UniEmo: Unifying Emotional Understanding and Generation with Learnable Expert Queries
Pith reviewed 2026-05-25 08:11 UTC · model grok-4.3
The pith
UniEmo unifies emotional understanding and generation by extracting multi-scale features with learnable expert queries that guide diffusion and receive dual feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a unified framework extracts multi-scale emotional features via a hierarchical chain of learnable expert queries, fuses those queries and representations to steer a diffusion model, and uses joint training plus a data filtering algorithm to create generation-driven dual feedback loops that improve the understanding component in return.
What carries the argument
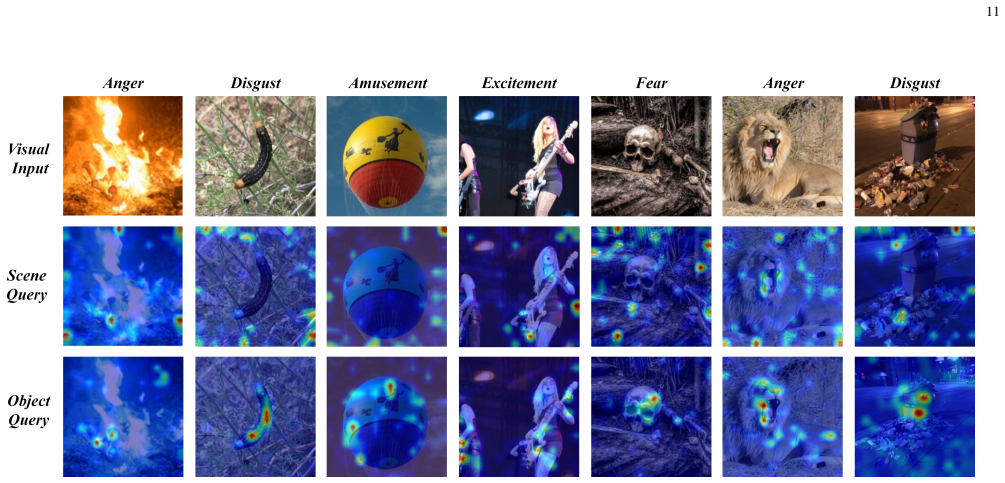
Hierarchical emotional understanding chain with learnable expert queries that progressively extracts multi-scale emotional features to serve as a shared foundation for both tasks.
If this is right
- Fusing the expert queries and emotional representations with an emotional correlation coefficient and emotional condition loss improves diversity and fidelity of generated emotion-evoking images.
- Joint training lets the generation component supply implicit feedback that strengthens the understanding component.
- A data filtering algorithm applied to high-quality images from the trained model supplies explicit feedback that further raises understanding capacity.
- The resulting model outperforms prior separate state-of-the-art methods on both emotional understanding and emotional generation benchmarks.
Where Pith is reading between the lines
- The same query-based unification pattern could be tested on other paired vision tasks such as scene understanding paired with conditional image synthesis.
- Iterating the dual feedback loop multiple times might produce further gains without additional labeled data.
- The approach could lower the need for large separate training sets by letting generated images supplement understanding data.
Load-bearing premise
The assumption that multi-scale emotional features extracted by the learnable expert queries form a foundational step that benefits both understanding and generation tasks.
What would settle it
An experiment that replaces the learnable expert queries and hierarchical chain with standard fixed features and measures whether both understanding accuracy and generation quality drop or stay the same under joint training.
