Sequential Regression Learning with Randomized Algorithms
Pith reviewed 2026-05-19 05:49 UTC · model grok-4.3
The pith
Randomized SINDy maintains a probability distribution over predictors for time-dependent data and proves PAC learning via functional analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Randomized SINDy is a sequential machine learning algorithm for dynamic data that has a time-dependent structure. It employs a probabilistic approach with its PAC learning property rigorously proven through the mathematical theory of functional analysis. The algorithm dynamically predicts using a learned probability distribution of predictors, updating weights via gradient descent and a proximal algorithm to maintain a valid probability density. Inspired by SINDy, it incorporates feature augmentation and Tikhonov regularization. For multivariate normal weights the proximal step is omitted to focus on parameter estimation. Effectiveness is demonstrated through experimental results in both the
What carries the argument
The randomized SINDy algorithm, which maintains and updates a probability distribution over predictors via gradient descent and proximal steps to ensure valid densities while establishing PAC bounds through functional analysis.
If this is right
- The method supplies PAC guarantees for sequential regression on time-structured data.
- It applies directly to both regression and binary classification tasks.
- Feature augmentation and Tikhonov regularization can be used together with the probabilistic updates.
- When weights follow a multivariate normal, the proximal step can be dropped without losing the estimation focus.
Where Pith is reading between the lines
- The same probabilistic-update structure might be tested on other sequential tasks such as forecasting or reinforcement learning if the time dependence is preserved.
- Functional-analysis techniques for proving PAC bounds could be applied to other online or streaming algorithms that maintain distributions.
- Empirical checks on additional time-series benchmarks would clarify how sensitive the PAC bounds are to the strength of the time dependence.
Load-bearing premise
The input data must possess a time-dependent structure that keeps the evolving predictor distribution valid under the gradient and proximal updates.
What would settle it
Run the algorithm on a dataset with clear time-dependent structure and measure whether the output distribution ever becomes invalid or whether empirical error rates violate the derived PAC bounds.
Figures

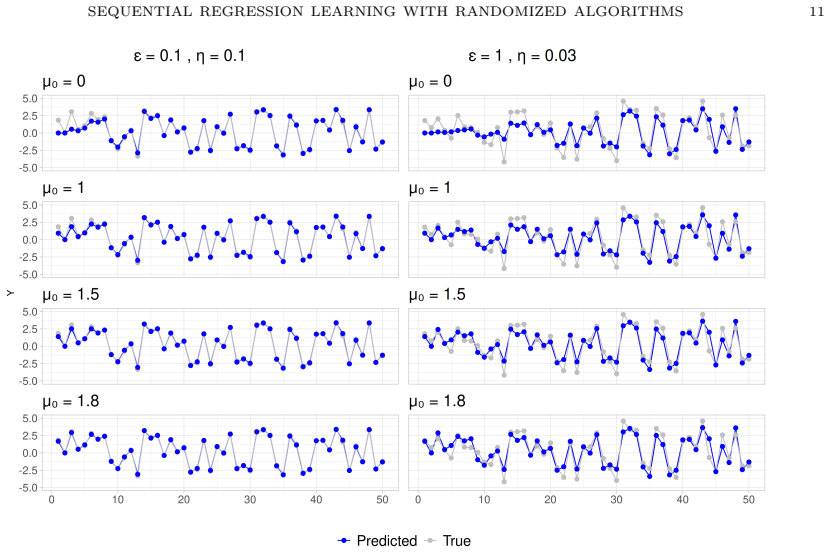







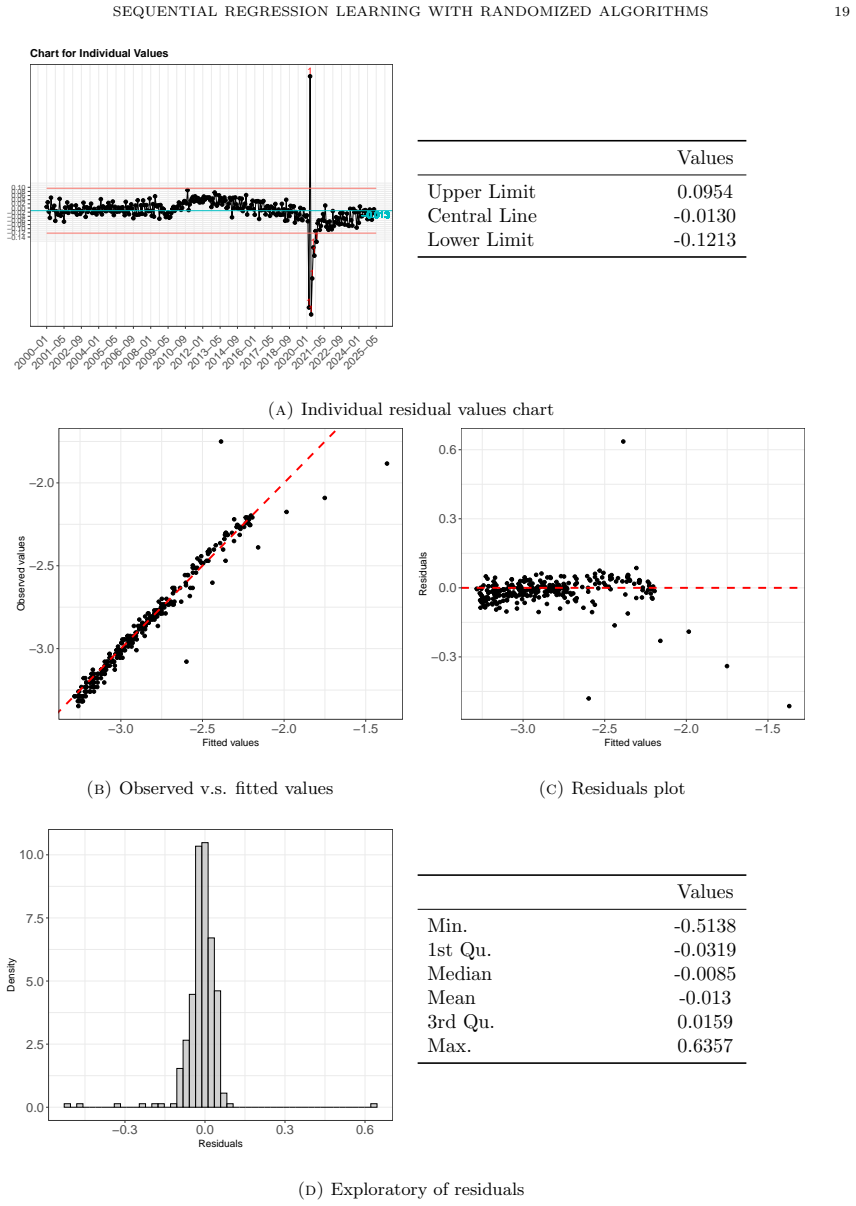


