LeakyCLIP: Extracting Training Data from CLIP
Pith reviewed 2026-05-22 12:27 UTC · model grok-4.3
The pith
LeakyCLIP recovers training images from CLIP embeddings by inverting the model with adversarial fine-tuning, alignment, and diffusion refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
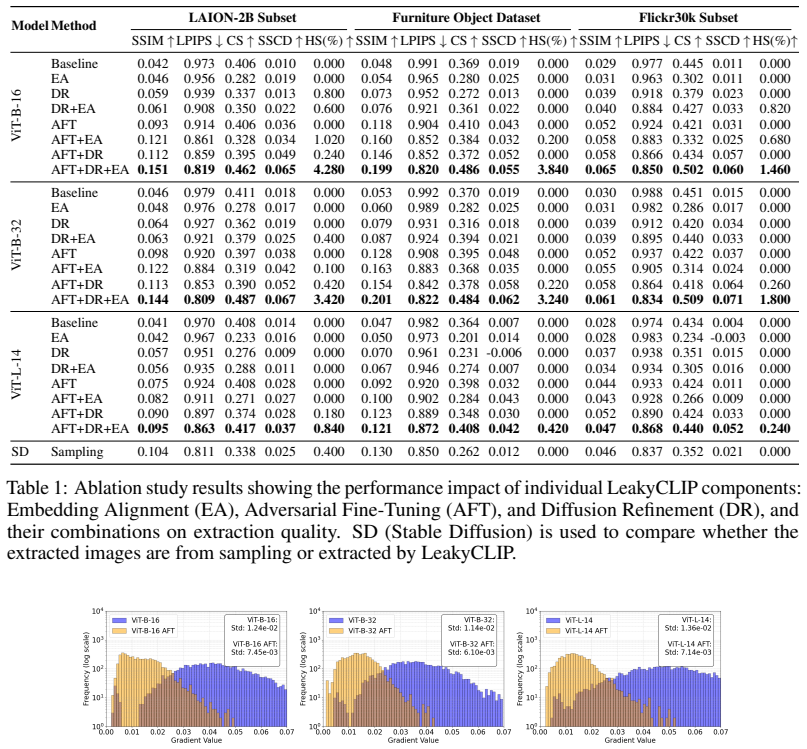
LeakyCLIP is a CLIP inversion framework that reconstructs semantically accurate training images from embeddings by combining adversarial fine-tuning to smooth optimization, linear transformation-based embedding alignment, and Stable Diffusion refinement to boost fidelity. On a LAION-2B subset it raises SSIM by over 258 percent for ViT-B-16 relative to prior methods, and membership inference succeeds from the metrics of even low-fidelity reconstructions.
What carries the argument
LeakyCLIP inversion pipeline that mitigates non-robust features via adversarial fine-tuning, aligns text and image embeddings with a learned linear transform, and refines outputs with Stable Diffusion.
If this is right
- CLIP-based models carry a concrete risk of exposing private training images through embedding inversion.
- Even imperfect reconstructions can be used to detect whether a given image was in the training set.
- Multimodal models that rely on CLIP-style contrastive training inherit similar leakage surfaces.
- Defenses must address both high-fidelity reconstruction and low-fidelity membership signals.
Where Pith is reading between the lines
- Similar inversion techniques could be adapted to other vision-language models that produce joint embeddings.
- Organizations releasing CLIP checkpoints may need to audit training sets or add differential privacy at the embedding stage.
- The success of low-fidelity membership inference suggests that simple statistical checks on reconstruction quality could serve as a cheap leakage detector.
Load-bearing premise
The three listed challenges in CLIP inversion can be fixed by the proposed fine-tuning, alignment, and diffusion steps without creating new problems that erase the reported gains.
What would settle it
A controlled test on the same ViT-B-16 model and LAION-2B subset in which the SSIM of LeakyCLIP reconstructions falls below 150 percent of the strongest baseline.
