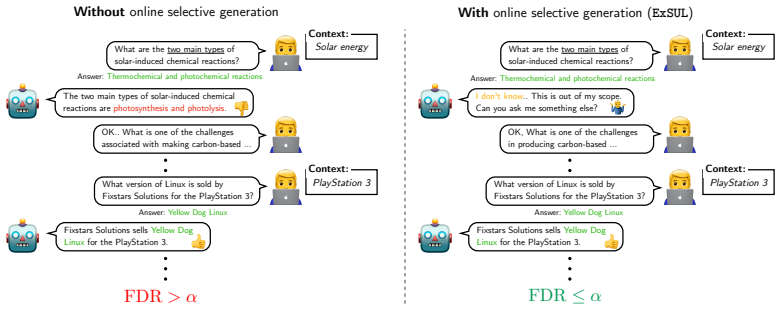
Online Conformal Abstention for Factuality Control Under Adversarial Bandit Feedback
Pith reviewed 2026-05-19 08:51 UTC · model grok-4.3
The pith
ExAUL achieves O(√T) FDR control for conformal abstention under partial adversarial feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ExAUL combines a conversion lemma that maps the regret of any bandit algorithm into a finite-sample FDR bound with a feedback unlocking strategy that exploits the structure of conformal abstention; this produces a regret bound of O(√(T ln |H|)) that implies an O(√T) bound on FDR risk control, matching the controllability of full-information settings even when feedback is restricted to the selected response and the environment is adversarial.
What carries the argument
The conversion lemma that maps the regret of any bandit algorithm directly into a finite-sample FDR bound, together with the feedback unlocking strategy that extracts additional learning signals from partial feedback on the selected response.
If this is right
- Generative models can keep the rate of unreliable answers below a controllable threshold while still answering frequently.
- Large language models on question-answering tasks maintain FDR control in non-stationary and adversarial environments.
- Partial user feedback on the chosen answer is sufficient to reach the same risk level as full evaluation of all responses.
- Answering coverage remains competitive while the FDR stays bounded.
Where Pith is reading between the lines
- The same conversion approach could be adapted to control other risk measures such as false negative rate or expected calibration error.
- Feedback unlocking may extend naturally to multi-turn conversations where later user signals can retroactively inform earlier abstention decisions.
- Real-world deployment on live user platforms could test whether the O(√T) scaling holds when the adversarial model is replaced by actual non-stationary human behavior.
Load-bearing premise
The conversion lemma continues to translate bandit regret into a finite-sample FDR bound when feedback is limited to the selected response and the environment is adversarial.
What would settle it
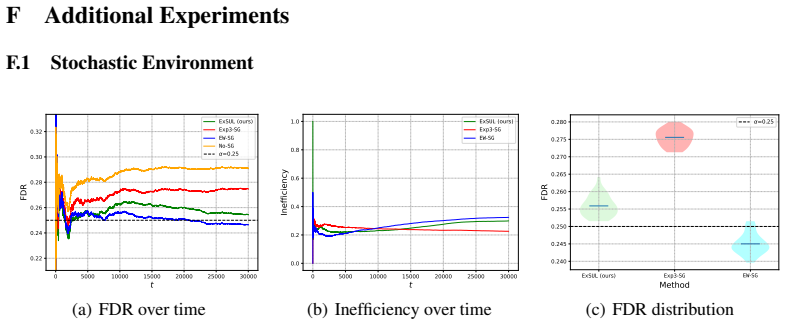
An experiment in which the false discovery rate grows faster than O(√T) while ExAUL runs on an adversarial bandit feedback stream for conformal abstention would disprove the claimed guarantee.
Figures























read the original abstract
As interactive generative systems are increasingly deployed in real-world applications, their tendency to generate unreliable or false responses raises serious concerns. Conformal abstention mitigates this risk by ensuring that the system answers only when confident. However, real-world deployments typically provide only partial user feedback (e.g., thumbs up/down) on the selected response and often operate in non-stationary or adversarial environments, for which effective learning methods are largely missing. To bridge this gap, we propose ExAUL, a novel online learning framework for conformal abstention with adversarial and partial feedback. Technically, we introduce (i) a novel conversion lemma}that translates the regret of any bandit algorithm into an FDR bound, and (ii) feedback unlocking, a strategy that exploits the structure of conformal abstention to extract additional learning signals from partial feedback. We prove that ExAUL achieves a regret bound of $O(\sqrt{T \ln |{H}|})$, which translates into an ${O}(\sqrt{T})$ bound on FDR risk control, matching the controllability of full-information settings despite receiving only partial feedback. While applicable to general generative tasks, we demonstrate the efficacy of ExAUL for ensuring the reliability of Large Language Models (LLMs) through empirical validation on question-answering tasks across diverse non-stationary and adversarial settings. Our results demonstrate that ExAUL robustly controls the FDR while maintaining competitive answering coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExAUL, an online framework for conformal abstention that controls false discovery rate (FDR) in generative models under adversarial bandit feedback. It proposes a conversion lemma mapping the regret of any bandit algorithm to a finite-sample FDR bound and a 'feedback unlocking' technique that extracts extra signals from partial (selected-response) feedback. The central theorem states that ExAUL attains O(√(T ln |H|)) regret, which translates into an O(√T) FDR guarantee, matching full-information rates; the claim is supported by an empirical evaluation on LLM question-answering tasks in non-stationary and adversarial regimes.
