Making Logic a First-Class Citizen in Generative ML for Networking
Pith reviewed 2026-05-19 07:21 UTC · model grok-4.3
The pith
Enforcing learned networking logic rules on a generic GPT-2 model matches or exceeds specialized systems across three tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
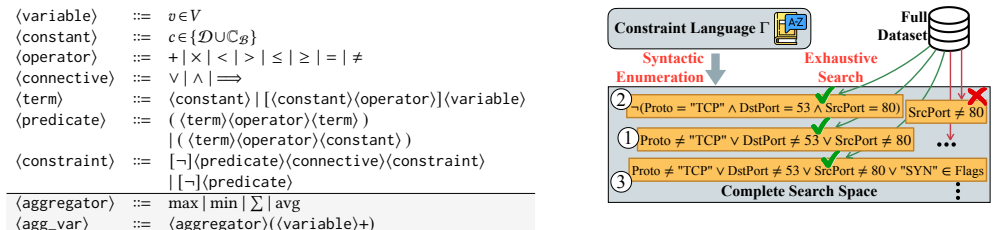
NetNomos is a multi-stage framework that learns first-order logic rules from network data, filters them to retain only semantically meaningful ones, and enforces them via collaborative generation between a generative ML model and an SMT solver. When these rules are applied to a generic GPT-2 model, the resulting system achieves performance on par with or surpassing specialized state-of-the-art systems such as Zoom2Net and NetShare on telemetry imputation, traffic forecasting, and synthetic data generation across four real-world network datasets, while also proving 1.6 to 6.5 times more scalable than prior rule-learning methods.
What carries the argument
Collaborative generation between the ML model and SMT solver that enforces filtered first-order logic rules during output production.
If this is right
- Generative outputs respect known networking relationships instead of visibly violating them.
- Behavioral adjustments are possible by editing the rule set rather than retraining the underlying model.
- Rule discovery scales 1.6 to 6.5 times better than previous state-of-the-art methods across diverse datasets.
- A single general model can handle imputation, forecasting, and synthetic trace generation at competitive quality levels.
Where Pith is reading between the lines
- The same learn-filter-enforce pattern could be applied to generative models in other constrained domains such as physics or biology simulations.
- Live network deployments would reveal whether the SMT step introduces latency that limits real-time use.
- Combining data-learned rules with a small amount of expert-provided rules might cover edge cases the current pipeline misses.
- The explicit rules could serve as an interpretable interface for operators to audit or override model behavior.
Load-bearing premise
Rules automatically learned from data can be filtered into a set that is both semantically meaningful and sufficient to improve model behavior when enforced via SMT collaboration without the enforcement step degrading generative quality.
What would settle it
Demonstrating that SMT-enforced outputs have measurably lower accuracy or realism than the base unenforced GPT-2 model on any of the three tasks would falsify the central claim.
Figures












read the original abstract
Generative ML models are increasingly popular in networking for tasks such as telemetry imputation, prediction, and synthetic trace generation. Despite their capabilities, they suffer from two shortcomings: \emph{(i)} their output is often visibly violating well-known networking rules, which undermines their trustworthiness; and \emph{(ii)} they are difficult to control, frequently requiring retraining even for minor changes. To address these limitations and unlock the benefits of generative models for networking, we propose a new paradigm for integrating explicit network knowledge, in the form of first-order logic rules, into ML models used for networking tasks. Rules capture well-known relationships among observed signals, e.g., that increased latency precedes packet loss. While the idea is conceptually straightforward, its realization is challenging: networking knowledge is rarely formalized into rules, and naively injecting rules into ML models often hampers their effectiveness. This paper introduces NetNomos, a multi-stage framework that \emph{(i)} learns rules directly from data (e.g., measurements); \emph{(ii)} filters them to select semantically meaningful ones; and \emph{(iii)} enforces them through collaborative generation between an ML model and a Satisfiability Modulo Theories (SMT) solver. %We evaluate NetNomos both component-wise and end-to-end across four diverse network datasets. We show that NetNomos learns diverse, meaningful rules from four real-world datasets and is 1.6--6.5$\times$ more scalable than DuoAI, a state-of-the-art (SOTA) rule-learning method. By enforcing these rules on a generic GPT-2 model, NetNomos achieves performance on par with or even surpassing specialized SOTA systems such as Zoom2Net and NetShare across three networking tasks: telemetry imputation, traffic forecasting, and synthetic data generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NetNomos, a multi-stage framework that learns first-order logic rules directly from network measurement data, filters them for semantic meaningfulness, and enforces them during inference through collaborative generation between a generic GPT-2 model and an SMT solver. The central claims are that this integration addresses rule violations and lack of controllability in generative ML for networking, yields 1.6–6.5× better scalability than DuoAI for rule learning, and achieves performance on par with or exceeding specialized SOTA systems (Zoom2Net, NetShare) on telemetry imputation, traffic forecasting, and synthetic trace generation across four real-world datasets.
