Adaptive Network Security Policies via Belief Aggregation and Rollout
Pith reviewed 2026-05-19 04:50 UTC · model grok-4.3
The pith
Network security policies adapt quickly to changes by updating a system model and using particle filtering, feature-based aggregation, and rollout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
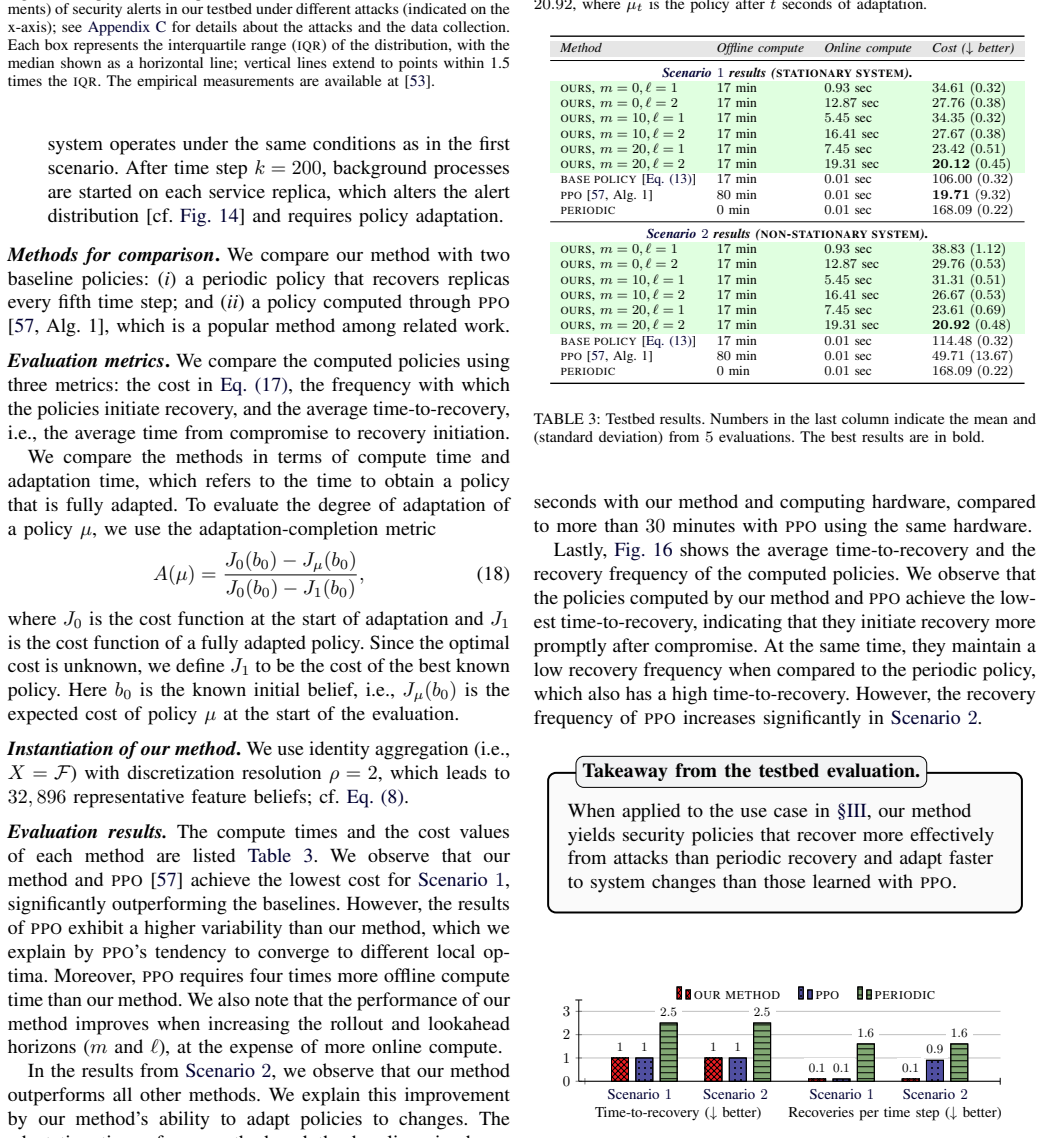
The central claim is that security policies can be computed scalably offline via feature-based aggregation on a system model and then adapted online through rollout when the model is updated for changes in conditions or vulnerabilities, with belief estimation performed by particle filtering. The aggregation approximation error is analyzed, and rollout is shown to adapt policies efficiently under certain conditions without needing to repeat offline optimization. This combination yields a method that is scalable, provides theoretical guarantees, and adapts faster than standard reinforcement learning approaches lacking such assurances, as demonstrated in simulations and testbed results outperfr
What carries the argument
The three-part framework of particle filtering for belief estimation, feature-based aggregation for scalable offline policy computation, and rollout for online adaptation to model updates.
