Experience converting a large mathematical software package written in C++ to C++20 modules
Pith reviewed 2026-05-19 07:37 UTC · model grok-4.3
The pith
A large C++ finite element library can be converted to C++20 modules with moderate effort while keeping header support intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that deal.II can be converted to provide both traditional header includes and C++20 module interfaces from one codebase, and that this change reduces compile time for the library after a non-trivial but manageable amount of work.
What carries the argument
The dual-interface build system that produces both header files and module interface units from the existing code without altering internal organization.
If this is right
- The library itself compiles faster after conversion.
- Downstream projects experience no clear improvement or worsening in compile times.
- Legacy header users continue to work without changes.
- A gradual, ecosystem-wide shift to modules becomes realistic over many years.
Where Pith is reading between the lines
- Other large scientific C++ libraries could adopt the same dual-header-and-module approach to lower migration risk.
- Compiler improvements in module handling may amplify the compile-time gains seen here.
- Build systems for numerical software may evolve to default to modules once a critical mass of packages convert.
Load-bearing premise
The library's existing header structure and build system can be adapted to produce both header and module interfaces without requiring a complete redesign of the internal code organization or loss of functionality for existing users.
What would settle it
An attempt that forces a full internal redesign, breaks existing user code, or shows no compile-time improvement for the library itself would falsify the central claim.
Figures
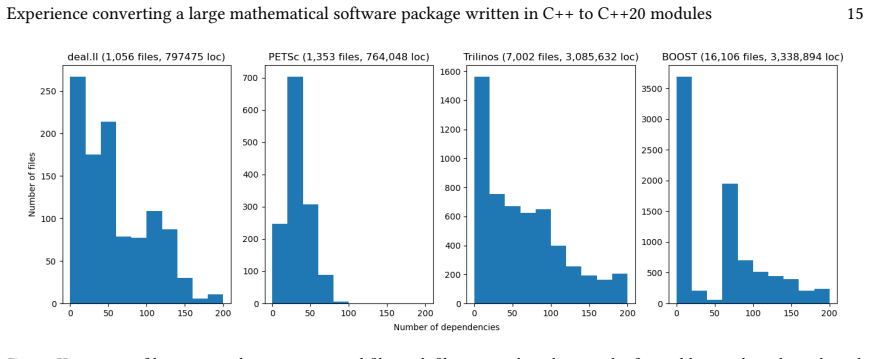
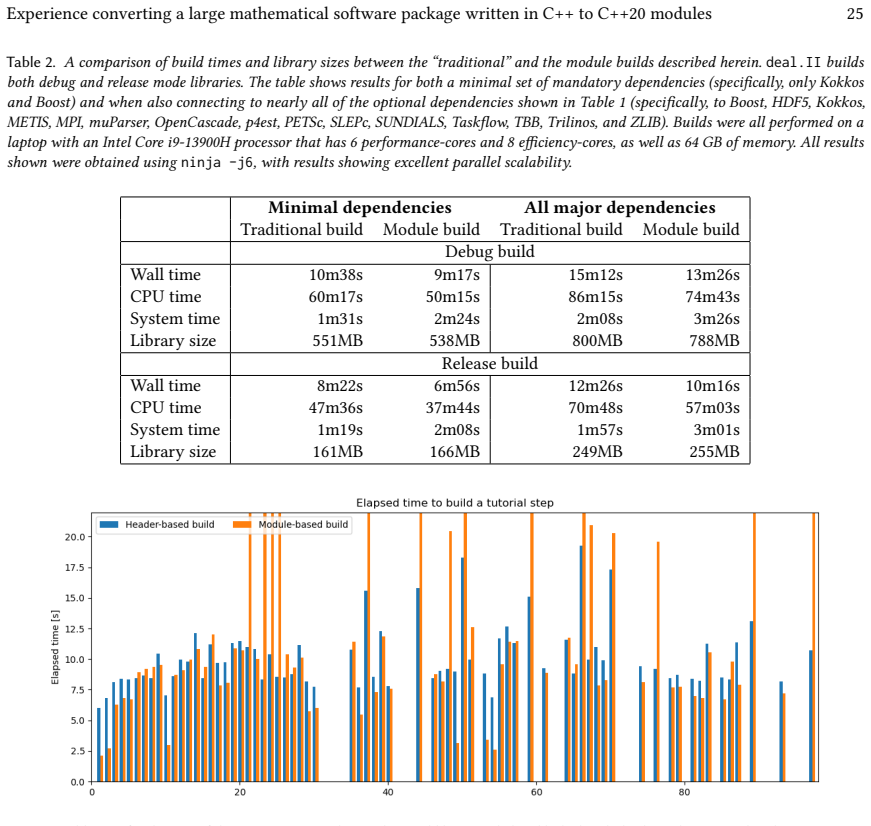
read the original abstract
Mathematical software has traditionally been built in the form of "packages" that build on each other. A substantial fraction of these packages is written in C++ and, as a consequence, the interface of a package is described in the form of header files that downstream packages and applications can then #include. C++ has inherited this approach towards exporting interfaces from C, but the approach is clunky, unreliable, and slow. As a consequence, C++20 has introduced a "module" system in which packages explicitly export declarations and code that compilers then store in machine-readable form and that downstream users can "import" -- a system in line with what many other programming languages have used for decades. Herein, I explore how one can convert large mathematical software packages written in C++ to this system, using the deal.II finite element library with its around 800,000 lines of code as an example. I describe an approach that allows providing both header-based and module-based interfaces from the same code base, discuss the challenges one encounters, and how modules actually work in practice in a variety of technical and human metrics. The results show that with a non-trivial, but also not prohibitive effort, the conversion to modules is possible, resulting in a reduction in compile time for the converted library itself; on the other hand, for downstream projects, compile times show no clear trend. I end with thoughts about long-term strategies for converting the entire ecosystem of mathematical software over the coming years or decades.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports on converting the deal.II finite element library (~800,000 lines of C++) to C++20 modules while preserving a traditional header-based interface from the same source base. It details a dual-interface migration strategy, technical and human challenges encountered, compile-time measurements for the library and downstream projects, and concludes that conversion is feasible with non-trivial but manageable effort, yielding compile-time reductions for the converted library itself but no clear trend for downstream users. The author also discusses long-term strategies for the broader mathematical software ecosystem.
