Revisiting the Past: Data Unlearning with Model State History
Pith reviewed 2026-05-19 08:08 UTC · model grok-4.3
The pith
Arithmetic on past model checkpoints removes targeted data influences from large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
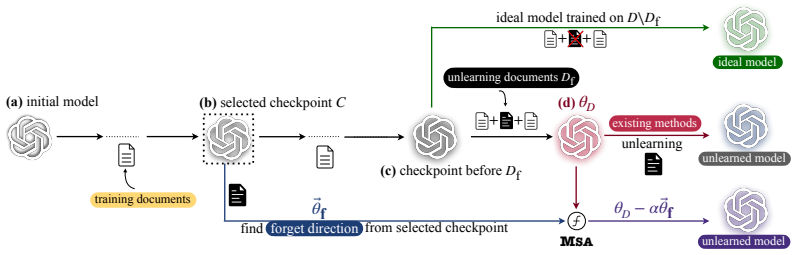
MSA utilizes prior model checkpoints to estimate and counteract the effect of targeted datapoints through arithmetic operations on those states, achieving competitive performance and often outperforming existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics.
What carries the argument
Model State Arithmetic (MSA), which performs linear combinations of historical model checkpoints to isolate and negate the contribution of specific training examples.
Load-bearing premise
Simple arithmetic on checkpoints recorded at different training stages can isolate the precise influence of individual datapoints without unintended changes to unrelated model behavior.
What would settle it
A direct test would check whether a model after MSA still produces outputs traceable to the unlearned datapoints or exhibits measurable drops on unrelated tasks or general capabilities.
Figures



read the original abstract
Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints on a model through complete retraining -- by repeatedly pretraining the model on datasets that exclude these specific instances -- is computationally prohibitive. To address this, unlearning algorithms have been proposed, that aim to eliminate the influence of particular datapoints at a low computational cost, while leaving the rest of the model intact. However, precisely unlearning the influence of data on a large language model has proven to be a major challenge. In this work, we propose a new algorithm, MSA (Model State Arithmetic), for unlearning datapoints in large language models. MSA utilizes prior model checkpoints -- artifacts that record model states at different stages of pretraining -- to estimate and counteract the effect of targeted datapoints. Our experimental results show that MSA achieves competitive performance and often outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Model State Arithmetic (MSA), a new unlearning algorithm for large language models that performs arithmetic operations on historical model checkpoints saved at different stages of pretraining to estimate and subtract the influence of targeted datapoints. It claims that MSA achieves competitive performance and often outperforms existing machine unlearning methods across multiple benchmarks, models, and evaluation metrics while remaining computationally efficient.
Significance. If the central claims hold after addressing the noted issues, the work could be significant for offering a practical unlearning approach that exploits readily available training artifacts rather than requiring gradients or full retraining, potentially advancing data erasure techniques for privacy, copyright, and performance concerns in LLMs.
major comments (2)
- [Method (MSA definition and derivation)] The core assumption underlying MSA—that linear or simple arithmetic combinations of prior checkpoints can isolate the contribution of individual datapoints—is load-bearing for the central claim but rests on an unverified separability premise. Given the path-dependent and non-linear nature of SGD trajectories, differences between checkpoints at stages t and t+k do not cleanly disentangle the effect of any single example from entangled batch, layer, and optimization influences; explicit controls demonstrating unchanged performance on unrelated capabilities and data distributions are needed to support the outperformance claims.
- [Abstract and Experiments section] Abstract and experimental results: The claim that MSA 'achieves competitive performance and often outperforms existing machine unlearning algorithms' is presented without details on exact metrics, chosen baselines, statistical significance testing, or safeguards against post-hoc baseline or hyperparameter selection. This directly affects verifiability of the performance advantage and must be addressed with full tables, held-out evaluation protocols, and ablation studies.
minor comments (2)
- [Method] Notation for the arithmetic operations in MSA should be defined more explicitly (e.g., the precise form of the linear combination or subtraction) to allow reproducibility.
- [Abstract] The abstract would benefit from a one-sentence description of the specific benchmarks and models used to ground the performance claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to improve its rigor, clarity, and verifiability.
read point-by-point responses
-
Referee: [Method (MSA definition and derivation)] The core assumption underlying MSA—that linear or simple arithmetic combinations of prior checkpoints can isolate the contribution of individual datapoints—is load-bearing for the central claim but rests on an unverified separability premise. Given the path-dependent and non-linear nature of SGD trajectories, differences between checkpoints at stages t and t+k do not cleanly disentangle the effect of any single example from entangled batch, layer, and optimization influences; explicit controls demonstrating unchanged performance on unrelated capabilities and data distributions are needed to support the outperformance claims.