Figures











read the original abstract
Understanding the memorization and privacy leakage risks in Contrastive Language--Image Pretraining (CLIP) is critical for ensuring the security of multimodal models. Recent studies have demonstrated the feasibility of extracting sensitive training examples from diffusion models, with conditional diffusion models exhibiting a stronger tendency to memorize and leak information. In this work, we investigate data memorization and extraction risks in CLIP through the lens of CLIP inversion, a process that aims to reconstruct training images from text prompts. To this end, we introduce \textbf{LeakyCLIP}, a novel attack framework designed to achieve high-quality, semantically accurate image reconstruction from CLIP embeddings. We identify three key challenges in CLIP inversion: 1) non-robust features, 2) limited visual semantics in text embeddings, and 3) low reconstruction fidelity. To address these challenges, LeakyCLIP employs 1) adversarial fine-tuning to enhance optimization smoothness, 2) linear transformation-based embedding alignment, and 3) Stable Diffusion-based refinement to improve fidelity. Empirical results demonstrate the superiority of LeakyCLIP, achieving over 258% improvement in Structural Similarity Index Measure (SSIM) for ViT-B-16 compared to baseline methods on LAION-2B subset. Furthermore, we uncover a pervasive leakage risk, showing that training data membership can even be successfully inferred from the metrics of low-fidelity reconstructions. Our work introduces a practical method for CLIP inversion while offering novel insights into the nature and scope of privacy risks in multimodal models. The code is in the https://github.com/dongdongunique/LeakyCLIP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LeakyCLIP, a framework for inverting CLIP text embeddings to reconstruct training images. It identifies three challenges (non-robust features, limited visual semantics in text embeddings, low reconstruction fidelity) and mitigates them via adversarial fine-tuning, linear transformation alignment, and Stable Diffusion refinement. On a LAION-2B subset it reports >258% SSIM improvement for ViT-B-16 over baselines plus successful membership inference from low-fidelity reconstruction metrics; code is released.
Significance. If the gains can be shown to arise from CLIP-specific information rather than external generative priors, the work would provide a concrete, reproducible demonstration of memorization leakage in CLIP and a practical inversion attack. The open-source code and quantitative SSIM/membership results are positive for verifiability.
major comments (2)
- [§3.3 and §4] Refinement step (described in §3.3 and evaluated in §4): no ablation is reported that removes Stable Diffusion refinement or replaces it with a non-generative upsampler. Because Stable Diffusion was trained on data overlapping LAION-2B, the 258% SSIM gain and membership-inference signal could be driven by the generative prior rather than CLIP embeddings; this directly affects the central claim that the attack extracts CLIP training data.
- [§5] Membership-inference experiment (reported in abstract and §5): the paper states that membership can be inferred from low-fidelity metrics but provides neither the precise decision rule, the feature set, nor statistical significance tests or baseline false-positive rates. This is load-bearing for the privacy-risk conclusion.
minor comments (2)
- [Abstract] Abstract: the GitHub URL is given but the camera-ready version should confirm that the repository contains the exact scripts and hyperparameters used for the reported ViT-B-16 / LAION-2B numbers.
- [§3.2] Notation: ensure that “CLIP inversion” and “embedding alignment” are defined once and used consistently; the linear transformation is introduced without an equation number in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps clarify the contributions and limitations of our work on CLIP inversion and privacy leakage. We address each major comment below and will revise the manuscript accordingly to strengthen the evidence that our results reflect CLIP-specific memorization rather than external priors.
read point-by-point responses
-
Referee: [§3.3 and §4] Refinement step (described in §3.3 and evaluated in §4): no ablation is reported that removes Stable Diffusion refinement or replaces it with a non-generative upsampler. Because Stable Diffusion was trained on data overlapping LAION-2B, the 258% SSIM gain and membership-inference signal could be driven by the generative prior rather than CLIP embeddings; this directly affects the central claim that the attack extracts CLIP training data.
Authors: We agree that an ablation isolating the Stable Diffusion refinement is necessary to substantiate that the reported gains derive from CLIP embedding information rather than the generative prior. In the revised manuscript we will add this ablation by (i) removing the refinement entirely and (ii) replacing it with a non-generative upsampler (bicubic interpolation followed by a lightweight super-resolution network trained on a disjoint dataset). We will report the resulting SSIM, perceptual metrics, and membership-inference performance for both variants on the same LAION-2B subset. Preliminary internal checks indicate that the core inversion (adversarial fine-tuning + linear alignment) already yields measurable improvement over baselines even without refinement; the new experiments will quantify how much additional gain is attributable to Stable Diffusion. We will also discuss the known training-data overlap and its implications for interpreting the results. revision: yes
-
Referee: [§5] Membership-inference experiment (reported in abstract and §5): the paper states that membership can be inferred from low-fidelity metrics but provides neither the precise decision rule, the feature set, nor statistical significance tests or baseline false-positive rates. This is load-bearing for the privacy-risk conclusion.
