Detecting In-Person Conversations in Noisy Real-World Environments with Smartwatch Audio and Motion Sensing
Pith reviewed 2026-05-19 04:59 UTC · model grok-4.3
The pith
Smartwatch audio combined with wrist motion data detects face-to-face conversations even in noisy environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
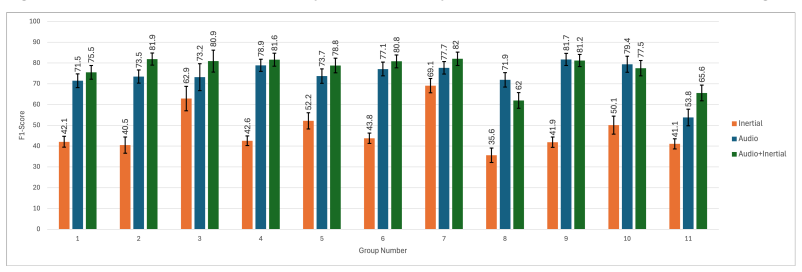
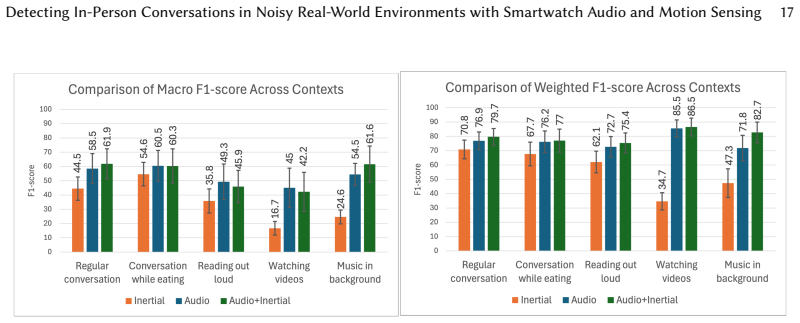
Fusing inertial data with audio significantly improves detection performance by capturing non-verbal conversational dynamics. The framework achieves 82.0±3.0% macro F1-score when detecting conversations in the lab and 77.2±1.8% in the semi-naturalistic setting, and it supports real-time deployment on commercial smartwatches.
What carries the argument
Multimodal fusion of microphone audio with 6-axis inertial signals inside convolutional and attention-based neural networks
If this is right
- Audio-only detection misses important conversational cues that wrist motion provides.
- The same fusion approach works across both controlled lab and semi-naturalistic environments.
- Real-time conversation detection becomes feasible on existing commercial smartwatches without extra hardware.
- Social interaction tracking can rely on passive wrist-worn sensors instead of cameras or dedicated microphones.
Where Pith is reading between the lines
- This sensing method could support longitudinal studies of daily social contact patterns in health or workplace research.
- Privacy-conscious users might prefer wrist-based detection over always-on phone microphones for logging conversations.
- The approach opens a path to context-aware features such as automatic note-taking during meetings or reminders based on detected social time.
Load-bearing premise
The semi-naturalistic study with 24 participants captures enough real-world noise and variability for the detection performance to hold outside the study conditions.
What would settle it
Running the trained model on audio and motion data collected from a new group of participants in a crowded, unstructured public space where background noise and movement patterns differ markedly, and finding macro F1 below 65 percent.
Figures









read the original abstract
Social interactions play a crucial role in shaping human behavior, relationships, and societies. It encompasses various forms of communication, such as verbal conversation, non-verbal gestures, facial expressions, and body language. In this work, we develop a novel computational approach to detect face-to-face verbal conversations, a foundational aspect of human social interactions. We leverage multimodal data captured by a commodity smartwatch, specifically synchronizing microphone audio with 6-axis inertial signals (accelerometer and gyroscope). We design, train, and evaluate convolutional and attention-based neural networks using three different fusion methods to integrate the audio and motion modalities. To validate this framework, we conduct a lab study with 11 participants and a semi-naturalistic study with 24 participants. Our comprehensive evaluation demonstrates that fusing inertial data with audio significantly improves detection performance by capturing non-verbal conversational dynamics. Overall, our framework achieved 82.0$\pm$3.0% macro F1-score when detecting conversations in the lab and 77.2$\pm$1.8% in the semi-naturalistic setting. Lastly, we demonstrate real-time conversation detection by deploying our trained model to a user application running on a commercial smartwatch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a multimodal framework for detecting face-to-face verbal conversations using synchronized audio and 6-axis inertial (accelerometer + gyroscope) data from a commodity smartwatch. It trains convolutional and attention-based neural networks with three fusion strategies, evaluates them on a lab study (N=11) and a semi-naturalistic study (N=24), reports macro F1 scores of 82.0±3.0% and 77.2±1.8%, and demonstrates real-time on-device deployment.
