Optimal differentially private kernel learning with random projection
Pith reviewed 2026-05-19 03:04 UTC · model grok-4.3
The pith
Random projection in kernel space achieves minimax-optimal excess risk under differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the paper's own terms, the central claim is that the proposed random projection method for differentially private kernel ERM attains the minimax optimal excess risk rates for the squared loss and Lipschitz-smooth convex loss functions under a local strong convexity condition. Existing approaches based on random Fourier features or l2 regularization are suboptimal. The work includes the derivation of dimension-free excess risk bounds for objective perturbation-based private linear ERM without relying on noisy gradient mechanisms, as well as sharper bounds for existing DP kernel ERM algorithms.
What carries the argument
Random projection in the reproducing kernel Hilbert space using Gaussian processes, which performs dimension reduction to balance privacy and statistical performance in the ERM framework.
Load-bearing premise
The local strong convexity condition on the loss function is required to obtain the minimax-optimal rates.
What would settle it
If the excess risk of the proposed method exceeds the minimax rate in an experiment satisfying the local strong convexity condition, that would falsify the optimality.
Figures





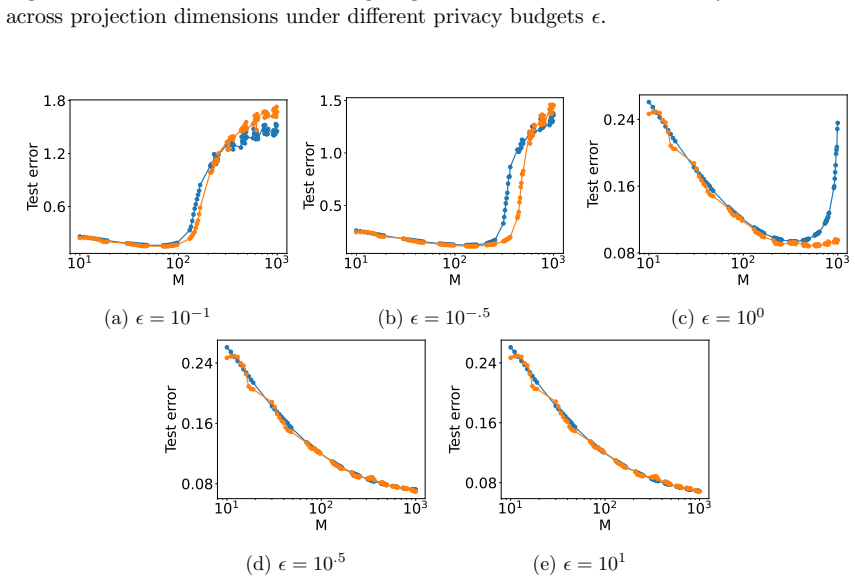



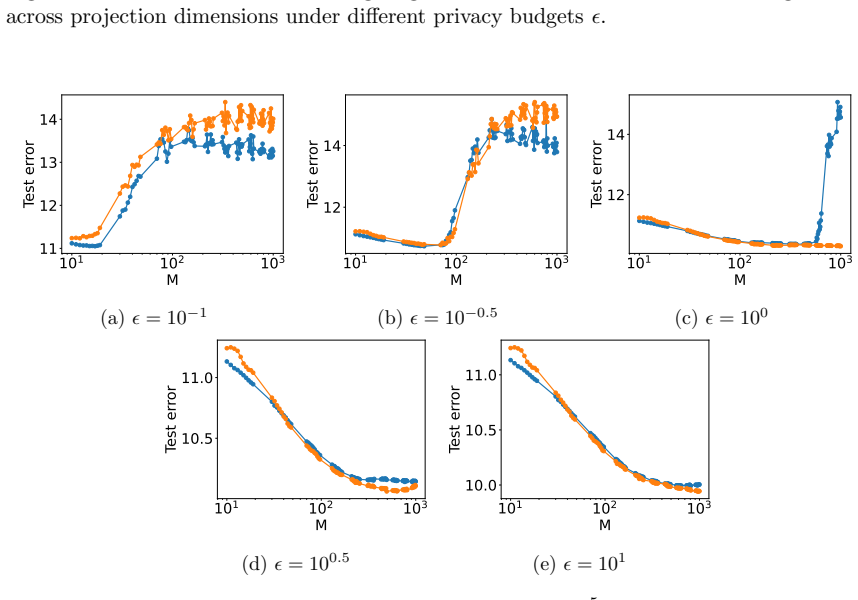
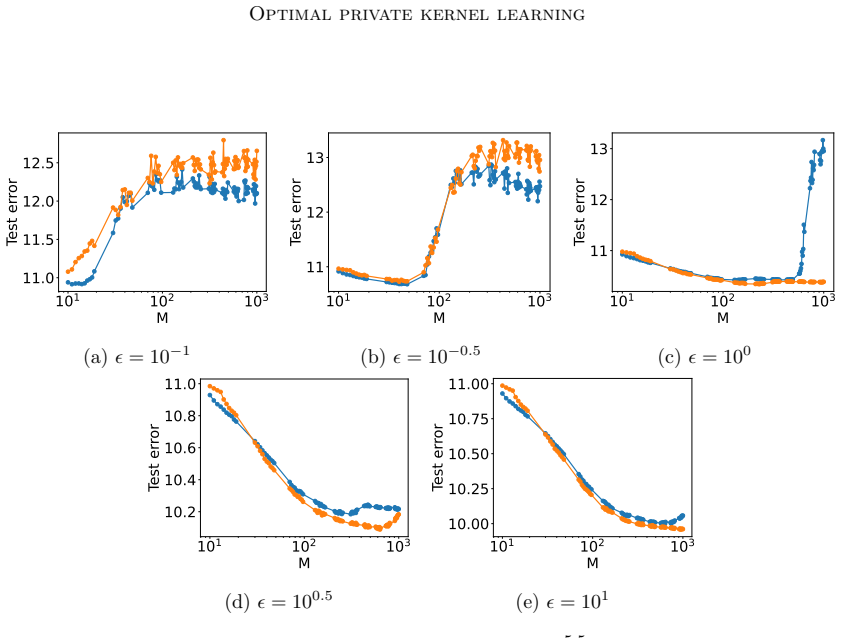

read the original abstract
Differential privacy has become a cornerstone in the development of privacy-preserving learning algorithms. This work addresses optimizing differentially private kernel learning within the empirical risk minimization (ERM) framework. We propose a novel differentially private kernel ERM algorithm based on random projection in the reproducing kernel Hilbert space using Gaussian processes. Our method achieves minimax-optimal excess risk rates for both the squared loss and Lipschitz-smooth convex loss functions under a local strong convexity condition. We further show that existing approaches based on alternative dimension reduction techniques, such as random Fourier