalized multi-view stereo networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020, pp. 1790–1799
work page 2020
-
[20]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,
L. Ling, Y . Sheng, Z. Tu, W. Zhao, C. Xin, K. Wan, L. Yu, Q. Guo, Z. Yu, and Y . Lu, “Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024, pp. 22 160–22 169
work page 2024
-
[21]
Dual-level precision edges guided multi-view stereo with accurate planarization,
K. Chen, Z. Yuan, T. Mao, and Z. Wang, “Dual-level precision edges guided multi-view stereo with accurate planarization,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 39, pp. 2105–2113
-
[22]
NeRF-based polarimetric multi-view stereo,
J. Cao, Z. Yuan, T. Mao, Z. Wang, and Z. Li, “NeRF-based polarimetric multi-view stereo,” vol. 158, p. 111036, publisher: Elsevier
-
[23]
T. Shen, S. Liu, J. Feng, Z. Ma, and N. An, “Topology-aware 3d gaussian splatting: Leveraging persistent homology for optimized struc- tural integrity,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 6823–6832
work page 2025
-
[24]
Di-mvs: learning efficient multi- view stereo with depth-aware iterations,
J. Jiang, M. Cao, J. Yi, and C. Li, “Di-mvs: learning efficient multi- view stereo with depth-aware iterations,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 3180–3184
work page 2024
-
[25]
Rrt-mvs: Recurrent regularization transformer for multi-view stereo,
J. Jiang, L. Wang, H. Yu, T. Hu, J. Chen, and H. Ma, “Rrt-mvs: Recurrent regularization transformer for multi-view stereo,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 39, no. 4, 2025, pp. 3994–4002
work page 2025
-
[26]
Patch- match: A randomized correspondence algorithm for structural image editing,
C. Barnes, E. Shechtman, A. Finkelstein, and D. B. Goldman, “Patch- match: A randomized correspondence algorithm for structural image editing,” ACM Trans. Graph., p. 24, 2009
work page 2009
-
[27]
Z. Yuan, Z. Yang, Y . Cai, K. Wu, M. Liu, D. Zhang, H. Jiang, Z. Li, and Z. Wang, “SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint,” Mar. 2025
work page 2025
-
[28]
MSP-MVS: Multi-Granularity Segmentation Prior Guided Multi-View Stereo,
Z. Yuan, C. Liu, F. Shen, Z. Li, J. Luo, T. Mao, and Z. Wang, “MSP-MVS: Multi-Granularity Segmentation Prior Guided Multi-View Stereo,” Dec. 2024
work page 2024
-
[29]
Z. Yuan, J. Cao, Z. Li, H. Jiang, and Z. Wang, “SD-MVS: segmentation- driven deformation multi-view stereo with spherical refinement and EM optimization,” CoRR, vol. abs/2401.06385, 2024
-
[30]
Tsar-mvs: Textureless-aware segmentation and correlative refinement guided multi-view stereo,
Z. Yuan, J. Cao, Z. Wang, and Z. Li, “Tsar-mvs: Textureless-aware segmentation and correlative refinement guided multi-view stereo,” Pattern Recognition, p. 110565, 2024
work page 2024
-
[31]
Multi-Scale Geometric Consistency Guided and Planar Prior Assisted Multi-View Stereo,
Q. Xu, W. Kong, W. Tao, and M. Pollefeys, “Multi-Scale Geometric Consistency Guided and Planar Prior Assisted Multi-View Stereo,”IEEE Trans. Pattern Anal. Mach. Intell. , pp. 1–18, 2022
work page 2022
-
[32]
Hierarchical prior mining for non-local multi-view stereo,
C. Ren, Q. Xu, S. Zhang, and J. Yang, “Hierarchical prior mining for non-local multi-view stereo,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2023, pp. 3611–3620
work page 2023
-
[33]
Phi-mvs: Plane hypothesis inference multi-view stereo for large-scale scene reconstruction,
S. Sun, Y . Zheng, X. Shi, Z. Xu, and Y . Liu, “Phi-mvs: Plane hypothesis inference multi-view stereo for large-scale scene reconstruction,” arXiv preprint arXiv:2104.06165, 2021
-
[34]
Adaptive patch deformation for textureless-resilient multi- view stereo,
Y . Wang, Z. Zeng, T. Guan, W. Yang, Z. Chen, W. Liu, L. Xu, and Y . Luo, “Adaptive patch deformation for textureless-resilient multi- view stereo,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 1621–1630
work page 2023
-
[35]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth Anything V2,” Jun. 2024
work page 2024
-
