Adapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Pith reviewed 2026-05-19 02:59 UTC · model grok-4.3
The pith
Adapting large vision-language models with iterative and manual instructions guides diffusion models to produce more realistic low-light image enhancements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLM-IMI consists of a Normal-Light Instruction Prior Generation branch that uses a VLM to produce textual cues describing desired normal-light content, and an Instruction-aware Light Enhancement Diffusion branch that incorporates those cues via a learnable fusion module to steer the generative process. At inference time the system applies iterative instruction refinement to progressively improve quality, while also permitting manual user instructions fed directly into the language model for customized outputs, and experiments show these elements together yield higher perceptual quality and realism than existing state-of-the-art low-light enhancement techniques.
What carries the argument
the learnable instruction prior fusion module that dynamically aligns and merges image features with VLM-generated text features to condition the diffusion enhancement process
If this is right
- The framework enables user-controlled enhancement by accepting custom textual instructions that override or supplement the generated priors.
- Iterative instruction refinement during inference can progressively correct illumination and detail without requiring paired normal-light training data at test time.
- Semantic text guidance from VLMs allows the diffusion model to handle complex lighting where brightness adjustments alone produce artifacts or loss of scene identity.
- Cross-modal fusion of image and text priors leads to outputs with greater detail coherence and realism than methods relying solely on visual priors or low-light inputs.
Where Pith is reading between the lines
- The same instruction-generation and fusion pattern could be tested on related restoration tasks such as dehazing or shadow removal to check whether semantic cues transfer across degradation types.
- If the iterative refinement loop converges reliably, it suggests a path toward reference-free enhancement pipelines that improve with each additional instruction pass.
- Manual instruction support opens the possibility of interactive editing workflows where a user describes desired lighting or style changes in natural language.
Load-bearing premise
Textual descriptions produced by the vision-language model correctly capture the desired normal-light appearance of the scene and can be used as reliable enhancement cues even without any ground-truth normal-light image available.
What would settle it
A controlled test on scenes with unusual or ambiguous objects where the generated text instructions either produce visible semantic mismatches or fail to improve perceptual quality over non-instruction baselines.
Figures

















read the original abstract
Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a framework that adapts large vision-language models with iterative and manual instructions for generative LLIE. VLM-IMI mainly contains two branches: Normal-Light Instruction Prior Generation (NL-IPG) and Instruction-aware Light Enhancement Diffusion (IA-LED). The NL-IPG incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. IA-LED incorporates instruction priors from the NL-IPG to guide the diffusion process, enabling precise illumination enhancement. To effectively integrate cross-modal priors, we introduce a learnable instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, as the ground-truth normal-light images are not available, we propose an inference with an iterative instructions strategy to refine textual instructions, progressively improving visual quality. Our VLM-IMI also inherently supports manual instruction control by allowing users to directly input custom instructions into the LLM to generate user-expected outputs. Experiments across diverse scenarios demonstrate that VLM-IMI outperforms SOTA methods in terms of perception and realism. The source code is available at: https://github.com/sunxiaoran01/VLM-IMI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLM-IMI, a framework adapting large vision-language models for generative low-light image enhancement via iterative and manual instructions. It introduces two branches—Normal-Light Instruction Prior Generation (NL-IPG) to produce textual descriptions of desired normal-light content as semantic cues, and Instruction-aware Light Enhancement Diffusion (IA-LED) to guide a diffusion process using these priors through a learnable instruction prior fusion module. At inference, an iterative instructions strategy refines the texts in the absence of ground-truth normal-light images, while also supporting direct manual user instructions to the LLM. Experiments are claimed to show outperformance over SOTA methods on perception and realism metrics across diverse scenarios, with code released.
