Evaluating Angle and Amplitude Encoding Strategies for Variational Quantum Machine Learning: their impact on model's accuracy
Pith reviewed 2026-05-19 01:24 UTC · model grok-4.3
The pith
Different data encoding methods in variational quantum circuits can shift classification accuracy by 10 to 41 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
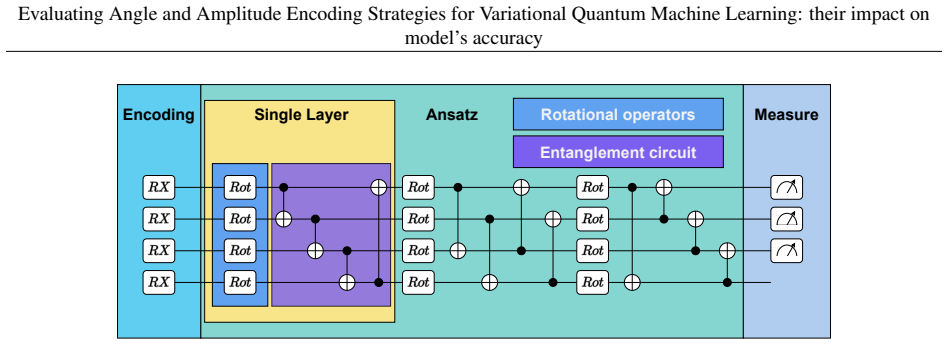
Under identical model topologies, the difference in accuracy between the best and worst models ranges from 10% to 30%, with differences reaching up to 41%. The choice of rotational gates used in encoding can significantly impact the model's classification performance. The embedding represents a hyperparameter for VQC models.
What carries the argument
The encoding layer that loads classical data via angle or amplitude encoding using rotational gates such as RX, RY, or RZ.
If this is right
- Encoding must be optimized as a hyperparameter when building variational quantum classifiers.
- Rotational gate selection inside the encoding layer drives measurable accuracy changes on the Wine and Diabetes datasets.
- Amplitude and angle encodings are not interchangeable without risking large performance shifts.
- Systematic comparison of embedding options is required to reach reliable VQC results.
Where Pith is reading between the lines
- The magnitude of the accuracy gap may depend on dataset size or feature distribution.
- Encoding selection could interact with circuit depth or entanglement structure in ways the fixed-topology tests do not reveal.
- Automated hyperparameter searches for VQCs should include encoding strategies as a searchable dimension.
Load-bearing premise
All compared models differ only in the encoding layer and rotational gates while sharing identical ansatz topology, training procedure, optimizer settings, and hyperparameter search effort.
What would settle it
Repeating the experiments on the Wine and Diabetes datasets and measuring accuracy differences below 5 percent across every encoding variant would falsify the claim of significant impact from the encoding choice.
Figures















read the original abstract
Recent advancements in Quantum Computing and Machine Learning have increased attention to Quantum Machine Learning (QML), which aims to develop machine learning models by exploiting the quantum computing paradigm. One of the widely used models in this area is the Variational Quantum Circuit (VQC), a hybrid model where the quantum circuit handles data inference while classical optimization adjusts the parameters of the circuit. The quantum circuit consists of an encoding layer, which loads data into the circuit, and a template circuit, known as the ansatz, responsible for processing the data. This work involves performing an analysis by considering both Amplitude- and Angle-encoding models, and examining how the type of rotational gate applied affects the classification performance of the model. This comparison is carried out by training the different models on two datasets, Wine and Diabetes, and evaluating their performance. The study demonstrates that, under identical model topologies, the difference in accuracy between the best and worst models ranges from 10% to 30%, with differences reaching up to 41%. Moreover, the results highlight how the choice of rotational gates used in encoding can significantly impact the model's classification performance. The findings confirm that the embedding represents a hyperparameter for VQC models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript performs an empirical comparison of amplitude encoding versus angle encoding (with RX, RY, or RZ rotational gates) inside variational quantum circuits for binary classification on the Wine and Diabetes datasets. It reports that, under identical model topologies, accuracy differences between the best and worst encoding choices range from 10% to 30% and can reach 41%, concluding that the embedding layer constitutes an important hyperparameter for VQC models.
