ChangeBridge: Spatiotemporal Image Generation with Multimodal Controls for Remote Sensing
Pith reviewed 2026-05-19 06:53 UTC · model grok-4.3
The pith
ChangeBridge generates post-event remote sensing scenes that are spatially and temporally coherent using a drift-asynchronous diffusion bridge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a drift-asynchronous diffusion bridge, built from composed bridge initialization, asynchronous drift diffusion, and drift-aware denoising, allows generation of post-event scenes conditioned on pre-event images and multimodal event controls that maintain both spatial alignment and temporal coherence.
What carries the argument
A drift-asynchronous diffusion bridge that uses a pixel-wise drift map to assign different drift magnitudes to event-driven changes and cross-temporal variations during the pre-to-post transition.
If this is right
- ChangeBridge produces better cross-spatiotemporal aligned scenarios than existing methods.
- It has potential applications in land-use planning.
- It can act as a data generation engine for various change detection tasks.
Where Pith is reading between the lines
- This separation of change types could help in modeling complex scenarios like climate-induced shifts combined with human activities.
- Similar drift mechanisms might improve generation tasks in other time-series imaging domains such as medical scans.
- Integrating more control modalities could further enhance precision in predicting specific outcomes.
Load-bearing premise
Multimodal event controls together with the pixel-wise drift map separate event-driven changes from cross-temporal variations without introducing uncorrectable artifacts in the denoising process.
What would settle it
Comparing generated images against actual post-event observations and finding systematic mismatches in alignment or introduced artifacts in areas of mixed change types.
Figures






read the original abstract
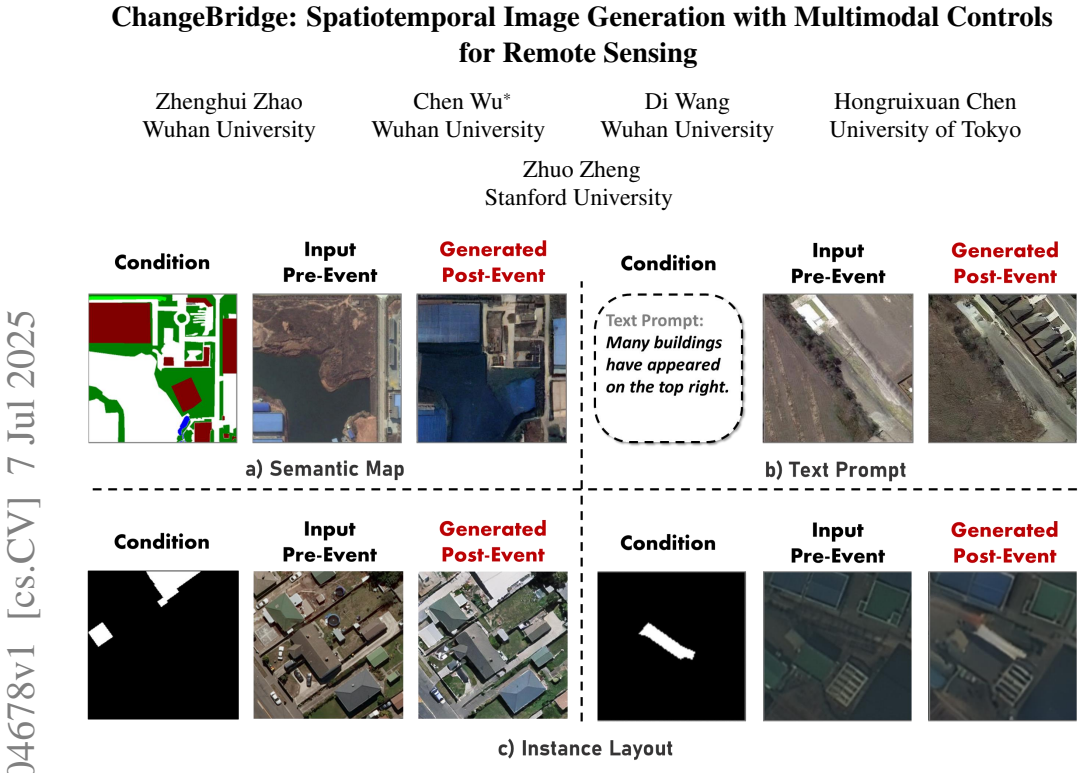
Spatiotemporal image generation is a highly meaningful task, which can generate future scenes conditioned on given observations. However, existing change generation methods can only handle event-driven changes (e.g., new buildings) and fail to model cross-temporal variations (e.g., seasonal shifts). In this work, we propose ChangeBridge, a conditional spatiotemporal image generation model for remote sensing. Given pre-event images and multimodal event controls, ChangeBridge generates post-event scenes that are both spatially and temporally coherent. The core idea is a drift-asynchronous diffusion bridge. Specifically, it consists of three main modules: a) Composed Bridge Initialization, which replaces noise initialization. It starts the diffusion from a composed pre-event state, modeling a diffusion bridge process. b) Asynchronous Drift Diffusion, which uses a pixel-wise drift map, assigning different drift magnitudes to event and temporal evolution. This enables differentiated generation during the pre-to-post transition. c) Drift-Aware Denoising, which embeds the drift map into the denoising network, guiding drift-aware reconstruction. Experiments show that ChangeBridge can generate better cross-spatiotemporal aligned scenarios compared to state-of-the-art methods. Additionally, ChangeBridge shows great potential for land-use planning and as a data generation engine for a series of change detection tasks. Code is available at https://github.com/zhenghuizhao/ChangeBridge
