AI Feedback Enhances Community-Based Content Moderation through Engagement with Counterarguments
Pith reviewed 2026-05-19 05:18 UTC · model grok-4.3
The pith
AI-generated argumentative feedback produces the largest gains in quality for community-sourced notes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
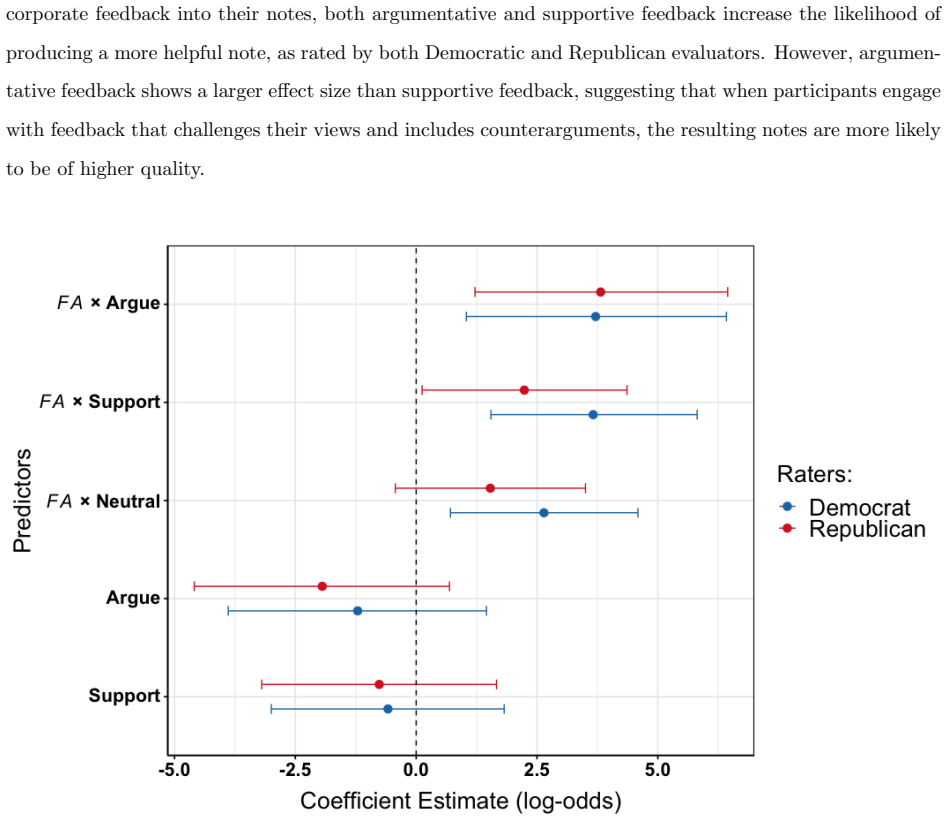
Participants who received AI-generated argumentative feedback on their Community Notes and revised accordingly produced notes of measurably higher quality than those who received supportive or neutral feedback. The improvement is attributed to the requirement that writers directly engage with counterarguments, which leads to more balanced and better-supported content. The study therefore concludes that an AI-assisted hybrid framework can enhance the effectiveness of community-based moderation by incorporating diverse perspectives through targeted feedback.
What carries the argument
The AI-generated argumentative feedback loop that presents counterarguments to a draft note and prompts the writer to revise in response.
If this is right
- Note quality increases after any AI feedback but rises most after argumentative feedback.
- Direct engagement with opposing views improves the balance and support of crowdsourced fact-checks.
- Hybrid human-AI systems can address delays and partisan bias in existing community moderation.
- Design choices that prioritize counterargument feedback yield stronger collective intelligence outcomes.
Where Pith is reading between the lines
- Platforms could insert short AI feedback steps into existing note-writing interfaces without changing user incentives.
- The same feedback mechanism might transfer to other crowdsourced verification tasks such as Wikipedia edit reviews or citizen-science data labeling.