Figures






read the original abstract
Emotional understanding and generation are often treated as separate tasks, yet they are inherently complementary and can mutually enhance each other. In this paper, we propose the UniEmo, a unified framework that seamlessly integrates these two tasks. The key challenge lies in the abstract nature of emotions, necessitating the extraction of visual representations beneficial for both tasks. To address this, we propose a hierarchical emotional understanding chain with learnable expert queries that progressively extracts multi-scale emotional features, thereby serving as a foundational step for unification. Simultaneously, we fuse these expert queries and emotional representations to guide the diffusion model in generating emotion-evoking images. To enhance the diversity and fidelity of the generated emotional images, we further introduce the emotional correlation coefficient and emotional condition loss into the fusion process. This step facilitates fusion and alignment for emotional generation guided by the understanding. In turn, we demonstrate that joint training allows the generation component to provide implicit feedback to the understanding part. Furthermore, we propose a novel data filtering algorithm to select high-quality and diverse emotional images generated by the well-trained model, which explicitly feedback into the understanding part. Together, these generation-driven dual feedback processes enhance the model's understanding capacity. Extensive experiments show that UniEmo significantly outperforms state-of-the-art methods in both emotional understanding and generation tasks. The code for the proposed method is available at https://github.com/JiuTian-VL/UniEmo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniEmo, a unified framework for emotional understanding and generation tasks. It introduces a hierarchical emotional understanding chain using learnable expert queries to extract multi-scale emotional features, which are fused with emotional representations to condition a diffusion model for generation. An emotional correlation coefficient and emotional condition loss are added to improve generation quality, while dual feedback loops (implicit from generation and explicit via a novel data filtering algorithm) enable mutual enhancement between the two tasks. The manuscript reports that extensive experiments on standard benchmarks demonstrate significant outperformance over prior state-of-the-art methods on both understanding and generation, with code released at https://github.com/JiuTian-VL/UniEmo.
Significance. If the empirical results and mutual-enhancement claims hold, the work could meaningfully advance affective computing by providing a concrete mechanism for joint training of understanding and generation with shared representations and feedback. The public code release is a clear strength that supports reproducibility and extension by the community.
major comments (2)
- [Method section] The central unification claim rests on the hierarchical chain with learnable expert queries serving as a foundational step for both tasks (Method section). However, no ablation is reported that isolates the contribution of these queries versus a standard multi-scale feature extractor, making it unclear whether the reported gains on understanding benchmarks are attributable to this component or to joint training alone.
- [Experiments section] The dual feedback processes (implicit generation feedback and explicit data filtering) are presented as enhancing understanding capacity (Experiments section). The manuscript should report the performance delta on understanding metrics when the generation-driven feedback is disabled, as this directly tests the mutual-enhancement argument that underpins the unification.
minor comments (2)
- [Abstract] The abstract asserts outperformance without any numerical results, dataset names, or baseline references; while the full experimental section supplies these, the abstract should be updated for consistency with journal standards.
- [Method section] Notation for the emotional correlation coefficient and emotional condition loss should be introduced with explicit equations in the method section to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contributions of our proposed components. We address each major comment below and will revise the manuscript to include the requested ablations.
read point-by-point responses
-
Referee: [Method section] The central unification claim rests on the hierarchical chain with learnable expert queries serving as a foundational step for both tasks (Method section). However, no ablation is reported that isolates the contribution of these queries versus a standard multi-scale feature extractor, making it unclear whether the reported gains on understanding benchmarks are attributable to this component or to joint training alone.
Authors: We agree that an ablation isolating the learnable expert queries would strengthen the paper. The queries are designed to enable task-specific progressive extraction of multi-scale emotional features within the hierarchical chain. In the revised manuscript, we will add an ablation comparing our approach against a standard multi-scale feature extractor (e.g., a feature pyramid network with non-learnable queries) while keeping joint training fixed, to quantify the specific contribution of the learnable queries. revision: yes
-
Referee: [Experiments section] The dual feedback processes (implicit generation feedback and explicit data filtering) are presented as enhancing understanding capacity (Experiments section). The manuscript should report the performance delta on understanding metrics when the generation-driven feedback is disabled, as this directly tests the mutual-enhancement argument that underpins the unification.
Authors: We concur that this ablation is necessary to directly test the mutual-enhancement claim. We will add results in the revised Experiments section showing understanding benchmark performance when the generation-driven feedback (both implicit and explicit) is disabled, thereby reporting the performance delta attributable to these processes. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript introduces a new neural architecture (hierarchical emotional understanding chain with learnable expert queries, emotional correlation coefficient, dual feedback loops, and data filtering) and reports empirical gains on standard benchmarks. No equations, derivations, or first-principles claims are present that reduce by construction to fitted parameters, self-citations, or renamed inputs. The unification argument rests on the described training procedure and quantitative comparisons rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable expert queries
- emotional correlation coefficient
axioms (1)
- domain assumption Emotional understanding and generation are inherently complementary and can mutually enhance each other.
invented entities (2)
-
learnable expert queries
no independent evidence
-
emotional correlation coefficient
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Navigating the Emotion Tree: Hierarchical Hyperbolic RAG for Multimodal Emotion Recognition
HyperEmo-RAG uses hierarchical hyperbolic embeddings and graph-based evidence injection to outperform prior methods in multimodal emotion recognition.