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChangeBridge, a conditional diffusion model for spatiotemporal image generation in remote sensing. Given pre-event images and multimodal event controls, it generates post-event scenes via a drift-asynchronous diffusion bridge comprising composed bridge initialization (replacing standard noise), asynchronous drift diffusion (using a pixel-wise drift map to assign differentiated magnitudes to event-driven changes versus cross-temporal variations), and drift-aware denoising (embedding the map into the network). The central claim is that this produces better cross-spatiotemporal alignment than existing methods, with applications to land-use planning and synthetic data for change detection; code is released.
Significance. If the drift map successfully isolates asynchronous changes without uncorrectable residuals, the approach could meaningfully extend conditional diffusion to remote-sensing scenarios that mix abrupt events and gradual temporal shifts, improving upon methods limited to event-driven changes only. Open-sourced code is a clear strength for reproducibility.
major comments (2)
- [Abstract / Experiments] Abstract and experimental section: the claim of superior cross-spatiotemporal alignment is stated without any reported quantitative metrics (e.g., FID, PSNR, change-detection F1 on generated pairs), ablation studies, or baseline details. This leaves the headline result unverified from the provided text.
- [Asynchronous Drift Diffusion] Asynchronous Drift Diffusion module: the pixel-wise drift map is presented as the mechanism that separates event-driven changes from temporal evolution, yet no ablation (e.g., uniform-drift control) or direct validation (per-pixel fidelity to ground-truth change masks, or downstream change-detection accuracy on generated pairs) is described to confirm separation succeeds rather than merely amplifying conditioning strength.
minor comments (1)
- [Composed Bridge Initialization] Clarify the precise construction of the composed pre-event state in the initialization module and how multimodal controls are encoded before being fed to the drift map.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, indicating where revisions will be made to improve the clarity and verifiability of our results.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental section: the claim of superior cross-spatiotemporal alignment is stated without any reported quantitative metrics (e.g., FID, PSNR, change-detection F1 on generated pairs), ablation studies, or baseline details. This leaves the headline result unverified from the provided text.
Authors: The current manuscript emphasizes qualitative visual comparisons in the experiments to illustrate the advantages in cross-spatiotemporal coherence. However, we agree that quantitative support would strengthen the claims. In the revised version, we will report standard metrics such as FID and PSNR for image quality, as well as change-detection F1 scores on pairs generated by ChangeBridge versus baselines. We will also expand the experimental section with explicit baseline details and additional ablations. revision: yes
-
Referee: [Asynchronous Drift Diffusion] Asynchronous Drift Diffusion module: the pixel-wise drift map is presented as the mechanism that separates event-driven changes from temporal evolution, yet no ablation (e.g., uniform-drift control) or direct validation (per-pixel fidelity to ground-truth change masks, or downstream change-detection accuracy on generated pairs) is described to confirm separation succeeds rather than merely amplifying conditioning strength.
