Synthetic POMDPs to Challenge Memory-Augmented RL: Memory Demand Structure Modeling
Pith reviewed 2026-05-19 01:02 UTC · model grok-4.3
The pith
Researchers can now construct POMDPs whose memory requirements are set in advance through a defined structure and construction rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that POMDPs can be synthesized with a predetermined Memory Demand Structure by starting from linear dynamical systems, applying state aggregation to control observability, and redistributing rewards to align incentives with the required memory usage, yielding a practical suite of lightweight environments whose memory demands scale predictably.
What carries the argument
Memory Demand Structure (MDS), a model of the precise patterns of historical information retention needed to solve the POMDP, which is realized by combining linear dynamics with aggregation and reward adjustment.
If this is right
- Evaluation of memory architectures becomes more interpretable because the exact retention pattern each environment requires is known in advance.
- POMDP design guidelines emerge that let researchers target particular memory weaknesses rather than relying on ad-hoc partial observability.
- Lightweight synthetic environments allow rapid iteration and scaling of tests without the computational overhead of complex simulators.
- Selection of memory models for downstream tasks can be guided by matching an agent's capabilities to the MDS profile of the target environment.
Where Pith is reading between the lines
- The same construction pipeline could be adapted to generate families of environments that isolate other partial-observability features such as delayed rewards or stochastic transitions.
- Benchmarks built this way might serve as diagnostic tools to map which memory mechanisms handle which classes of history dependence.
- If the MDS formalism proves robust, it could influence how memory modules are regularized during training by providing explicit targets for what must be remembered.
Load-bearing premise
Linear dynamics plus state aggregation and reward redistribution are sufficient to create POMDPs whose memory demands match the ones that matter for real memory-augmented RL agents.
What would settle it
Run a set of memory-augmented agents on both the synthetic POMDPs and standard benchmarks; if the relative performance rankings or required history lengths fail to align with the MDS predictions, the construction method does not transfer the intended challenges.
Figures














read the original abstract
Recent benchmarks for memory-augmented reinforcement learning (RL) have introduced partially observable Markov decision process (POMDP) environments in which agents must use historical observations to make decisions. However, these benchmarks often lack fine-grained control over the challenges posed to memory models. Synthetic environments offer a solution, enabling precise manipulation of environment dynamics for rigorous and interpretable evaluation of memory-augmented RL. This paper advances the design of such customizable POMDPs with three key contributions: (1) a theoretical framework for analyzing POMDPs based on Memory Demand Structure (MDS) and related concepts; (2) a methodology using linear dynamics, state aggregation, and reward redistribution to construct POMDPs with predefined MDS; and (3) a suite of lightweight, scalable POMDP environments with tunable difficulty, grounded in our theoretical insights. Overall, our work clarifies core challenges in partially observable RL, offers principled guidelines for POMDP design, and aids in selecting and developing suitable memory architectures for RL tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a theoretical framework for analyzing POMDPs via Memory Demand Structure (MDS) and related concepts, presents a construction methodology based on linear dynamics, state aggregation, and reward redistribution to generate POMDPs with user-specified MDS, and releases a suite of lightweight, scalable synthetic POMDP environments with tunable difficulty for benchmarking memory-augmented RL agents.
Significance. If the central construction is shown to produce observation sequences whose optimal policies genuinely require the targeted history-dependent beliefs matching the prescribed MDS, the work would supply a much-needed controllable testbed for memory-augmented RL. This would allow systematic isolation of memory depth requirements and clearer comparisons among recurrent, transformer, and memory-augmented architectures, addressing a clear gap in existing POMDP benchmarks that lack fine-grained control over non-Markovian structure.
major comments (2)
- [§3] §3 (Methodology): The claim that linear dynamics plus state aggregation and reward redistribution yield POMDPs whose memory demand exactly matches a pre-specified MDS parameter is load-bearing for the entire contribution, yet the manuscript provides no theorem, proposition, or empirical diagnostic demonstrating that the resulting transition and observation kernels force history dependence of the claimed length. In particular, it is not shown that the aggregated process remains non-Markovian once the policy is optimized, nor that short-horizon recurrent agents fail while longer-memory agents succeed precisely at the MDS-specified depth.
- [§4] §4 (Environment suite): The tunable difficulty parameters are presented as directly controlling MDS, but no ablation or sensitivity analysis is reported that isolates the effect of each construction knob (e.g., aggregation granularity versus reward redistribution) on the minimal memory length required by an optimal policy. Without such verification, the environments risk collapsing to Markovian or short-correlation regimes that do not challenge memory-augmented agents as intended.
minor comments (2)
- [§2] Notation for the MDS parameter and the aggregation operator should be introduced with explicit definitions and an illustrative small example early in §2 to improve readability for readers unfamiliar with the framework.
