Focusing Influence Mechanism for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-19 07:14 UTC · model grok-4.3
The pith
A focusing influence mechanism helps multi-agent systems explore sparse-reward environments more effectively by directing attention to under-explored state space regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Focusing Influence Mechanism encourages agents to direct their influence toward under-explored parts of the state space using an entropy criterion, and employs eligibility traces to allow multiple agents to sustain and align their influence on the same regions, thereby enabling coordinated exploration even when rewards are extremely sparse.
What carries the argument
The Focusing Influence Mechanism (FIM), which combines an entropy-based criterion for identifying under-explored states with eligibility traces for persistent alignment among agents.
Load-bearing premise
An entropy-based criterion combined with eligibility traces will successfully encourage agents to focus and sustain influence on the same under-explored state space parts in a way that improves coordination without negative side effects or heavy environment-specific adjustments.
What would settle it
Running the same MARL benchmarks with the entropy criterion or eligibility traces removed and observing whether performance gains disappear while other components remain unchanged.
Figures














read the original abstract
Cooperative multi-agent reinforcement learning (MARL) under sparse rewards remains fundamentally challenging because agents often fail to concentrate their influence, leading to insufficiently coordinated exploration. To address this, we propose the Focusing Influence Mechanism (FIM), a framework that encourages agents to focus their influence on under-explored parts of the state space through an entropy-based criterion, while leveraging eligibility traces to enable multiple agents to consistently align and sustain their influence on the same parts of the state space when beneficial, thereby promoting coordinated and persistent joint behavior. By emphasizing under-explored regions of the state space, FIM facilitates more efficient and structured exploration even under extremely sparse rewards. Across diverse MARL benchmarks, FIM consistently improves cooperative performance over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Focusing Influence Mechanism (FIM) for cooperative multi-agent reinforcement learning under sparse rewards. FIM uses an entropy-based criterion to direct agents toward under-explored regions of the joint state space and eligibility traces to sustain aligned influence across agents on those regions, with the goal of enabling more structured and persistent coordinated exploration. The central claim is that this yields consistent performance gains over strong baselines on diverse MARL benchmarks.
Significance. If the empirical claims are substantiated with rigorous evidence, FIM could provide a practical addition to the MARL toolkit for sparse-reward settings by repurposing entropy and eligibility traces to promote joint focus without introducing many new hyperparameters. The approach is grounded in standard RL primitives, which is a strength if it produces reproducible gains across environments.
major comments (2)
- Abstract and §4 (Experiments): the assertion of 'consistent improvements over strong baselines' is presented without any reported statistical tests, variance across seeds, ablation results, or environment-specific implementation details. This leaves the central performance claim unsupported by the information provided.
- §3 (FIM description): the entropy criterion is stated to flag under-explored joint regions and eligibility traces are said to enable sustained multi-agent alignment, yet no analysis is given of how these components behave under function approximation in high-dimensional, non-stationary joint state spaces. The skeptic concern that noisy entropy estimates and changing policies could break reliable coordination is not addressed with a concrete test or counter-example.
minor comments (1)
- Notation for the entropy term and trace decay parameter should be introduced with explicit equations and distinguished from standard single-agent usage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the empirical support and analysis.
read point-by-point responses
-
Referee: Abstract and §4 (Experiments): the assertion of 'consistent improvements over strong baselines' is presented without any reported statistical tests, variance across seeds, ablation results, or environment-specific implementation details. This leaves the central performance claim unsupported by the information provided.
Authors: We agree that the performance claims require stronger statistical backing. In the revised version, we will report mean returns with standard deviations across multiple random seeds (at least five per environment), include pairwise statistical significance tests (e.g., Welch’s t-test with p-values), add ablation studies isolating the entropy criterion and eligibility traces, and expand the implementation details for each benchmark to specify network architectures, hyperparameters, and training protocols. These additions will directly support the central claim. revision: yes
-
Referee: §3 (FIM description): the entropy criterion is stated to flag under-explored joint regions and eligibility traces are said to enable sustained multi-agent alignment, yet no analysis is given of how these components behave under function approximation in high-dimensional, non-stationary joint state spaces. The skeptic concern that noisy entropy estimates and changing policies could break reliable coordination is not addressed with a concrete test or counter-example.