Significance. If the claims hold, the work would represent a meaningful step in low-light enhancement by injecting VLM-derived semantic guidance into the restoration process, potentially improving coherence and realism beyond purely image-based or reference-free priors. The public code release supports reproducibility and further exploration. The significance is limited by the unverified reliability of the generated textual priors, which form the core of the proposed advantage.
major comments (2)
- [NL-IPG branch and inference strategy (as described in abstract)] The headline claim of SOTA perceptual and realism superiority rests on the NL-IPG branch producing textual descriptions that serve as reliable enhancement cues at inference (when ground-truth normal-light images are unavailable). No evaluation of text quality—such as semantic similarity metrics to held-out normal-light captions, human ratings of description accuracy, or ablation removing the iterative refinement loop—is reported, leaving open the possibility that hallucinations or omissions in VLM outputs undermine the downstream IA-LED gains.
- [Instruction prior fusion module] The learnable instruction prior fusion module is presented as dynamically aligning image and text features, yet no details on its architecture, training objective, or ablation isolating its contribution versus simpler concatenation or attention mechanisms are visible, making it difficult to assess whether the cross-modal integration is the load-bearing factor for the reported improvements.
minor comments (2)
- [Experiments] The abstract references 'experiments across diverse scenarios' but provides no specifics on datasets, number of test images, statistical significance testing, or full set of baselines and metrics; these details are essential for evaluating robustness.
- [Inference with iterative instructions] Clarify the exact iterative loop procedure (number of iterations, stopping criterion, and how manual instructions interact with the automatic refinement) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our work. We provide point-by-point responses below and indicate planned revisions to address the concerns raised.
read point-by-point responses
-
Referee: [NL-IPG branch and inference strategy (as described in abstract)] The headline claim of SOTA perceptual and realism superiority rests on the NL-IPG branch producing textual descriptions that serve as reliable enhancement cues at inference (when ground-truth normal-light images are unavailable). No evaluation of text quality—such as semantic similarity metrics to held-out normal-light captions, human ratings of description accuracy, or ablation removing the iterative refinement loop—is reported, leaving open the possibility that hallucinations or omissions in VLM outputs undermine the downstream IA-LED gains.
Authors: We agree that direct evaluation of the textual priors would provide stronger evidence for their reliability as enhancement cues, particularly at inference without ground-truth normal-light images. While the reported end-to-end gains in perceptual and realism metrics offer indirect support for the NL-IPG branch and iterative strategy, we acknowledge that explicit validation is missing. In the revised version we will add semantic similarity metrics (e.g., CLIP-based cosine similarity) against held-out normal-light captions, a small-scale human rating study of description accuracy, and an ablation that disables the iterative refinement loop to quantify its impact. revision: yes
-
Referee: [Instruction prior fusion module] The learnable instruction prior fusion module is presented as dynamically aligning image and text features, yet no details on its architecture, training objective, or ablation isolating its contribution versus simpler concatenation or attention mechanisms are visible, making it difficult to assess whether the cross-modal integration is the load-bearing factor for the reported improvements.
Authors: We accept that the current manuscript provides insufficient architectural and experimental detail on the instruction prior fusion module. We will expand the relevant section to describe the module’s exact architecture, the training objective used to optimize the cross-modal alignment, and new ablation studies that compare the proposed fusion against simpler baselines such as feature concatenation and standard attention. These additions will allow readers to evaluate whether the learnable fusion is the primary driver of the observed gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes VLM-IMI as a new framework with two branches (NL-IPG for textual prior generation from VLMs and IA-LED for instruction-aware diffusion enhancement) plus a learnable fusion module whose parameters are trained on data. Claims of SOTA perceptual performance rest on experimental comparisons across scenarios rather than any self-referential equations, fitted inputs renamed as predictions, or load-bearing self-citations. The iterative inference strategy for refining instructions when ground-truth is unavailable is an operational procedure, not a closed loop that reduces the output to the input by construction. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear in the provided sections. This is a standard architectural proposal with independent empirical support.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable weights in instruction prior fusion module
axioms (1)
- domain assumption Pre-trained large VLMs can produce textual descriptions that serve as reliable semantic priors for normal-light image content
invented entities (1)
-
Instruction prior fusion module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VLM-IMI comprises two key components: the Instruction Prior Parsing (I2P) branch and the Instruction-aware Lighting Diffusion (ILD) branch... iterative instruction strategy to progressively refine textual guidance
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
instruction prior fusion module (IPFM) that dynamically aligns and fuses image and text features
What do these tags mean?