Significance. If the reported fusion gains and generalization hold, the work would provide a practical, privacy-preserving method for capturing social interaction dynamics via wearables, with potential value for behavioral science and health applications. The combination of audio with motion to capture non-verbal cues and the successful commercial-hardware deployment are concrete strengths.
major comments (2)
- [Evaluation sections (lab and semi-naturalistic studies)] Evaluation (lab and semi-naturalistic studies): The central claim that inertial fusion enables reliable detection 'in noisy real-world environments' rests on the semi-naturalistic protocol being representative of background noise, motion patterns, conversation durations, and device placement variability. With only 24 participants and no reported cross-environment, cross-device, or leave-one-environment-out testing, systematic differences between the study setting and true field conditions could inflate the 77.2±1.8% F1 without contradicting the internal numbers.
- [Methods and results sections] Methods and results: Full training details, data-split procedure, and hyperparameter search are not fully specified, making it difficult to reproduce the reported fusion benefit or to determine whether the ±3.0% and ±1.8% intervals reflect multiple random seeds, cross-validation folds, or participant-level variability.
minor comments (2)
- [Model architecture] Clarify the exact definitions and implementation differences among the three fusion methods (early, late, hybrid) in the model architecture description.
- [Discussion or conclusion] Add a limitations paragraph explicitly discussing the gap between the semi-naturalistic protocol and uncontrolled real-world conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have addressed the concerns about the representativeness of the semi-naturalistic evaluation and the lack of methodological detail by expanding the relevant sections and adding a limitations discussion. Below we respond point by point.
read point-by-point responses
-
Referee: [Evaluation sections (lab and semi-naturalistic studies)] Evaluation (lab and semi-naturalistic studies): The central claim that inertial fusion enables reliable detection 'in noisy real-world environments' rests on the semi-naturalistic protocol being representative of background noise, motion patterns, conversation durations, and device placement variability. With only 24 participants and no reported cross-environment, cross-device, or leave-one-environment-out testing, systematic differences between the study setting and true field conditions could inflate the 77.2±1.8% F1 without contradicting the internal numbers.
Authors: We acknowledge that a single semi-naturalistic environment cannot fully capture all possible real-world variabilities. The study was conducted in an actual café during normal operating hours, with measured background noise levels averaging 62–68 dB, natural participant motion (walking, gesturing, eating), variable conversation lengths (2–12 min), and smartwatch placement on the non-dominant wrist. All 24 participants were distinct from the lab cohort. While we did not conduct leave-one-environment-out or cross-device experiments, the fusion strategy still yields a consistent 4–6 point macro-F1 gain over audio-only baselines in this setting. In the revision we have added a detailed protocol description, noise measurements, and an explicit limitations paragraph noting the need for future multi-site validation. We believe these changes better contextualize the 77.2 % result without overstating generalizability. revision: partial
-
Referee: [Methods and results sections] Methods and results: Full training details, data-split procedure, and hyperparameter search are not fully specified, making it difficult to reproduce the reported fusion benefit or to determine whether the ±3.0% and ±1.8% intervals reflect multiple random seeds, cross-validation folds, or participant-level variability.