Authors: We acknowledge the value of explicit analysis under function approximation. While the empirical results were obtained with neural-network approximators in high-dimensional environments and show consistent gains, we will insert a new discussion subsection in §3 that examines the effects of noisy entropy estimates and policy non-stationarity on coordination. We will also add a brief sensitivity study and a simple illustrative counter-example in the appendix to address the concern about potential breakdown of alignment. revision: partial
Circularity Check
No circularity; mechanism uses standard RL primitives with external benchmark validation
full rationale
The paper introduces FIM by combining an entropy-based criterion for identifying under-explored state regions with eligibility traces to sustain multi-agent influence alignment. No equations, derivations, or claims in the abstract reduce by construction to fitted parameters, self-definitions, or self-citation chains. Performance improvements are asserted via consistent gains on diverse MARL benchmarks against strong baselines, providing independent empirical grounding outside any internal fitting loop. This satisfies the default expectation of a non-circular proposal.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
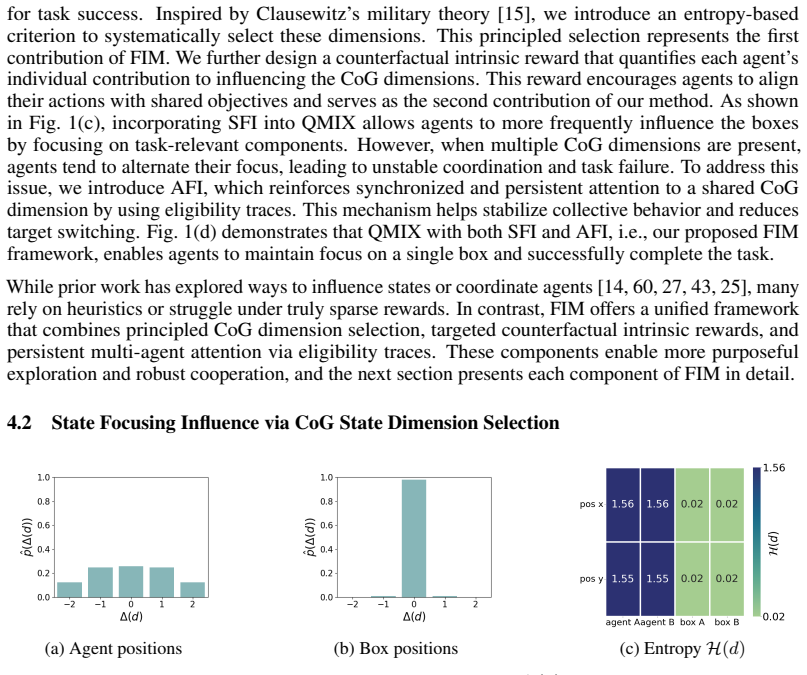
we introduce a state focusing influence (SFI) mechanism that guides agents to increase their impact on such dimensions. ... H(d) = E_ρ [ -log p̂(Δd(st,st+1) | st) ] ... CoG_δ = {d | 0 < H(d) < δ}
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ed_t = λ · ed_{t-1} + η · Inf^d_t ... r_int,t = Σ wd · Inf^d_t · clip(ed_{t-1},1,cmax)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Interaction-Breaking Adversarial Learning Framework for Robust Multi-Agent Reinforcement Learning
The IBAL framework builds information-theoretic attacks that break agent interactions in MARL and trains policies to stay robust under observation and action perturbations.