- Long-term deployment would require monitoring whether repeated exposure to argumentative feedback changes writers' willingness to contribute at all.
Load-bearing premise
The observed quality gains come from genuine engagement with the counterarguments rather than from the simple act of revising or from unmeasured differences in how the feedback types were generated.
What would settle it
A follow-up trial in which participants revise notes after receiving only generic revision prompts (no content-specific feedback) and still show quality gains equal to or larger than those produced by argumentative feedback.
Figures






read the original abstract
Today, social media platforms are significant sources of news and political communication, but their role in spreading misinformation has raised significant concerns. In response, these platforms have implemented various content moderation strategies. One such method, Community Notes (formerly Birdwatch) on X (formerly Twitter), relies on crowdsourced fact-checking and has gained traction. However, it faces challenges such as partisan bias and delays in verification. This study explores an AI-assisted hybrid moderation framework in which participants receive AI-generated feedback, supportive, neutral, or argumentative, on their notes and are asked to revise them accordingly. The results show that incorporating feedback improves note quality, with the most substantial gains coming from argumentative feedback. This underscores the value of diverse perspectives and direct engagement in human-AI collective intelligence. The research contributes to ongoing discussions about AI's role in political content moderation, highlighting the potential of generative AI and the importance of informed design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an AI-assisted hybrid moderation framework for Community Notes on X, in which participants receive one of three types of AI-generated feedback (supportive, neutral, or argumentative) on their notes and are asked to revise them. It reports that feedback incorporation improves note quality, with the largest gains under argumentative feedback, and argues this demonstrates the value of engaging with counterarguments in human-AI collective intelligence for content moderation.
Significance. If the central empirical result holds after addressing design issues, the work would be moderately significant for platform moderation research. It offers a concrete test of how generative AI can supply diverse perspectives to crowdsourced fact-checking, potentially addressing delays and partisan bias in systems like Community Notes, and contributes to broader discussions of AI-augmented collective intelligence in political communication.
major comments (2)
- [Methods] The experimental design (likely described in the Methods section) compares three feedback conditions but omits a no-feedback revision control arm and does not report measures or statistical controls for revision effort, time-on-task, or number of edits. This leaves open the possibility that quality gains attributed to argumentative feedback are artifacts of generic revision incentives rather than engagement with counterarguments, directly undermining the causal claim in the abstract and results.
- [Results] The Results section (and abstract) reports directional improvements in note quality without providing sample size, statistical tests, effect sizes, controls for confounds, or the operational definition and measurement of 'note quality.' These omissions make it impossible to assess whether the data support the claim that argumentative feedback produces the most substantial gains.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly stating the sample size, how note quality was scored, and the key statistical result supporting the 'most substantial gains' claim.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major concern point by point below and have revised the manuscript to improve reporting and acknowledge design limitations where possible.
read point-by-point responses
-
Referee: [Methods] The experimental design (likely described in the Methods section) compares three feedback conditions but omits a no-feedback revision control arm and does not report measures or statistical controls for revision effort, time-on-task, or number of edits. This leaves open the possibility that quality gains attributed to argumentative feedback are artifacts of generic revision incentives rather than engagement with counterarguments, directly undermining the causal claim in the abstract and results.
Authors: We agree that a no-feedback control arm would strengthen causal inference by separating the effects of receiving feedback from the effects of revision alone. Our design prioritized comparisons across feedback types (supportive, neutral, argumentative), all of which prompted revision, allowing relative differences in quality gains to be attributed to feedback content. We have added an explicit discussion of this design decision and its implications to the Limitations section. However, we did not collect time-on-task or edit-count data during the original experiment and therefore cannot add statistical controls for revision effort. We have updated the Limitations section to note this gap and recommend that future studies include such measures. revision: partial
-
Referee: [Results] The Results section (and abstract) reports directional improvements in note quality without providing sample size, statistical tests, effect sizes, controls for confounds, or the operational definition and measurement of 'note quality.' These omissions make it impossible to assess whether the data support the claim that argumentative feedback produces the most substantial gains.