- matches
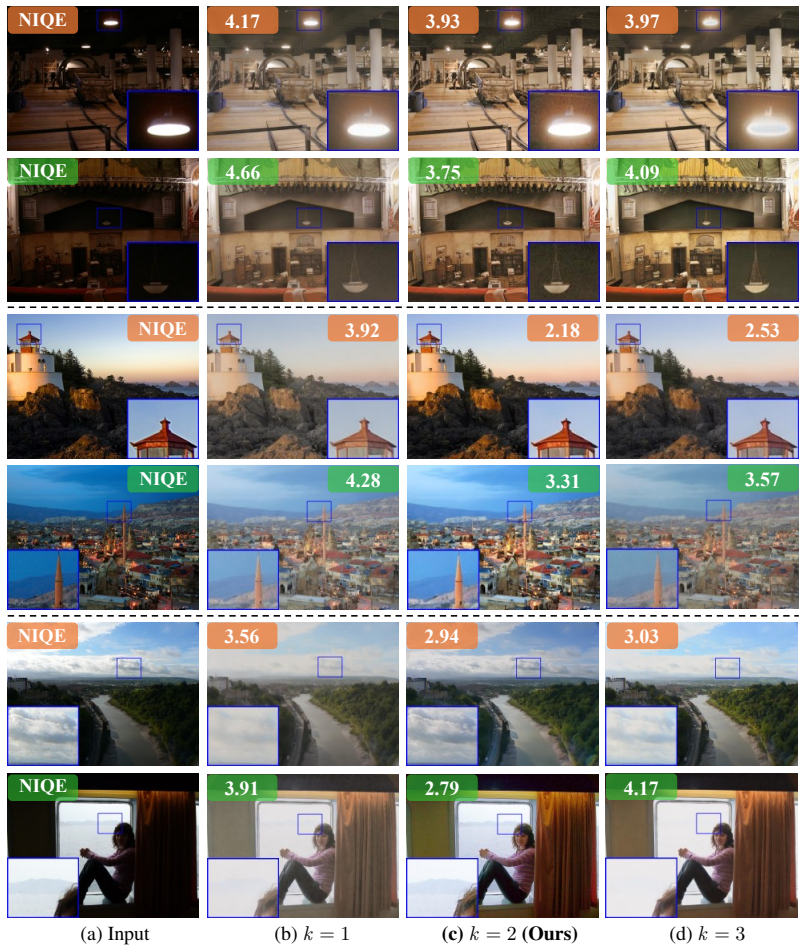
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. 2022. Flamingo: a visual language model for few-shot learning.NeurIPS(2022)
work page 2022
-
[2]
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, et al. 2022. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
2010.Handbook of image and video processing
Alan C Bovik. 2010.Handbook of image and video processing. Academic press
work page 2010
-
[4]
Rongtai Cai and Zekun Chen. 2023. Brain-like retinex: A biologically plausible retinex algorithm for low light image enhancement.PR(2023)
work page 2023
-
[5]
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang. 2023. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. InICCV
work page 2023
-
[6]
Jiale Cheng, Xiao Liu, Kehan Zheng, Pei Ke, Hongning Wang, Yuxiao Dong, Jie Tang, and Minlie Huang
- [7]
-
[8]
Duc-Tien Dang-Nguyen, Cecilia Pasquini, Valentina Conotter, and Giulia Boato. 2015. Raise: A raw images dataset for digital image forensics. InACM MMSys
work page 2015
-
[9]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. InCVPR
work page 2019
-
[10]
Ben Fei, Zhaoyang Lyu, Liang Pan, Junzhe Zhang, Weidong Yang, Tianyue Luo, Bo Zhang, and Bo Dai
-
[11]
Generative diffusion prior for unified image restoration and enhancement. InCVPR
-
[12]
Zhenqi Fu, Yan Yang, Xiaotong Tu, Yue Huang, Xinghao Ding, and Kai-Kuang Ma. 2023. Learning a simple low-light image enhancer from paired low-light instances. InCVPR
work page 2023
-
[13]
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong
-
[14]
Zero-reference deep curve estimation for low-light image enhancement. InCVPR
- [15]
-
[16]
Xiaojie Guo, Yu Li, and Haibin Ling. 2016. LIME: Low-light image enhancement via illumination map estimation.IEEE TIP(2016)
work page 2016
-
[17]
Jiang Hai, Zhu Xuan, Ren Yang, Yutong Hao, Fengzhu Zou, Fang Lin, and Songchen Han. 2023. R2rnet: Low-light image enhancement via real-low to real-normal network.JVCIR(2023)
work page 2023
-
[18]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.NeurIPS (2020)
work page 2020
-
[19]
Jinhui Hou, Zhiyu Zhu, Junhui Hou, Hui Liu, Huanqiang Zeng, and Hui Yuan. 2023. Global structure- aware diffusion process for low-light image enhancement.NeurIPS(2023)
work page 2023
-
[20]
Hai Jiang, Ao Luo, Haoqiang Fan, Songchen Han, and Shuaicheng Liu. 2023. Low-light image enhance- ment with wavelet-based diffusion models.ACM TOG(2023)
work page 2023
-
[21]
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, and Zhangyang Wang. 2021. Enlightengan: Deep light enhancement without paired supervision.IEEE TIP (2021)
work page 2021
-
[22]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. Musiq: Multi-scale image quality transformer. InICCV
work page 2021
-
[23]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Edwin H Land. 1977. The retinex theory of color vision.SciAm(1977)
work page 1977
-
[25]
Chulwoo Lee, Chul Lee, and Chang-Su Kim. 2013. Contrast enhancement based on layered difference representation of 2D histograms.IEEE TIP(2013). 10
work page 2013
-
[26]