Significance. If the observed accuracy gaps can be shown to arise solely from the encoding choice with all other circuit and training elements held fixed, the result would usefully alert practitioners that encoding strategy is a first-order design decision in VQML rather than a neutral preprocessing step. The work is otherwise a straightforward empirical study without new theoretical derivations or machine-checked proofs.
major comments (2)
- Abstract and §3 (Methods): the central claim that accuracy differences of 10–41% are attributable to encoding alone rests on the assertion of 'identical model topologies' and 'training procedure.' No table or section enumerates the exact ansatz depth, entanglement pattern, number of layers, optimizer (e.g., Adam vs. SPSA), learning-rate schedule, epoch count, or initialization seed that were used uniformly across all six encoding variants. Without an explicit statement or supplementary table confirming that these elements were not re-tuned per encoding, the gaps could reflect optimization disparity rather than encoding expressivity.
- Abstract: accuracy ranges are stated without error bars, standard deviations across random seeds, or any statistical test (paired t-test, Wilcoxon, etc.). A 10–41% spread cannot be interpreted as decisive evidence that embedding is a 'hyperparameter' until the reader can assess whether the differences exceed run-to-run variability.
minor comments (2)
- The manuscript would benefit from a single consolidated table listing, for each encoding variant, the final test accuracy, training accuracy, and at least one measure of variability.
- Figure captions and axis labels should explicitly state the number of qubits, the dataset split ratio, and the classical optimizer used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our empirical results. We address each major point below and have revised the manuscript to improve transparency and statistical rigor.
read point-by-point responses
-
Referee: Abstract and §3 (Methods): the central claim that accuracy differences of 10–41% are attributable to encoding alone rests on the assertion of 'identical model topologies' and 'training procedure.' No table or section enumerates the exact ansatz depth, entanglement pattern, number of layers, optimizer (e.g., Adam vs. SPSA), learning-rate schedule, epoch count, or initialization seed that were used uniformly across all six encoding variants. Without an explicit statement or supplementary table confirming that these elements were not re-tuned per encoding, the gaps could reflect optimization disparity rather than encoding expressivity.
Authors: We agree that explicit documentation is required to substantiate the claim of identical topologies and procedures. The original manuscript asserted this but did not provide a consolidated list. In the revision we have added Table 1 in Section 3 that enumerates all fixed elements: ansatz depth of 2 layers with linear entanglement, COBYLA optimizer, 100 epochs, and a fixed random seed of 42 for all runs. No per-encoding hyperparameter retuning occurred; the only variation was the choice of encoding gate (RX, RY, RZ) or amplitude encoding. This table makes the experimental controls fully reproducible. revision: yes
-
Referee: Abstract: accuracy ranges are stated without error bars, standard deviations across random seeds, or any statistical test (paired t-test, Wilcoxon, etc.). A 10–41% spread cannot be interpreted as decisive evidence that embedding is a 'hyperparameter' until the reader can assess whether the differences exceed run-to-run variability.