Reference graph
Works this paper leans on
-
[1]
Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving
Shai Shalev-Shwartz, Shaked Shammah, and Amnon Shashua. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv preprint arXiv:1610.03295, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Multi-agent reinforcement learning for redundant robot control in task-space
Adolfo Perrusquía, Wen Yu, and Xiaoou Li. Multi-agent reinforcement learning for redundant robot control in task-space. International Journal of Machine Learning and Cybernetics, 12: 231–241, 2021
work page 2021
-
[3]
Grandmaster level in starcraft ii using multi-agent reinforcement learning
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. nature, 575(7782):350–354, 2019
work page 2019
-
[4]
A concise introduction to decentralized POMDPs, volume 1
Frans A Oliehoek, Christopher Amato, et al. A concise introduction to decentralized POMDPs, volume 1. Springer, 2016
work page 2016
-
[5]
Optimal and approximate q-value functions for decentralized pomdps
Frans A Oliehoek, Matthijs TJ Spaan, and Nikos Vlassis. Optimal and approximate q-value functions for decentralized pomdps. Journal of Artificial Intelligence Research, 32:289–353, 2008
work page 2008
-
[6]
The surprising effectiveness of ppo in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and YI WU. The surprising effectiveness of ppo in cooperative multi-agent games. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24611–24624. Curran Associates, Inc., 2022
work page 2022
-
[7]
Value- decomposition networks for cooperative multi-agent learning based on team reward
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value- decomposition networks for cooperative multi-agent learning based on team reward. In Pro- ceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems,...
work page 2085
-
[8]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In International Conference on Machine Learning, pages 4295–4304. PMLR, 2018
work page 2018
-
[9]
Qplex: Duplex dueling multi-agent q-learning
Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. Qplex: Duplex dueling multi-agent q-learning. In International Conference on Learning Representations
-
[10]
Social influence as intrinsic motivation for multi-agent deep reinforcement learning
Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro Ortega, DJ Strouse, Joel Z Leibo, and Nando De Freitas. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In International conference on machine learning, pages 3040–3049. PMLR, 2019
work page 2019
-
[11]
Influence-based multi-agent exploration
Tonghan Wang, Jianhao Wang, Yi Wu, and Chongjie Zhang. Influence-based multi-agent exploration. In International Conference on Learning Representations, 2020
work page 2020
-
[12]
Cooperative exploration for multi-agent deep reinforcement learning
Iou-Jen Liu, Unnat Jain, Raymond A Yeh, and Alexander Schwing. Cooperative exploration for multi-agent deep reinforcement learning. In International conference on machine learning, pages 6826–6836. PMLR, 2021
work page 2021
-
[13]
Episodic multi-agent reinforcement learning with curiosity- driven exploration
Lulu Zheng, Jiarui Chen, Jianhao Wang, Jiamin He, Yujing Hu, Yingfeng Chen, Changjie Fan, Yang Gao, and Chongjie Zhang. Episodic multi-agent reinforcement learning with curiosity- driven exploration. Advances in Neural Information Processing Systems, 34:3757–3769, 2021
work page 2021
-
[14]
Celebrating diversity in shared multi-agent reinforcement learning
Chenghao Li, Tonghan Wang, Chengjie Wu, Qianchuan Zhao, Jun Yang, and Chongjie Zhang. Celebrating diversity in shared multi-agent reinforcement learning. Advances in Neural Infor- mation Processing Systems, 34:3991–4002, 2021
work page 2021
-
[15]
Clausewitz’s center of gravity: It’s not what we thought
Antulio J Echevarria. Clausewitz’s center of gravity: It’s not what we thought. Naval War College Review, 56(1):108–123, 2003
work page 2003
-
[16]
Coordinated exploration via intrinsic rewards for multi-agent rein- forcement learning
Shariq Iqbal and Fei Sha. Coordinated exploration via intrinsic rewards for multi-agent rein- forcement learning. arXiv preprint arXiv:1905.12127, 2019. 10
-
[17]
Jiahui Li, Kun Kuang, Baoxiang Wang, Xingchen Li, Fei Wu, Jun Xiao, and Long Chen. Two heads are better than one: A simple exploration framework for efficient multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 36:20038–20053, 2023