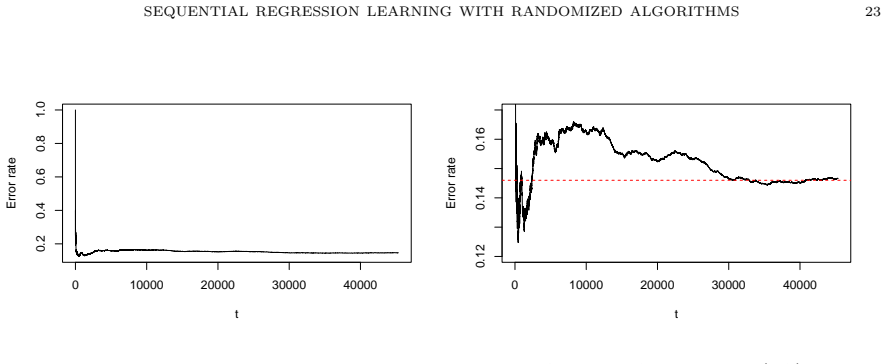
read the original abstract
This paper presents ``randomized SINDy", a sequential machine learning algorithm designed for dynamic data that has a time-dependent structure. It employs a probabilistic approach, with its PAC learning property rigorously proven through the mathematical theory of functional analysis. The algorithm dynamically predicts using a learned probability distribution of predictors, updating weights via gradient descent and a proximal algorithm to maintain a valid probability density. Inspired by SINDy (Brunton et al. 2016), it incorporates feature augmentation and Tikhonov regularization. For multivariate normal weights, the proximal step is omitted to focus on parameter estimation. The algorithm's effectiveness is demonstrated through experimental results in regression and binary classification using real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'randomized SINDy', a sequential machine learning algorithm for dynamic data with time-dependent structure. It employs a probabilistic predictor distribution updated via gradient descent and proximal steps (omitted for multivariate normal weights) to enforce valid densities, claims a rigorous PAC learning guarantee derived from functional analysis, incorporates SINDy-style feature augmentation and Tikhonov regularization, and reports experimental effectiveness on regression and binary classification tasks using real-world data.
Significance. If the PAC guarantee is rigorously established without hidden assumptions on density preservation and the experiments include proper controls, the work could provide a useful bridge between functional-analytic learning theory and sequential regression methods for non-stationary data. The explicit use of randomized predictors and case-dependent proximal handling is a potentially distinctive element, though its value depends on verifiable separation of fitted parameters from out-of-sample predictions.
major comments (2)
- [§3] §3 (PAC learning property via functional analysis): the central claim that a rigorous PAC bound follows from functional analysis applied to the randomized predictor distribution is load-bearing, yet the derivation provides no explicit verification that sequential gradient-descent and proximal updates preserve measurability, boundedness, and independence conditions under time-dependent data structures. The note that the proximal step is omitted for multivariate normal weights further indicates that density-maintenance is case-dependent and requires case-by-case justification.