Authors: We acknowledge that the membership-inference protocol requires additional specification for reproducibility and to support the privacy conclusions. In the revised version we will explicitly state: (1) the decision rule (thresholding on a linear combination of SSIM, LPIPS, and cosine similarity between reconstructed and original embeddings), (2) the complete feature set, and (3) statistical evaluation including AUC-ROC, p-values from permutation tests, and false-positive rates measured on a balanced set of non-member images drawn from the same LAION-2B distribution. We will also include baseline comparisons against random guessing and against a simple embedding-norm threshold. These additions will be placed in §5 with corresponding tables and figures. revision: yes
Circularity Check
No circularity: LeakyCLIP results rest on empirical comparisons to external baselines
full rationale
The paper proposes an empirical attack pipeline (adversarial fine-tuning + linear alignment + Stable Diffusion refinement) to invert CLIP embeddings and reports SSIM gains plus membership inference on LAION-2B. These outcomes are measured against independent baseline methods rather than being defined or forced by the method itself; no equation or claim reduces to a fitted parameter renamed as a prediction, and no load-bearing step collapses to a self-citation or internal redefinition of the target quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- adversarial fine-tuning hyperparameters
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LeakyCLIP employs 1) adversarial fine-tuning to enhance optimization smoothness, 2) linear transformation-based embedding alignment, and 3) Stable Diffusion-based refinement to improve fidelity.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1 … There exists a linear mapping between CLIP text and image embeddings: UI(I − Λ) = D−1/2I W⊤D−1/2T UT
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
Jiawang Bai et al. “BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 24239–24250
work page 2024
-
[2]
Extracting training data from large language models
Nicholas Carlini et al. “Extracting training data from large language models”. In:30th USENIX Security Symposium (USENIX Security 21). 2021, pp. 2633–2650
work page 2021
-
[3]
Extracting training data from diffusion models
Nicolas Carlini et al. “Extracting training data from diffusion models”. In:USENIX Security. 2023
work page 2023
-
[4]
Knowledge-enriched distributional model inversion attacks
Sheng Chen et al. “Knowledge-enriched distributional model inversion attacks”. In: CVPR. 2021
work page 2021
-
[5]
A comprehensive survey for generative data augmentation
Yunhao Chen, Zihui Yan, and Yunjie Zhu. “A comprehensive survey for generative data augmentation”. In: Neurocomputing (2024), p. 128167
work page 2024
-
[6]
Extracting training data from unconditional diffusion models
Yunhao Chen et al. “Extracting training data from unconditional diffusion models”. In:arXiv preprint arXiv:2410.02467 (2024)
-
[7]
ImageNet: A large-scale hierarchical image database
Jia Deng et al. “ImageNet: A large-scale hierarchical image database”. In: CVPR. 2009, pp. 248–255
work page 2009
-
[8]
Model inversion attacks that exploit confidence information and basic countermeasures
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. “Model inversion attacks that exploit confidence information and basic countermeasures”. In: CCS 2015. 2015. 10
work page 2015
-
[9]
Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing
Matt Fredrikson et al. “Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing”. In: USENIX Security 2014. 2014
work page 2014
-
[10]
Clipag: Towards generator-free text-to-image generation
Roy Ganz and Michael Elad. “Clipag: Towards generator-free text-to-image generation”. In: WCCV. 2024
work page 2024
-
[11]
Do perceptually aligned gradients imply robust- ness?