If this is right
- Feature-based aggregation makes offline policy optimization scalable for large networks.
- Rollout adapts policies online to system model changes without repeating the full offline computation.
- The approximation error introduced by aggregation can be analyzed and bounded theoretically.
- The overall method provides performance guarantees and faster adaptation than reinforcement learning baselines under the stated conditions.
- Empirical validation on benchmarks including CAGE-2 shows outperformance relative to state-of-the-art methods.
Where Pith is reading between the lines
- The structure might transfer to other model-based control problems where maintaining an updatable simulator is feasible, such as resource allocation under uncertainty.
- Frequent model updates could reduce reliance on purely online learning loops in large-scale adaptive systems.
- Similar aggregation-plus-rollout patterns may help in approximate dynamic programming settings beyond security.
Load-bearing premise
A sufficiently accurate model or simulator of the network exists and can be updated when operational conditions or vulnerabilities change, allowing the particle filter and rollout steps to operate without large model mismatch.
What would settle it
A testbed experiment after a vulnerability change where the rollout-adapted policy shows no meaningful performance improvement or requires re-optimization time comparable to full offline recomputation.
Figures
















read the original abstract
Evolving security vulnerabilities and shifting operational conditions require frequent updates to network security policies. These updates include adjustments to incident response procedures and modifications to access controls, among others. Reinforcement learning methods have been proposed for automating such policy adaptations, but most methods in the research literature lack performance guarantees and adapt slowly to changes. In this paper, we address these limitations and present a method for computing security policies that is scalable, offers theoretical guarantees, and adapts quickly to changes. The method uses a model or simulator of the system, which is updated when changes occur, and combines three components: belief estimation through particle filtering, offline policy computation through feature-based aggregation, and online policy adaptation through rollout. In particular, feature-based aggregation enables scalable offline optimization of a policy, while rollout adapts the policy online to changes in the system model without repeating the offline optimization. We analyze the approximation error of the aggregation and show that the rollout efficiently adapts policies to changes under certain conditions. Simulations and testbed results demonstrate that our method outperforms state-of-the-art methods on several benchmarks, including CAGE-2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a method for adaptive network security policies that integrates particle filtering for belief estimation, feature-based aggregation for scalable offline policy optimization, and rollout for online adaptation to model changes. It claims to analyze the approximation error of the aggregation step and to show that rollout enables efficient adaptation under certain conditions, while outperforming state-of-the-art methods on benchmarks including CAGE-2. The approach relies on an updatable system model or simulator.