Significance. If the empirical claims are substantiated, the work offers a practical route to embedding explicit domain knowledge as first-class constraints in generative models without full retraining, which could improve trustworthiness in safety-critical networking applications. The reported scalability gains in rule extraction and the ability to retrofit a generic language model with SMT collaboration are potentially impactful if the enforcement mechanism is shown not to harm generative fidelity.
major comments (3)
- [§3] §3 (Framework): The collaborative generation procedure between GPT-2 and the SMT solver is load-bearing for the performance-parity claim, yet the manuscript provides no quantitative diagnostics (e.g., sample diversity, KL divergence to real traces, or ablation removing the SMT step) demonstrating that hard rule enforcement preserves or improves task metrics rather than introducing bias or mode collapse.
- [§5.1] §5.1 (Rule-learning evaluation): The 1.6–6.5× scalability advantage over DuoAI is asserted, but the comparison lacks explicit controls for dataset size, rule-set cardinality after filtering, and hardware normalization; without these, it is unclear whether the reported speedup is attributable to the proposed pipeline or to implementation differences.
- [§4.3] §4.3 (Filtering stage): The rule-filtering criteria are described as selecting 'semantically meaningful' rules, yet the manuscript treats the filtering thresholds as free parameters without a sensitivity analysis or automated criterion; this directly affects reproducibility of the downstream performance results.
minor comments (3)
- [§2] §2: The related-work discussion of prior logic-injection methods could cite more recent SMT+ML hybrids outside networking to better situate the novelty.
- [Table 2] Table 2: Performance tables report point estimates without standard deviations or confidence intervals across the 22 runs mentioned in the text.
- [Figure 3] Figure 3: The y-axis scale for the scalability plot is logarithmic but the caption does not state the base or the exact metric (wall-clock time vs. memory).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, providing our responses and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Framework): The collaborative generation procedure between GPT-2 and the SMT solver is load-bearing for the performance-parity claim, yet the manuscript provides no quantitative diagnostics (e.g., sample diversity, KL divergence to real traces, or ablation removing the SMT step) demonstrating that hard rule enforcement preserves or improves task metrics rather than introducing bias or mode collapse.
Authors: We agree that explicit diagnostics on the SMT solver's contribution would strengthen the performance-parity claim. The manuscript shows end-to-end results comparable to or better than specialized systems, but lacks a direct ablation of the collaborative generation. In the revised version, we will add an ablation study removing the SMT step and report quantitative metrics including sample diversity, KL divergence to real traces, and task-specific performance to demonstrate that rule enforcement preserves generative fidelity without introducing bias or mode collapse. revision: yes
-
Referee: [§5.1] §5.1 (Rule-learning evaluation): The 1.6–6.5× scalability advantage over DuoAI is asserted, but the comparison lacks explicit controls for dataset size, rule-set cardinality after filtering, and hardware normalization; without these, it is unclear whether the reported speedup is attributable to the proposed pipeline or to implementation differences.
Authors: The referee correctly notes that additional controls would clarify the source of the reported scalability gains. Our experiments used consistent datasets and hardware for both methods. We will revise §5.1 to explicitly report dataset sizes, the cardinality of rule sets after filtering for NetNomos and DuoAI, and hardware-normalized timing measurements. These additions will make the comparison transparent and confirm that the 1.6–6.5× advantage stems from our pipeline's efficiency. revision: yes
-
Referee: [§4.3] §4.3 (Filtering stage): The rule-filtering criteria are described as selecting 'semantically meaningful' rules, yet the manuscript treats the filtering thresholds as free parameters without a sensitivity analysis or automated criterion; this directly affects reproducibility of the downstream performance results.