Authors: We recognize that additional evidence is required to validate the specific contribution of the pixel-wise drift map. To address this, we will add an ablation experiment using a uniform drift map as a control. Furthermore, we will include quantitative validation by measuring per-pixel agreement with ground-truth change masks and assessing the accuracy of change detection models trained on the synthetically generated data. These additions will help demonstrate that the asynchronous drift mechanism provides meaningful separation beyond enhanced conditioning. revision: yes
Circularity Check
No significant circularity in architectural derivation or claims
full rationale
The paper presents ChangeBridge as a new conditional diffusion model with three explicitly described modules (Composed Bridge Initialization replacing noise, Asynchronous Drift Diffusion via a pixel-wise drift map derived from multimodal controls and pre-event images, and Drift-Aware Denoising). These are introduced as independent design choices rather than derived quantities. No equations are shown that reduce outputs to inputs by construction, no parameters are fitted to a data subset and then relabeled as predictions, and no uniqueness theorems or ansatzes are imported via self-citation to force the central construction. The abstract's claim of better cross-spatiotemporal alignment is positioned as an experimental outcome, not a definitional necessity. This matches the default expectation for most papers and yields no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal controls can be injected into the diffusion process to guide both spatial and temporal coherence.
invented entities (1)
-
pixel-wise drift map
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
core idea is a drift-asynchronous diffusion bridge... Asynchronous Drift Diffusion, which uses a pixel-wise drift map, assigning different drift magnitudes to event and temporal evolution
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stochastic Brownian bridge process... p(zt|z0, zT) = N((1-t/T)z0 + t/T zT, t(T-t)/T I)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Orkhan Baghirli, Hamid Askarov, Imran Ibrahimli, Is- mat Bakhishov, and Nabi Nabiyev. Satdm: Synthe- sizing realistic satellite image with semantic layout conditioning using diffusion models. arXiv preprint arXiv:2309.16812, 2023. 1
-
[2]
A transformer-based siamese network for change de- tection
Wele Gedara Chaminda Bandara and Vishal M Patel. A transformer-based siamese network for change de- tection. In IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium , pages 207–210. IEEE, 2022. 7
work page 2022
-
[3]
N. Bourdis, D. Marraud, and H. Sahbi. Constrained optical flow for aerial image change detection. In2011 IEEE International Geoscience and Remote Sensing Symposium, pages 4176–4179. IEEE, 2011. 3
work page 2011
-
[4]
Machine learning al- gorithms for urban land use planning: A review
V Chaturvedi and WT de Vries. Machine learning al- gorithms for urban land use planning: A review. Ur- ban Science, 5(3):68, 2021. 3
work page 2021
-
[5]
Spectral-cascaded diffu- sion model for remote sensing image spectral super- resolution
Bowen Chen, Liqin Liu, Chenyang Liu, Zhengxia Zou, and Zhenwei Shi. Spectral-cascaded diffu- sion model for remote sensing image spectral super- resolution. IEEE Transactions on Geoscience and Re- mote Sensing, 2024. 1
work page 2024
-
[6]
Hao Chen and Zhenwei Shi. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sensing, 12 (10):1662, 2020. 5, 7
work page 2020
-
[7]
Remote sens- ing image change detection with transformers
Hao Chen, Zipeng Qi, and Zhenwei Shi. Remote sens- ing image change detection with transformers. IEEE Transactions on Geoscience and Remote Sensing, 60: 1–14, 2021. 7
work page 2021
-
[8]
A rule-based model of urban land use and economic growth
A T Crooks, N W Gibin, and J J Heppenstall. A rule-based model of urban land use and economic growth. International Journal of Geographical Infor- mation Science, 24(2):311–331, 2010. 3
work page 2010
-
[9]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems , 34:8780– 8794, 2021. 2
work page 2021
-
[10]
Taming transformers for high-resolution image syn- thesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image syn- thesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 12873–12883, 2021. 6 9
work page 2021
-