[36]
M. Hu, W. Yin, C. Zhang, Z. Cai, X. Long, H. Chen, K. Wang, G. Yu, C. Shen, and S. Shen, “Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[37]
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo,
Z. Yuan, J. Luo, F. Shen, Z. Li, C. Liu, T. Mao, and Z. Wang, “DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo,” Dec. 2024
work page 2024
-
[38]
Patchmatch stereo - stereo matching with slanted support windows,
M. Bleyer, C. Rhemann, and C. Rother, “Patchmatch stereo - stereo matching with slanted support windows,” in British Mach. Vis. Conf. (BMVC), J. Hoey, S. J. McKenna, and E. Trucco, Eds., September 2011, pp. 1–11
work page 2011
-
[39]
Massively parallel multiview stereopsis by surface normal diffusion,
S. Galliani, K. Lasinger, and K. Schindler, “Massively parallel multiview stereopsis by surface normal diffusion,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV) , December 2015
work page 2015
-
[40]
Multi-scale geometric consistency guided multi- view stereo,
Q. Xu and W. Tao, “Multi-scale geometric consistency guided multi- view stereo,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June 2019
work page 2019
-
[41]
Mesh-guided multi-view stereo with pyramid architecture,
Y . Wang, T. Guan, Z. Chen, Y . Luo, K. Luo, and L. Ju, “Mesh-guided multi-view stereo with pyramid architecture,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , June 2020, pp. 2036–2045
work page 2020
-
[42]
Pyramid Multi-View Stereo with Local Consistency,
J. Liao, Y . Fu, Q. Yan, and C. Xiao, “Pyramid Multi-View Stereo with Local Consistency,” Computer Graphics Forum, vol. 38, no. 7, pp. 335– 346, Oct. 2019
work page 2019
-
[43]
Adaptive pixelwise inference multi-view stereo,
S. Sun, J. Liu, Y . Li, H. Ying, Z. Zhai, and Y . Mou, “Adaptive pixelwise inference multi-view stereo,” in Thirteenth International Conference on Graphics and Image Processing (ICGIP 2021), D. Xu and L. Xiao, Eds. Kunming, China: SPIE, Feb. 2022, p. 77
work page 2021
-
[44]
mmfas: Multimodal face anti-spoofing using multi-level alignment and switch-attention fusion,
G. Chen, W. Xie, D. Lin, Y . Liu, and M. Wang, “mmfas: Multimodal face anti-spoofing using multi-level alignment and switch-attention fusion,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 1, 2025, pp. 58–66
work page 2025
-
[45]
Adaptive label correction for robust medical image segmentation with noisy labels,
C. Qian, K. Han, S. Ma, C. Lyu, Z. Yuan, J. Chen, and Z. Liu, “Adaptive label correction for robust medical image segmentation with noisy labels,” arXiv preprint arXiv:2503.12218 , 2025
-
[46]
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
C. Qian, S. Xing, S. Li, Y . Zhao, and Z. Tu, “Decalign: Hierarchical cross-modal alignment for decoupled multimodal representation learn- ing,” arXiv preprint arXiv:2503.11892 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
arXiv preprint arXiv:2503.06456 (2025)
C. Qian, K. Han, J. Wang, Z. Yuan, C. Lyu, J. Chen, and Z. Liu, “Dyncim: Dynamic curriculum for imbalanced multimodal learning,” arXiv preprint arXiv:2503.06456 , 2025
-
[48]
Tokenunify: Scalable autoregressive visual pre-training with mixture token prediction,
Y . Chen, H. Shi*, X. Liu, T. Shi, R. Zhang, D. Liu, Z. Xiong, and F. Wu, “Tokenunify: Scalable autoregressive visual pre-training with mixture token prediction,” arXiv preprint arXiv:2405.16847 , 2024
-
[49]
Text2reaction: Enabling reactive task planning using large language models,
Z. Yang, L. Ning, H. Wang, T. Jiang, S. Zhang, S. Cui, H. Jiang, C. Li, S. Wang, and Z. Wang, “Text2reaction: Enabling reactive task planning using large language models,” IEEE Robotics and Automation Letters , 2024
work page 2024
-
[50]
Hierarchical subgoal generation from language instruction for robot task planning,
Z. Yang, L. Ning, H. Jiang, and Z. Wang, “Hierarchical subgoal generation from language instruction for robot task planning,” in 2022 China Automation Congress (CAC) . IEEE, 2022, pp. 5976–5980
work page 2022
-
[51]