Authors: We recognize that treating filtering thresholds as free parameters without further analysis limits reproducibility. The thresholds were selected empirically to retain semantically relevant rules. In the revised manuscript, we will add a sensitivity analysis varying the thresholds and reporting effects on rule count and downstream performance. We will also introduce an automated criterion based on data-driven measures such as minimum support and confidence to systematize the process. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation of external components.
full rationale
The paper's core pipeline—learning rules from data, filtering for semantic meaning, and enforcing via SMT collaboration with a generic GPT-2 model—is presented as a multi-stage framework evaluated on real datasets against external baselines (DuoAI, Zoom2Net, NetShare). No equations or steps reduce a claimed performance gain to a fitted parameter or self-citation by construction. The abstract and framework description treat rule learning, filtering, and SMT enforcement as independent modules whose outputs are measured on downstream tasks, without redefining success metrics in terms of the inputs themselves. This is the expected non-circular case for an applied systems paper whose results are benchmarked externally.
Axiom & Free-Parameter Ledger
free parameters (1)
- rule filtering criteria
axioms (1)
- domain assumption Networking domain knowledge can be expressed as first-order logic rules that relate observable signals such as latency and packet loss.
Reference graph
Works this paper leans on
-
[1]
1995.Mining Sequential Patterns
R Agrawal. 1995.Mining Sequential Patterns. Technical Report. Research report
work page 1995
-
[2]
Dana Angluin. 1987. Learning regular sets from queries and counterex- amples. Information and computation 75, 2 (1987), 87–106
work page 1987
-
[3]
Domagoj Babić, Daniel Reynaud, and Dawn Song. 2011. Malware Analysis with Tree Automata Inference. InComputer Aided Verification, Ganesh Gopalakrishnan and Shaz Qadeer (Eds.). Vol. 6806. Springer Berlin Heidelberg, Berlin, Heidelberg, 116–131. https://doi.org/10.1007/ 978-3-642-22110-1_10 Series Title: Lecture Notes in Computer Science
work page 2011
-
[4]
Osbert Bastani, Yewen Pu, and Armando Solar-Lezama. 2018. Verifi- able reinforcement learning via policy extraction.Advances in neural information processing systems 31 (2018)
work page 2018
-
[5]
Nicolas Beldiceanu and Helmut Simonis. 2012. A Model Seeker: Extracting Global Constraint Models from Positive Examples. In Principles and Practice of Constraint Programming , Michela Milano (Ed.). Springer, Berlin, Heidelberg, 141–157. https://doi.org/10.1007/ 978-3-642-33558-7_13
work page 2012
-
[6]
Christian Bessiere, Remi Coletta, Frédéric Koriche, and Barry O’Sullivan
-
[7]
A SAT-based version space algorithm for acquiring constraint satisfaction problems. InMachine Learning: ECML 2005: 16th European Conference on Machine Learning, Porto, Portugal, October 3-7, 2005. Pro- ceedings 16. Springer, 23–34
work page 2005
- [8]
-
[9]
Armin Biere. 2021. Bounded model checking. In Handbook of satisfia- bility. IOS press, 739–764
work page 2021
-
[10]