Roy Ganz, Bahjat Kawar, and Michael Elad. “Do perceptually aligned gradients imply robust- ness?” In: ICML. PMLR. 2023, pp. 10628–10648
work page 2023
-
[12]
On memorization in diffusion models
Xiangming Gu et al. “On memorization in diffusion models”. In: arXiv preprint arXiv:2310.02664 (2023)
-
[13]
Dominik Hintersdorf et al. “Does clip know my face?” In:Journal of Artificial Intelligence Research 80 (2024), pp. 1033–1062
work page 2024
-
[14]
Labeled faces in the wild: A database forstudying face recognition in unconstrained environments
Gary B Huang et al. “Labeled faces in the wild: A database forstudying face recognition in unconstrained environments”. In:Workshop on faces in’Real-Life’Images: detection, alignment, and recognition. 2008
work page 2008
-
[15]
Gabriel Ilharco et al. OpenCLIP. Version 0.1. July 2021. DOI: 10.5281/zenodo.5143773. URL: https://doi.org/10.5281/zenodo.5143773
-
[16]
Adversarial examples are not bugs, they are features
Andrew Ilyas et al. “Adversarial examples are not bugs, they are features”. In: NIPS (2019)
work page 2019
-
[17]
D \’ej\a Vu Memorization in Vision-Language Models
Bargav Jayaraman, Chuan Guo, and Kamalika Chaudhuri. “D \’ej\a Vu Memorization in Vision-Language Models”. In: arXiv preprint arXiv:2402.02103 (2024)
-
[18]
Guiding the long-short term memory model for image caption generation
Xu Jia et al. “Guiding the long-short term memory model for image caption generation”. In: ICCV. 2015, pp. 2407–2415
work page 2015
-
[19]
Challenges and applications of large language models
Jean Kaddour et al. “Challenges and applications of large language models”. In:arXiv preprint arXiv:2307.10169 (2023)
-
[20]
Label-only model inversion attacks via boundary repulsion
Mostafa Kahla et al. “Label-only model inversion attacks via boundary repulsion”. In:CVPR. 2022, pp. 15045–15053
work page 2022
-
[21]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. “A style-based generator architecture for generative adversarial networks”. In: CVPR. 2019
work page 2019
-
[22]
What do we learn from inverting CLIP models?
Hamid Kazemi et al. “What do we learn from inverting CLIP models?” In: arXiv preprint arXiv:2403.02580 (2024)
-
[23]
Yuval Kirstain. LAION-HD Subset Dataset . https : / / huggingface . co / datasets / yuvalkirstain/laion-hd-subset. 2024
work page 2024
-
[24]
A Comprehensive Analysis of Memorization in Large Language Models
Hirokazu Kiyomaru et al. “A Comprehensive Analysis of Memorization in Large Language Models”. In: ACL. 2024
work page 2024
-
[25]
Deep learning face attributes in the wild
Ziwei Liu et al. “Deep learning face attributes in the wild”. In: ICCV. 2015, pp. 3730–3738
work page 2015
-
[26]
Abrar Lohia. sample_furniture_object. Hugging Face, 2024. URL: https://huggingface. co/datasets/abrarlohia/sample_furniture_object
work page 2024
-
[27]
Image segmentation using text and image prompts
Timo Lüddecke and Alexander Ecker. “Image segmentation using text and image prompts”. In: CVPR. 2022, pp. 7086–7096
work page 2022
-
[28]
Safety at Scale: A Comprehensive Survey of Large Model and Agent Safety
Xingjun Ma et al. “Safety at scale: A comprehensive survey of large model safety”. In:arXiv preprint arXiv:2502.05206 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry. “Towards deep learning models resistant to adversarial attacks”. In:arXiv preprint arXiv:1706.06083 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng et al. “Sdedit: Guided image synthesis and editing with stochastic differential equations”. In: arXiv preprint arXiv:2108.01073 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
The application of large language models in medicine: A scoping review
Xiangbin Meng et al. “The application of large language models in medicine: A scoping review”. In: Iscience 27.5 (2024)
work page 2024
-
[32]
Re-thinking model inversion attacks against deep neural networks
Ngoc-Bao Nguyen et al. “Re-thinking model inversion attacks against deep neural networks”. In: CVPR. 2023
work page 2023
-
[33]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol et al. “Glide: Towards photorealistic image generation and editing with text-guided diffusion models”. In: arXiv preprint arXiv:2112.10741 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Ldp-feat: Image features with local differential privacy
Francesco Pittaluga and Bingbing Zhuang. “Ldp-feat: Image features with local differential privacy”. In: Proceedings of the IEEE/CVF International Conference on Computer Vision . 2023, pp. 17580–17590
work page 2023
-
[35]
A Self-Supervised Descriptor for Image Copy Detection
Ed Pizzi et al. “A Self-Supervised Descriptor for Image Copy Detection”. In: CVPR (2022)