feature mappings or $\ell_2$ regularization, yield suboptimal excess risk bounds. Our key theoretical contribution also includes the derivation of dimension-free excess risk bounds for objective perturbation-based private linear ERM, marking the first such result that does not rely on noisy gradient-based mechanisms. Additionally, we obtain sharper excess risk bounds for existing differentially private kernel ERM algorithms. Empirical evaluations support our theoretical claims, demonstrating that random projection enables statistically efficient and optimally private kernel learning. These findings provide new insights into the design of differentially private algorithms and highlight the central role of dimension reduction in balancing privacy and utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a differentially private kernel ERM algorithm that uses random projections in the RKHS induced by Gaussian processes. It claims to achieve minimax-optimal excess risk rates for both squared loss and Lipschitz-smooth convex losses (under a local strong convexity condition), demonstrates suboptimality of alternative dimension-reduction techniques such as random Fourier features and ℓ₂ regularization, derives the first dimension-free excess risk bounds for objective-perturbation private linear ERM, obtains sharper bounds for prior DP kernel ERM methods, and supports the theory with empirical results.
Significance. If the local strong convexity condition is verified to hold after projection and the derivations are complete, the work would be significant for showing that a carefully chosen random projection can attain optimal privacy-utility trade-offs in kernel methods where other reductions do not, while also contributing dimension-free bounds for linear private ERM.
major comments (2)
- [Abstract and §4] Abstract and §4 (convex-loss case): the minimax-optimal excess-risk rate for Lipschitz-smooth convex losses is obtained only under the local strong convexity condition; the manuscript invokes this condition to match the lower bound but does not verify that the Gaussian-process random projection preserves the required local curvature in the RKHS, leaving the optimality claim for this loss class unsecured.