Garrett Birkhoff. 1940. Lattice theory. Vol. 25. American Mathematical Soc
work page 1940
-
[11]
Garrett Birkhoff. 1967. Lattice Theory. American Mathematical Society. Providence, RI (1967)
work page 1967
-
[12]
Francesco Bronzino, Paul Schmitt, Sara Ayoubi, Guilherme Martins, Renata Teixeira, and Nick Feamster. 2019. Inferring streaming video quality from encrypted traffic: Practical models and deployment experi- ence. Proceedings of the ACM on Measurement and Analysis of Computing Systems 3, 3 (2019), 1–25
work page 2019
-
[13]
Chia Yuan Cho, Domagoj Babi Ć, Eui Chul Richard Shin, and Dawn Song. 2010. Inference and analysis of formal models of botnet command and control protocols. In Proceedings of the 17th ACM conference on Computer and communications security . ACM, Chicago Illinois USA, 426–439. https://doi.org/10.1145/1866307.1866355
-
[14]
Chia Yuan Cho, Domagoj Babić, Pongsin Poosankam, Kevin Zhijie Chen, Edward XueJun Wu, and Dawn Song. 2011.{MACE}:{Model- inference-Assisted} concolic exploration for protocol and vulnerability discovery. In20th USENIX Security Symposium (USENIX Security 11)
work page 2011
-
[15]
Edmund Clarke, Armin Biere, Richard Raimi, and Yunshan Zhu. 2001. Bounded model checking using satisfiability solving.Formal methods in system design 19 (2001), 7–34
work page 2001
-
[16]
David Cohen and Peter Jeavons. 2006. The complexity of constraint languages. In Foundations of Artificial Intelligence. Vol. 2. Elsevier, 245– 280
work page 2006
-
[17]
Fady Copty, Limor Fix, Ranan Fraer, Enrico Giunchiglia, Gila Kamhi, Armando Tacchella, and Moshe Y Vardi. 2001. Benefits of bounded model checking at an industrial setting. InComputer Aided Verification: 13th International Conference, CA V 2001 Paris, France, July 18–22, 2001 Proceedings 13. Springer, 436–453
work page 2001
-
[18]
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. 2020. Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems 33 (2020), 17429–17442
work page 2020
-
[19]
Andrew Cropper and Sebastijan Dumančić. 2022. Inductive logic pro- gramming at 30: a new introduction. Journal of Artificial Intelligence Research 74 (2022), 765–850
work page 2022
-
[20]
Joscha Cüppers, Adrien Schoen, Gregory Blanc, and Pierre-Francois Gimenez. 2024. FlowChronicle: Synthetic Network Flow Generation through Pattern Set Mining. Proceedings of the ACM on Networking 2, CoNEXT4 (2024), 1–20
work page 2024
-
[21]
2002.Introduction to lattices and order
Brian A Davey and Hilary A Priestley. 2002.Introduction to lattices and order. Cambridge university press
work page 2002
-
[22]
Nachum Dershowitz, Ziyad Hanna, and Alexander Nadel. 2006. A scalable algorithm for minimal unsatisfiable core extraction. InTheory and Applications of Satisfiability Testing-SAT 2006: 9th International Conference, Seattle, W A, USA, August 12-15, 2006. Proceedings 9. Springer, 36–41
work page 2006
-
[23]
Franck Djeumou, Cyrus Neary, Eric Goubault, Sylvie Putot, and Ufuk Topcu. 2022. Neural Networks with Physics-Informed Architectures and Constraints for Dynamical Systems Modeling. In Proceedings of The 4th Annual Learning for Dynamics and Control Conference (Pro- ceedings of Machine Learning Research) , Vol. 168. PMLR, 263–277. https://proceedings.mlr.pre...