-
ConsisVLA-4D: Advancing Spatiotemporal Consistency in Efficient 3D-Perception and 4D-Reasoning for Robotic Manipulation
ConsisVLA-4D adds cross-view semantic alignment, cross-object geometric fusion, and cross-scene dynamic reasoning to VLA models, delivering 21.6% and 41.5% gains plus 2.3x and 2.4x speedups on LIBERO and real-world tasks.
-
AffectAgent: Collaborative Multi-Agent Reasoning for Retrieval-Augmented Multimodal Emotion Recognition
AffectAgent deploys a query planner, evidence filter, and emotion generator as collaborative agents trained via MAPPO with shared reward, plus MB-MoE and RAAF modules, to achieve superior multimodal emotion recognitio...
Reference graph
Works this paper leans on
-
[1]
Video ecommerce++: Toward large scale online video advertising,
Z.-Q. Cheng, X. Wu, Y . Liu, and X.-S. Hua, “Video ecommerce++: Toward large scale online video advertising,” IEEE transactions on multimedia, vol. 19, no. 6, pp. 1170–1183, 2017
work page 2017
-
[2]
Video2shop: Exact matching clothes in videos to online shopping images,
——, “Video2shop: Exact matching clothes in videos to online shopping images,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4048–4056
work page 2017
-
[3]
Detecting and grounding multi-modal media manipulation and beyond,
R. Shao, T. Wu, J. Wu, L. Nie, and Z. Liu, “Detecting and grounding multi-modal media manipulation and beyond,” IEEE Transactions on Pattern Analysis and Machine Intelligence , 2024
work page 2024
-
[4]
Detecting and grounding multi-modal media manipulation,
R. Shao, T. Wu, and Z. Liu, “Detecting and grounding multi-modal media manipulation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 6904–6913
work page 2023
-
[5]
Multi-adversarial discriminative deep domain generalization for face presentation attack detection,
R. Shao, X. Lan, J. Li, and P. C. Yuen, “Multi-adversarial discriminative deep domain generalization for face presentation attack detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 023–10 031
work page 2019
-
[6]
Emotion recognition, emotion expres- sion, and cultural display rules: Implications for counseling
A. Hutchison and L. Gerstein, “Emotion recognition, emotion expres- sion, and cultural display rules: Implications for counseling.” Journal of Asia Pacific Counseling, vol. 7, no. 1, 2017
work page 2017
-
[7]
Stimuli-aware visual emotion analysis,
J. Yang, J. Li, X. Wang, Y . Ding, and X. Gao, “Stimuli-aware visual emotion analysis,” IEEE Transactions on Image Processing, vol. 30, pp. 7432–7445, 2021
work page 2021
-
[8]
Y . Lyu, R. Shao, G. Chen, Y . Zhu, W. Guan, and L. Nie, “Puma: Layer-pruned language model for efficient unified multimodal retrieval with modality-adaptive learning,” in Proceedings of the 33nd ACM International Conference on Multimedia , 2025
work page 2025
-
[9]
Analyzing emotional semantics of abstract art using low-level image features,
H. Zhang, E. Augilius, T. Honkela, J. Laaksonen, H. Gamper, and H. Alene, “Analyzing emotional semantics of abstract art using low-level image features,” in Advances in Intelligent Data Analysis X , J. Gama, E. Bradley, and J. Hollm ´en, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 413–423
work page 2011
-
[10]
Learning deep features for image emotion classification,
M. Chen, L. Zhang, and J. P. Allebach, “Learning deep features for image emotion classification,” in 2015 IEEE International Conference on Image Processing (ICIP) , 2015, pp. 4491–4495
work page 2015
-
[11]
Dependency exploitation: A unified cnn-rnn approach for visual emotion recognition,
X. Zhu, L. Li, W. Zhang, T. Rao, M. Xu, Q. Huang, and D. Xu, “Dependency exploitation: A unified cnn-rnn approach for visual emotion recognition,” in International Joint Conference on Artificial Intelligence, 2017. [Online]. Available: https://api.semanticscholar.org/ CorpusID:4963251
work page 2017
-
[12]
Exploring discriminative representations for image emotion recognition with cnns,
W. Zhang, X. He, and W. Lu, “Exploring discriminative representations for image emotion recognition with cnns,” IEEE Transactions on Mul- timedia, vol. 22, no. 2, pp. 515–523, 2020