Authors: We acknowledge the absence of variability measures in the original submission. We have re-executed all experiments across 10 independent random seeds per encoding variant and now report mean accuracy with standard deviation in both the abstract and results tables. Paired t-tests between the best and worst encoding strategies yield p < 0.01 on the Wine dataset and p < 0.05 on the Diabetes dataset, confirming that the observed gaps exceed run-to-run variability. These additions directly support the interpretation that encoding choice functions as a first-order hyperparameter. revision: yes
Circularity Check
No circularity: direct empirical comparison without derivations or self-referential reductions
full rationale
The manuscript is a straightforward empirical study that trains and evaluates multiple VQC variants on the Wine and Diabetes datasets, reporting observed accuracy differences (10-41%) across encoding choices. No equations, ansatzes, uniqueness theorems, or predictive derivations appear in the text. The central claim rests on experimental controls (identical topologies and training procedures) rather than any reduction of results to quantities defined or fitted inside the paper itself. Self-citations, if present, are not load-bearing for any derivation chain. This qualifies as a self-contained empirical evaluation with no circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The study demonstrates that, under identical model topologies, the difference in accuracy between the best and worst models ranges from 10% to 30%, with differences reaching up to 41%. ... the embedding represents a hyperparameter for VQC models.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Angle encoding ... each feature is encoded on a different qubit ... |ψ⟩ = (⊗N−1i=0 R(xi)) |00...0⟩
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Russell and P. Norvig, Artificial Intelligence A Modern Approach, Global Edition
-
[2]
Machine learning: Trends, perspectives, and prospects,
M. I. Jordan and T. M. Mitchell, “Machine learning: Trends, perspectives, and prospects,” Science, vol. 349, no. 6245, pp. 255–260, 2015
work page 2015
-
[3]
M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, 2010
work page 2010
-
[4]
S. Lloyd, “Universal quantum simulators,” Science, vol. 273, no. 5278, pp. 1073–1078, 1996
work page 1996
-
[5]
Algorithms for quantum computation: discrete logarithms and factoring,
P. Shor, “Algorithms for quantum computation: discrete logarithms and factoring,” in Proceedings 35th Annual Symposium on Foundations of Computer Science, 1994, pp. 124–134
work page 1994
-
[6]
Proceedings of the Twenty-Eighth Annual
L. K. Grover, “A fast quantum mechanical algorithm for database search,” in Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, ser. STOC ’96. New York, NY , USA: Association for Computing Machinery, 1996, p. 212–219. [Online]. Available: https://doi.org/10.1145/237814.237866
-
[7]
An introduction to quantum machine learning,
M. Schuld, I. Sinayskiy, and F. Petruccione, “An introduction to quantum machine learning,” Contemporary Physics, vol. 56, no. 2, pp. 172–185, Apr 2015
work page 2015
-
[8]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,”Nature, vol. 549, no. 7671, pp. 195–202, Sep. 2017
work page 2017
-
[9]
Quantum machine learning: a classical perspective,
C. Ciliberto, M. Herbster, A. D. Ialongo, M. Pontil, A. Rocchetto, S. Severini, and L. Wossnig, “Quantum machine learning: a classical perspective,” Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 474, no. 2209, p. 20170551, 2018
work page 2018
-
[10]
Quantum machine learning in feature hilbert spaces,
M. Schuld and N. Killoran, “Quantum machine learning in feature hilbert spaces,” Phys. Rev. Lett., vol. 122, p. 040504, Feb 2019
work page 2019
-
[11]
Circuit-centric quantum classifiers,
M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, “Circuit-centric quantum classifiers,” Phys. Rev. A, vol. 101, p. 032308, Mar 2020
work page 2020
-
[12]
Quantum machine learning in high energy physics,
W. Guan, G. Perdue, A. Pesah, M. Schuld, K. Terashi, S. Vallecorsa, and J.-R. Vlimant, “Quantum machine learning in high energy physics,” Machine Learning: Science and Technology, vol. 2, no. 1, p. 011003, mar 2021
work page 2021
-
[13]
Quantum machine learning for drowsiness detection with eeg signals,
I. D. Lins, L. M. M. Ara ´ujo, C. B. S. Maior, P. M. da Silva Ramos, M. J. das Chagas Moura, A. J. Ferreira-Martins, R. Chaves, and A. Canabarro, “Quantum machine learning for drowsiness detection with eeg signals,” Process Safety and Environmental Protection, vol. 186, pp. 1197–1213, 2024. [Online]. Available: https://www.sciencedirect.com/science/articl...