- [Theorem 5.1] Theorem 5.1 (comparison to random Fourier features): the claimed suboptimality of RFF-based methods is shown via excess-risk bounds, yet the argument appears to rely on a specific scaling of the projection dimension (a free parameter); without an explicit statement that the dimension choice is independent of the privacy parameter or sample size, the separation from the proposed method is not fully load-bearing.
minor comments (1)
- [Notation] Notation for the random-projection dimension and the Gaussian-process kernel could be introduced earlier and used consistently to improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (convex-loss case): the minimax-optimal excess-risk rate for Lipschitz-smooth convex losses is obtained only under the local strong convexity condition; the manuscript invokes this condition to match the lower bound but does not verify that the Gaussian-process random projection preserves the required local curvature in the RKHS, leaving the optimality claim for this loss class unsecured.
Authors: We thank the referee for this observation. The local strong convexity condition is invoked to attain the minimax rate for the Lipschitz-smooth convex loss, and we agree that an explicit verification of its preservation after projection is needed to fully secure the claim. In the revised manuscript we will add a new lemma showing that the Gaussian-process random projection preserves local strong convexity in the projected RKHS with high probability, provided the projection dimension satisfies a mild lower bound that remains independent of the privacy parameter. We will also update the abstract and Section 4 to reference this preservation result. revision: yes
-
Referee: [Theorem 5.1] Theorem 5.1 (comparison to random Fourier features): the claimed suboptimality of RFF-based methods is shown via excess-risk bounds, yet the argument appears to rely on a specific scaling of the projection dimension (a free parameter); without an explicit statement that the dimension choice is independent of the privacy parameter or sample size, the separation from the proposed method is not fully load-bearing.
Authors: We appreciate the referee's request for clarification. In the analysis underlying Theorem 5.1 the projection dimension for the proposed Gaussian-process method is chosen independently of both the privacy parameter ε and the sample size n (scaling only logarithmically with n). In contrast, matching the same excess-risk bound with random Fourier features requires a dimension that grows with privacy-dependent terms. We will add an explicit remark in the theorem statement and surrounding text stating this independence and thereby reinforcing the separation. revision: yes
Circularity Check
No circularity: derivation builds on standard DP-ERM and RKHS bounds with explicit assumptions
full rationale
The paper's central results consist of excess-risk upper bounds derived from random Gaussian-process projection into an RKHS, combined with objective perturbation for privacy. These bounds are obtained under the stated local strong convexity assumption for the convex-loss case; the assumption is introduced explicitly rather than derived from the projection step itself. No equation reduces a claimed prediction to a fitted parameter by construction, no load-bearing uniqueness theorem is imported via self-citation, and no ansatz is smuggled through prior work. The comparison showing alternative dimension-reduction methods are suboptimal follows directly from the same excess-risk analysis applied to those methods. The derivation chain therefore remains self-contained against external benchmarks once the local-strong-convexity hypothesis is granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- random projection dimension
axioms (1)
- domain assumption Local strong convexity of the loss function
Reference graph
Works this paper leans on
-
[1]
Differentially private assouad, fano, and le cam
Jayadev Acharya, Ziteng Sun, and Huanyu Zhang. Differentially private assouad, fano, and le cam. In Algorithmic Learning Theory, pages 48--78. PMLR, 2021
work page 2021
-
[2]
Database-friendly random projections
Dimitris Achlioptas. Database-friendly random projections. In Proceedings of the twentieth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, pages 274--281, 2001
work page 2001
-
[3]
Robert J Adler and Jonathan E Taylor. Gaussian inequalities. Random Fields and Geometry, pages 49--64, 2007
work page 2007
-
[4]
Differentially private generalized linear models revisited
Raman Arora, Raef Bassily, Crist \'o bal Guzm \'a n, Michael Menart, and Enayat Ullah. Differentially private generalized linear models revisited. Advances in neural information processing systems, 35: 0 22505--22517, 2022
work page 2022
-
[5]
Arnab Auddy, T Tony Cai, and Abhinav Chakraborty. Minimax and adaptive transfer learning for nonparametric classification under distributed differential privacy constraints. arXiv preprint arXiv:2406.20088, 2024
-
[6]
Differentially private database release via kernel mean embeddings
Matej Balog, Ilya Tolstikhin, and Bernhard Sch \"o lkopf. Differentially private database release via kernel mean embeddings. In International Conference on Machine Learning, pages 414--422. PMLR, 2018
work page 2018
-
[7]
Rademacher and gaussian complexities: Risk bounds and structural results
Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3 0 (Nov): 0 463--482, 2002
work page 2002
-
[8]
Differentially private learning with margin guarantees
Raef Bassily, Mehryar Mohri, and Ananda Theertha Suresh. Differentially private learning with margin guarantees. Advances in Neural Information Processing Systems, 35: 0 32127--32141, 2022 a
work page 2022
-
[9]
Differentially private learning with margin guarantees
Raef Bassily, Mehryar Mohri, and Ananda Theertha Suresh. Differentially private learning with margin guarantees. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 32127--32141. Curran Associates, Inc., 2022 b . URL https://proceedings.neurips.cc/paper_files/pa...