[11]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Un- terthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural infor- mation processing systems, 30, 2017. 6
work page 2017
-
[12]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020. 2, 5
work page 2020
-
[13]
Resolving multi-condition confusion for finetuning-free personalized image gen- eration
Qihan Huang, Siming Fu, Jinlong Liu, Hao Jiang, Yipeng Yu, and Jie Song. Resolving multi-condition confusion for finetuning-free personalized image gen- eration. arXiv preprint arXiv:2409.17920, 2024. 5
-
[14]
Shunping Ji, Shiqing Wei, and Meng Lu. Fully con- volutional networks for multisource building extrac- tion from an open aerial and satellite imagery data set. IEEE Transactions on Geoscience and Remote Sens- ing, 57(1):574–586, 2018. 5
work page 2018
-
[15]
Samar Khanna, Patrick Liu, Linqi Zhou, Chenlin Meng, Robin Rombach, Marshall Burke, David Lo- bell, and Stefano Ermon. Diffusionsat: A generative foundation model for satellite imagery. arXiv preprint arXiv:2312.03606, 2023. 1
-
[16]
Bbdm: Image-to-image translation with brownian bridge dif- fusion models
Bo Li, Kaitao Xue, Bin Liu, and Yu-Kun Lai. Bbdm: Image-to-image translation with brownian bridge dif- fusion models. In Proceedings of the IEEE/CVF con- ference on computer vision and pattern Recognition , pages 1952–1961, 2023. 2, 3
work page 1952
-
[17]
Open-cd: A comprehensive toolbox for change detection
Kaiyu Li, Jiawei Jiang, Andrea Codegoni, Chengxi Han, Yupeng Deng, Keyan Chen, Zhuo Zheng, Hao Chen, Zhengxia Zou, Zhenwei Shi, et al. Open-cd: A comprehensive toolbox for change detection. arXiv preprint arXiv:2407.15317, 2024. 7
-
[18]
Gligen: Open-set grounded text-to- image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to- image generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 22511–22521, 2023. 2
work page 2023
-
[19]
Diverse hyperspectral remote sens- ing image synthesis with diffusion models
Liqin Liu, Bowen Chen, Hao Chen, Zhengxia Zou, and Zhenwei Shi. Diverse hyperspectral remote sens- ing image synthesis with diffusion models. IEEE Transactions on Geoscience and Remote Sensing, 61: 1–16, 2023. 1
work page 2023
-
[20]
A diffusion pro- cess and its applications to detecting a change in the drift of brownian motion
Moshe Pollak and David Siegmund. A diffusion pro- cess and its applications to detecting a change in the drift of brownian motion. Biometrika, 72(2):267–280,
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 6
work page 2021
-
[22]
Spatially explicit simulation of land use/land cover changes: Current coverage and future prospects
Y Ren, Y L ¨u, A Comber, B Fu, P Harris, and L Wu. Spatially explicit simulation of land use/land cover changes: Current coverage and future prospects. Land Use Policy, 80:324–336, 2019. 3
work page 2019
-
[23]
High- resolution image synthesis with latent diffusion mod- els
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High- resolution image synthesis with latent diffusion mod- els. In CVPR, 2022. 2, 3, 6
work page 2022
-
[24]
MS Roodposhti, J Aryal, and BA Bryan. A novel al- gorithm for calculating transition potential in cellular automata models of land-use/cover change. Science of the Total Environment, 674:290–303, 2019. 3
work page 2019
-
[25]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023. 2, 6
work page 2023
-
[26]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. Advances in neural in- formation processing systems, 29, 2016. 6
work page 2016
-
[27]
Unit-ddpm: Unpaired image translation with denoising diffusion probabilistic models,
Hiroshi Sasaki, Chris G Willcocks, and Toby P Breckon. Unit-ddpm: Unpaired image translation with denoising diffusion probabilistic models. arXiv preprint arXiv:2104.05358, 2021. 2
-
[28]
S2looking: A satellite side-looking dataset for build- ing change detection
Li Shen, Yao Lu, Hao Chen, Hao Wei, Donghai Xie, Jiabao Yue, Rui Chen, Shouye Lv, and Bitao Jiang. S2looking: A satellite side-looking dataset for build- ing change detection. Remote Sensing, 13(24):5094,
-
[29]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021. 2
work page 2021
-
[30]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In ICLR, 2021. 2, 5
work page 2021
-
[31]
Crs-diff: Con- trollable generative remote sensing foundation model
Datao Tang, Xiangyong Cao, Xingsong Hou, Zhongyuan Jiang, and Deyu Meng. Crs-diff: Con- trollable generative remote sensing foundation model. arXiv e-prints, pages arXiv–2403, 2024. 1