Significance. If the conversion lemma is shown to hold without hidden full-information or stationarity assumptions, the result would be significant: it extends conformal prediction to realistic partial-feedback, adversarial online settings while preserving the √T rate that is standard in full-information conformal control. The empirical demonstration across diverse non-stationary environments provides concrete evidence of practical utility for factuality control in LLMs.
major comments (2)
- [§3.2, Lemma 3] §3.2, Lemma 3 (Conversion Lemma): The lemma asserts that any bandit algorithm's regret directly yields an O(√T) FDR bound under partial feedback. The provided derivation does not explicitly construct an unbiased or conservatively biased estimator for the full loss vector when the adversary chooses both the loss vector and the feedback mask adaptively; without this step the translation from regret to FDR is not yet load-bearing for the headline claim.
- [§4.1, Theorem 1] §4.1, Theorem 1: The O(√(T ln |H|)) regret bound is stated to hold for ExAUL. The proof sketch relies on the conversion lemma plus feedback unlocking, yet the interaction between the two components under adaptive adversarial feedback is not fully expanded; this is the sole bridge to the FDR guarantee and therefore requires a self-contained argument.
minor comments (3)
- [Abstract] Notation: the abstract writes |{H}| while the body uses |H|; standardize to |H| throughout.
- [Figure 2] Figure 2 caption: the legend labels 'ExAUL (unlocked)' and 'ExAUL (baseline)' but the text does not define the baseline variant; add a one-sentence clarification.
- [§2] Related work: the discussion of prior online conformal methods omits the recent bandit-conformal line (e.g., works on contextual bandits with abstention); a brief comparison would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, providing clarifications and committing to revisions that strengthen the rigor of the proofs without altering the core claims.
read point-by-point responses
-
Referee: [§3.2, Lemma 3] §3.2, Lemma 3 (Conversion Lemma): The lemma asserts that any bandit algorithm's regret directly yields an O(√T) FDR bound under partial feedback. The provided derivation does not explicitly construct an unbiased or conservatively biased estimator for the full loss vector when the adversary chooses both the loss vector and the feedback mask adaptively; without this step the translation from regret to FDR is not yet load-bearing for the headline claim.
Authors: We thank the referee for highlighting this point. The conversion lemma in the current manuscript relies on the structure of conformal abstention to ensure that the partial feedback (only on the selected response) yields a conservatively biased estimator for the full loss vector. In the revision, we will explicitly construct this estimator: for the selected action we use the observed loss directly (unbiased), and for non-selected actions we use a conservative upper bound derived from the abstention threshold and the fact that the adversary's mask is applied after the action selection. This construction holds under fully adaptive adversarial choices of both losses and masks, without requiring stationarity or hidden full-information assumptions. We will add this step-by-step derivation to Section 3.2 to make the regret-to-FDR translation fully load-bearing. revision: yes
-
Referee: [§4.1, Theorem 1] §4.1, Theorem 1: The O(√(T ln |H|)) regret bound is stated to hold for ExAUL. The proof sketch relies on the conversion lemma plus feedback unlocking, yet the interaction between the two components under adaptive adversarial feedback is not fully expanded; this is the sole bridge to the FDR guarantee and therefore requires a self-contained argument.