work page 2022
-
[10]
T. Bertin-Mahieux. Year Prediction MSD . UCI Machine Learning Repository, 2011. DOI : https://doi.org/10.24432/C50K61
-
[11]
The cost of privacy: Optimal rates of convergence for parameter estimation with differential privacy
T Tony Cai, Yichen Wang, and Linjun Zhang. The cost of privacy: Optimal rates of convergence for parameter estimation with differential privacy. The Annals of Statistics, 49 0 (5): 0 2825--2850, 2021
work page 2021
-
[12]
T Tony Cai, Abhinav Chakraborty, and Lasse Vuursteen. Optimal federated learning for nonparametric regression with heterogeneous distributed differential privacy constraints. arXiv preprint arXiv:2406.06755, 2024
-
[13]
Optimal rates for the regularized least-squares algorithm
Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics, 7: 0 331--368, 2007
work page 2007
-
[14]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, \'U lfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th USENIX Security Symposium (USENIX Security 19), pages 267--284, Santa Clara, CA, 2019. USENIX Association. ISBN 978-1-939133-06-9. URL https://www.usenix.org/conference/usenixsecurity19/...
work page 2019
-
[15]
Differentially private empirical risk minimization
Kamalika Chaudhuri, Claire Monteleoni, and Anand D Sarwate. Differentially private empirical risk minimization. Journal of Machine Learning Research, 12 0 (3), 2011
work page 2011
-
[16]
Andreas Christmann and Ingo Steinwart. Support vector machines. Springer, 2008
work page 2008
-
[17]
Jinshuo Dong, Aaron Roth, and Weijie J Su. Gaussian differential privacy. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84: 0 3--37, 2022
work page 2022
-
[18]
John C. Duchi, Michael I. Jordan, and Martin J. Wainwright. Local privacy and statistical minimax rates. In 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, pages 429--438, 2013
work page 2013
-
[19]
Our data, ourselves: Privacy via distributed noise generation
Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. Our data, ourselves: Privacy via distributed noise generation. In Advances in Cryptology-EUROCRYPT 2006: 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Proceedings 25. Springer, 2006 a
work page 2006
-
[20]
Calibrating noise to sensitivity in private data analysis
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography: Third Theory of Cryptography Conference, Proceedings 3, pages 265--284. Springer, 2006 b
work page 2006
-
[22]
Model inversion attacks that exploit confidence information and basic countermeasures
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, CCS '15, page 1322–1333, New York, NY, USA, 2015 b . Association for Computing Machinery. ISBN 9781450338325. URL https://doi.or...