JDMCK Lee and K Toutanova. 2018. Pre-training of deep bidirectional transformers for language under- standing.arXiv preprint arXiv:1810.04805(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Xiaozhou Lei, Zixiang Fei, Wenju Zhou, Huiyu Zhou, and Minrui Fei. 2022. Low-light image enhance- ment using the cell vibration model.IEEE TMM(2022)
work page 2022
-
[28]
Jinlong Li, Baolu Li, Zhengzhong Tu, Xinyu Liu, Qing Guo, Felix Juefei-Xu, Runsheng Xu, and Hongkai Yu. 2024. Light the night: A multi-condition diffusion framework for unpaired low-light enhancement in autonomous driving. InCVPR
work page 2024
-
[29]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML
work page 2022
-
[30]
Mading Li, Jiaying Liu, Wenhan Yang, Xiaoyan Sun, and Zongming Guo. 2018. Structure-revealing low-light image enhancement via robust retinex model.IEEE TIP(2018)
work page 2018
-
[31]
Zhexin Liang, Chongyi Li, Shangchen Zhou, Ruicheng Feng, and Chen Change Loy. 2023. Iterative prompt learning for unsupervised backlit image enhancement. InICCV
work page 2023
-
[32]
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. 2017. Feature pyramid networks for object detection. InCVPR
work page 2017
- [33]
-
[34]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning.NeurIPS (2023)
work page 2023
-
[35]
Yuhao Liu, Zhanghan Ke, Fang Liu, Nanxuan Zhao, and Rynson WH Lau. 2024. Diff-plugin: Revitalizing details for diffusion-based low-level tasks. InCVPR
work page 2024
-
[36]
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. 2017. LLNet: A deep autoencoder approach to natural low-light image enhancement. (2017)
work page 2017
-
[37]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion probabilistic models. InCVPR
work page 2022
- [38]
-
[39]
Long Ma, Dian Jin, Nan An, Jinyuan Liu, Xin Fan, Zhongxuan Luo, and Risheng Liu. 2023. Bilevel fast scene adaptation for low-light image enhancement.IJCV(2023)
work page 2023
-
[40]
Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, and Zhongxuan Luo. 2022. Toward fast, flexible, and robust low-light image enhancement. InCVPR
work page 2022
-
[41]
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. 2012. Making a “completely blind” image quality analyzer.IEEE SPL(2012)
work page 2012
-
[42]
Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffusion probabilistic models. InICML
work page 2021
-
[43]
Ozan ¨Ozdenizci and Robert Legenstein. 2023. Restoring vision in adverse weather conditions with patch- based denoising diffusion models.IEEE TPAMI(2023)
work page 2023
-
[44]
Yunpeng Qu, Kun Yuan, Kai Zhao, Qizhi Xie, Jinhua Hao, Ming Sun, and Chao Zhou. 2024. Xpsr: Cross-modal priors for diffusion-based image super-resolution. InECCV
work page 2024
-
[45]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InICML
work page 2021
-
[46]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR(2020)
work page 2020
-
[47]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. 2022. High- resolution image synthesis with latent diffusion models. InCVPR. 11
work page 2022
-
[48]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR
work page 2023
-
[49]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localiza- tion. InICCV
work page 2017
-
[50]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Vassilios V onikakis, Rigas Kouskouridas, and Antonios Gasteratos. 2018. On the evaluation of illumina- tion compensation algorithms.MTAP(2018)
work page 2018