work page 2022
-
[24]
Pedro Domingos. 1999. The role of Occam’s razor in knowledge discov- ery. Data mining and knowledge discovery 3 (1999), 409–425
work page 1999
-
[25]
Frederic B Fitch. 1963. A logical analysis of some value concepts1.The journal of symbolic logic 28, 2 (1963), 135–142
work page 1963
-
[26]
Center for Applied Internet Data Analysis. 2018. The CAIDA Anonymized Internet Traces Dataset. (April 2018). https://www.caida. org/catalog/datasets/passive_dataset/
work page 2018
-
[27]
Ehab Ghabashneh, Yimeng Zhao, Cristian Lumezanu, Neil Spring, Srikanth Sundaresan, and Sanjay Rao. 2022. A microscopic view of bursts, buffer contention, and loss in data centers. InProceedings of the 22nd ACM Internet Measurement Conference. 567–580
work page 2022
-
[28]
Fengchen Gong, Divya Raghunathan, Aarti Gupta, and Maria Aposto- laki. 2024. Zoom2net: Constrained network telemetry imputation. In Proceedings of the ACM SIGCOMM 2024 Conference. 764–777
work page 2024
-
[29]
Sven Gowal, Krishnamurthy Dvijotham, Robert Stanforth, Rudy Bunel, Chongli Qin, Jonathan Uesato, Relja Arandjelovic, Timothy Mann, and Pushmeet Kohli. 2018. On the effectiveness of interval bound propagation for training verifiably robust models. arXiv preprint arXiv:1810.12715 (2018)
-
[30]
George Grätzer. 2002.General lattice theory. Springer Science & Business Media
work page 2002
-
[31]
2007.The minimum description length principle
Peter D Grünwald. 2007.The minimum description length principle. MIT press
work page 2007
-
[32]
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. 2017. Improved training of wasserstein gans. Advances in neural information processing systems 30 (2017)
work page 2017
-
[33]
Matthias Höschele and Andreas Zeller. 2016. Mining input grammars from dynamic taints. InProceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering. 720–725
work page 2016
-
[34]
Alexey Ignatiev, Alessandro Previti, Mark Liffiton, and Joao Marques- Silva. 2015. Smallest MUS extraction with minimal hitting set dualiza- tion. In International Conference on Principles and Practice of Constraint Programming. Springer, 173–182
work page 2015
-
[35]
Katsumi Inoue, Andrei Doncescu, and Hidetomo Nabeshima. 2013. Com- pleting causal networks by meta-level abduction.Machine learning 91, 2 (2013), 239–277
work page 2013
-
[36]
Jacobs, Roman Beltiukov, Walter Willinger, Ronaldo A
Arthur S. Jacobs, Roman Beltiukov, Walter Willinger, Ronaldo A. Fer- reira, Arpit Gupta, and Lisandro Z. Granville. 2022. AI/ML for Network Security: The Emperor has no Clothes. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (CCS ’22). Association for Computing Machinery, New York, NY, USA, 1537–1551. https://doi.o...
-
[37]
Xiaodong Jia and Gang Tan. 2024. V-Star: Learning Visibly Pushdown Grammars from Program Inputs. Proceedings of the ACM on Program- ming Languages 8, PLDI (2024), 2003–2026
work page 2024
-
[38]
Xi Jiang, Shinan Liu, Aaron Gember-Jacobson, Arjun Nitin Bhagoji, Paul Schmitt, Francesco Bronzino, and Nick Feamster. 2024. Netdiffu- sion: Network data augmentation through protocol-constrained traffic generation. Proceedings of the ACM on Measurement and Analysis of Computing Systems 8, 1 (2024), 1–32
work page 2024
-
[39]
Minhao Jin and Maria Apostolaki. 2025. Robustifying ML-powered Network Classifiers with PANTS. In34th USENIX Security Symposium (USENIX Security 25)
work page 2025
-
[40]
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. 2021. Physics-informed machine learning. Nature Reviews Physics 3, 6 (2021), 422–440
work page 2021
-
[41]
Guy Katz, Derek A. Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Alek- sandar Zeljić, David L. Dill, Mykel J. Kochenderfer, and Clark Barrett. [n. d.]. The Marabou Framework for Verification and Analysis of Deep Neural Networks. In Computer Aided Verification, Isil Dillig and Serdar Tasiran (...
-
[42]
Samuel Kolb, Sergey Paramonov, Tias Guns, and Luc De Raedt. 2017. Learning constraints in spreadsheets and tabular data.Machine Learning 106 (2017), 1441–1468
work page 2017
-
[43]
Mohit Kumar, Samuel Kolb, and Tias Guns. 2022. Learning constraint programming models from data using generate-and-aggregate. In28th International Conference on Principles and Practice of Constraint Program- ming (CP 2022). Schloss Dagstuhl-Leibniz-Zentrum für Informatik
work page 2022
-
[44]
Gabriel Maciá-Fernández, José Camacho, Roberto Magán-Carrión, Pe- dro García-Teodoro, and Roberto Therón. 2018. UGR ‘16: A new dataset for the evaluation of cyclostationarity-based network IDSs.Computers & Security 73 (2018), 411–424
work page 2018
-
[45]
Zili Meng, Minhu Wang, Jiasong Bai, Mingwei Xu, Hongzi Mao, and Hongxin Hu. [n. d.]. Interpreting Deep Learning-Based Networking Systems. In Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication (2020-07-30) (SIGCOMM ’20). Asso...