work page 2023
-
[18]
Self-motivated multi- agent exploration
Shaowei Zhang, Jiahan Cao, Lei Yuan, Yang Yu, and De-Chuan Zhan. Self-motivated multi- agent exploration. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 476–484, 2023
work page 2023
-
[19]
Kai Yang, Zhirui Fang, Xiu Li, and Jian Tao. Cmbe: Curiosity-driven model-based exploration for multi-agent reinforcement learning in sparse reward settings. In 2024 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2024
work page 2024
-
[20]
Population-based diverse exploration for sparse-reward multi-agent tasks
Pei Xu, Junge Zhang, and Kaiqi Huang. Population-based diverse exploration for sparse-reward multi-agent tasks. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 283–291, 2024
work page 2024
-
[21]
Yucong Zhang and Chao Yu. Expode: Exploiting policy discrepancy for efficient exploration in multi-agent reinforcement learning. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 58–66, 2023
work page 2023
-
[22]
Toward efficient multi-agent exploration with trajectory entropy maximization
Tianxu Li and Kun Zhu. Toward efficient multi-agent exploration with trajectory entropy maximization. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[23]
Learning joint behaviors with large variations
Tianxu Li and Kun Zhu. Learning joint behaviors with large variations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23249–23257, 2025
work page 2025
-
[24]
Maven: Multi-agent variational exploration
Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. Maven: Multi-agent variational exploration. Advances in neural information processing systems, 32, 2019
work page 2019
-
[25]
Fox: Formation-aware exploration in multi-agent reinforcement learning
Yonghyeon Jo, Sunwoo Lee, Junghyuk Yeom, and Seungyul Han. Fox: Formation-aware exploration in multi-agent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 12985–12994, 2024
work page 2024
-
[26]
Hierarchical Deep Multiagent Reinforcement Learning with Temporal Abstraction
Hongyao Tang, Jianye Hao, Tangjie Lv, Yingfeng Chen, Zongzhang Zhang, Hangtian Jia, Chunxu Ren, Yan Zheng, Zhaopeng Meng, Changjie Fan, et al. Hierarchical deep multiagent reinforcement learning with temporal abstraction. arXiv preprint arXiv:1809.09332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Maser: Multi-agent rein- forcement learning with subgoals generated from experience replay buffer
Jeewon Jeon, Woojun Kim, Whiyoung Jung, and Youngchul Sung. Maser: Multi-agent rein- forcement learning with subgoals generated from experience replay buffer. In International conference on machine learning, pages 10041–10052. PMLR, 2022
work page 2022
-
[28]
Subspace-aware exploration for sparse-reward multi-agent tasks
Pei Xu, Junge Zhang, Qiyue Yin, Chao Yu, Yaodong Yang, and Kaiqi Huang. Subspace-aware exploration for sparse-reward multi-agent tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11717–11725, 2023
work page 2023
-
[29]
Xin He, Hongwei Ge, Yaqing Hou, and Jincheng Yu. Saeir: sequentially accumulated entropy intrinsic reward for cooperative multi-agent reinforcement learning with sparse reward. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 4107–4115, 2024
work page 2024
-
[30]
Zixian Ma, Rose Wang, Fei-Fei Li, Michael Bernstein, and Ranjay Krishna. Elign: Expectation alignment as a multi-agent intrinsic reward.Advances in Neural Information Processing Systems, 35:8304–8317, 2022
work page 2022
-
[31]
Pmic: Improving multi-agent reinforcement learning with progressive mutual information collaboration
Pengyi Li, Hongyao Tang, Tianpei Yang, Xiaotian Hao, Tong Sang, Yan Zheng, Jianye Hao, Matthew E Taylor, Wenyuan Tao, and Zhen Wang. Pmic: Improving multi-agent reinforcement learning with progressive mutual information collaboration. In International Conference on Machine Learning, pages 12979–12997. PMLR, 2022
work page 2022
-
[32]
Cooperative multiagent learning and exploration with min–max intrinsic motivation
Yaqing Hou, Jie Kang, Haiyin Piao, Yifeng Zeng, Yew-Soon Ong, Yaochu Jin, and Qiang Zhang. Cooperative multiagent learning and exploration with min–max intrinsic motivation. IEEE Transactions on Cybernetics, 2025. 11
work page 2025
-
[33]