-
[23]
Differential privacy for functions and functional data
Rob Hall, Alessandro Rinaldo, and Larry Wasserman. Differential privacy for functions and functional data. J. Mach. Learn. Res., 14 0 (1): 0 703–727, 2013. ISSN 1532-4435
work page 2013
-
[24]
Frederik Harder, Kamil Adamczewski, and Mijung Park. Dp-merf: Differentially private mean embeddings with randomfeatures for practical privacy-preserving data generation. In International conference on artificial intelligence and statistics, pages 1819--1827. PMLR, 2021
work page 2021
-
[25]
Differentially private learning with kernels
Prateek Jain and Abhradeep Thakurta. Differentially private learning with kernels. In International conference on machine learning, pages 118--126. PMLR, 2013
work page 2013
-
[26]
\"U ber lineare methoden in der wahrscheinlichkeitsrechnung
Kari Karhunen. \"U ber lineare methoden in der wahrscheinlichkeitsrechnung. Ann Acad Sci Fennicae, 37: 0 1, 1947
work page 1947
-
[27]
Finite Sample Differentially Private Confidence Intervals
Vishesh Karwa and Salil Vadhan. Finite Sample Differentially Private Confidence Intervals . In Anna R. Karlin, editor, 9th Innovations in Theoretical Computer Science Conference (ITCS 2018), volume 94 of Leibniz International Proceedings in Informatics (LIPIcs), pages 44:1--44:9, Dagstuhl, Germany, 2018. Schloss Dagstuhl -- Leibniz-Zentrum f \"u r Informa...
-
[28]
Private convex empirical risk minimization and high-dimensional regression
Daniel Kifer, Adam Smith, and Abhradeep Thakurta. Private convex empirical risk minimization and high-dimensional regression. In Proceedings of the 25th Annual Conference on Learning Theory, volume 23, pages 25.1--25.40, 2012
work page 2012
-
[29]
Concentration inequalities and moment bounds for sample covariance operators
Vladimir Koltchinskii and Karim Lounici. Concentration inequalities and moment bounds for sample covariance operators . Bernoulli, 23 0 (1): 0 110 -- 133, 2017. URL https://doi.org/10.3150/15-BEJ730
-
[30]
B. Laurent and P. Massart. Adaptive estimation of a quadratic functional by model selection . The Annals of Statistics, 28 0 (5): 0 1302 -- 1338, 2000. URL https://doi.org/10.1214/aos/1015957395
-
[31]
Minimax risks and optimal procedures for estimation under functional local differential privacy
Bonwoo Lee, Jeongyoun Ahn, and Cheolwoo Park. Minimax risks and optimal procedures for estimation under functional local differential privacy. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 57964--57975. Curran Associates, Inc., 2023. URL https://proceedi...
work page 2023
-
[32]
Differential privacy in scalable general kernel learning via k-means nyström random features
Bonwoo Lee, Jeongyoun Ahn, and Cheolwoo Park. Differential privacy in scalable general kernel learning via k-means nyström random features. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 21141--21171. Curran Associates, Inc., 2024. URL https...
work page 2024
-
[33]
Towards sharp analysis for distributed learning with random features
Jian Li and Yong Liu. Towards sharp analysis for distributed learning with random features. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI '23, 2023. ISBN 978-1-956792-03-4. URL https://doi.org/10.24963/ijcai.2023/436
-
[34]
Optimal rates for distributed learning with random features
Jian Li, Yong Liu, and Weiping Wang. Optimal rates for distributed learning with random features. In Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), 2022
work page 2022
-
[35]
On the asymptotic learning curves of kernel ridge regression under power-law decay
Yicheng Li, haobo Zhang, and Qian Lin. On the asymptotic learning curves of kernel ridge regression under power-law decay. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 49341--49364. Curran Associates, Inc., 2023 a . URL https://proceedings.neurips.cc/pa...
work page 2023
-
[36]
Kernel interpolation generalizes poorly
Yicheng Li, Haobo Zhang, and Qian Lin. Kernel interpolation generalizes poorly. Biometrika, 111 0 (2): 0 715--722, 08 2023 b . ISSN 1464-3510. URL https://doi.org/10.1093/biomet/asad048
-
[37]
Distributed learning of conditional quantiles in the reproducing kernel hilbert space
Heng Lian. Distributed learning of conditional quantiles in the reproducing kernel hilbert space. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 11686--11696. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/4c12...