Significance. If the claimed error bounds and adaptation conditions hold, the work provides a principled model-based alternative to purely data-driven RL for network security, offering scalability through offline aggregation and rapid online updates via rollout. The empirical results on CAGE-2 strengthen the case for practical utility in evolving threat environments.
major comments (1)
- [Abstract and theoretical analysis of approximation error and rollout adaptation] The analysis of aggregation approximation error and the conditions for efficient rollout adaptation (as described in the abstract and the method overview) are derived under the assumption that the simulator exactly matches the true dynamics. No separate robustness or sensitivity analysis is provided for model mismatch arising from approximate updates to new vulnerabilities or traffic shifts; this directly affects the validity of the particle-filter beliefs and rollout value estimates and is load-bearing for the central performance guarantees.
minor comments (2)
- The abstract states that simulations and testbed results demonstrate outperformance but provides no details on the specific metrics, number of runs, or statistical tests used; adding these would improve clarity.
- Clarify how feature-based aggregation is constructed (e.g., choice of features and basis functions) to make the scalability claim more transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis of approximation error and rollout adaptation] The analysis of aggregation approximation error and the conditions for efficient rollout adaptation (as described in the abstract and the method overview) are derived under the assumption that the simulator exactly matches the true dynamics. No separate robustness or sensitivity analysis is provided for model mismatch arising from approximate updates to new vulnerabilities or traffic shifts; this directly affects the validity of the particle-filter beliefs and rollout value estimates and is load-bearing for the central performance guarantees.
Authors: We agree that our theoretical analysis of the aggregation approximation error and the rollout adaptation is conducted under the assumption that the simulator exactly matches the true system dynamics. This assumption is explicit in our model-based framework, where the simulator is updated to reflect changes in vulnerabilities or traffic. The particle filtering is used to maintain beliefs under uncertainty, and the rollout is shown to adapt the policy efficiently when the model is updated. While we do not provide a separate sensitivity analysis for residual model mismatch after updates, the empirical results on CAGE-2 and other benchmarks demonstrate practical performance even in realistic settings. We will revise the manuscript to explicitly state this assumption in the abstract and method overview and add a brief discussion on the implications of model mismatch for future work. revision: partial
Circularity Check
No significant circularity; derivation relies on external model and independent error analysis
full rationale
The paper presents a composite method (particle filtering for belief estimation, feature-based aggregation for offline policy, rollout for online adaptation) whose central claims rest on an external updatable simulator and a separate theoretical analysis of aggregation approximation error plus rollout adaptation conditions. No equations or steps reduce by construction to fitted inputs from the same data, self-definitions, or unverified self-citation chains. Benchmarks such as CAGE-2 supply external validation. This is the expected honest non-finding for a method grounded in approximate dynamic programming with stated modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A model or simulator of the network exists that can be updated when changes occur and is accurate enough for particle filtering and rollout to function.
Forward citations
Cited by 2 Pith papers
-
On-Line Policy Iteration with Trajectory-Driven Policy Generation
An online policy iteration algorithm produces monotonically cost-improving policies for a fixed initial state by training successive policies on trajectory data generated by prior policies.
-
On-Line Policy Iteration with Trajectory-Driven Policy Generation
An online policy iteration algorithm produces a sequence of monotonically cost-improving policies for fixed-initial-state deterministic control by training each new policy on the trajectory generated by the prior one.