work page 2024
-
[14]
Perspectives of quantum computing for chemical engineering,
D. E. Bernal, A. Ajagekar, S. M. Harwood, S. T. Stober, D. Trenev, and F. You, “Perspectives of quantum computing for chemical engineering,” AIChE Journal, vol. 68, no. 6, p. e17651, 2022. [Online]. Available: https://aiche.onlinelibrary.wiley.com/doi/abs/10.1002/aic.17651
-
[15]
S. Mensa, E. Sahin, F. Tacchino, P. K. Barkoutsos, and I. Tavernelli, “Quantum machine learning framework for virtual screening in drug discovery: a prospective quantum advantage,” Machine Learning: Science and Technology, vol. 4, no. 1, p. 015023, feb 2023
work page 2023
-
[16]
Quantum convolutional neural networks,
I. Cong, S. Choi, and M. D. Lukin, “Quantum convolutional neural networks,” Nature Physics, vol. 15, no. 12, pp. 1273–1278, Dec. 2019
work page 2019
-
[17]
Path planning for cellular-connected uav: A drl solution with quantum- inspired experience replay,
Y . Li, A. H. Aghvami, and D. Dong, “Path planning for cellular-connected uav: A drl solution with quantum- inspired experience replay,” IEEE Transactions on Wireless Communications, vol. 21, no. 10, pp. 7897–7912, 2022
work page 2022
-
[18]
Challenges and opportunities in quantum machine learning,
M. Cerezo, G. Verdon, H.-Y . Huang, L. Cincio, and P. J. Coles, “Challenges and opportunities in quantum machine learning,”Nature Computational Science, vol. 2, no. 9, pp. 567–576, Sep. 2022
work page 2022
-
[19]
Opportunities and challenges for quantum- assisted machine learning in near-term quantum computers,
A. Perdomo-Ortiz, M. Benedetti, J. Realpe-G ´omez, and R. Biswas, “Opportunities and challenges for quantum- assisted machine learning in near-term quantum computers,” Quantum Science and Technology, vol. 3, no. 3, p. 030502, jun 2018. 21 Evaluating Angle and Amplitude Encoding Strategies for Variational Quantum Machine Learning: their impact on model’s accuracy
work page 2018
-
[20]
Quantum embeddings for machine learning,
S. Lloyd, M. Schuld, A. Ijaz, J. Izaac, and N. Killoran, “Quantum embeddings for machine learning,” 2020
work page 2020
-
[21]
Data re-uploading for a universal quantum classifier,
A. P ´erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,”Quantum
-
[22]
Effect of data encoding on the expressive power of variational quantum- machine-learning models,
M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum- machine-learning models,”Phys. Rev. A, vol. 103, p. 032430, Mar 2021
work page 2021
-
[23]
Variational quantum algorithms,
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, “Variational quantum algorithms,”Nature Reviews Physics, vol. 3, no. 9, pp. 625–644, Sep. 2021
work page 2021
-
[24]
M. Schuld and F. Petruccione, Supervised learning with quantum computers. Springer, 2018, vol. 17
work page 2018
- [25]
-
[26]
“Diabetes dataset,” https://www.kaggle.com/datasets/mathchi/diabetes-data-set, accessed: March 2024
work page 2024
-
[27]
Pennylane: Automatic differentiation of hybrid quantum- classical computations,
V . Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V . Ajith, M. S. Alam, G. Alonso-Linaje, B. Akash- Narayanan, A. Asadi, J. M. Arrazola, U. Azad, S. Banning, C. Blank, T. R. Bromley, B. A. Cordier, J. Ceroni, A. Delgado, O. D. Matteo, A. Dusko, T. Garg, D. Guala, A. Hayes, R. Hill, A. Ijaz, T. Isacsson, D. Ittah, S. Ja- hangiri, P. Jain, E. Jiang,...
work page 2022
-
[28]
R. Fauzi, M. Zarlis, H. Mawengkang, and P. Sihombing, “Analysis of several quantum encoding methods implemented on a quantum circuit architecture to improve classification accuracy,” in 2022 6th International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), 2022, pp. 152–154
work page 2022
-
[29]
Tensorflow quantum: Impacts of quantum state preparation on quantum machine learning performance,
D. Sierra-Sosa, M. Telahun, and A. Elmaghraby, “Tensorflow quantum: Impacts of quantum state preparation on quantum machine learning performance,”IEEE Access, vol. 8, pp. 215 246–215 255, 2020
work page 2020
-
[30]
Data rotation and its influence on quantum encoding,
D. Sierra-Sosa, S. Pal, and M. Telahun, “Data rotation and its influence on quantum encoding,” Quantum Information Processing, vol. 22, no. 1, p. 89, Jan 2023
work page 2023
-
[31]
In: IEEE International Conference on Quantum Computing and Engineering (QCE)
A. Matic, M. Monnet, J. Lorenz, B. Schachtner, and T. Messerer, “Quantum-classical convolutional neural networks in radiological image classification,” in 2022 IEEE International Conference on Quantum Computing and Engineering (QCE). Los Alamitos, CA, USA: IEEE Computer Society, sep 2022, pp. 56–66. [Online]. Available: https://doi.ieeecomputersociety.org...