Authors: We agree that the original submission omitted key reproducibility information. The revised Methods section now specifies: (i) the exact hyperparameter search ranges and final values (learning rate 1e-4, batch size 32, 50 epochs, early stopping patience 5), (ii) the participant-independent split (70 % train / 15 % val / 15 % test, ensuring no user overlap), and (iii) that the reported ±3.0 % and ±1.8 % are standard deviations over five independent training runs with different random seeds. These additions allow readers to reproduce both the fusion gains and the reported variability. revision: yes
Circularity Check
No circularity: results from empirical held-out evaluation on collected participant data
full rationale
The paper describes data collection from a lab study (11 participants) and semi-naturalistic study (24 participants), followed by training convolutional and attention-based networks using three fusion methods on synchronized audio and 6-axis inertial signals. Reported metrics (82.0±3.0% macro F1 in lab, 77.2±1.8% in semi-naturalistic) are measured performance on held-out data splits, with real-time deployment on commercial hardware. No equations, parameters, or claims reduce by construction to self-definitions, fitted inputs renamed as predictions, or self-citation chains; the evaluation is externally falsifiable via replication on new participants or environments.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network hyperparameters
axioms (1)
- domain assumption Data collected in the lab study with 11 participants and semi-naturalistic study with 24 participants is representative of noisy real-world conversational environments
Reference graph
Works this paper leans on
-
[1]
Alireza Abedin, Mahsa Ehsanpour, Qinfeng Shi, Hamid Rezatofighi, and Damith C. Ranasinghe. 2021. Attend and Discriminate: Beyond the State-of-the-Art for Human Activity Recognition Using Wearable Sensors.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 5, 1, Article 1 (mar 2021), 22 pages. https://doi.org/10.1145/3448083
-
[2]
Apple. 2023. AirPods redefine the personal audio experience. https://www.apple.com/newsroom/2023/06/airpods- redefine-the-personal-audio-experience/ Accessed: 2023-12-19
work page 2023
- [3]
-
[4]
rConverse: Moment by Moment Conversation Detection Using a Mobile Respiration Sensor. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2, 1, Article 2 (mar 2018), 27 pages. https://doi.org/10.1145/3191734
-
[5]
Mahbubur Rahman, Nazir Saleheen, Megan Battles Parsons, Eugene H
Rummana Bari, Md. Mahbubur Rahman, Nazir Saleheen, Megan Battles Parsons, Eugene H. Buder, and Santosh Kumar
-
[6]
4, 4, Article 117 (dec 2020), 23 pages
Automated Detection of Stressful Conversations Using Wearable Physiological and Inertial Sensors. 4, 4, Article 117 (dec 2020), 23 pages. https://doi.org/10.1145/3432210
-
[7]
Janet Bavelas and Jennifer Gerwing. 2007. Conversational hand gestures and facial displays in face-to-face dialogue . 283–308
work page 2007
-
[8]
Vincent Becker, Linus Fessler, and Gábor Sörös. 2019. GestEar: combining audio and motion sensing for gesture recognition on smartwatches. In 2019 ISWC (London, United Kingdom) (ISWC ’19). ACM, New York, NY, USA, 10–19. https://doi.org/10.1145/3341163.3347735
-
[9]
Sarnab Bhattacharya, Rebecca Adaimi, and Edison Thomaz. 2022. Leveraging Sound and Wrist Motion to Detect Activities of Daily Living with Commodity Smartwatches. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 6, 2, Article 42 (jul 2022), 28 pages. https://doi.org/10.1145/3534582
-
[10]
Hervé Bredin. 2023. pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. In Proc. INTERSPEECH 2023
work page 2023
-
[11]
Esra Nur Çatak, Alper Açık, and Tilbe Göksun. 2018. The relationship between handedness and valence: A gesture study. Quarterly Journal of Experimental Psychology 71, 12 (2018), 2615–2626. https://doi.org/10.1177/1747021817750110 arXiv:https://doi.org/10.1177/1747021817750110 PMID: 29355469
-
[12]