Authors: We have revised the Results section to include the missing details: the total sample size, the operational definition of note quality (a composite of accuracy, clarity, and sourcing rated by blinded coders), the statistical tests performed (including pre-post comparisons and between-condition ANOVA), effect sizes, and basic demographic controls. These elements were summarized in supplementary materials but have now been integrated into the main text and abstract for transparency. revision: yes
- The original experiment did not collect data on revision effort, time-on-task, or number of edits, so these specific controls cannot be added retrospectively.
Circularity Check
No circularity: empirical experiment with independent outcome measures
full rationale
The paper describes a controlled experiment in which participants revise Community Notes after receiving one of three AI feedback conditions (supportive, neutral, argumentative) and quality is then scored by independent raters. No equations, fitted parameters, or first-principles derivations are present; results are obtained from new data collection rather than by re-expressing inputs. No self-citation is invoked to justify uniqueness or to close a logical loop. The design is therefore self-contained against external benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The results show that incorporating feedback improves note quality, with the most substantial gains coming from argumentative feedback.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Feedback Acceptance rate (FA), a metric that quantifies the extent to which participants incorporated the provided feedback into their final submissions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Characterizing AI Fact-Checkers and Their Contributions on Community Notes
AI writers account for 14.2% of Community Notes submissions with high responsiveness and coverage but lower helpfulness classification rates than human experts.
-
Beyond Community Notes: A Framework for Understanding and Building Crowdsourced Context Systems for Social Media
The authors conduct a systematic literature review and real-world analysis to define Crowdsourced Context Systems and map a six-aspect design space with normative implications.
Reference graph
Works this paper leans on
-
[1]
Exposure to ideologically diverse news and opinion on facebook.Science, 348(6239):1130–1132, 2015
Eytan Bakshy, Solomon Messing, and Lada A Adamic. Exposure to ideologically diverse news and opinion on facebook.Science, 348(6239):1130–1132, 2015
work page 2015
-
[2]
Cass R Sunstein.Echo chambers: Bush v. Gore, impeachment, and beyond. Princeton University Press Princeton, NJ, 2001
work page 2001
-
[3]
Gary King, Benjamin Schneer, and Ariel White. How the news media activate public expression and influence national agendas.Science, 358(6364):776–780, 2017
work page 2017
-
[4]
Hunt Allcott and Matthew Gentzkow. Social media and fake news in the 2016 election.Journal of economic perspectives, 31(2):211–236, 2017. 19
work page 2016
-
[5]
Ciara M Greene, Robert A Nash, and Gillian Murphy. Misremembering brexit: Partisan bias and individual predictors of false memories for fake news stories among brexit voters.Memory, 29(5):587– 604, 2021
work page 2021
-
[6]
Director-general speeches: Munich security conference
World Health Organization. Director-general speeches: Munich security conference. Accessed: April 3, 2024
work page 2024
-
[7]
Ofra Klein. Mobilising the mob: The multifaceted role of social media in the january 6th us capitol attack.Javnost-The Public, 32(1):33–50, 2025
work page 2025
-
[8]
Joel Kaplan. More speech and fewer mistakes.https://about.fb.com/news/2025/01/ meta-more-speech-fewer-mistakes/, 2025. Accessed: (February 25, 2025)
work page 2025
-
[9]