Significance. If the described conversion process and measurements are reproducible, the work provides a valuable, grounded case study for maintainers of large scientific C++ codebases considering C++20 module adoption. It demonstrates practical feasibility without requiring a full redesign, quantifies compile-time effects on the library, and surfaces real-world obstacles such as build-system integration and compatibility. These insights are timely for high-performance computing and mathematical software communities where header-based interfaces remain dominant.
minor comments (3)
- Abstract: the phrase 'around 800,000 lines of code' would benefit from an exact figure or a citation to the specific commit/version measured.
- Section on benchmark methodology: clarify whether the reported compile-time reductions include or exclude module interface unit compilation time, and state the compiler version and flags used for all measurements.
- Discussion of downstream projects: the statement that 'compile times show no clear trend' would be strengthened by reporting the number of downstream projects tested and the range of observed changes rather than a qualitative summary.
Simulated Author's Rebuttal
We thank the referee for their positive review and recommendation to accept the manuscript. The referee's summary accurately captures our contributions regarding the conversion of the deal.II library to C++20 modules while maintaining a header-based interface.
Circularity Check
No significant circularity
full rationale
This is an empirical experience report describing the practical conversion of the deal.II library to C++20 modules. It reports on implementation steps, encountered challenges, and direct compile-time measurements from the actual codebase. There are no mathematical derivations, no parameters fitted to data and then presented as predictions, and no load-bearing self-citations or uniqueness theorems. All claims rest on observable outcomes from the migration process itself rather than reducing to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Major C++ compilers provide stable enough support for modules to allow a large existing codebase to be converted without fundamental incompatibilities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The results show that with a non-trivial, but also not prohibitive effort, the conversion to modules is possible, resulting in a reduction in compile time for the converted library itself
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dealing with external dependencies turned out to be a major component of the work
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of Numerical Mathematics32(4), 369–380 (2024) https://doi.org/10.1515/jnma-2024-0137
The deal.II library, Version 9.6.Journal of Numerical Mathematics 32, 4 (2024), 369–380. https://doi.org/10.1515/jnma-2024-0137 M. Alnæs, J. Blechta, J. Hake, A. Johansson, B. Kehlet, A. Logg, C. Richardson, J. Ring, M. E. Rognes, and G. N. Wells
-
[2]
Archive of Numerical Software 3, 100 (Dec
The FEniCS Project Version 1.5. Archive of Numerical Software 3, 100 (Dec. 2015), 9–23. https://doi.org/10.11588/ans.2015.100.20553 Manuscript submitted to ACM Experience converting a large mathematical software package written in C++ to C++20 modules 31 P. R. Amestoy, A. Buttari, J.-Y. L’Excellent, and T. Mary
- [3]
-
[4]
https://doi.org/10.1145/3242094 R. Anderson, J. Andrej, A. Barker, J. Bramwell, J.-S. Camier, J. Cerveny, V. Dobrev, Y. Dudouit, A. Fisher, T. Kolev, W. Pazner, M. Stowell, V. Tomov, I. Akkerman, J. Dahm, D. Medina, and S. Zampini
-
[5]
Computers & Mathematics with Applications 81 (Jan
MFEM: A Modular Finite Element Methods Library. Computers & Mathematics with Applications 81 (Jan. 2021), 42–74. https://doi.org/10.1016/j.camwa.2020.06.009 D. Arndt, W. Bangerth, D. Davydov, T. Heister, L. Heltai, M. Kronbichler, M. Maier, J.-P. Pelteret, B. Turcksin, and D. Wells
-
[6]
Computers & Mathematics with Applications 81 (2021), 407–422
The deal.II finite element library: Design, features, and insights. Computers & Mathematics with Applications 81 (2021), 407–422. https://doi.org/10.1016/j.camwa.2020.02.022 S. Balay, S. Abhyankar, M. F. Adams, S. Benson, J. Brown, P. Brune, K. Buschelman, E. Constantinescu, L. Dalcin, A. Dener, V. Eijkhout, W. D. Gropp, V. Hapla, T. Isaac, P. Jolivet, D....