work page 2020
-
[13]
Emotion recognition based on con- volutional neural network (cnn),
B. G. K. Reddy, P. Yashwanthsaai, A. R. Raja, A. Jagarlamudi, N. Leeladhar, and T. T. Kumar, “Emotion recognition based on con- volutional neural network (cnn),” in 2021 International Conference on Advancements in Electrical, Electronics, Communication, Computing and Automation (ICAECA) , 2021, pp. 1–5
work page 2021
-
[14]
Solver: Scene-object interrelated visual emotion reasoning network,
J. Yang, X. Gao, L. Li, X. Wang, and J. Ding, “Solver: Scene-object interrelated visual emotion reasoning network,” IEEE Transactions on Image Processing, vol. 30, pp. 8686–8701, 2021
work page 2021
-
[15]
Z. Hu, K. Yuan, X. Liu, Z. Yu, Y . Zong, J. Shi, H. Yue, and J. Yang, “Feallm: Advancing facial emotion analysis in multimodal large lan- guage models with emotional synergy and reasoning,” arXiv preprint arXiv:2505.13419, 2025
-
[16]
Emogen: Emotional image content generation with text-to-image diffusion models,
J. Yang, J. Feng, and H. Huang, “Emogen: Emotional image content generation with text-to-image diffusion models,” in 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . Los Alamitos, CA, USA: IEEE Computer Society, jun 2024, pp. 6358–6368. [Online]. Available: https://doi.ieeecomputersociety.org/10. 1109/CVPR52733.2024.00608
-
[17]
Current state of text sentiment analysis from opinion to emotion mining,
A. Yadollahi, A. G. Shahraki, and O. R. Zaiane, “Current state of text sentiment analysis from opinion to emotion mining,” ACM Computing Surveys (CSUR), vol. 50, no. 2, pp. 1–33, 2017
work page 2017
-
[18]
E. Hsieh and B. Nicodemus, “Conceptualizing emotion in healthcare interpreting: A normative approach to interpreters’ emotion work,” Patient Education and Counseling, vol. 98, no. 12, pp. 1474–1481, 2015
work page 2015
-
[19]
Learning to prompt for vision-language emotion recognition,
H. Xie, H. Chung, H.-H. Shuai, and W.-H. Cheng, “Learning to prompt for vision-language emotion recognition,” in 2023 11th International Conference on Affective Computing and Intelligent Interaction Work- shops and Demos (ACIIW) . IEEE, 2023, pp. 1–4
work page 2023
-
[20]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems , vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[21]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2022, pp. 10 684–10 695
work page 2022
-
[22]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,” Advances in Neural Information Processing Systems, vol. 34, pp. 8780–8794, 2021
work page 2021
-
[23]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2023, pp. 3836–3847
work page 2023
-
[24]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 22 500–22 510
work page 2023
-
[25]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
J. Xie, W. Mao, Z. Bai, D. J. Zhang, W. Wang, K. Q. Lin, Y . Gu, Z. Chen, Z. Yang, and M. Z. Shou, “Show-o: One single transformer to unify multimodal understanding and generation,” arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettlemoyer, and O. Levy, “Transfusion: Predict the next token and diffuse images with one multi-modal model,” arXiv preprint arXiv:2408.11039, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Y . Wu, Z. Zhang, J. Chen, H. Tang, D. Li, Y . Fang, L. Zhu, E. Xie, H. Yin, L. Yi et al. , “Vila-u: a unified foundation model integrating visual understanding and generation,” arXiv preprint arXiv:2409.04429, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Emu3: Next-Token Prediction is All You Need
X. Wang, X. Zhang, Z. Luo, Q. Sun, Y . Cui, J. Wang, F. Zhang, Y . Wang, Z. Li, Q. Yu et al., “Emu3: Next-token prediction is all you need,” arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
ID3: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition,
S. Li, J. Xu, J. Wu, M. Xiong, A. Deng, J. Ji, Y . Huang, W. Feng, S. Ding, and B. Hooi, “ID3: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition,” arXiv preprint arXiv:2409.17576, 2024
-
[30]
Diffusion feedback helps clip see better,