Reference graph
Works this paper leans on
-
[1]
D. E. Denning, “An intrusion-detection model,” IEEE Transactions on Software Engineering, vol. SE-13, no. 2, pp. 222–232, 1987
work page 1987
-
[2]
A policy-based security architecture for software-defined networks,
V . Varadharajan, K. Karmakar, U. Tupakula, and M. Hitchens, “A policy-based security architecture for software-defined networks,” IEEE Transactions on Information Forensics and Security , vol. 14, no. 4, pp. 897–912, 2019
work page 2019
-
[3]
Deep reinforcement learning for cyber security,
T. T. Nguyen and V . J. Reddi, “Deep reinforcement learning for cyber security,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 3779–3795, 2023
work page 2023
-
[4]
The mayhem cyber reasoning system,
T. Avgerinos, D. Brumley, J. Davis, R. Goulden, T. Nighswander, A. Rebert, and N. Williamson, “The mayhem cyber reasoning system,” IEEE Security & Privacy , vol. 16, no. 2, pp. 52–60, 2018
work page 2018
-
[5]
RRE: A game-theoretic intrusion response and recovery engine,
S. A. Zonouz, H. Khurana, W. H. Sanders, and T. M. Yardley, “RRE: A game-theoretic intrusion response and recovery engine,” in 2009 IEEE/IFIP International Conference on Dependable Systems & Net- works, 2009, pp. 439–448
work page 2009
-
[6]
PentestGPT: Evaluating and harnessing large language models for automated penetration testing,
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “PentestGPT: Evaluating and harnessing large language models for automated penetration testing,” in 33rd USENIX Security Symposium (USENIX Security 24) . Philadelphia, PA: USENIX Association, Aug. 2024, pp. 847–864
work page 2024
-
[7]
T. Zhang, C. Xu, Y . Lian, H. Tian, J. Kang, X. Kuang, and D. Niyato, “When moving target defense meets attack prediction in digital twins: A convolutional and hierarchical reinforcement learning approach,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 10, pp. 3293– 3305, 2023
work page 2023
-
[8]
Intrusion tolerance for networked systems through two-level feedback control,
K. Hammar and R. Stadler, “Intrusion tolerance for networked systems through two-level feedback control,” in 2024 54th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) , 2024, pp. 338–352
work page 2024
-
[9]
SyzVegas: Beating kernel fuzzing odds with rein- forcement learning,
D. Wang, Z. Zhang, H. Zhang, Z. Qian, S. V . Krishnamurthy, and N. Abu-Ghazaleh, “SyzVegas: Beating kernel fuzzing odds with rein- forcement learning,” in 30th USENIX Security Symposium (USENIX Security 21). USENIX Association, Aug. 2021, pp. 2741–2758
work page 2021
-
[10]
Bertsekas, Dynamic Programming and Optimal Control: Vol
D. Bertsekas, Dynamic Programming and Optimal Control: Vol. II , 4th ed. Athena Scientific Belmont, 2012
work page 2012
-
[11]
——, Rollout, Policy Iteration, and Distributed Reinforcement Learning. Athena Scientific, 2021
work page 2021
-
[12]
On-line policy improvement using Monte- Carlo search,
G. Tesauro and G. Galperin, “On-line policy improvement using Monte- Carlo search,” in Advances in Neural Information Processing Systems , M. Mozer, M. Jordan, and T. Petsche, Eds., vol. 9. MIT Press, 1996
work page 1996
-
[13]
Discretized approximations for POMDP with average cost,
H. Yu and D. Bertsekas, “Discretized approximations for POMDP with average cost,” in Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, ser. UAI ’04. Arlington, Virginia, USA: AUAI Press, 2004, p. 619–627
work page 2004
-
[14]
N. Saldi, S. Y ¨uksel, and T. Linder, “On the asymptotic optimality of finite approximations to Markov decision processes with Borel spaces,” Math. Oper. Res., vol. 42, no. 4, p. 945–978, Nov. 2017
work page 2017
-
[15]
Feature-based aggregation and deep reinforcement learn- ing: A survey and some new implementations,