- [§5] §5 (experimental results): effectiveness is asserted for regression and binary classification on real-world data, but the section contains no baseline comparisons, ablation on the proximal step, or quantitative error analysis separating in-sample fitting from predictive performance, undermining the claim that the algorithm demonstrates practical superiority.
minor comments (2)
- [§2] Notation for the probabilistic predictor distribution and weight updates is introduced without a clear summary table or diagram, making it difficult to track how parameters are separated from predictions across time steps.
- [Introduction] The abstract and introduction cite Brunton et al. (2016) for SINDy inspiration but do not discuss how the randomized extension differs from subsequent SINDy variants that already incorporate probabilistic or sequential elements.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (PAC learning property via functional analysis): the central claim that a rigorous PAC bound follows from functional analysis applied to the randomized predictor distribution is load-bearing, yet the derivation provides no explicit verification that sequential gradient-descent and proximal updates preserve measurability, boundedness, and independence conditions under time-dependent data structures. The note that the proximal step is omitted for multivariate normal weights further indicates that density-maintenance is case-dependent and requires case-by-case justification.
Authors: We agree that the manuscript would benefit from more explicit verification of the conditions required for the PAC bound. The current derivation in §3 applies functional-analytic results to the randomized predictor distribution after the updates, with the proximal operator (when used) projecting onto valid densities. For the multivariate-normal case the proximal step is omitted because the family is closed under the relevant operations and remains a valid density; the independence and boundedness conditions are inherited from the underlying stochastic approximation framework. We will add a new subsection to §3 that supplies the missing case-by-case verification, citing standard measurability results for gradient and proximal maps on probability densities. revision: yes
-
Referee: [§5] §5 (experimental results): effectiveness is asserted for regression and binary classification on real-world data, but the section contains no baseline comparisons, ablation on the proximal step, or quantitative error analysis separating in-sample fitting from predictive performance, undermining the claim that the algorithm demonstrates practical superiority.