MR-IntelliAssist: A world cognition agent enabling adaptive human-AI symbiosis in industry 4.0,
C. Liu, Z. Yuan, Y . Wang, Y . Yin, W. Luo, Z. He, and X. Liang, “MR-IntelliAssist: A world cognition agent enabling adaptive human-AI symbiosis in industry 4.0,” in Artificial Intelligence in HCI , H. Degen and S. Ntoa, Eds. Springer Nature Switzerland, vol. 15822, pp. 163– 177
-
[52]
Self-supervised neuron segmentation with multi-agent reinforcement learning,
Y . Chen, W. Huang, S. Zhou, Q. Chen, and Z. Xiong, “Self-supervised neuron segmentation with multi-agent reinforcement learning,” in IJCAI 23, 2023
work page 2023
-
[53]
Mask- factory: Towards high-quality synthetic data generation for dichotomous image segmentation,
H. Qian*, Y . Chen*, S. Lou, F. S. Khan, X. Jin, and D.-P. Fan, “Mask- factory: Towards high-quality synthetic data generation for dichotomous image segmentation,” NeurIPS 24, 2024
work page 2024
-
[54]
Generative text-guided 3d vision-language pretraining for unified medical image segmentation,
Y . Chen, C. Liu*, W. Huang, X. Liu, S. Cheng, R. Arcucci, and Z. Xiong, “Generative text-guided 3d vision-language pretraining for unified medical image segmentation,” arXiv preprint arXiv:2306.04811, 2023
-
[55]
Structure-adaptive multi-view graph clustering for remote sensing data,
R. Guan, W. Tu, S. Wang, J. Liu, D. Hu, C. Tang, Y . Feng, J. Li, B. Xiao, and X. Liu, “Structure-adaptive multi-view graph clustering for remote sensing data,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 16 933–16 941
work page 2025
-
[56]
R. Guan, Z. Li, W. Tu, J. Wang, Y . Liu, X. Li, C. Tang, and R. Feng, “Contrastive multiview subspace clustering of hyperspectral images based on graph convolutional networks,” IEEE Transactions on Geoscience and Remote Sensing , vol. 62, pp. 1–14, 2024
work page 2024
-
[57]
Spatial-spectral graph contrastive clustering with hard sample mining for hyperspectral images,
R. Guan, W. Tu, Z. Li, H. Yu, D. Hu, Y . Chen, C. Tang, Q. Yuan, and X. Liu, “Spatial-spectral graph contrastive clustering with hard sample mining for hyperspectral images,”IEEE Transactions on Geoscience and Remote Sensing, pp. 1–16, 2024
work page 2024
-
[58]
Program: Prototype graph model based pseudo-label learning for test-time adaptation,
H. Sun, L. Xu, S. Jin, P. Luo, C. Qian, and W. Liu, “Program: Prototype graph model based pseudo-label learning for test-time adaptation,” in The Twelfth International Conference on Learning Representations
-
[59]
Unsupervised continual domain shift learning with multi- prototype modeling,
H. Sun, Y . Zhang, L. Xu, S. Jin, P. Luo, C. Qian, W. Liu, and Y . Chen, “Unsupervised continual domain shift learning with multi- prototype modeling,” in Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , June 2025, pp. 10 131–10 141
work page 2025
-
[60]
C. Liu, K. Chen, R. Zhao, Z. Zou, and Z. Shi, “Text2earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model,” IEEE Geoscience and Remote Sensing Mag- azine, pp. 2–23, 2025
work page 2025
-
[61]
Rscama: Remote sensing image change captioning with state space model,
C. Liu, K. Chen, B. Chen, H. Zhang, Z. Zou, and Z. Shi, “Rscama: Remote sensing image change captioning with state space model,” IEEE Geoscience and Remote Sensing Letters , vol. 21, pp. 1–5, 2024. 14
work page 2024
-
[62]
Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,” IEEE Transactions on Geoscience and Remote Sensing , vol. 62, pp. 1–16, 2024
work page 2024
-
[63]
C. Liu, R. Zhao, H. Chen, Z. Zou, and Z. Shi, “Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–20, 2022
work page 2022
-
[64]
Remote sensing spatio-temporal vision-language models: A comprehensive survey,
C. Liu, J. Zhang, K. Chen, M. Wang, Z. Zou, and Z. Shi, “Remote sensing spatio-temporal vision-language models: A comprehensive survey,” 2025. [Online]. Available: https://arxiv.org/abs/2412.02573
-
[65]
Mvsnet: Depth inference for unstructured multi-view stereo,
Y . Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “Mvsnet: Depth inference for unstructured multi-view stereo,” in Proc. Eur. Conf. Comput. Vis. (ECCV), September 2018