work page 2022
-
[38]
Random features for kernel approximation: A survey on algorithms, theory, and beyond
Fanghui Liu, Xiaolin Huang, Yudong Chen, and Johan AK Suykens. Random features for kernel approximation: A survey on algorithms, theory, and beyond. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 0 (10): 0 7128--7148, 2021
work page 2021
-
[39]
Improved analysis of supervised learning in the rkhs with random features: Beyond least squares
Jiamin Liu, Lei Wang, and Heng Lian. Improved analysis of supervised learning in the rkhs with random features: Beyond least squares. Neural Networks, 184: 0 107091, 2025
work page 2025
-
[40]
Linear regression with random projections
Odalric Maillard and R \'e mi Munos. Linear regression with random projections. Journal of Machine Learning Research, 13 0 (1): 0 2735--2772, 2012
work page 2012
-
[41]
Generalization error bounds for bayesian mixture algorithms
Ron Meir and Tong Zhang. Generalization error bounds for bayesian mixture algorithms. Journal of Machine Learning Research, 4 0 (Oct): 0 839--860, 2003
work page 2003
-
[42]
Exploiting unintended feature leakage in collaborative learning
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. Exploiting unintended feature leakage in collaborative learning. In 2019 IEEE Symposium on Security and Privacy (SP), pages 691--706, 2019
work page 2019
-
[43]
Regularization in kernel learning
Shahar Mendelson and Joseph Neeman. Regularization in kernel learning . The Annals of Statistics, 38 0 (1): 0 526 -- 565, 2010. URL https://doi.org/10.1214/09-AOS728
-
[44]
Efficient P rivate A lgorithms for L earning L arge- M argin H alfspaces
Huy L\^ e Nguy\ \^ e n, Jonathan Ullman, and Lydia Zakynthinou. Efficient P rivate A lgorithms for L earning L arge- M argin H alfspaces. In Aryeh Kontorovich and Gergely Neu, editors, Proceedings of the 31st International Conference on Algorithmic Learning Theory, volume 117 of Proceedings of Machine Learning Research, pages 704--724. PMLR, 08 Feb--11 Fe...
work page 2020
-
[45]
The geometry of differential privacy: the sparse and approximate cases
Aleksandar Nikolov, Kunal Talwar, and Li Zhang. The geometry of differential privacy: the sparse and approximate cases. In Proceedings of the Forty-Fifth Annual ACM Symposium on Theory of Computing, STOC '13, page 351–360, 2013
work page 2013
-
[46]
Efficient differentially private kernel support vector classifier for multi-class classification
Jinseong Park, Yujin Choi, Junyoung Byun, Jaewook Lee, and Saerom Park. Efficient differentially private kernel support vector classifier for multi-class classification. Information Sciences, 619: 0 889--907, 2023
work page 2023
-
[47]
Privacy-preserving deep learning: Revisited and enhanced
Le Trieu Phong, Yoshinori Aono, Takuya Hayashi, Lihua Wang, and Shiho Moriai. Privacy-preserving deep learning: Revisited and enhanced. In Lynn Batten, Dong Seong Kim, Xuyun Zhang, and Gang Li, editors, Applications and Techniques in Information Security, pages 100--110, Singapore, 2017. Springer Singapore. ISBN 978-981-10-5421-1
work page 2017
-
[48]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. Advances in neural information processing systems, 20, 2007
work page 2007
-
[49]
Noise-aware differentially private regression via meta-learning
Ossi R \"a is \"a , Stratis Markou, Matthew Ashman, Wessel Bruinsma, Marlon Tobaben, Antti Honkela, and Richard Turner. Noise-aware differentially private regression via meta-learning. Advances in Neural Information Processing Systems, 37: 0 63873--63907, 2024
work page 2024
-
[50]
A differentially private kernel two-sample test
Anant Raj, Ho Chung Leon Law, Dino Sejdinovic, and Mijung Park. A differentially private kernel two-sample test. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 697--724. Springer, 2019
work page 2019
-
[51]
Lipschitz extensions for node-private graph statistics and the generalized exponential mechanism
Sofya Raskhodnikova and Adam Smith. Lipschitz extensions for node-private graph statistics and the generalized exponential mechanism. In 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), pages 495--504, 2016
work page 2016
-
[52]
Learning in a Large Function Space: Privacy-Preserving Mechanisms for SVM Learning
Benjamin IP Rubinstein, Peter L Bartlett, Ling Huang, and Nina Taft. Learning in a large function space: Privacy-preserving mechanisms for svm learning. arXiv preprint arXiv:0911.5708, 2009
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[53]
Generalization properties of learning with random features
Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file...