Authors: The referee correctly identifies that §5 currently lacks systematic controls. The reported experiments demonstrate feasibility on real-world regression and classification tasks but do not include the requested comparisons or ablations. We will revise §5 to add (i) baseline comparisons against standard SINDy, recursive least squares, and other sequential regression methods, (ii) an ablation that isolates the effect of the proximal step on non-Gaussian weight distributions, and (iii) separate in-sample versus out-of-sample error tables with quantitative metrics to clarify predictive performance. revision: yes
Circularity Check
No significant circularity; PAC claim rests on external functional analysis
full rationale
The paper claims a rigorous PAC learning guarantee derived from functional analysis applied to the randomized predictor distribution, with sequential updates via gradient descent and proximal steps to preserve valid density. This theoretical step is presented as independent of the specific fitted weights or data realizations, drawing on standard mathematical theory rather than self-referential definitions or prior self-citations. Experimental results on real-world regression and classification tasks are reported separately as empirical validation. No equations or sections in the provided material reduce a claimed prediction or uniqueness result to a fitted input or self-citation by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The data has a time-dependent structure suitable for sequential probabilistic prediction.
- domain assumption Functional analysis can be applied to prove PAC learning bounds for the randomized predictor distribution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
gt := arg min { Θ(x,y)(g) + 1/(2η) ||g−gt−1||² } ... prox_ηΨ [gt−1 − η ∇c]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 2.1. A H class of admissible predictors admits the sequential PAC property
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Attouch, Hedy and Juan Peypouquet (2016). “The Rate of Convergence of Nesterov’s Accelerated Forward-Backward Method is Actually Faster Than 1 /k2”. In: SIAM Journal on Optimization 26.3, pp. 1824–1834. doi: 10.1137/15M1046095
-
[2]
Boyd, Stephen and Lieven Vandenberghe (2004). Convex Optimization. Cambridge University Press
work page 2004
-
[3]
Brunton, Steven L., Joshua L. Proctor, and J. Nathan Kutz (2016). “Discovering governing equations from data by sparse identification of nonlinear dynamical systems”. In: Proceedings of the National Academy of Sciences 113.15, pp. 3932–3937. doi: 10 . 1073 / pnas . 1517384113. eprint: https : //www.pnas.org/doi/pdf/10.1073/pnas.1517384113 . url: https://w...
-
[4]
Regression on the basis of nonstationary Gaussian processes with Bayesian regularization
Burnaev, E. V., M. E. Panov, and A. A. Zaytsev (June 2016). “Regression on the basis of nonstationary Gaussian processes with Bayesian regularization”. In: Journal of Communications Technology and Electronics 61.6, pp. 661–671. issn: 1555-6557. doi: 10.1134/S1064226916060061
-
[5]
Prediction, Learning, and Games
Cesa-Bianchi, Nicolo and Gabor Lugosi (2006). Prediction, Learning, and Games . USA: Cambridge University Press. isbn: 0521841089
work page 2006
-
[6]
Online Passive-Aggressive Algorithms
Crammer, Koby, Ofer Dekel, et al. (Dec. 2006). “Online Passive-Aggressive Algorithms”. In: J. Mach. Learn. Res. 7, pp. 551–585. issn: 1532-4435
work page 2006
-
[7]
Online classification on a budget
Crammer, Koby, Jaz Kandola, and Yoram Singer (2003). “Online classification on a budget”. In: Pro- ceedings of the 17th International Conference on Neural Information Processing Systems . NIPS’03
work page 2003
-
[8]
Confidence-weighted linear classifi- cation