work page 2018
-
[66]
Recurrent mvsnet for high-resolution multi-view stereo depth inference,
Y . Yao, Z. Luo, S. Li, T. Shen, T. Fang, and L. Quan, “Recurrent mvsnet for high-resolution multi-view stereo depth inference,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5525–5534
work page 2019
-
[67]
Itermvs: Itera- tive probability estimation for efficient multi-view stereo,
F. Wang, S. Galliani, C. V ogel, and M. Pollefeys, “Itermvs: Itera- tive probability estimation for efficient multi-view stereo,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , 2022, pp. 8606–8615
work page 2022
-
[68]
Cost volume pyramid based depth inference for multi-view stereo,
J. Yang, W. Mao, J. M. Alvarez, and M. Liu, “Cost volume pyramid based depth inference for multi-view stereo,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , 2020, pp. 4876–4885
work page 2020
-
[69]
Patch- matchnet: Learned multi-view patchmatch stereo,
F. Wang, S. Galliani, C. V ogel, P. Speciale, and M. Pollefeys, “Patch- matchnet: Learned multi-view patchmatch stereo,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 14 194–14 203
work page 2021
-
[70]
MVSTER: Epipolar transformer for efficient multi-view stereo,
X. Wang, Z. Zhu, G. Huang, F. Qin, Y . Ye, Y . He, X. Chi, and X. Wang, “MVSTER: Epipolar transformer for efficient multi-view stereo,” in European Conference on Computer Vision . Springer, 2022, pp. 573– 591
work page 2022
-
[71]
Epp-mvsnet: Epipolar-assembling based depth prediction for multi-view stereo,
X. Ma, Y . Gong, Q. Wang, J. Huang, L. Chen, and F. Yu, “Epp-mvsnet: Epipolar-assembling based depth prediction for multi-view stereo,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV) , 2021, pp. 5712–5720
work page 2021
-
[72]
GeoMVSNet: Learning Multi-View Stereo With Geometry Perception,
Z. Zhang, R. Peng, Y . Hu, and R. Wang, “GeoMVSNet: Learning Multi-View Stereo With Geometry Perception,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 21 508–21 518
work page 2023
-
[73]
Multi-View Stereo Representation Revist: Region-Aware MVSNet,
Y . Zhang, J. Zhu, and L. Lin, “Multi-View Stereo Representation Revist: Region-Aware MVSNet,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 17 376–17 385
work page 2023
-
[74]
Pixelwise view selection for unstructured multi-view stereo,
J. L. Sch ¨onberger, E. Zheng, J.-M. Frahm, and M. Pollefeys, “Pixelwise view selection for unstructured multi-view stereo,” in Proc. Eur. Conf. Comput. Vis. (ECCV) , 2016, pp. 501–518
work page 2016
-
[75]
Accurate multiple view 3d reconstruction using patch-based stereo for large-scale scenes,
S. Shen, “Accurate multiple view 3d reconstruction using patch-based stereo for large-scale scenes,”IEEE Trans. Image Process., vol. 22, no. 5, pp. 1901–1914, 2013
work page 1901
-
[76]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second,
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun, “Depth Pro: Sharp Monocular Metric Depth in Less Than a Second,” Oct. 2024
work page 2024
-
[77]
Repurposing diffusion-based image generators for monoc- ular depth estimation,
B. Ke, A. Obukhov, S. Huang, N. Metzger, R. C. Daudt, and K. Schindler, “Repurposing diffusion-based image generators for monoc- ular depth estimation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, n CVPR 2024, Seattle, WA, USA, June 16-22,
work page 2024
- [78]
-
[79]
Nddepth: Normal- distance assisted monocular depth estimation and completion,
S. Shao, Z. Pei, W. Chen, P. C. Y . Chen, and Z. Li, “Nddepth: Normal- distance assisted monocular depth estimation and completion,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 8883–8899, 2024
work page 2024
-
[80]
Efficient edge-preserving multi-view stereo network for depth estimation,
W. Su and W. Tao, “Efficient edge-preserving multi-view stereo network for depth estimation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, 2023, pp. 2348–2356
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.