Authors: We acknowledge that SGD trajectories are path-dependent and non-linear, which complicates clean isolation of individual datapoint effects. Our approach is an empirical approximation that leverages readily available checkpoints rather than claiming exact separability. In the revised manuscript, we have added explicit controls evaluating performance on unrelated tasks and data distributions after applying MSA, demonstrating that non-targeted capabilities remain largely unaffected. We have also expanded the discussion of the method's assumptions and limitations to better contextualize the approximation. revision: yes
-
Referee: [Abstract and Experiments section] Abstract and experimental results: The claim that MSA 'achieves competitive performance and often outperforms existing machine unlearning algorithms' is presented without details on exact metrics, chosen baselines, statistical significance testing, or safeguards against post-hoc baseline or hyperparameter selection. This directly affects verifiability of the performance advantage and must be addressed with full tables, held-out evaluation protocols, and ablation studies.
Authors: We agree that additional transparency is essential for verifying the performance claims. The revised Experiments section now includes full tables with all metrics, a complete list of baselines with references, results from statistical significance testing, and explicit descriptions of held-out evaluation protocols. Ablation studies on checkpoint frequency and arithmetic variants have been added. We clarify that baselines and hyperparameters were selected based on prior literature and fixed in advance, with no post-hoc adjustments. The abstract has been lightly updated to direct readers to these detailed results in the main text. revision: yes
Circularity Check
MSA unlearning method is a heuristic arithmetic on checkpoints with empirical validation; no derivation reduces to its inputs by construction.
full rationale
The paper proposes MSA as a practical algorithm that performs arithmetic on prior model checkpoints to counteract targeted datapoint effects. Performance claims rest on experimental comparisons across benchmarks, models, and metrics rather than any closed-form derivation or theorem. No load-bearing step equates a prediction to a fitted parameter or self-referential definition, and the method does not invoke self-citations to establish uniqueness or force its form. The approach remains self-contained as an empirical proposal without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Model State Arithmetic (MSA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
θ_unlearn = θ_D − α ⃗θ_f + β ⃗θ_r ... finetune θ0 for ef epochs on the forget set Df, resulting in ... forget vector ⃗θ_f := θ1 − θ0
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MSA utilizes prior model checkpoints ... to estimate and counteract the effect of targeted datapoints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
To each (textual sequence) its own: Im- proving memorized-data unlearning in large language models
George-Octavian Barbulescu and Peter Triantafillou. To each (textual sequence) its own: Im- proving memorized-data unlearning in large language models. arXiv preprint arXiv:2405.03097, 2024
-
[3]
Leace: Perfect linear concept erasure in closed form
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. Leace: Perfect linear concept erasure in closed form. Advances in Neural Information Processing Systems, 36:66044–66063, 2023
work page 2023
-
[4]
Digital forgetting in large language models: A survey of unlearning methods
Alberto Blanco-Justicia, Najeeb Jebreel, Benet Manzanares, David Sánchez, Josep Domingo- Ferrer, Guillem Collell, and Kuan Eeik Tan. Digital forgetting in large language models: A survey of unlearning methods. arXiv preprint arXiv:2404.02062, 2024
-
[5]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In 2021 IEEE symposium on security and privacy (SP) , pages 141–159. IEEE, 2021
work page 2021
-
[6]
The right to be forgotten and the informational autonomy in the digital environment
De Terwangne C. The right to be forgotten and the informational autonomy in the digital environment. Scientific analysis or review LB-NA-26434-EN-N, Luxembourg (Luxembourg), 2013
work page 2013
-
[7]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21) , pages 2633–2650, 2021
work page 2021
-
[8]
Unlearn what you want to forget: Efficient unlearning for llms
Jiaao Chen and Diyi Yang. Unlearn what you want to forget: Efficient unlearning for llms. arXiv preprint arXiv:2310.20150, 2023
-
[9]
Towards scalable exact machine unlearning using parameter-efficient fine-tuning
Somnath Basu Roy Chowdhury, Krzysztof Choromanski, Arijit Sehanobish, Avinava Dubey, and Snigdha Chaturvedi. Towards scalable exact machine unlearning using parameter-efficient fine-tuning. arXiv preprint arXiv:2406.16257, 2024
-
[10]