Ciro Cattuto, Wouter Van den Broeck, Alain Barrat, Vittoria Colizza, Jean-François Pinton, and Alessandro Vespignani
-
[13]
Dynamics of Person-to-Person Interactions from Distributed RFID Sensor Networks. PLOS ONE 5, 7 (07 2010), 1–9. https://doi.org/10.1371/journal.pone.0011596
-
[14]
Metod Celestina, Jan Hrovat, and Chucri A. Kardous. 2018. Smartphone-based sound level measurement apps: Evaluation of compliance with international sound level meter standards. Applied Acoustics 139 (2018), 119–128. https://doi.org/10.1016/j.apacoust.2018.04.011
-
[15]
Tanzeem Choudhury and Alex Pentland. 2003. Sensing and Modeling Human Networks. (01 2003)
work page 2003
-
[16]
International Noise Awareness Day. 2024. https://noiseawareness.org/info-center/common-noise-levels/ Accessed: 2024-09-05
work page 2024
-
[17]
Susan Kay Donaldson. 1979. One Kind of Speech Act: How Do We Know When We ?Re Conversing?? Semiotica 28, 3-4 (1979). https://doi.org/10.1515/semi.1979.28.3-4.259
-
[18]
R.S. Feldman and J.M. Tyler. 2006. Factoring in age: Nonverbal communication across the life span . 181–200. https: //doi.org/10.4135/9781412976152.n10
-
[19]
Georgi Gerganov. 2023. whisper.cpp. https://github.com/ggerganov/whisper.cpp
work page 2023
-
[20]
John J. Godfrey, Edward C. Holliman, and Jane McDaniel. 1992. SWITCHBOARD: telephone speech corpus for research and development. In 1992 ICASSP (San Francisco, California) (ICASSP’92). IEEE Computer Society, USA, 517–520
work page 1992
-
[21]
Ki-Won Haan, Christoph Riedl, and Anita Woolley. 2021. Discovering Where We Excel: How Inclusive Turn-Taking in Conversation Improves Team Performance. In 2021 ICMI (Montreal, QC, Canada) (ICMI ’21 Companion). ACM, New York, NY, USA, 278–283. https://doi.org/10.1145/3461615.3485417
-
[22]
Jay Hall and W. H. Watson. 1970. The Effects of a Normative Intervention on Group Decision-Making Performance. Human Relations 23, 4 (1970), 299–317. https://doi.org/10.1177/001872677002300404
-
[23]
Mattias Heldner and Jens Edlund. 2010. Pauses, gaps and overlaps in conversations. Journal of Phonetics 38 (10 2010), 555–568. https://doi.org/10.1016/j.wocn.2010.08.002
-
[24]
Katerina Hilari and Sarah Northcott. 2016. “Struggling to stay connected”: comparing the social relationships of healthy older people and people with stroke and aphasia. Aphasiology (08 2016), 1–14. https://doi.org/10.1080/02687038.2016. , Vol. 1, No. 1, Article . Publication date: September 2025. 24 Zhang et al. 1218436
-
[25]
Kendrick, Marisa Casillas, and Stephen C
Judith Holler, Kobin H. Kendrick, Marisa Casillas, and Stephen C. Levinson (Eds.). 2016. Turn-Taking in Human Communicative Interaction. Frontiers Media S.A., Lausanne. https://eprints.whiterose.ac.uk/116190/
work page 2016
-
[26]
Chiao-Yin Hsiao, Wan-Rong Jih, and Jane Hsu. 2012. Recognizing Continuous Social Engagement Level in Dyadic Conversation by Using Turn-taking and Speech Emotion Patterns
work page 2012
-
[27]
Hyunchoong Kim, Jonghoon Shin, Soohwan Kim, Yohan Ko, Kyoungwoo Lee, Hojung Cha, Seong Il Hahm, and Taejun Kwon. 2017. Collaborative classification for daily activity recognition with a smartwatch (2016 IEEE International Conference on Systems, Man, and Cybernetics) . Institute of Electrical and Electronics Engineers Inc., 3707–3712. https: //doi.org/10.1...
-
[28]
Youngki Lee, Chulhong Min, Chanyou Hwang, Jaeung Lee, Inseok Hwang, Younghyun Ju, Chungkuk Yoo, Miri Moon, Uichin Lee, and Junehwa Song. 2013. SocioPhone: Everyday face-to-face interaction monitoring platform using multi-phone sensor fusion. MobiSys 2013, 375–388. https://doi.org/10.1145/2462456.2465426
-
[29]
Fangyuan Lei, Xun Liu, Qingyun Dai, and Bingo Ling. 2020. Shallow convolutional neural network for image classification. SN Applied Sciences 2 (01 2020). https://doi.org/10.1007/s42452-019-1903-4
- [30]
-
[31]
Dawei Liang, Guihong Li, Rebecca Adaimi, Radu Marculescu, and Edison Thomaz. 2022. AudioIMU: Enhancing Inertial Sensing-Based Activity Recognition with Acoustic Models. In 2022 ISWC (Cambridge, United Kingdom) (ISWC ’22). ACM, New York, NY, USA, 44–48. https://doi.org/10.1145/3544794.3558471