W. Wang, Q. Sun, F. Zhang, Y . Tang, J. Liu, and X. Wang, “Diffusion feedback helps clip see better,” arXiv preprint arXiv:2407.20171, 2024
-
[31]
M. Bar, “Visual objects in context,” Nature Reviews Neuroscience, vol. 5, no. 8, pp. 617–629, 2004
work page 2004
-
[32]
Emotion experience and its varieties,
N. H. Frijda, “Emotion experience and its varieties,” Emotion Review, vol. 1, no. 3, pp. 264–271, 2009
work page 2009
-
[33]
Affective image content analysis: Two decades review and new perspectives,
S. Zhao, X. Yao, J. Yang, G. Jia, G. Ding, T.-S. Chua, B. W. Schuller, and K. Keutzer, “Affective image content analysis: Two decades review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6729–6751, 2022
work page 2022
-
[34]
Fuzzy similarity-based emotional classification of color images,
J. Lee and E. Park, “Fuzzy similarity-based emotional classification of color images,” IEEE Transactions on Multimedia , vol. 13, no. 5, pp. 1031–1039, 2011
work page 2011
-
[35]
Large-scale visual sentiment ontology and detectors using adjective noun pairs,
D. Borth, R. Ji, T. Chen, T. Breuel, and S.-F. Chang, “Large-scale visual sentiment ontology and detectors using adjective noun pairs,” in Proceedings of the 21st ACM International Conference on Multimedia , 2013, pp. 223–232
work page 2013
-
[36]
Affective image classification using features inspired by psychology and art theory,
J. Machajdik and A. Hanbury, “Affective image classification using features inspired by psychology and art theory,” in Proceedings of the 18th ACM International Conference on Multimedia , ser. MM ’10. 13 New York, NY , USA: Association for Computing Machinery, 2010, p. 83–92. [Online]. Available: https://doi.org/10.1145/1873951.1873965
-
[37]
Mdan: Multi-level dependent attention network for visual emotion analysis,
L. Xu, Z. Wang, B. Wu, and S. Lui, “Mdan: Multi-level dependent attention network for visual emotion analysis,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 9469–9478
work page 2022
-
[38]
Learning multi-level deep representations for image emotion classification,
T. Rao, X. Li, and M. Xu, “Learning multi-level deep representations for image emotion classification,” Neural Processing Letters , vol. 51, pp. 2043–2061, 2020
work page 2043
-
[39]
Object semantics sentiment correlation analysis enhanced image sentiment classification,
J. Zhang, M. Chen, H. Sun, D. Li, and Z. Wang, “Object semantics sentiment correlation analysis enhanced image sentiment classification,” Know.-Based Syst. , vol. 191, no. C, Mar. 2020. [Online]. Available: https://doi.org/10.1016/j.knosys.2019.105245
-
[40]
D. Borth, T. Chen, R. Ji, and S.-F. Chang, “Sentibank: large-scale ontology and classifiers for detecting sentiment and emotions in visual content,” in Proceedings of the 21st ACM International Conference on Multimedia, 2013, pp. 459–460
work page 2013
-
[41]
Progressive visual content understanding network for image emotion classification,
J. Pan and S. Wang, “Progressive visual content understanding network for image emotion classification,” in Proceedings of the 31st ACM International Conference on Multimedia , ser. MM ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 6034–6044. [Online]. Available: https://doi.org/10.1145/3581783.3612186
-
[42]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image gen- eration and editing with text-guided diffusion models,” arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,” arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Y . Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, Q. Zhang, K. Kreis, M. Aittala, T. Aila, S. Laine, B. Catanzaro, T. Karras, and M.-Y . Liu, “ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers,” 2023. [Online]. Available: https://arxiv.org/abs/2211.01324
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,” Advances in Neural Information Processing Systems , vol. 35, pp. 36 479–36 494, 2022
work page 2022
-
[46]
Text to image generation with semantic-spatial aware gan,