X.com community notes guide.https://communitynotes.x.com/guide/en. Accessed: April 3, 2024
work page 2024
-
[10]
The quest to automate fact-checking
Naeemul Hassan, Bill Adair, James T Hamilton, Chengkai Li, Mark Tremayne, Jun Yang, and Cong Yu. The quest to automate fact-checking. InProceedings of the 2015 computation+ journalism symposium. Citeseer, 2015
work page 2015
-
[11]
Emily Vogels, Andrew Perrin, and Monica Anderson. Most americans think social me- dia sites censor political viewpoints.https://www.pewresearch.org/internet/2020/08/19/ most-americans-think-social-media-sites-censor-political-viewpoints/, 2020. Accessed: February 26, 2025
work page 2020
-
[12]
Taha Yasseri and Filippo Menczer. Can crowdsourcing rescue the social marketplace of ideas?Com- munications of the ACM, 66(9):42–45, 2023
work page 2023
-
[13]
Jennifer Allen, Cameron Martel, and David G Rand. Birds of a feather don’t fact-check each other: Partisanship and the evaluation of news in twitter’s birdwatch crowdsourced fact-checking program. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pages 1–19, 2022
work page 2022
-
[14]
Rated not helpful; how x’s community notes system falls short on misleading election claims, 2024
Center for Countering Digital Hate. Rated not helpful; how x’s community notes system falls short on misleading election claims, 2024. New research by CCDH shows that X’s Community Notes are failing to counter false and misleading claims about the US election
work page 2024
-
[15]
Bao Tran Truong, Sangyeon Kim, Gianluca Nogara, Enrico Verdolotti, Erfan Samieyan Sahneh, Florian Saurwein, Natascha Just, Luca Luceri, Silvia Giordano, and Filippo Menczer. Delayed takedown of illegal content on social media makes moderation ineffective.arXiv preprint arXiv:2502.08841, 2025
-
[16]
Gianluca Demartini, Stefano Mizzaro, and Damiano Spina. Human-in-the-loop artificial intelligence for fighting online misinformation: Challenges and opportunities.IEEE Data Eng. Bull., 43(3):65–74, 2020. 20
work page 2020
-
[17]
"Liar, Liar Pants on Fire": A New Benchmark Dataset for Fake News Detection
William Yang Wang. ”liar, liar pants on fire”: A new benchmark dataset for fake news detection.arXiv preprint arXiv:1705.00648, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
FEVER : a Large-scale Dataset for Fact Extraction and VER ification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification.arXiv preprint arXiv:1803.05355, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Bertie Vidgen and Leon Derczynski. Directions in abusive language training data, a systematic review: Garbage in, garbage out.Plos one, 15(12):e0243300, 2020
work page 2020
-
[20]
Like trainer, like bot? inheritance of bias in algorithmic content moderation
Reuben Binns, Michael Veale, Max Van Kleek, and Nigel Shadbolt. Like trainer, like bot? inheritance of bias in algorithmic content moderation. InSocial Informatics: 9th International Conference, SocInfo 2017, Oxford, UK, September 13-15, 2017, Proceedings, Part II 9, pages 405–415. Springer, 2017
work page 2017
-
[21]
Jason W Burton, Ezequiel Lopez-Lopez, Shahar Hechtlinger, Zoe Rahwan, Samuel Aeschbach, Michiel A Bakker, Joshua A Becker, Aleks Berditchevskaia, Julian Berger, Levin Brinkmann, et al. How large language models can reshape collective intelligence.Nature human behaviour, 8(9):1643–1655, 2024
work page 2024
-
[22]
Ai-enhanced collective intelligence.Patterns, 5(11), 2024
Hao Cui and Taha Yasseri. Ai-enhanced collective intelligence.Patterns, 5(11), 2024
work page 2024
-
[23]
Llm-generated messages can persuade humans on policy issues.Nature Communications, 16(1):6037, 2025
Hui Bai, Jan G Voelkel, Shane Muldowney, Johannes C Eichstaedt, and Robb Willer. Llm-generated messages can persuade humans on policy issues.Nature Communications, 16(1):6037, 2025