work page 2024
-
[32]
Kai Tang and Jin Chen. Changeanywhere: Sam- ple generation for remote sensing change detection via semantic latent diffusion model. arXiv preprint arXiv:2404.08892, 2024. 3
-
[33]
X Tong, H Liu, and Y Li. A statistical model for land use and land cover change prediction: A case study of urban growth in the beijing metropolitan area. Envi- ronmental Modeling & Software , 153:105418, 2022. 3 10
work page 2022
-
[34]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017. 5
work page 2017
-
[35]
On the theory of the brownian motion ii
Ming Chen Wang and George Eugene Uhlenbeck. On the theory of the brownian motion ii. Reviews of mod- ern physics, 17(2-3):323, 1945. 3
work page 1945
-
[36]
Elite: Encod- ing visual concepts into textual embeddings for cus- tomized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encod- ing visual concepts into textual embeddings for cus- tomized text-to-image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15943–15953, 2023. 6
work page 2023
-
[37]
arXiv preprint arXiv:2010.05687 (2020)
Kunping Yang, Gui-Song Xia, Zicheng Liu, Bo Du, Wen Yang, Marcello Pelillo, and Liangpei Zhang. Se- mantic change detection with asymmetric siamese net- works. arXiv preprint arXiv:2010.05687, 2020. 5
-
[38]
Yang Yang, Wen Wang, Liang Peng, Chaotian Song, Yao Chen, Hengjia Li, Xiaolong Yang, Qinglin Lu, Deng Cai, Boxi Wu, et al. Lora-composer: Leverag- ing low-rank adaptation for multi-concept customiza- tion in training-free diffusion models. arXiv preprint arXiv:2403.11627, 2024. 2
-
[39]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Huan Ye, Jian Zhang, Shu Liu, Xinzhu Han, and Wen- jun Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint, arXiv:2308.06721, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Video probabilistic diffusion models in pro- jected latent space
Sihyun Yu, Kihyuk Sohn, Subin Kim, and Jinwoo Shin. Video probabilistic diffusion models in pro- jected latent space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 18456–18466, 2023. 2
work page 2023
-
[41]
Metaearth: A generative founda- tion model for global-scale remote sensing image gen- eration
Zhiping Yu, Chenyang Liu, Liqin Liu, Zhenwei Shi, and Zhengxia Zou. Metaearth: A generative founda- tion model for global-scale remote sensing image gen- eration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1
work page 2024
-
[42]
Qi Zang, Jiayi Yang, Shuang Wang, Dong Zhao, Wen- jun Yi, and Zhun Zhong. Changediff: A multi- temporal change detection data generator with flexible text prompts via diffusion model, 2024. 1, 3
work page 2024
-
[43]
Un- balanced feature transport for exemplar-based image translation
Fangneng Zhan, Yingchen Yu, Kaiwen Cui, Gongjie Zhang, Shijian Lu, Jianxiong Pan, Changgong Zhang, Feiying Ma, Xuansong Xie, and Chunyan Miao. Un- balanced feature transport for exemplar-based image translation. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 15028–15038, 2021. 6
work page 2021
-
[44]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision , pages 3836– 3847, 2023. 5, 6
work page 2023
-
[45]
Inversion-based style transfer with diffusion models
Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 10146– 10156, 2023. 2
work page 2023
-
[46]
Change is everywhere: Single-temporal supervised object change detection in remote sensing imagery
Zhuo Zheng, Ailong Ma, Liangpei Zhang, and Yan- fei Zhong. Change is everywhere: Single-temporal supervised object change detection in remote sensing imagery. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 15193–15202. IEEE, 2021. 7
work page 2021
-
[47]
Zhuo Zheng, Shiqi Tian, Ailong Ma, Liangpei Zhang, and Yanfei Zhong. Scalable multi-temporal re- mote sensing change data generation via simulating stochastic change process. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 21818–21827, 2023. 3
work page 2023
-
[48]
Changen2: Multi-temporal remote sensing generative change foundation model
Zhuo Zheng, Stefano Ermon, Dongjun Kim, Liangpei Zhang, and Yanfei Zhong. Changen2: Multi-temporal remote sensing generative change foundation model. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1, 3
work page 2024
-
[49]
Denoising diffusion bridge models.arXiv preprint arXiv:2309.16948,
Linqi Zhou, Aaron Lou, Samar Khanna, and Stefano Ermon. Denoising diffusion bridge models. arXiv preprint arXiv:2309.16948, 2023. 2 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.