D. Bertsekas, “Feature-based aggregation and deep reinforcement learn- ing: A survey and some new implementations,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 1, pp. 1–31, 2019
work page 2019
-
[16]
Athena Scientific, 2025, 2nd edition
——, A Course in Reinforcement Learning . Athena Scientific, 2025, 2nd edition
work page 2025
- [17]
-
[18]
Online policy adaptation for networked systems using rollout,
F. S. Samani, K. Hammar, and R. Stadler, “Online policy adaptation for networked systems using rollout,” in NOMS 2024-2024 IEEE Network Operations and Management Symposium , 2024, pp. 1–9
work page 2024
-
[19]
Reinforce- ment learning based approach for flip attack detection,
H. Liu, Y . Li, J. M ˚artensson, L. Xie, and K. H. Johansson, “Reinforce- ment learning based approach for flip attack detection,” in 2020 59th IEEE Conference on Decision and Control (CDC) . IEEE, 2020, pp. 3212–3217
work page 2020
-
[20]
Rollout approach to sensor scheduling for remote state estimation under integrity attack,
H. Liu, Y . Li, K. H. Johansson, J. M ˚artensson, and L. Xie, “Rollout approach to sensor scheduling for remote state estimation under integrity attack,” Automatica, vol. 144, p. 110473, 2022
work page 2022
-
[21]
Adaptive security response strategies through conjectural online learning,
K. Hammar, T. Li, R. Stadler, and Q. Zhu, “Adaptive security response strategies through conjectural online learning,” IEEE Transactions on Information Forensics and Security , vol. 20, pp. 4055–4070, 2025
work page 2025
-
[22]
Rollout-based charging strategy for electric trucks with hours-of-service regulations,
T. Bai, Y . Li, K. H. Johansson, and J. M ˚artensson, “Rollout-based charging strategy for electric trucks with hours-of-service regulations,” IEEE Control Systems Letters , vol. 7, pp. 2167–2172, 2023
work page 2023
-
[23]
Adaptive aggregation methods for infi- nite horizon dynamic programming,
D. Bertsekas and D. Castanon, “Adaptive aggregation methods for infi- nite horizon dynamic programming,” IEEE Transactions on Automatic Control, vol. 34, no. 6, pp. 589–598, 1989
work page 1989
-
[24]
T. Alpcan and T. Basar, Network Security: A Decision and Game- Theoretic Approach, 1st ed. USA: Cambridge University Press, 2010
work page 2010
-
[25]
Optimal security response to network intrusions in IT systems,
K. Hammar, “Optimal security response to network intrusions in IT systems,” Ph.D. dissertation, KTH Royal Instistute of Technology, 2024
work page 2024
-
[26]
Towards the deployment of realistic autonomous cyber network defence: A systematic review,
S. Vyas, V . Mavroudis, and P. Burnap, “Towards the deployment of realistic autonomous cyber network defence: A systematic review,”ACM Comput. Surv., May 2025
work page 2025
-
[27]
CAGE, “TTCP CAGE challenge 2,” in AAAI-22 Workshop on Artificial Intelligence for Cyber Security (AICS) , 2022, https://github .com/cage- challenge/cage-challenge-2
work page 2022
-
[28]
Automated cyber defence: A review,
S. Vyas, J. Hannay, A. Bolton, and P. P. Burnap, “Automated cyber defence: A review,” 2023, https://arxiv.org/abs/2303.04926, code: https: //github.com/john-cardiff/-cyborg-cage-2
-
[29]
Reward shaping for happier autonomous cyber security agents,
E. Bates, V . Mavroudis, and C. Hicks, “Reward shaping for happier autonomous cyber security agents,” in Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , ser. AISec ’23, New York, NY , USA, 2023, p. 221–232
work page 2023
-
[30]
Beyond CAGE: Investigating generalization of learned autonomous network defense policies,
M. Wolk, A. Applebaum, C. Dennler, P. Dwyer, M. Moskowitz, H. Nguyen, N. Nichols, N. Park, P. Rachwalski, F. Rau, and A. Webster, “Beyond CAGE: Investigating generalization of learned autonomous network defense policies,” 2022
work page 2022
-
[31]
Autonomous network defence using reinforcement learning,