-
[46]
Tom M Mitchell. 1982. Generalization as search.Artificial intelligence 18, 2 (1982), 203–226
work page 1982
-
[47]
Tom M Mitchell and Tom M Mitchell. 1997.Machine learning. Vol. 1. McGraw-hill New York
work page 1997
-
[48]
Soo-Jin Moon, Jeffrey Helt, Yifei Yuan, Yves Bieri, Sujata Banerjee, Vyas Sekar, Wenfei Wu, Mihalis Yannakakis, and Ying Zhang. 2019. Alembic: Automated model inference for stateful network functions. In 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19). 699–718
work page 2019
-
[49]
Alexander Nadel. 2010. Boosting minimal unsatisfiable core extraction. In Formal methods in computer aided design. IEEE, 221–229
work page 2010
-
[50]
Jon Postel. 1981. Transmission Control Protocol. RFC 793. (Sept. 1981). https://doi.org/10.17487/RFC0793
-
[51]
Markus Ring, Daniel Schlör, Dieter Landes, and Andreas Hotho. 2019. Flow-based network traffic generation using generative adversarial networks. Computers & Security 82 (2019), 156–172
work page 2019
-
[52]
Markus Ring, Sarah Wunderlich, Dominik Grüdl, Dieter Landes, and Andreas Hotho. 2017. Creation of Flow-Based Data Sets for Intrusion Detection. Journal of Information Warfare 16 (2017), 40–53. Issue 4
work page 2017
-
[53]
Adrien Schoen, Gregory Blanc, Pierre-François Gimenez, Yufei Han, Frédéric Majorczyk, and Ludovic Me. 2024. A Tale of Two Methods: Unveiling the limitations of GAN and the Rise of Bayesian Networks for Synthetic Network Traffic Generation. In2024 IEEE European Sym- posium on Security and Privacy Workshops (EuroS&PW). IEEE, 273–286
work page 2024
-
[54]
Iman Sharafaldin, Arash Habibi Lashkari, and Ali A Ghorbani. 2018. Intrusion detection evaluation dataset (CIC-IDS2017).Proceedings of the of Canadian Institute for Cybersecurity (2018)
work page 2018
-
[55]
Aivin V. Solatorio and Olivier Dupriez. 2023. REaLTabFormer: Generat- ing Realistic Relational and Tabular Data using Transformers.arXiv preprint arXiv:2302.02041 (2023)
-
[56]
Ramakrishnan Srikant and Rakesh Agrawal. 1996. Mining sequential patterns: Generalizations and performance improvements. InInterna- tional conference on extending database technology. Springer, 1–17
work page 1996
-
[57]
Leslie G Valiant. 1984. A theory of the learnable.Commun. ACM 27, 11 (1984), 1134–1142
work page 1984
-
[58]
Pan Wang, Shuhang Li, Feng Ye, Zixuan Wang, and Moxuan Zhang
-
[59]
In IEEE International Conference on Communications (ICC) (IEEE): 1–6
PacketCGAN: Exploratory Study of Class Imbalance for Encrypted Traffic Classification Using CGAN. InICC 2020 - 2020 IEEE International Conference on Communications (ICC) . 1–7. https://doi.org/10.1109/ ICC40277.2020.9148946
-
[60]
Brandon T Willard and Rémi Louf. 2023. Efficient Guided Generation for LLMs. arXiv preprint arXiv:2307.09702 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Kerry N Wood and Richard E Harang. 2015. Grammatical inference and language frameworks for langsec. In2015 IEEE Security and Privacy Workshops. IEEE, 88–98
work page 2015
-
[62]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veera- machaneni. 2019. Modeling tabular data using conditional gan. Ad- vances in neural information processing systems 32 (2019)
work page 2019
-
[63]
Yucheng Yin, Zinan Lin, Minhao Jin, Giulia Fanti, and Vyas Sekar. 2022. Practical gan-based synthetic ip header trace generation using netshare. In Proceedings of the ACM SIGCOMM 2022 Conference. 458–472
work page 2022
-
[64]
Yifei Yuan, Dong Lin, Rajeev Alur, and Boon Thau Loo. 2015. Scenario- based programming for SDN policies. InProceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies. 1–13. A SEMANTICS LEARNING ON CIDDS AND UGR Fig. 13 shows the rule violation rates for CIDDS and UGR. Similarly, NetNomos is able to capture semantic differe...