work page 2017
-
[54]
Learning with kernels: support vector machines, regularization, optimization, and beyond
Bernhard Scholkopf and Alexander J Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2018
work page 2018
-
[55]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy (SP), pages 3--18, 2017
work page 2017
-
[56]
Differentially private regression with gaussian processes
Michael T Smith, Mauricio A \'A lvarez, Max Zwiessele, and Neil D Lawrence. Differentially private regression with gaussian processes. In International Conference on Artificial Intelligence and Statistics, pages 1195--1203. PMLR, 2018
work page 2018
-
[57]
Differentially private regression and classification with sparse gaussian processes
Michael Thomas Smith, Mauricio A \'A lvarez, and Neil D Lawrence. Differentially private regression and classification with sparse gaussian processes. Journal of Machine Learning Research, 22 0 (188): 0 1--41, 2021
work page 2021
-
[58]
Machine learning models that remember too much
Congzheng Song, Thomas Ristenpart, and Vitaly Shmatikov. Machine learning models that remember too much. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS '17, page 587–601, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450349468. URL https://doi.org/10.1145/3133956.3134077
-
[59]
Characterizing private clipped gradient descent on convex generalized linear problems
Shuang Song, Om Thakkar, and Abhradeep Thakurta. Characterizing private clipped gradient descent on convex generalized linear problems. arXiv preprint arXiv:2006.06783, 2020
-
[60]
Optimal rates for regularized least squares regression
Ingo Steinwart, Don Hush, and Clint Scovel. Optimal rates for regularized least squares regression. 01 2009
work page 2009
-
[61]
Mercer theorem for rkhs on noncompact sets
Hongwei Sun. Mercer theorem for rkhs on noncompact sets. Journal of Complexity, 21 0 (3): 0 337--349, 2005. ISSN 0885-064X. URL https://www.sciencedirect.com/science/article/pii/S0885064X04000822
work page 2005
-
[62]
High-dimensional probability: An introduction with applications in data science, volume 47
Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018
work page 2018
-
[63]
Fast private kernel density estimation via locality sensitive quantization
Tal Wagner, Yonatan Naamad, and Nina Mishra. Fast private kernel density estimation via locality sensitive quantization. In International Conference on Machine Learning, pages 35339--35367. PMLR, 2023
work page 2023
-
[64]
Privacy-preserving q-learning with functional noise in continuous spaces
Baoxiang Wang and Nidhi Hegde. Privacy-preserving q-learning with functional noise in continuous spaces. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[65]
Optimal kernel quantile learning with random features
Caixing Wang and Xingdong Feng. Optimal kernel quantile learning with random features. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 504...
work page 2024
-
[66]
Towards theoretical understanding of learning large-scale dependent data via random features
Chao Wang, Xin Bing, Caixing Wang, et al. Towards theoretical understanding of learning large-scale dependent data via random features. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[67]
Differentially private sgd with random features
Yi-guang Wang and Zheng-chu Guo. Differentially private sgd with random features. Applied Mathematics-A Journal of Chinese Universities, 39 0 (1): 0 1--23, 2024
work page 2024
-
[68]
Yu-Xiang Wang. Revisiting differentially private linear regression: optimal and adaptive prediction & estimation in unbounded domain. In Uncertainty in Artificial Intelligence (UAI-18), 2018
work page 2018
-
[69]
Beyond inferring class representatives: User-level privacy leakage from federated learning
Zhibo Wang, Mengkai Song, Zhifei Zhang, Yang Song, Qian Wang, and Hairong Qi. Beyond inferring class representatives: User-level privacy leakage from federated learning. In IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, pages 2512--2520, 2019
work page 2019
-
[70]
Yun Yang, Mert Pilanci, and Martin J. Wainwright. Randomized sketches for kernels: Fast and optimal nonparametric regression . The Annals of Statistics, 45 0 (3): 0 991 -- 1023, 2017. URL https://doi.org/10.1214/16-AOS1472
-
[71]
Online performative gradient descent for learning nash equilibria in decision-dependent games
Zihan Zhu, Ethan Fang, and Zhuoran Yang. Online performative gradient descent for learning nash equilibria in decision-dependent games. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 47902--47913. Curran Associates, Inc., 2023. URL https://proceedings.neu...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.