Learning individually inferred communication for multi-agent cooperation
Ziluo Ding, Tiejun Huang, and Zongqing Lu. Learning individually inferred communication for multi-agent cooperation. Advances in neural information processing systems, 33:22069–22079, 2020
work page 2020
-
[34]
Learning with opponent-learning awareness
Jakob Foerster, Richard Y Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems , pages 122–130, 2018
work page 2018
-
[35]
Stable opponent shaping in differentiable games
Alistair Letcher, Jakob Foerster, David Balduzzi, Tim Rocktäschel, and Shimon Whiteson. Stable opponent shaping in differentiable games. In International Conference on Learning Representations, 2019
work page 2019
-
[36]
Learning latent representations to influence multi-agent interaction
Annie Xie, Dylan Losey, Ryan Tolsma, Chelsea Finn, and Dorsa Sadigh. Learning latent representations to influence multi-agent interaction. In Conference on robot learning, pages 575–588. PMLR, 2021
work page 2021
-
[37]
Influencing long-term behavior in multiagent reinforcement learning
Dong-Ki Kim, Matthew Riemer, Miao Liu, Jakob Foerster, Michael Everett, Chuangchuang Sun, Gerald Tesauro, and Jonathan P How. Influencing long-term behavior in multiagent reinforcement learning. Advances in Neural Information Processing Systems, 35:18808–18821, 2022
work page 2022
-
[38]
Zeyang Liu, Lipeng Wan, Xinrui Yang, Zhuoran Chen, Xingyu Chen, and Xuguang Lan. Imagine, initialize, and explore: An effective exploration method in multi-agent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17487–17495, 2024
work page 2024
-
[39]
Settling decentralized multi-agent coordinated exploration by novelty sharing
Haobin Jiang, Ziluo Ding, and Zongqing Lu. Settling decentralized multi-agent coordinated exploration by novelty sharing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17444–17452, 2024
work page 2024
-
[40]
Learning to incentivize other learning agents
Jiachen Yang, Ang Li, Mehrdad Farajtabar, Peter Sunehag, Edward Hughes, and Hongyuan Zha. Learning to incentivize other learning agents. Advances in Neural Information Processing Systems, 33:15208–15219, 2020
work page 2020
-
[41]
Learning to penalize other learning agents
Kyrill Schmid, Lenz Belzner, and Claudia Linnhoff-Popien. Learning to penalize other learning agents. In Artificial Life Conference Proceedings 33, volume 2021, page 59. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info . . . , 2021
work page 2021
-
[42]
Reciprocal reward influence encourages cooperation from self-interested agents
John L Zhou, Weizhe Hong, and Jonathan Kao. Reciprocal reward influence encourages cooperation from self-interested agents. Advances in Neural Information Processing Systems, 37:59491–59512, 2024
work page 2024
-
[43]
Boyin Liu, Zhiqiang Pu, Yi Pan, Jianqiang Yi, Yanyan Liang, and Du Zhang. Lazy agents: A new perspective on solving sparse reward problem in multi-agent reinforcement learning. In International Conference on Machine Learning, pages 21937–21950. PMLR, 2023
work page 2023
-
[44]
Individual contributions as intrinsic explo- ration scaffolds for multi-agent reinforcement learning
Xinran Li, Zifan Liu, Shibo Chen, and Jun Zhang. Individual contributions as intrinsic explo- ration scaffolds for multi-agent reinforcement learning. In International Conference on Machine Learning, pages 28387–28402. PMLR, 2024
work page 2024
-
[45]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[46]
On the use and misuse of absorbing states in multi-agent reinforcement learning
Andrew Cohen, Ervin Teng, Vincent-Pierre Berges, Ruo-Ping Dong, Hunter Henry, Marwan Mattar, Alexander Zook, and Sujoy Ganguly. On the use and misuse of absorbing states in multi-agent reinforcement learning. arXiv preprint arXiv:2111.05992, 2021
-
[47]
Towards un- derstanding cooperative multi-agent q-learning with value factorization
Jianhao Wang, Zhizhou Ren, Beining Han, Jianing Ye, and Chongjie Zhang. Towards un- derstanding cooperative multi-agent q-learning with value factorization. Advances in Neural Information Processing Systems, 34:29142–29155, 2021. 12
work page 2021
-
[48]
Global rewards in multi-agent deep reinforcement learning for autonomous mobility on demand systems