-
[7]
Computers & Mathematics with Applications 81 (Jan
The DUNE Framework: Basic Concepts and Recent Developments. Computers & Mathematics with Applications 81 (Jan. 2021), 75–112. https://doi.org/10.1016/j.camwa.2020.06.007 N. Brousse
-
[8]
The issue of monorepo and polyrepo in large enterprises. In Programming ’19: Companion Proceedings of the 3rd International Conference on the Art, Science, and Engineering of Programming , S. Marr and W. Cazzola (Eds.). ACM. https://doi.org/10.1145/3328433.3328435 C. Burstedde, L. C. Wilcox, and O. Ghattas
-
[9]
p4est: Scalable algorithms for parallel adaptive mesh refinement on forests of octrees. SIAM J. Sci. Comput. 33, 3 (2011), 1103–1133. T. A. Davis
work page 2011
- [10]
-
[11]
Algorithm 755: ADOL-C: a package for the automatic differentiation of algorithms written in C/C++. ACM Trans. Math. Software 22, 2 (1996), 131–167. https://doi.org/10.1145/229473.229474 T. Heister, J. Dannberg, R. Gassmöller, and W. Bangerth
-
[12]
II: Realistic Models and Problems
High Accuracy Mantle Convection Simulation through Modern Numerical Methods. II: Realistic Models and Problems. Geophysics Journal International 210 (2017), 833–851. V. Hernandez, J. E. Roman, and V. Vidal
work page 2017
- [13]
- [14]
- [15]
-
[16]
IEEE Transactions on Parallel and Distributed Systems 33, 6 (2021), 1303–1320
Taskflow: A lightweight parallel and heterogeneous task graph computing system. IEEE Transactions on Parallel and Distributed Systems 33, 6 (2021), 1303–1320. International Standards Organization
work page 2021
-
[17]
https://www.iso.org/standard/79358.html
ISO/IEC 14882:2020: The C++20 Programming Language Standard. https://www.iso.org/standard/79358.html. B. Jacob, G. Guennebaud, et al
work page 2020
-
[18]
A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 20, 1 (1998), 359–392. B. S. Kirk, J. W. Peterson, R. H. Stogner, and G. F. Carey
work page 1998
-
[19]
Engineering with Computers 22, 3 (Dec
libMesh: A C++ Library for Parallel Adaptive Mesh Refinement/Coarsening Simulations. Engineering with Computers 22, 3 (Dec. 2006), 237–254. https://doi.org/10.1007/s00366-006-0049-3 M. Kronbichler, T. Heister, and W. Bangerth
-
[20]
Geophysics Journal International 191 (2012), 12–29
High Accuracy Mantle Convection Simulation through Modern Numerical Methods. Geophysics Journal International 191 (2012), 12–29. Message Passing Interface Forum
work page 2012
-
[21]
Why Google stores billions of lines of code in a single repository. Commun. ACM 59 (2016), 78–87. Issue
work page 2016
- [22]
-
[23]
https://crascit.com/2024/04/04/cxx-modules-cmake-shared-libraries/
C++20 Modules, CMake, And Shared Libraries. https://crascit.com/2024/04/04/cxx-modules-cmake-shared-libraries/. The Boost project
work page 2024
-
[24]
IEEE Transactions on Parallel and Distributed Systems 33, 4 (2022), 805–817
Kokkos 3: Programming Model Extensions for the Exascale Era. IEEE Transactions on Parallel and Distributed Systems 33, 4 (2022), 805–817. https://doi.org/10.1109/TPDS.2021.3097283 A. Wächter and L. T. Biegler
-
[25]
On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Mathematical Programming 106, 1 (April 2005), 25–57. https://doi.org/10.1007/s10107-004-0559-y Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.