M. Foley, C. Hicks, K. Highnam, and V . Mavroudis, “Autonomous network defence using reinforcement learning,” in Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, ser. ASIA CCS ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 1252–1254
work page 2022
-
[32]
Inroads into autonomous network defence using explained reinforcement learning,
M. Foley, M. Wang, Z. M, C. Hicks, and V . Mavroudis, “Inroads into autonomous network defence using explained reinforcement learning,” 2023, https://arxiv.org/abs/2306.09318
-
[33]
S. Xu, Z. Xie, C. Zhu, X. Wang, and L. Shi, “Enhancing cybersecurity in industrial control system with autonomous defense using normalized proximal policy optimization model,” in 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS) , 2023, pp. 928–935
work page 2023
-
[34]
RICE: breaking through the training bottlenecks of reinforcement learning with explanation,
Z. Cheng, X. Wu, J. Yu, S. Yang, G. Wang, and X. Xing, “RICE: breaking through the training bottlenecks of reinforcement learning with explanation,” in Proceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[35]
J. Nyberg and P. Johnson, “Structural generalization in autonomous cyber incident response with message-passing neural networks and reinforcement learning,” in 2024 IEEE International Conference on Cyber Security and Resilience (CSR) , 2024, pp. 282–289
work page 2024
-
[36]
An empirical game-theoretic anal- ysis of autonomous cyber-defence agents,
G. Palmer, L. Swaby, D. J. B. Harrold, M. Stewart, A. Hiles, C. Willis, I. Miles, and S. Farmer, “An empirical game-theoretic anal- ysis of autonomous cyber-defence agents,” 2025, https://arxiv .org/abs/ 2501.19206
-
[37]
Neuroevolution for autonomous cyber defense,
K. Heckel, “Neuroevolution for autonomous cyber defense,” in Pro- ceedings of the Companion Conference on Genetic and Evolutionary Computation, ser. GECCO ’23 Companion. New York, NY , USA: Association for Computing Machinery, 2023, p. 651–654
work page 2023
-
[38]
Y . Tang, J. Sun, H. Wang, J. Deng, L. Tong, and W. Xu, “A method of network attack-defense game and collaborative defense decision-making based on hierarchical multi-agent reinforcement learning,” Computers & Security, vol. 142, p. 103871, 2024
work page 2024
-
[39]
Learning cyber defence tactics from scratch with multi-agent reinforcement learning,
J. Wiebe, R. A. Mallah, and L. Li, “Learning cyber defence tactics from scratch with multi-agent reinforcement learning,” 2023, https://arxiv.org/ abs/2310.05939
-
[40]
Hierarchical multi-agent reinforcement learning for cyber network defense,
A. V . Singh, E. Rathbun, E. Graham, L. Oakley, S. Boboila, A. Oprea, and P. Chin, “Hierarchical multi-agent reinforcement learning for cyber network defense,” 2024, https://arxiv .org/abs/2410.17351
-
[41]
Y . Yan, Y . Zhang, and K. Huang, “Depending on yourself when you should: Mentoring LLM with RL agents to become the master in cybersecurity games,” 2024, https://arxiv .org/html/2403.17674v1
-
[42]
Design of an autonomous cyber defence agent using hybrid AI models,
J. F. Loevenich, E. Adler, R. Mercier, A. Velazquez, and R. R. F. Lopes, “Design of an autonomous cyber defence agent using hybrid AI models,” in 2024 International Conference on Military Communication and Information Systems (ICMCIS) , 2024, pp. 1–10
work page 2024
-
[43]
Optimal defender strategies for CAGE-2 using causal modeling and tree search,
K. Hammar, N. Dhir, and R. Stadler, “Optimal defender strategies for CAGE-2 using causal modeling and tree search,” 2024, https://arxiv.org/ abs/2407.11070
-
[44]
A. Ramamurthy and N. Dhir, “General autonomous cybersecurity de- fense: Learning robust policies for dynamic topologies and diverse attackers,” 2025, https://arxiv.org/abs/2506.22706
-
[45]
Leveraging large language models for autonomous cyber defense: Insights from CAGE-2 simula- tions,
H. Mohammadi, J. J. Davis, and M. Kiely, “Leveraging large language models for autonomous cyber defense: Insights from CAGE-2 simula- tions,” IEEE Intelligent Systems , pp. 1–8, 2025