work page 2025
-
[24]
Kobi Hackenburg and Helen Margetts. Evaluating the persuasive influence of political microtargeting with large language models.Proceedings of the National Academy of Sciences, 121(24):e2403116121, 2024
work page 2024
-
[25]
Large language models can rate news outlet credibility.arXiv e-prints, pages arXiv–2304, 2023
Kai-Cheng Yang and Filippo Menczer. Large language models can rate news outlet credibility.arXiv e-prints, pages arXiv–2304, 2023
work page 2023
-
[26]
Dorian Quelle and Alexandre Bovet. The perils and promises of fact-checking with large language models.Frontiers in Artificial Intelligence, 7:1341697, 2024
work page 2024
-
[27]
Leveraging chatgpt for efficient fact-checking.PsyArXiv
Emma Hoes, Sacha Altay, and Juan Bermeo. Leveraging chatgpt for efficient fact-checking.PsyArXiv. April, 3, 2023
work page 2023
-
[28]
Elizaveta Kuznetsova, Mykola Makhortykh, Victoria Vziatysheva, Martha Stolze, Ani Baghumyan, and Aleksandra Urman. In generative ai we trust: can chatbots effectively verify political information? Journal of Computational Social Science, 8(1):15, 2025
work page 2025
-
[29]
arXiv preprint arXiv:2403.11169 , year=
Xinyi Zhou, Ashish Sharma, Amy X Zhang, and Tim Althoff. Correcting misinformation on social media with a large language model.arXiv preprint arXiv:2403.11169, 2024. 21
-
[30]
Supernotes: Driving consensus in crowd-sourced fact-checking
Soham De, Michiel A Bakker, Jay Baxter, and Martin Saveski. Supernotes: Driving consensus in crowd-sourced fact-checking. InProceedings of the ACM on Web Conference 2025, pages 3751–3761, 2025
work page 2025
-
[31]
arXiv preprint arXiv:2509.11052 , year=
Shuning Zhang, Linzhi Wang, Dai Shi, Yuwei Chuai, Jingruo Chen, Yunyi Chen, Yifan Wang, Yating Wang, Xin Yi, and Hewu Li. Commenotes: Synthesizing organic comments to support community-based fact-checking.arXiv preprint arXiv:2509.11052, 2025
-
[32]
Zhuoran Lu, Patrick Li, Weilong Wang, and Ming Yin. The effects of ai-based credibility indicators on the detection and spread of misinformation under social influence.Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2):1–27, 2022
work page 2022
-
[33]
Believe it or not: designing a human-ai partnership for mixed-initiative fact-checking
An T Nguyen, Aditya Kharosekar, Saumyaa Krishnan, Siddhesh Krishnan, Elizabeth Tate, Byron C Wallace, and Matthew Lease. Believe it or not: designing a human-ai partnership for mixed-initiative fact-checking. InProceedings of the 31st annual ACM symposium on user interface software and tech- nology, pages 189–199, 2018
work page 2018
-
[34]
Content moderation, ai, and the question of scale.Big Data & Society, 7(2):5, 2020
Tarleton Gillespie. Content moderation, ai, and the question of scale.Big Data & Society, 7(2):5, 2020
work page 2020
-
[35]
A new sociology of humans and machines.Nature Human Behaviour, 8(10):1864–1876, 2024
Milena Tsvetkova, Taha Yasseri, Niccolo Pescetelli, and Tobias Werner. A new sociology of humans and machines.Nature Human Behaviour, 8(10):1864–1876, 2024
work page 2024
-
[36]
The role of explainability in collaborative human-ai disinformation detection
Vera Schmitt, Luis-Felipe Villa-Arenas, NIls Feldhus, Joachim Meyer, Robert P Spang, and Sebastian M¨ oller. The role of explainability in collaborative human-ai disinformation detection. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2157–2174, 2024
work page 2024
-
[37]
Automation bias in intelligent time critical decision support systems
Mary L Cummings. Automation bias in intelligent time critical decision support systems. InDecision making in aviation, pages 289–294. Routledge, 2017
work page 2017
-
[38]