work page 2015
-
[65]
Since 𝐶3 |=𝐶2, one of𝐶2 1 and 𝐶2 2 is semantically equivalent to𝐶2; as- sume it is𝐶2
-
[66]
By the same token, one can find another arity-2 constraint that is equivalent to𝐶2
-
[67]
As the learner traverses downward from the lowest arity value in𝐿, the equivalents of 𝐶2 1 and 𝐶2 2 will be encountered by the learner before𝐶3. Thus, prioritizing the more general but more succinct𝐶2 would not lead to missing𝐶3. In fact, when the learner starts to exam- ine 𝐶3 with, the set C2 of learned arity-2 constraints yields C2 |=𝐶3, making it redu...
-
[68]
∧ (Ack3 = Seq2 +1)) 3: Seq1 +Len1 = Ack2 TCP packet sequencing. 4: (Ack2 = Seq1 + 1 ∧ SrcIp1 = DstIp2) =⇒ ( Tsval1 = Tsecr2) Timestamp echo. 5: (Ack3 = Seq2 + 1 ∧ SrcIp2 = DstIp3) =⇒ ( Tsval2 = Tsecr3) 6: (SrcIp1 = SrcIp2) =⇒ ( Seq1 +Len1 = SeqNum2) Timestamp continuity. 7: (SrcIp ="server") =⇒ ( DstPort ="client_port"∧SrcPort = "server_port") 8: (SrcIp =...
-
[69]
∨ (RstFlagCount > 0) ∨ (PshFlagCount > 0) ∨ (AckFlagCount >
-
[70]
∨ ( CweFlagCount > 0) ∨ ( EceFlagCount > 0)) =⇒ (Protocol ≠ 17) 7: (SynFlagCount > 0) =⇒ (TotalLengthOfFwdPackets > 0) 8: (RstFlagCount > 0) =⇒ (TotalLengthOfFwdPackets > 0) 9: (CweFlagCount > 0) =⇒ (TotalLengthOfFwdPackets > 0) 10: (EceFlagCount > 0) =⇒ (TotalLengthOfFwdPackets > 0) 11: (( SynFlagCount > 0) ∨ (RstFlagCount > 0) ∨(CweFlagCount > 0) ∨ (Ece...
-
[71]
∧ (TotalLengthOfBwdPackets > 0) =⇒ ( FlowBytesPerSecond > 0) 15: (PacketLengthMean > 0) ∧ ( PacketLengthMax > 0) ∧ (PacketLengthMin > 0) =⇒ ( PacketLengthVariance ≥ 0) 16: (FwdPacketLengthMean > 0) ∧ (BwdPacketLengthMean >
-
[72]
∧ (FwdPacketCount > 0) ∧ (BwdPacketCount > 0) =⇒ (FlowPacketMean > 0) 17: (FlowIatMean > 0) ∧ (FlowIatStd > 0) ∧ (FlowIatMin >
-
[73]
Training and inference of ML models are all conducted on an A100 NVIDIA GPU
∧ (FlowIatMax > 0) =⇒ ( ActiveMean > 0) ∧ (IdleMean > 0) 18: (FwdPacketCount > 0) ∨ ( BwdPacketCount > 0) =⇒ (TotalPacketCount = FwdPacketCount+BwdPacketCount) 19: (( TcpFlagsCount > 0) ∧ (Protocol = 6)) ∨(( UdpPacketCount > 0) ∧(Protocol = 17))∨ (( IcmpPacketCount > 0) ∧ (Protocol = 1)) 20: (PacketCount > 0) =⇒ ( MinPacketLength ≤ MeanPacketLength ≤ MaxP...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.