-
[32]
Understanding the effects of data encoding on quantum-classical convolutional neural networks,
M. Monnet, N. Chaabani, T.-A. Dragan, B. Schachtner, and J. M. Lorenz, “Understanding the effects of data encoding on quantum-classical convolutional neural networks,” 2024. [Online]. Available: https://arxiv.org/abs/2405.03027
-
[33]
M. A. Nielsen and I. L. Chuang, Quantum computation and quantum information. Cambridge university press, 2010
work page 2010
-
[34]
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning. MIT Press, 2016
work page 2016
-
[35]
The balanced accuracy and its posterior distribution,
K. H. Brodersen, C. S. Ong, K. E. Stephan, and J. M. Buhmann, “The balanced accuracy and its posterior distribution,” in2010 20th International Conference on Pattern Recognition, 2010, pp. 3121–3124
work page 2010
-
[36]
Classification with quantum neural networks on near term processors,
E. Farhi and H. Neven, “Classification with quantum neural networks on near term processors,”arXiv: Quantum Physics, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:119037649
work page 2018
-
[37]
Expressive power of parametrized quantum circuits,
Y . Du, M.-H. Hsieh, T. Liu, and D. Tao, “Expressive power of parametrized quantum circuits,”Phys. Rev. Res., vol. 2, p. 033125, Jul 2020. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevResearch.2.033125
-
[38]
S. Sim, P. D. Johnson, and A. Aspuru-Guzik, “Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms,” Advanced Quantum Technologies, vol. 2, no. 12, p. 1900070, 2019. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/qute.201900070
-
[39]
Transformation of quantum states using uniformly controlled rotations,
M. Mottonen, J. J. Vartiainen, V . Bergholm, and M. M. Salomaa, “Transformation of quantum states using uniformly controlled rotations,” 2004
work page 2004
-
[40]
Quantum convolutional neural network for classical data classification,
T. Hur, L. Kim, and D. K. Park, “Quantum convolutional neural network for classical data classification,” Quantum Machine Intelligence, vol. 4, no. 1, p. 3, Feb 2022. [Online]. Available: https://doi.org/10.1007/s42484-021-00061-x 22 Evaluating Angle and Amplitude Encoding Strategies for Variational Quantum Machine Learning: their impact on model’s accuracy
-
[41]
Quantum convolutional neural network based on variational quantum circuits,
L.-H. Gong, J.-J. Pei, T.-F. Zhang, and N.-R. Zhou, “Quantum convolutional neural network based on variational quantum circuits,” Optics Communications, vol. 550, p. 129993, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0030401823007411
work page 2024
-
[42]
Encoding patterns for quantum algorithms,
M. Weigold, J. Barzen, F. Leymann, and M. Salm, “Encoding patterns for quantum algorithms,” IET Quantum Communication, vol. 2, no. 4, pp. 141–152, 2021. [Online]. Available: https: //ietresearch.onlinelibrary.wiley.com/doi/abs/10.1049/qtc2.12032
-
[43]
Data re-uploading for a universal quantum classifier,
A. P ´erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,”Quantum, vol. 4, p. 226, 2020
work page 2020
-
[44]
“Strongly entangling layers,” https://docs.pennylane.ai/en/stable/code/api/pennylane.StronglyEntanglingLayers. html, accessed: March 2024
work page 2024
-
[45]
S. Wold, K. Esbensen, and P. Geladi, “Principal component analysis,” Chemometrics and intelligent laboratory systems, vol. 2, no. 1-3, pp. 37–52, 1987
work page 1987
-
[46]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017
work page 2017
-
[47]
Automatic differentiation in pytorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” inNIPS 2017 Workshop on Autodiff, 2017
work page 2017
-
[48]
Intel Xeon Gold 6134 processor - product specification,
“Intel Xeon Gold 6134 processor - product specification,” [Online] https://ark.intel.com/content/www/us/en/ark/ products/120493/intel-xeon-gold-6134-processor-24-75m-cache-3-20-ghz.html, accessed 25-October-2021. 23
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.