Dredze, Mark, Koby Crammer, and Fernando Pereira (2008). “Confidence-weighted linear classifi- cation”. In: Proceedings of the 25th International Conference on Machine Learning . ICML ’08
work page 2008
-
[9]
Helsinki, Finland: Association for Computing Machinery, pp. 264–271. isbn: 9781605582054. doi: 10.1145/1390156.1390190. url: https://doi.org/10.1145/1390156.1390190
- [10]
-
[11]
Gama, Jo˜ ao et al. (2004). “Learning with Drift Detection”. In: Advances in Artificial Intelligence – SBIA 2004 . Ed. by Ana L. C. Bazzan and Sofiane Labidi. Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 286–295. isbn: 978-3-540-28645-5
work page 2004
-
[12]
SPLICE-2 Comparative Evaluation: Electricity Pricing
Harries, M. (1999). “SPLICE-2 Comparative Evaluation: Electricity Pricing”. In: Technical report
work page 1999
-
[13]
Forecasting Unemployment via Machine Learning: The use of Average Win- dows Forecasts
Ho, Tsung-Wu (2022). “Forecasting Unemployment via Machine Learning: The use of Average Win- dows Forecasts”. In: SSRN Electron. J
work page 2022
-
[14]
Kivinen, J., A.J. Smola, and R.C. Williamson (2004). “Online learning with kernels”. In: IEEE Trans- actions on Signal Processing 52.8, pp. 2165–2176. doi: 10.1109/TSP.2004.830991
-
[15]
Large Scale Online Kernel Learning
Lu, Jing et al. (2016). “Large Scale Online Kernel Learning”. In:Journal of Machine Learning Research 17.47, pp. 1–43. url: http://jmlr.org/papers/v17/14-148.html
work page 2016
-
[16]
Large-scale online kernel learning with random feature reparame- terization
Nguyen, Tu Dinh et al. (2017). “Large-scale online kernel learning with random feature reparame- terization”. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence . IJCAI’17. Melbourne, Australia: AAAI Press, pp. 2543–2549. isbn: 9780999241103
work page 2017
-
[17]
Convex optimization in normed spaces: Theory, methods and examples
Peypouquet, Juan (2015). Convex optimization in normed spaces: Theory, methods and examples . English. SpringerBriefs in Optimization. Springer. isbn: 978-3-319-13709-4
work page 2015
-
[18]
Random features for large-scale kernel machines
Rahimi, Ali and Benjamin Recht (2007). “Random features for large-scale kernel machines”. In: Pro- ceedings of the 21st International Conference on Neural Information Processing Systems . NIPS’07
work page 2007
-
[19]
Relax and randomize: from value to algorithms
Rakhlin, Alexander, Ohad Shamir, and Karthik Sridharan (2012). “Relax and randomize: from value to algorithms”. In: Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2 . NIPS’12. Lake Tahoe, Nevada: Curran Associates Inc., pp. 2141–2149
work page 2012
-
[20]
Rasmussen, Carl Edward and Christopher K. I. Williams (2005). Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning) . The MIT Press. isbn: 026218253X. 26 REFERENCES
work page 2005
-
[21]
The perceptron: a probabilistic model for information storage and organiza- tion in the brain
Rosenblatt, Frank (1958). “The perceptron: a probabilistic model for information storage and organiza- tion in the brain.” In:Psychological review 65 6, pp. 386–408.url: https://api.semanticscholar. org/CorpusID:12781225
work page 1958
-
[22]
Sequence to sequence learning with neural networks
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le (2014). “Sequence to sequence learning with neural networks”. In: Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 . NIPS’14. Montreal, Canada: MIT Press, pp. 3104–3112
work page 2014
-
[23]
Vovk, Vladimir, Alexander Gammerman, and Glenn Shafer (Jan. 2022). Algorithmic Learning in a Random World, Second Edition. English (US). Publisher Copyright: © Springer Verlag New York, Inc. 2005. Springer International Publishing. isbn: 9783031066481. doi: 10 . 1007 / 978 - 3 - 031 - 06649-8
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.