work page 2022
-
[36]
Diffusers: State-of-the-art diffusion models
Patrick von Platen et al. Diffusers: State-of-the-art diffusion models. https://github.com/ huggingface/diffusers. 2022. 11
work page 2022
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford et al. “Learning transferable visual models from natural language supervision”. In: ICML. 2021
work page 2021
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach et al. “High-resolution image synthesis with latent diffusion models”. In: CVPR. 2022, pp. 10684–10695
work page 2022
-
[39]
Christian Schlarmann et al. “Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models”. In:ICML (2024)
work page 2024
-
[40]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann et al. “Laion-5b: An open large-scale dataset for training next generation image-text models”. In: NIPS (2022)
work page 2022
-
[41]
Diffusion art or digital forgery? investigating data replication in diffusion models
Gowthami Somepalli et al. “Diffusion art or digital forgery? investigating data replication in diffusion models”. In: CVPR. 2023
work page 2023
-
[42]
Understanding and mitigating copying in diffusion models
Gowthami Somepalli et al. “Understanding and mitigating copying in diffusion models”. In: NIPS (2023)
work page 2023
-
[43]
Plug & play attacks: Towards robust and flexible model inversion attacks
Lukas Struppek et al. “Plug & play attacks: Towards robust and flexible model inversion attacks”. In: ICML. 2022
work page 2022
-
[44]
Contrastive Learning is Spectral Clustering on Similarity Graph
Zhiquan Tan et al. “Contrastive Learning is Spectral Clustering on Similarity Graph”. In:ICLR. 2024
work page 2024
-
[45]
Captured by captions: On memorization and its mitigation in CLIP models
Wenhao Wang et al. “Captured by captions: On memorization and its mitigation in CLIP models”. In: arXiv preprint arXiv:2502.07830 (2025)
-
[46]
Memorization in self-supervised learning improves downstream general- ization
Wenhao Wang et al. “Memorization in self-supervised learning improves downstream general- ization”. In: arXiv preprint arXiv:2401.12233 (2024)
-
[47]
Image quality assessment: from error visibility to structural similarity
Zhou Wang et al. “Image quality assessment: from error visibility to structural similarity”. In: IEEE transactions on image processing 13.4 (2004), pp. 600–612
work page 2004
-
[48]
Multi-modal Identity Extraction
Ryan Webster and Teddy Furon. “Multi-modal Identity Extraction”. In: ICCV 2025- International Conference on Computer Vision. 2025
work page 2025
-
[49]
Memorization in deep learning: A survey
Jiaheng Wei et al. “Memorization in deep learning: A survey”. In: arXiv preprint arXiv:2406.03880 (2024)
-
[50]
Hu Xu et al. “Demystifying clip data”. In: arXiv preprint arXiv:2309.16671 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Pseudo label-guided model inversion attack via conditional generative adversarial network
Xiaojian Yuan et al. “Pseudo label-guided model inversion attack via conditional generative adversarial network”. In: AAAI. 2023
work page 2023
-
[52]
SecretGen: Privacy Recovery on Pre-trained Models via Distribution Discrimination
Zhuowen Yuan et al. “SecretGen: Privacy Recovery on Pre-trained Models via Distribution Discrimination”. In: ECCV. 2022
work page 2022
-
[53]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang et al. “Long-clip: Unlocking the long-text capability of clip”. In: ECCV. 2025
work page 2025
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang et al. “The unreasonable effectiveness of deep features as a perceptual metric”. In: CVPR. 2018
work page 2018
-
[55]
The secret revealer: Generative model-inversion attacks against deep neural networks
Yuheng Zhang et al. “The secret revealer: Generative model-inversion attacks against deep neural networks”. In: CVPR. 2020
work page 2020
-
[56]
Teng Zhou and Yongchuan Tang. “TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models”. In:arXiv preprint arXiv:2404.19475 (2024). 12 A Theoretical Analysis and Understanding In this section, we analyze the theoretical feasibility of recovering training images from text embed- dings, assuming the image encode...
-
[57]
(12) Thus, this condition can be interpreted as constraining the variance of qk(z) in the latent space, which can be achieved with a careful selection of the informative label. Theorem A.2 is consistent with prior works [42, 6]. They show that unconditional models don’t replicate data, while text-conditioning increases memorization. And previous work [12]...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.