Heiko Hoppe, Tobias Enders, Quentin Cappart, and Maximilian Schiffer. Global rewards in multi-agent deep reinforcement learning for autonomous mobility on demand systems. In 6th Annual Learning for Dynamics & Control Conference, pages 260–272. PMLR, 2024
work page 2024
-
[49]
Hanhan Zhou, Tian Lan, and Vaneet Aggarwal. Pac: Assisted value factorization with coun- terfactual predictions in multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 35:15757–15769, 2022
work page 2022
-
[50]
Aligning credit for multi-agent co- operation via model-based counterfactual imagination
Jiajun Chai, Yuqian Fu, Dongbin Zhao, and Yuanheng Zhu. Aligning credit for multi-agent co- operation via model-based counterfactual imagination. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 281–289, 2024
work page 2024
-
[51]
Shapley q-value: A local reward approach to solve global reward games
Jianhong Wang, Yuan Zhang, Tae-Kyun Kim, and Yunjie Gu. Shapley q-value: A local reward approach to solve global reward games. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7285–7292, 2020
work page 2020
-
[52]
Shapley counterfactual credits for multi-agent reinforcement learning
Jiahui Li, Kun Kuang, Baoxiang Wang, Furui Liu, Long Chen, Fei Wu, and Jun Xiao. Shapley counterfactual credits for multi-agent reinforcement learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 934–942, 2021
work page 2021
-
[53]
Shaq: Incorporating shapley value theory into multi-agent q-learning
Jianhong Wang, Yuan Zhang, Yunjie Gu, and Tae-Kyun Kim. Shaq: Incorporating shapley value theory into multi-agent q-learning. Advances in Neural Information Processing Systems, 35:5941–5954, 2022
work page 2022
-
[54]
Counterfactual conservative q learning for offline multi-agent reinforcement learning
Jianzhun Shao, Yun Qu, Chen Chen, Hongchang Zhang, and Xiangyang Ji. Counterfactual conservative q learning for offline multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 36:77290–77312, 2023
work page 2023
-
[55]
Learning to coordinate from offline datasets with uncoordinated behavior policies
Jinming Ma and Feng Wu. Learning to coordinate from offline datasets with uncoordinated behavior policies. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 1258–1266, 2023
work page 2023
-
[56]
Understanding individual agent importance in multi-agent system via counterfactual reasoning
Jianming Chen, Yawen Wang, Junjie Wang, Xiaofei Xie, Jun Hu, Qing Wang, and Fanjiang Xu. Understanding individual agent importance in multi-agent system via counterfactual reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 15785–15794, 2025
work page 2025
-
[57]
Statemask: Explaining deep reinforcement learning through state mask
Zelei Cheng, Xian Wu, Jiahao Yu, Wenhai Sun, Wenbo Guo, and Xinyu Xing. Statemask: Explaining deep reinforcement learning through state mask. Advances in Neural Information Processing Systems, 36:62457–62487, 2023
work page 2023
-
[58]
Learning nearly de- composable value functions via communication minimization
Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. Learning nearly de- composable value functions via communication minimization. In International Conference on Learning Representations, 2020
work page 2020
-
[59]
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, second edition, 2018. URL http://incompleteideas.net/book/the-book-2nd.html
work page 2018
-
[60]
Rode: Learning roles to decompose multi-agent tasks
Tonghan Wang, Tarun Gupta, Anuj Mahajan, Bei Peng, Shimon Whiteson, and Chongjie Zhang. Rode: Learning roles to decompose multi-agent tasks. In International Conference on Learning Representations, 2021
work page 2021
-
[61]
The StarCraft Multi-Agent Challenge,
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nan- tas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. arXiv preprint arXiv:1902.04043, 2019
-
[62]
Google research football: A novel reinforcement learning environment
Karol Kurach, Anton Raichuk, Piotr Sta´nczyk, Michał Zaj ˛ ac, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 4501–4510, 2020
work page 2020
-
[63]
Jian Hu, Siyang Jiang, Seth Austin Harding, Haibin Wu, and Shih wei Liao. Rethinking the implementation tricks and monotonicity constraint in cooperative multi-agent reinforcement learning. 2021. 13 A Broader Impact This work advances cooperative multi-agent systems by introducing a framework that fosters coordi- nated behavior through influence-based int...