OpenUnlearning: A unified framework for llm unlearning benchmarks
Vineeth Dorna, Anmol Mekala, Wenlong Zhao, Andrew McCallum, J Zico Kolter, and Pratyush Maini. OpenUnlearning: A unified framework for llm unlearning benchmarks. https:// github.com/locuslab/open-unlearning, 2025. Accessed: February 27, 2025
work page 2025
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Who’s Harry Potter? Approximate Unlearning in LLMs, October 2023
Ronen Eldan and Mark Russinovich. Who’s Harry Potter? Approximate Unlearning in LLMs, October 2023. URL http://arxiv.org/abs/2310.02238. arXiv:2310.02238 [cs]
-
[13]
Simplicity prevails: Rethinking negative preference optimization for llm unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for llm unlearning. arXiv preprint arXiv:2410.07163, 2024
-
[14]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2426–2436, 2023
work page 2023
-
[15]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312, 2020
work page 2020
-
[16]
Time travel in llms: Tracing data contamination in large language models, 2024
Shahriar Golchin and Mihai Surdeanu. Time travel in llms: Tracing data contamination in large language models, 2024. URL https://arxiv.org/abs/2308.08493
-
[17]
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. arXiv preprint arXiv:2402.00838, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Intrinsic evaluation of unlearning using parametric knowledge traces
Yihuai Hong, Lei Yu, Haiqin Yang, Shauli Ravfogel, and Mor Geva. Intrinsic evaluation of unlearning using parametric knowledge traces. arXiv preprint arXiv:2406.11614, 2024
-
[19]
Jie Huang, Hanyin Shao, and Kevin Chen-Chuan Chang. Are large pre-trained language models leaking your personal information? arXiv preprint arXiv:2205.12628, 2022
-
[20]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. arXiv preprint arXiv:2210.01504, 2022
-
[22]
Soul: Unlocking the power of second-order optimization for llm unlearning
Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffenderfer, Bhavya Kailkhura, and Sijia Liu. Soul: Unlocking the power of second-order optimization for llm unlearning. arXiv preprint arXiv:2404.18239, 2024
-
[23]
Rwku: Benchmarking real-world knowledge unlearning for large language models
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. Rwku: Benchmarking real-world knowledge unlearning for large language models. arXiv preprint arXiv:2406.10890, 2024
-
[24]
Kadhe, Farhan Ahmed, Dennis Wei, Nathalie Baracaldo, and Inkit Padhi
S. Kadhe, Farhan Ahmed, Dennis Wei, Nathalie Baracaldo, and Inkit Padhi. Split, unlearn, merge: Leveraging data attributes for more effective unlearning in llms. ArXiv, abs/2406.11780,
-
[25]
URL https://api.semanticscholar.org/CorpusId:270559985
-
[26]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. arXiv preprint arXiv:2403.03218, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms. arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Privacy risks of general-purpose language models
Xudong Pan, Mi Zhang, Shouling Ji, and Min Yang. Privacy risks of general-purpose language models. 2020 IEEE Symposium on Security and Privacy (SP) , pages 1314–1331, 2020. URL https://api.semanticscholar.org/CorpusID:220938739
work page 2020
-
[30]
The frontier of data erasure: Machine unlearning for large language models
Youyang Qu, Ming Ding, Nan Sun, Kanchana Thilakarathna, Tianqing Zhu, and Dusit Niyato. The frontier of data erasure: Machine unlearning for large language models. arXiv preprint arXiv:2403.15779, 2024
-
[31]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[32]
Restor: Knowledge recovery through machine unlearning
Keivan Rezaei, Khyathi Chandu, Soheil Feizi, Yejin Choi, Faeze Brahman, and Abhilasha Ravichander. Restor: Knowledge recovery through machine unlearning. arXiv preprint arXiv:2411.00204, 2024
-
[33]
Muse: Machine unlearning six-way evaluation for language models
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A Smith, and Chiyuan Zhang. Muse: Machine unlearning six-way evaluation for language models. arXiv preprint arXiv:2407.06460, 2024
-
[34]
Erasing without remembering: Safeguarding knowledge forgetting in large language models, 2025
Huazheng Wang, Yongcheng Jing, Haifeng Sun, Yingjie Wang, Jingyu Wang, Jianxin Liao, and Dacheng Tao. Erasing without remembering: Safeguarding knowledge forgetting in large language models, 2025. URL https://arxiv.org/abs/2502.19982
-
[35]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems , 36, 2024
work page 2024
-
[36]
Large language model unlearning
Yuanshun Yao, Xiaojun Xu, and Yang Liu. Large language model unlearning. arXiv preprint arXiv:2310.10683, 2023
-
[37]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. arXiv preprint arXiv:2404.05868, 2024. 12 A GPT-4o for TOFU Metrics We utilize GPT-4o to evaluate model outputs by identifying which candidate response is most semantically similar to the model’s output. Candidates include t...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.