-
[32]
Dawei Liang, Alice Zhang, and Edison Thomaz. 2023. Automated Face-To-Face Conversation Detection on a Commodity Smartwatch with Acoustic Sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 7, 3, Article 109 (Sept 2023), 29 pages. https://doi.org/10.1145/3610882
-
[33]
Chengwen Luo and Mun Chan. 2013. SocialWeaver: Collaborative inference of human conversation networks using smartphones. (11 2013), 14. https://doi.org/10.1145/2517351.2517353
-
[34]
Aleksandar Matic, Venet Osmani, and Oscar Mayora. 2013. Automatic Sensing of Speech Activity and Correlation with Mood Changes. 195–205. https://doi.org/10.1007/978-3-642-32538-0_9
-
[35]
David Matsumoto and Hyisung Hwang. 2016. The cultural bases of nonverbal communication. 77–101. https: //doi.org/10.1037/14669-004
-
[36]
Albert Mehrabian. 1972. Nonverbal Communication. Routledge
work page 1972
-
[37]
Cornelius, Ashwin Ramaswamy, Tanzeem Choudhury, Zhigang Liu, and Andrew T
Emiliano Miluzzo, Cory T. Cornelius, Ashwin Ramaswamy, Tanzeem Choudhury, Zhigang Liu, and Andrew T. Campbell
-
[38]
Darwin Phones: The Evolution of Sensing and Inference on Mobile Phones. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services (San Francisco, California, USA) (MobiSys ’10). ACM, New York, NY, USA, 5–20. https://doi.org/10.1145/1814433.1814437
-
[39]
Vimal Mollyn, Karan Ahuja, Dhruv Verma, Chris Harrison, and Mayank Goel. 2022. SAMoSA: Sensing Activities with Motion and Subsampled Audio. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 6, 3, Article 132 (sep 2022), 19 pages. https://doi.org/10.1145/3550284
-
[40]
Debbie S Moskowitz and Simon N Young. 2006. Ecological momentary assessment: what it is and why it is a method of the future in clinical psychopharmacology. J. Psychiatry Neurosci. 31, 1 (Jan. 2006), 13–20
work page 2006
- [41]
-
[42]
Waber, Taemie Kim, Akshay Mohan, Koji Ara, and Alex Pentland
Daniel Olguin Olguin, Benjamin N. Waber, Taemie Kim, Akshay Mohan, Koji Ara, and Alex Pentland. 2009. Sensible Organizations: Technology and Methodology for Automatically Measuring Organizational Behavior. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 39, 1 (2009), 43–55. https://doi.org/10.1109/TSMCB.2008.2006638
-
[43]
World Health Organization. 2021. Social isolation and loneliness among older people: advocacy brief. https://www.decadeofhealthyageing.org/find-knowledge/resources/publications/un-decade-of-healthy-ageing- advocacy-brief-social-isolation-and-loneliness-among-older-people Accessed: 2023-12-19
work page 2021
-
[44]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: An ASR corpus based on public domain audio books. In 2015 ICASSP. 5206–5210. https://doi.org/10.1109/ICASSP.2015.7178964
-
[45]
Matthew Pantell, David Rehkopf, Douglas Jutte, S Leonard Syme, John Balmes, and Nancy Adler. 2013. Social isolation: a predictor of mortality comparable to traditional clinical risk factors. Am. J. Public Health 103, 11 (Nov. 2013), 2056–2062
work page 2013
-
[46]
Maciej Pawłowski, Anna Wróblewska, and Sylwia Sysko-Romańczuk. 2023. Effective Techniques for Multimodal Data Fusion: A Comparative Analysis. Sensors 23, 5 (2023). https://doi.org/10.3390/s23052381
-
[47]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. https://doi.org/10.48550/ARXIV.2212.04356 , Vol. 1, No. 1, Article . Publication date: September 2025. Detecting In-Person Conversations in Noisy Real-World Environments with Smartwatch Audio and Mot...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04356 2022
-
[48]
Md Rahman, Amin Ali, Kurt Plarre, Mustafa al’Absi, Emre Ertin, and Santosh Kumar. 2011. MConverse: Inferring conversation episodes from respiratory measurements collected in the field. Proceedings - Wireless Health 2011, WH’11,
work page 2011
-
[49]
https://doi.org/10.1145/2077546.2077557
-
[50]
Mary Redmayne. 2017. Where’s Your Phone? A Survey of Where Women Aged 15-40 Carry Their Smartphone and Related Risk Perception: A Survey and Pilot Study. PLOS ONE 12 (01 2017), e0167996. https://doi.org/10.1371/journal. pone.0167996