work page 2021
-
[64]
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and introduction (Section 1) clearly and accurately reflect the paper’s main contributions and scope. Guidelines: • The answer NA means that the abstract and introduction do not include...
-
[65]
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Yes] Justification: Section 6 highlights that FIM assumes static influence targets and does not account for temporal adaptability. Guidelines: • The answer NA means that the paper has no limitation while the answer No means that the paper has limita...
-
[66]
Guidelines: • The answer NA means that the paper does not include theoretical results
Theory assumptions and proofs Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? 26 Answer: [NA] Justification: The paper does not include theoretical results. Guidelines: • The answer NA means that the paper does not include theoretical results. • All the theorems, formulas, and p...
-
[67]
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main ex- perimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)? Answer: [Yes] . Justification: The paper ensures reprod...
-
[68]
Guidelines: • The answer NA means that paper does not include experiments requiring code
Open access to data and code 27 Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Yes] Justification: The code is openly accessible with clear instructions for reproducing the main experimental results. Gui...
-
[69]
Guidelines: • The answer NA means that the paper does not include experiments
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyper- parameters, how they were chosen, type of optimizer, etc.) necessary to understand the results? Answer: [Yes] Justification: The paper provides all necessary training and testing details, including hyper- parameter settings, ablation ...
-
[70]
Guidelines: • The answer NA means that the paper does not include experiments
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments? Answer: [Yes] Justification: All performance plots report the mean across 5 random seeds with shaded areas denoting standard deviation, as stated in Section 5....
-
[71]
Guidelines: • The answer NA means that the paper does not include experiments
Experiments compute resources Question: For each experiment, does the paper provide sufficient information on the com- puter resources (type of compute workers, memory, time of execution) needed to reproduce the experiments? Answer: [Yes] Justification: Section D specifies the GPU/CPU setup and Section E discusses the time of execution. Guidelines: • The ...
-
[72]
Guidelines: • The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines? Answer: [Yes] Justification: The research uses standard simulation benchmarks without involving human subjects or sensitive data and adheres to NeurIPS ethical guidelines throughout. Guide...
-
[73]
Guidelines: 29 • The answer NA means that there is no societal impact of the work performed
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [Yes] Justification: Societal impacts are discussed in Appendix A and no negative impacts are foreseen. Guidelines: 29 • The answer NA means that there is no societal impact of the work performed. • If the ...
-
[74]
Guidelines: • The answer NA means that the paper poses no such risks
Safeguards Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)? Answer: [NA] Justification: The paper poses no significant risk of misuse, as it does not release models or datasets with d...
-
[75]
Guidelines: • The answer NA means that the paper does not use existing assets
Licenses for existing assets Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Yes] Justification: All used environments and baselines are properly cited in Section 5. Guidelines: • The answer NA...
-
[76]
Guidelines: • The answer NA means that the paper does not release new assets
New assets Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets? Answer: [Yes] Justification: The released code are documented and provided with usage instructions. Guidelines: • The answer NA means that the paper does not release new assets. • Researchers should communicate the details of...
-
[77]
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)? Answer: [NA] Justification: The research does not involve any human subjects or c...
-
[78]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[79]
Declaration of LLM usage Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigorousness, or originality of the research, decla...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.