work page 2025
-
[46]
Atlassian and C. Research, “2020 DevOps trends survey,” 2020, https: //www.atlassian.com/whitepapers/devops-survey-2020
work page 2020
-
[47]
2024 observability forecast report,
N. relic and E. T. R. (ETR), “2024 observability forecast report,” 2024
work page 2024
-
[48]
Optimal control of Markov processes with incomplete state information,
K. J. ˚Astr¨om, “Optimal control of Markov processes with incomplete state information,” Journal of Mathematical Analysis and Applications , vol. 10, no. 1, pp. 174–205, 1965
work page 1965
-
[49]
Krishnamurthy, Partially Observed Markov Decision Processes: From Filtering to Controlled Sensing
V . Krishnamurthy, Partially Observed Markov Decision Processes: From Filtering to Controlled Sensing . Cambridge University Press, 2016
work page 2016
-
[50]
A survey of convergence results on particle filtering methods for practitioners,
D. Crisan and A. Doucet, “A survey of convergence results on particle filtering methods for practitioners,” IEEE Transactions on Signal Pro- cessing, vol. 50, no. 3, pp. 736–746, 2002
work page 2002
-
[51]
Feature-based belief aggrega- tion for partially observable Markov decision problems,
Y . Li, K. Hammar, and D. Bertsekas, “Feature-based belief aggrega- tion for partially observable Markov decision problems,” 2025, https: //arxiv.org/abs/2507.04646
-
[52]
Bertsekas, Reinforcement Learning and Optimal Control
D. Bertsekas, Reinforcement Learning and Optimal Control . Athena Scientific, 2019
work page 2019
-
[53]
K. Hammar, “Software for the paper ”Adaptive Network Security Policies via Belief Aggregation and Rollout”,” 2025, the software and data are available at https://github.com/Limmen/rollout aggregation and https://github.com/Limmen/csle
work page 2025
-
[54]
Bertsekas, Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control
D. Bertsekas, Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control . Athena Scientific, 2022
work page 2022
- [55]
- [56]
-
[57]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”CoRR, 2017, http://arxiv.org/ abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
K. W. Cobbe, J. Hilton, O. Klimov, and J. Schulman, “Phasic policy gradient,” in Proceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
- [59]
-
[60]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, Feb. 2015
work page 2015
-
[61]
Monte-Carlo planning in large POMDPs,
D. Silver and J. Veness, “Monte-Carlo planning in large POMDPs,” in Advances in Neural Information Processing Systems , vol. 23, 2010
work page 2010
-
[62]
Approximate solution methods for partially observable Markov and semi-Markov decision processes,
H. Yu, “Approximate solution methods for partially observable Markov and semi-Markov decision processes,” Ph.D. dissertation, Massachusetts Institute of Technology, USA, 2006
work page 2006
-
[63]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,” Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
work page 2021
-
[64]
CleanRL: High-quality single-file implementations of deep reinforcement learning algorithms
S. Huang, R. F. J. Dossa, C. Ye, J. Braga, D. Chakraborty, K. Mehta, and J. G. M. Ara ´ujo, “CleanRL: High-quality single-file implementations of deep reinforcement learning algorithms.” Journal of Machine Learning Research, vol. 23, pp. 274:1–274:18, 2022
work page 2022
-
[65]
MITRE ATT&CK: Design and philosophy,
B. E. Strom, A. Applebaum, D. P. Miller, K. C. Nickels, A. G. Penning- ton, and C. B. Thomas, “MITRE ATT&CK: Design and philosophy,” in Technical report. The MITRE Corporation, 2018
work page 2018
-
[66]
End-to-end internet packet dynamics,
V . Paxson, “End-to-end internet packet dynamics,” in IEEE/ACM Trans- actions on Networking , 1997, pp. 277–292. 13
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.