-
[51]
Harry T. Reis and Ladd Wheeler. 1991. Studying Social Interaction with the Rochester Interaction Record . Elsevier, 269–318. https://doi.org/10.1016/s0065-2601(08)60332-9
-
[52]
Sujiya S and Dr.Chandra E. 2017. A Review on Speaker Recognition.International Journal of Engineering and Technology 9 (06 2017), 1592–1598. https://doi.org/10.21817/ijet/2017/v9i3/170903513
-
[53]
Harvey Sacks, Emanuel Schegloff, and Gail Jefferson. 1974. A Simple Systematic for the Organisation of Turn Taking in Conversation. Language 50 (12 1974), 696–735. https://doi.org/10.2307/412243
-
[54]
Florian Schiel, Christoph Draxler, Angela Baumann, Tania Ellbogen, and Alex T. Steffen. 2012. The Production of Speech Corpora. https://api.semanticscholar.org/CorpusID:61111457
work page 2012
-
[55]
Nabeel Siddiqui and Rosa Chan. 2020. Multimodal hand gesture recognition using single IMU and acoustic measure- ments at wrist. PLOS ONE 15 (01 2020), e0227039. https://doi.org/10.1371/journal.pone.0227039
-
[56]
NIOSH Hearing Loss Prevention Team. 2019. NIOSH Sound Level Meter Application (app) for iOS devices
work page 2019
-
[57]
Dipanwita Thakur and Suparna Biswas. 2021. Feature fusion using deep learning for smartphone based human activity recognition. International Journal of Information Technology 13 (06 2021). https://doi.org/10.1007/s41870-021-00719-6
-
[58]
Yonatan Vaizman, Katherine Ellis, Gert Lanckriet, and Nadir Weibel. 2018. ExtraSensory App: Data Collection In- the-Wild with Rich User Interface to Self-Report Behavior. In 2018 CHI (CHI ’18). ACM, New York, NY, USA, 1–12. https://doi.org/10.1145/3173574.3174128
-
[59]
Yonatan Vaizman, Nadir Weibel, and Gert Lanckriet. 2018. Context Recognition In-the-Wild: Unified Model for Multi-Modal Sensors and Multi-Label Classification. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 1 (01 2018), 1–22. https://doi.org/10.1145/3161192
-
[60]
Martin Warren. 2006. Features of Naturalness in Conversation . https://doi.org/10.1075/pbns.152
-
[61]
Gary Weiss, Jeffrey Lockhart, Tony Pulickal, Paul McHugh, Isaac Ronan, and Jessica Timko. 2016. Actitracker: A Smartphone-Based Activity Recognition System for Improving Health and Well-Being. 682–688. https://doi.org/10. 1109/DSAA.2016.89
work page 2016
-
[62]
Kelly White, Samuel Tate, Ros Zafonte, Shrikanth Narayanan, Matthias Mehl, Min Shin, and Amar Dhand. 2023. SocialBit: protocol for a prospective observational study to validate a wearable social sensor for stroke survivors with diverse neurological abilities. BMJ Open 13, 8. https://doi.org/10.1136/bmjopen-2023-076297
-
[63]
Peter Wittenburg, Hennie Brugman, Albert Russel, Alex Klassmann, and Han Sloetjes. 2006. ELAN: a Professional Framework for Multimodality Research. In 5th International Conference on Language Resources and Evaluation (LREC 2006), Nicoletta Calzolari, Khalid Choukri, Aldo Gangemi, Bente Maegaard, Joseph Mariani, Jan Odijk, and Daniel Tapias (Eds.). Europea...
work page 2006
-
[64]
Chenren Xu, Sugang Li, Gang Liu, Yanyong Zhang, Emiliano Miluzzo, Yih-Farn Chen, Jun Li, and Bernhard Firner
-
[65]
In 2013 UbiComp (Zurich, Switzerland) (UbiComp ’13)
Crowd++: unsupervised speaker count with smartphones. In 2013 UbiComp (Zurich, Switzerland) (UbiComp ’13). ACM, New York, NY, USA, 43–52. https://doi.org/10.1145/2493432.2493435
-
[66]
Ruiqing Yin, Hervé Bredin, and Claude Barras. 2017. Speaker Change Detection in Broadcast TV using Bidirectional Long Short-Term Memory Networks. In 2017 INTERSPEECH. Stockholm, Sweden. https://github.com/yinruiqing/ change_detection
work page 2017
-
[67]
Huanle Zhang, Wan Du, Pengfei Zhou, Mo Li, and Prasant Mohapatra. 2016. DopEnc: Acoustic-Based Encounter Profiling Using Smartphones. In 2016 MobiCom (New York City, New York)(MobiCom ’16). ACM, New York, NY, USA, 294–307. https://doi.org/10.1145/2973750.2973775 , Vol. 1, No. 1, Article . Publication date: September 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.