Matthew R DeVerna, Harry Yaojun Yan, Kai-Cheng Yang, and Filippo Menczer. Fact-checking in- formation from large language models can decrease headline discernment.Proceedings of the National Academy of Sciences, 121(50):e2322823121, 2024
work page 2024
-
[39]
Exploring the use of personalized ai for identifying misinformation on social media
Farnaz Jahanbakhsh, Yannis Katsis, Dakuo Wang, Lucian Popa, and Michael Muller. Exploring the use of personalized ai for identifying misinformation on social media. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–27, 2023
work page 2023
-
[40]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top- down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 22
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Yizhou Fan, Luzhen Tang, Huixiao Le, Kejie Shen, Shufang Tan, Yueying Zhao, Yuan Shen, Xinyu Li, and Dragan Gaˇ sevi´ c. Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance.British Journal of Educational Technology, 56(2):489– 530, 2025
work page 2025
-
[42]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. Your brain on chatgpt: Accumulation of cognitive debt when using an ai assistant for essay writing task.arXiv preprint arXiv:2506.08872, 4, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
The case for motivated reasoning.Psychological bulletin, 108(3):480–498, 1990
Ziva Kunda. The case for motivated reasoning.Psychological bulletin, 108(3):480–498, 1990
work page 1990
-
[44]
Biased ai improves human decision-making but reduces trust.arXiv preprint arXiv:2508.09297, 2025
Shiyang Lai, Junsol Kim, Nadav Kunievsky, Yujin Potter, and James Evans. Biased ai improves human decision-making but reduces trust.arXiv preprint arXiv:2508.09297, 2025
-
[45]
Junsol Kim, Zhao Wang, Haohan Shi, Hsin-Keng Ling, and James Evans. Differential impact from in- dividual versus collective misinformation tagging on the diversity of twitter (x) information engagement and mobility.Nature Communications, 16(1):973, 2025
work page 2025
-
[46]
Ofer Arazy, Oded Nov, Raymond Patterson, and Lisa Yeo. Information quality in wikipedia: The effects of group composition and task conflict.Journal of management information systems, 27(4):71–98, 2011
work page 2011
-
[47]
Dynamics of conflicts in wikipedia.PloS one, 7(6):e38869, 2012
Taha Yasseri, Robert Sumi, Andr´ as Rung, Andr´ as Kornai, and J´ anos Kert´ esz. Dynamics of conflicts in wikipedia.PloS one, 7(6):e38869, 2012
work page 2012
-
[48]
The wisdom of polarized crowds.Nature human behaviour, 3(4):329–336, 2019
Feng Shi, Misha Teplitskiy, Eamon Duede, and James A Evans. The wisdom of polarized crowds.Nature human behaviour, 3(4):329–336, 2019
work page 2019
-
[49]
Taha Yasseri. Computational sociology of humans and machines; conflict and collaboration.arXiv preprint arXiv:2412.14606, 2024
-
[50]
Aidan Combs, Graham Tierney, Brian Guay, Friedolin Merhout, Christopher A Bail, D Sunshine Hilly- gus, and Alexander Volfovsky. Anonymous cross-party conversations can decrease political polarization: A field experiment on a mobile chat platform.SocArXiv. September, 23, 2022
work page 2022
-
[51]
Lisa P Argyle, Christopher A Bail, Ethan C Busby, Joshua R Gubler, Thomas Howe, Christopher Ryt- ting, Taylor Sorensen, and David Wingate. Leveraging ai for democratic discourse: Chat interventions can improve online political conversations at scale.Proceedings of the National Academy of Sciences, 120(41):e2311627120, 2023
work page 2023
-
[52]
Interplay between diversity and efficiency in collaborative efforts for content moderation
Maria Gabriela Juncosa Calahorrano, Saeedeh Mohammadi, Margaret Samahita, and Taha Yasseri. Interplay between diversity and efficiency in collaborative efforts for content moderation. Manuscript in progress, 2024. 23
work page 2024
-
[53]