Authors: We agree that the interaction between feedback unlocking and the conversion lemma merits a more self-contained argument in the proof of Theorem 1. Feedback unlocking exploits the specific structure of conformal abstention (where the decision to answer or abstain provides an implicit signal even under partial feedback) to extract additional unbiased estimates beyond the bandit observation. In the revised proof, we will first show how unlocking augments the effective feedback to reduce the variance of the loss estimates, then apply the (revised) conversion lemma to translate the resulting O(√(T ln |H|)) regret directly into the O(√T) FDR bound. The argument will be expanded to explicitly track the adaptive adversary's choices at each step, confirming that no additional assumptions are needed. revision: yes
Circularity Check
No significant circularity; derivation reduces to external bandit regret via novel lemma
full rationale
The paper's core result derives an O(√T) FDR bound from the O(√(T ln |H|)) regret of any standard bandit algorithm, using a novel conversion lemma and feedback unlocking to handle partial adversarial feedback. The bandit regret is an external quantity from online learning theory, not fitted or defined within the paper. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided derivation chain; the lemma is explicitly introduced as new and bridges to FDR without assuming full observation by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User feedback is adversarial bandit feedback observed only on the selected response.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce (i) a novel conversion lemma that translates the regret of any bandit algorithm into an FDR bound, and (ii) feedback unlocking... We prove that ExAUL achieves a regret bound of O(√(T ln |H|))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduction of selective generation to bandits... novel Regret-to-FDR conversion lemma
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
OpenAI. GPT-3.5-turbo model card. https://platform.openai.com/docs/models/ gpt-3-5-turbo , 2023
work page 2023
-
[2]
LLaMA 3.1 8B-Instruct model card
Meta AI. LLaMA 3.1 8B-Instruct model card. https://huggingface.co/meta-llama/ Llama-3.1-8B-Instruct , 2024
work page 2024
-
[3]
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks.Advances in neural information processing systems, 30, 2017
work page 2017
-
[4]
Hierarchical selective classification
Shani Goren, Ido Galil, and Ran El-Yaniv. Hierarchical selective classification. arXiv preprint arXiv:2405.11533, 2024
-
[5]
Learning to reject with a fixed predictor: Application to decontextualization
Christopher Mohri, Daniel Andor, Eunsol Choi, and Michael Collins. Learning to reject with a fixed predictor: Application to decontextualization. arXiv preprint arXiv:2301.09044, 2023
-
[6]
Selective generation for con- trollable language models
Minjae Lee, Kyungmin Kim, Taesoo Kim, and Sangdon Park. Selective generation for con- trollable language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[7]
The nonstochastic multiarmed bandit problem
Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. The nonstochastic multiarmed bandit problem. SIAM journal on computing, 32(1):48–77, 2002
work page 2002
-
[8]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 1601–1611, Vancouver, Canada, July 2017. Association for Computational Linguistics
work page 2017
-
[9]
Natural questions: a benchmark for question answering research
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019
work page 2019
-
[10]
Prediction, learning, and games
Nicolo Cesa-Bianchi and Gábor Lugosi. Prediction, learning, and games. Cambridge university press, 2006
work page 2006
-
[11]
Foundations of machine learning
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2012
work page 2012
-
[12]
Semi-bandit feedback: A survey of results
Karthik Abinav Sankararaman. Semi-bandit feedback: A survey of results. ARXIV CoRR, 2016
work page 2016
-
[13]
Dylan J. Foster and Alexander Rakhlin. Foundations of reinforcement learning and interactive decision making, 2023
work page 2023
-
[14]
The weighted majority algorithm
Nick Littlestone and Manfred K Warmuth. The weighted majority algorithm. Information and computation, 108(2):212–261, 1994
work page 1994
-
[15]
Sample mean based index policies by o (log n) regret for the multi-armed bandit problem
Rajeev Agrawal. Sample mean based index policies by o (log n) regret for the multi-armed bandit problem. Advances in applied probability, 27(4):1054–1078, 1995
work page 1995
-
[16]
Eluder dimension and the sample complexity of optimistic exploration
Daniel Russo and Benjamin Van Roy. Eluder dimension and the sample complexity of optimistic exploration. Advances in Neural Information Processing Systems, 26, 2013. 11
work page 2013
-
[17]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[18]
A large annotated corpus for learning natural language inference
Samuel Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, 2015
work page 2015
-
[19]
Mehrdad Mahdavi, Rong Jin, and Tianbao Yang. Trading regret for efficiency: online convex optimization with long term constraints.The Journal of Machine Learning Research, 13(1):2503– 2528, 2012
work page 2012
-
[20]
An online convex optimization approach to proactive network resource allocation
Tianyi Chen, Qing Ling, and Georgios B Giannakis. An online convex optimization approach to proactive network resource allocation. IEEE Transactions on Signal Processing, 65(24):6350– 6364, 2017
work page 2017
-
[21]
Exponentially weighted algorithm for online network resource allocation with long-term constraints
Ahmed Sid-Ali, Ioannis Lambadaris, Yiqiang Q Zhao, Gennady Shaikhet, and Amirhossein Asgharnia. Exponentially weighted algorithm for online network resource allocation with long-term constraints. arXiv preprint arXiv:2405.02373, 2024
-
[22]
Optimal algorithms for online convex optimization with adversarial constraints
Abhishek Sinha and Rahul Vaze. Optimal algorithms for online convex optimization with adversarial constraints. Advances in Neural Information Processing Systems, 37:41274–41302, 2024
work page 2024
-
[23]
Stochastic online conformal prediction with semi-bandit feedback
Haosen Ge, Hamsa Bastani, and Osbert Bastani. Stochastic online conformal prediction with semi-bandit feedback. arXiv preprint arXiv:2405.13268, 2024
-
[24]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
When you are done with the current context, say ’SHIFT’ to request a new context
Harrison Chase. LangChain, October 2022. 12 A Additional Related Work Constrained Online Learning Several works have studied online learning with constraints. [19] first proposes long-term constraints in online convex optimization with time-invariant constraints, which allows to have the constraint function gt to be violated at each time step, i.e., g(xt)...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.