-
[52]
Haoyuan Wang, Ke Xu, and Rynson WH Lau. 2022. Local color distributions prior for image enhance- ment. InECCV
work page 2022
-
[53]
Ruixing Wang, Qing Zhang, Chi-Wing Fu, Xiaoyong Shen, Wei-Shi Zheng, and Jiaya Jia. 2019. Under- exposed photo enhancement using deep illumination estimation. InCVPR
work page 2019
-
[54]
Shuhang Wang, Jin Zheng, Hai-Miao Hu, and Bo Li. 2013. Naturalness preserved enhancement algorithm for non-uniform illumination images.IEEE TIP(2013)
work page 2013
-
[55]
Wenjing Wang, Huan Yang, Jianlong Fu, and Jiaying Liu. 2024. Zero-reference low-light enhancement via physical quadruple priors. InCVPR
work page 2024
-
[56]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE TIP(2004)
work page 2004
-
[57]
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. 2018. Deep retinex decomposition for low- light enhancement.arXiv preprint arXiv:1808.04560(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[58]
Jay Whang, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G Dimakis, and Peyman Milanfar. 2022. Deblurring via stochastic refinement. InCVPR
work page 2022
-
[59]
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. 2024. Seesr: Towards semantics-aware real-world image super-resolution. InCVPR
work page 2024
-
[60]
Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wenhan Yang, and Jianmin Jiang. 2022. Uretinex- net: Retinex-based deep unfolding network for low-light image enhancement. InCVPR
work page 2022
-
[61]
Xin Xu, Shiqin Wang, Zheng Wang, Xiaolong Zhang, and Ruimin Hu. 2021. Exploring image enhance- ment for salient object detection in low light images.ACM TOMM(2021)
work page 2021
-
[62]
Shuzhou Yang, Moxuan Ding, Yanmin Wu, Zihan Li, and Jian Zhang. 2023. Implicit neural representation for cooperative low-light image enhancement. InICCV
work page 2023
-
[63]
Shaoliang Yang, Dongming Zhou, Jinde Cao, and Yanbu Guo. 2022. Rethinking low-light enhancement via transformer-GAN.IEEE SPL(2022)
work page 2022
-
[64]
Wenhan Yang, Shiqi Wang, Yuming Fang, Yue Wang, and Jiaying Liu. 2020. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. InCVPR
work page 2020
-
[65]
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Jiayi Ma. 2023. Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model. InICCV
work page 2023
-
[66]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. InICCV
work page 2023
-
[67]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR
work page 2018
-
[68]
Yonghua Zhang, Xiaojie Guo, Jiayi Ma, Wei Liu, and Jiawan Zhang. 2021. Beyond brightening low-light images.IJCV(2021). 12 A Additional Controllable Result Figure 10 presents additional controllable enhancement results alongside corresponding Grad-CAM visualizations [46], demonstrating how different text instructions lead to distinct output variations. The...
work page 2021
-
[69]
(lower). B.3 More Results on the Iterative Instruction strategy Figure 13 provides more visualizations of different iterative instruction strategies applied to three real-world datasets. Whenk= 2, the contrast and brightness of the image in the shadowed areas improve significantly, revealing clearer details. The overall image appears more natural in subje...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.