Margo Janssens, Nicoleta Meslec, and Roger Th AJ Leenders. Collective intelligence in teams: Contex- tualizing collective intelligent behavior over time.Frontiers in psychology, 13:989572, 2022
work page 2022
-
[54]
Vincent J Straub, Milena Tsvetkova, and Taha Yasseri. The cost of coordination can exceed the benefit of collaboration in performing complex tasks.Collective Intelligence, 2(2):26339137231156912, 2023
work page 2023
-
[55]
Christoph Riedl, Young Ji Kim, Pranav Gupta, Thomas W Malone, and Anita Williams Woolley. Quantifying collective intelligence in human groups.Proceedings of the National Academy of Sciences, 118(21):e2005737118, 2021
work page 2021
-
[56]
Thomas W Malone and Michael Bernstein.Handbook of collective intelligence. MIT press, 2015
work page 2015
-
[57]
Preference for human, not algorithm aversion.Trends in Cognitive Sciences, 26(10):824–826, 2022
Carey K Morewedge. Preference for human, not algorithm aversion.Trends in Cognitive Sciences, 26(10):824–826, 2022
work page 2022
-
[58]
Testing a new feature to enhance content on tiktok.https://newsroom.tiktok.com/ footnotes, 2025
Adam Presser. Testing a new feature to enhance content on tiktok.https://newsroom.tiktok.com/ footnotes, 2025. Accessed: 2025-09-24
work page 2025
-
[59]
Community notes reduce the spread of misleading posts on x.OSF Preprint
Yuwei Chuai, Moritz Pilarski, Gabriele Lenzini, and Nicolas Pr¨ ollochs. Community notes reduce the spread of misleading posts on x.OSF Preprint. https://osf. io/preprints/osf/3a4fe, preprint: not peer reviewed, 2024
work page 2024
-
[60]
Isabelle Augenstein, Michiel Bakker, Tanmoy Chakraborty, David Corney, Emilio Ferrara, Iryna Gurevych, Scott Hale, Eduard Hovy, Heng Ji, Irene Larraz, et al. Community moderation and the new epistemology of fact checking on social media.arXiv preprint arXiv:2505.20067, 2025
-
[61]
Anita Williams Woolley and Pranav Gupta. Understanding collective intelligence: Investigating the role of collective memory, attention, and reasoning processes.Perspectives on Psychological Science, 19(2):344–354, 2024
work page 2024
-
[62]
Christopher A Bail, Lisa P Argyle, Taylor W Brown, John P Bumpus, Haohan Chen, MB Fallin Hun- zaker, Jaemin Lee, Marcus Mann, Friedolin Merhout, and Alexander Volfovsky. Exposure to opposing views on social media can increase political polarization.Proceedings of the National Academy of Sci- ences, 115(37):9216–9221, 2018
work page 2018
-
[63]
Levin Brinkmann, Deniz Gezerli, KV Kleist, Thomas F M¨ uller, Iyad Rahwan, and Niccolo Pescetelli. Hybrid social learning in human-algorithm cultural transmission.Philosophical Transactions of the Royal Society A, 380(2227):20200426, 2022
work page 2022
-
[64]
Cameron Martel, Jennifer Allen, Gordon Pennycook, and David G Rand. Crowds can effectively identify misinformation at scale.Perspectives on Psychological Science, 19(2):477–488, 2024. 24
work page 2024
-
[65]
Mohammed Saeed, Nicolas Traub, Maelle Nicolas, Gianluca Demartini, and Paolo Papotti. Crowd- sourced fact-checking at twitter: how does the crowd compare with experts? InProceedings of the 31st ACM international conference on information & knowledge management, pages 1736–1746, 2022
work page 2022
-
[66]
Aaron Halfaker, R Stuart Geiger, Jonathan T Morgan, and John Riedl. The rise and decline of an open collaboration system: How wikipedia’s reaction to popularity is causing its decline.American behavioral scientist, 57(5):664–688, 2013
work page 2013
-
[67]
Gordon Pennycook and David G Rand. Nudging social media toward accuracy.The Annals of the American Academy of Political and Social Science, 700(1):152–164, 2022. 25 Supplementary Information for AI Feedback Enhances Community-Based Content Moderation through Engagement with Counterarguments Saeedeh Mohammadi and Taha Yasseri Note Writing Experiment In thi...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.