W. Liao, K. Hu, M. Y . Yang, and B. Rosenhahn, “Text to image generation with semantic-spatial aware gan,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 18 187–18 196
work page 2022
-
[47]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Person- alizing text-to-image generation using textual inversion,” arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Multi- concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y . Zhu, “Multi- concept customization of text-to-image diffusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 1931–1941
work page 2023
-
[49]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning , 2021, pp. 8748–8763
work page 2021
-
[50]
Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation,
Y . Wei, Y . Zhang, Z. Ji, J. Bai, L. Zhang, and W. Zuo, “Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation,” arXiv preprint arXiv:2302.13848 , 2023
-
[51]
Emoedit: Evoking emotions through image manipulation,
J. Yang, J. Feng, W. Luo, D. Lischinski, D. Cohen-Or, and H. Huang, “Emoedit: Evoking emotions through image manipulation,” arXiv preprint arXiv:2405.12661, 2024
-
[52]
C. Li et al., “Emotionprompt: Leveraging psychology for large language models enhancement via emotional stimulus (nd). retrieved 1 august 2023.”
work page 2023
-
[53]
Emoticrafter: Text-to-emotional-image generation based on valence-arousal model,
Y . He, S. Dang, L. Ling, Z. Qian, N. Zhao, and N. Cao, “Emoticrafter: Text-to-emotional-image generation based on valence-arousal model,” arXiv preprint arXiv:2501.05710 , 2025
-
[54]
R. Zhang, R. Shao, G. Chen, K. Zhou, W. Guan, and L. Nie, “Fal- con: Resolving visual redundancy and fragmentation in high-resolution multimodal large language models via visual registers,” arXiv preprint arXiv:2501.16297, 2025
-
[55]
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,
Q. Ye, H. Xu, J. Ye, M. Yan, A. Hu, H. Liu, Q. Qian, J. Zhang, and F. Huang, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” in Proceedings of the ieee/cvf conference on computer vision and pattern recognition , 2024, pp. 13 040–13 051
work page 2024
-
[56]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang et al. , “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Lion-fs: Fast & slow video-language thinker as online video assistant,
W. Li, B. Hu, R. Shao, L. Shen, and L. Nie, “Lion-fs: Fast & slow video-language thinker as online video assistant,” in Proceedings of the Computer Vision and Pattern Recognition Conference , 2025, pp. 3240– 3251
work page 2025
-
[58]
Lion: Empowering multimodal large language model with dual-level visual knowledge,
G. Chen, L. Shen, R. Shao, X. Deng, and L. Nie, “Lion: Empowering multimodal large language model with dual-level visual knowledge,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 540–26 550
work page 2024
-
[59]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision . Springer, 2020, pp. 213– 229
work page 2020
-
[60]
Object-centric learning with slot attention, 2020,
F. Locatello, D. Weissenborn, T. Unterthiner, A. Mahendran, G. Heigold, J. Uszkoreit, A. Dosovitskiy, and T. Kipf, “Object-centric learning with slot attention, 2020,” URL https://arxiv. org/abs, 2006
work page 2020
-
[61]
Exploring plain vision transformer backbones for object detection,
Y . Li, H. Xu, Z. Wang, L. Zhang, and J. Sun, “Exploring plain vision transformer backbones for object detection,” in ECCV, 2022
work page 2022
-
[62]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection,
S. Zhang, Z. Wang, X. Wang, and J. Sun, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” in ICLR, 2023
work page 2023
-
[63]
Extract free dense labels from clip,
C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from clip,” in European conference on computer vision. Springer, 2022, pp. 696–712
work page 2022
-
[64]
Denseclip: Language-guided dense prediction with context-aware prompting,
Y . Rao, W. Zhao, G. Chen, Y . Tang, Z. Zhu, G. Huang, J. Zhou, and J. Lu, “Denseclip: Language-guided dense prediction with context-aware prompting,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2022, pp. 18 082–18 091
work page 2022
-
[65]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
D. Alexey, “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv: 2010.11929 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[66]
Emoset: A large-scale visual emotion dataset with rich attributes,
J. Yang, Q. Huang, T. Ding, D. Lischinski, D. Cohen-Or, and H. Huang, “Emoset: A large-scale visual emotion dataset with rich attributes,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 383–20 394
work page 2023
-
[67]
Building a large scale dataset for image emotion recognition: The fine print and the benchmark,
Q. You, J. Luo, H. Jin, and J. Yang, “Building a large scale dataset for image emotion recognition: The fine print and the benchmark,” in Proceedings of the AAAI conference on artificial intelligence , vol. 30, 2016
work page 2016
-
[68]
Where do emotions come from? predicting the emotion stimuli map,
K.-C. Peng, A. Sadovnik, A. Gallagher, and T. Chen, “Where do emotions come from? predicting the emotion stimuli map,” in2016 IEEE international conference on image processing (ICIP) . IEEE, 2016, pp. 614–618
work page 2016
-
[69]
Robust image sentiment analysis using progressively trained and domain transferred deep networks,
Q. You, J. Luo, H. Jin, and J. Yang, “Robust image sentiment analysis using progressively trained and domain transferred deep networks,” in Proceedings of the AAAI conference on Artificial Intelligence , vol. 29, no. 1, 2015
work page 2015
-
[70]
Emovit: Revolutionizing emotion insights with visual instruction tuning,
H. Xie, C.-J. Peng, Y .-W. Tseng, H.-J. Chen, C.-F. Hsu, H.-H. Shuai, and W.-H. Cheng, “Emovit: Revolutionizing emotion insights with visual instruction tuning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024, pp. 26 596–26 605
work page 2024
-
[71]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in Neural Information Processing Systems , vol. 30, 2017
work page 2017
-
[72]
Learning emotional prompt features with multiple views for visual emotion analysis,
Q. Xu, Y . Wei, S. Yuan, J. Wu, L. Wang, and C. Wu, “Learning emotional prompt features with multiple views for visual emotion analysis,” Information Fusion, vol. 108, p. 102366, 2024
work page 2024
-
[73]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” in International conference on machine learning . PMLR, 2023, pp. 19 730–19 742
work page 2023
-
[74]
Instructblip: towards general-purpose vision-language models with instruction tuning. arxiv,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “Instructblip: towards general-purpose vision-language models with instruction tuning. arxiv,” Preprint posted online on June , vol. 15, no. 2023, p. 4, 2023
work page 2023
-
[75]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al. , “Flamingo: a visual language model for few-shot learning,” Advances in neural information processing systems, vol. 35, pp. 23 716–23 736, 2022
work page 2022
-
[76]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems , vol. 36, 2024
work page 2024
-
[77]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,” International Journal of Computer Vision , vol. 130, no. 9, pp. 2337–2348, 2022
work page 2022
-
[78]
Conditional prompt learning for vision-language models,
——, “Conditional prompt learning for vision-language models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 816–16 825. 14
work page 2022
-
[79]
Simemotion: A simple knowledgeable prompt tuning method for im- age emotion classification,
S. Deng, G. Shi, L. Wu, L. Xing, W. Hu, H. Zhang, and Y . Xiang, “Simemotion: A simple knowledgeable prompt tuning method for im- age emotion classification,” in International Conference on Database Systems for Advanced Applications . Springer, 2022, pp. 222–229
work page 2022
-
[80]
Learning to compose diversified prompts for image emotion classifica- tion,
S. Deng, L. Wu, G. Shi, L. Xing, M. Jian, Y . Xiang, and R. Dong, “Learning to compose diversified prompts for image emotion classifica- tion,” Computational Visual Media , pp. 1–15, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.