- [Abstract] The abstract and introduction would benefit from a concise statement of the precise formal relationship between the linear dynamics parameters and the resulting MDS value, rather than leaving the mapping implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the potential value of the MDS framework and synthetic POMDP suite for memory-augmented RL benchmarking. We address the two major comments below, clarifying the design rationale while committing to added verification where the current manuscript is light on explicit diagnostics.
read point-by-point responses
-
Referee: [§3] §3 (Methodology): The claim that linear dynamics plus state aggregation and reward redistribution yield POMDPs whose memory demand exactly matches a pre-specified MDS parameter is load-bearing for the entire contribution, yet the manuscript provides no theorem, proposition, or empirical diagnostic demonstrating that the resulting transition and observation kernels force history dependence of the claimed length. In particular, it is not shown that the aggregated process remains non-Markovian once the policy is optimized, nor that short-horizon recurrent agents fail while longer-memory agents succeed precisely at the MDS-specified depth.
Authors: We agree that a formal proposition or theorem would make the central claim more rigorous. The construction deliberately uses linear dynamics to control the underlying state evolution, followed by aggregation that collapses distinguishable states into identical observations while preserving the reward structure via redistribution; this ensures that the belief over the original states cannot be recovered from a single observation and requires a history length matching the MDS parameter to reconstruct the necessary distinctions for optimality. Nevertheless, the manuscript currently relies on the construction logic rather than an explicit proof or diagnostic experiment. We will add both a short proposition formalizing the non-Markovian property under the aggregation map and an empirical section comparing short- versus long-memory agents on the generated environments to confirm that performance gaps appear exactly at the prescribed MDS depths. revision: partial
-
Referee: [§4] §4 (Environment suite): The tunable difficulty parameters are presented as directly controlling MDS, but no ablation or sensitivity analysis is reported that isolates the effect of each construction knob (e.g., aggregation granularity versus reward redistribution) on the minimal memory length required by an optimal policy. Without such verification, the environments risk collapsing to Markovian or short-correlation regimes that do not challenge memory-augmented agents as intended.
Authors: We accept that the current presentation would benefit from explicit sensitivity checks. The tunable parameters were chosen precisely because aggregation granularity directly modulates the number of distinguishable histories needed and reward redistribution controls whether those histories carry differential value; however, we did not report systematic ablations isolating each knob. In the revision we will include a sensitivity study that varies aggregation level and redistribution strength independently, measuring the minimal memory horizon at which optimal performance is achieved (via exhaustive search or long-horizon planning oracles) to demonstrate that the observed memory demand tracks the intended MDS parameter. revision: yes
Circularity Check
No significant circularity detected in MDS framework or POMDP construction
full rationale
The paper introduces a theoretical framework based on Memory Demand Structure (MDS) and describes a construction methodology using linear dynamics, state aggregation, and reward redistribution to achieve predefined MDS values. No equations, fitted parameters, or self-citations are exhibited in the abstract or methodology description that reduce any central claim to an input by construction. The derivation is presented as an independent theoretical and methodological contribution for generating tunable POMDP environments, with no load-bearing steps that equate predictions to prior fits or imported uniqueness results. This is the most common honest finding for papers that define new analysis concepts and construction procedures without internal reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Memory Demand Structure (MDS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We employ a deterministic autoregressive (AR) process ... z_{t+1} = (sum w_i z_{t-i}) mod 1 ... m=8, n=8 ... high-order MDPs of order k
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linear process dynamics, state aggregation, and reward redistribution to construct POMDPs with predefined MDS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Arcade Learning Environment: An Evaluation Platform For General Agents.Journal of Artificial Intelli- gence Research, 47: 253–279. Brockman, G.; Cheung, V .; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; and Zaremba, W. 2016. Openai Gym. arXiv preprint arXiv:1606.01540. Cobbe, K.; Hesse, C.; Hilton, J.; and Schulman, J. 2020. Leveraging Proce...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Han, D.; Doya, K.; and Tani, J
PMLR. Han, D.; Doya, K.; and Tani, J. 2019. Variational Recurrent Models for Solving Partially Observable Control Tasks. In International Conference on Learning Representations. Hochreiter, S.; and Schmidhuber, J. 1997. Long Short-Term Memory.Neural Computation, 9(8): 1735–1780. Huang, S.; Gallou´edec, Q.; Felten, F.; Raffin, A.; Dossa, R. F. J.; Zhao, Y ...
work page 2019
-
[3]
Open RL Benchmark: Comprehensive Tracked Exper- iments for Reinforcement Learning.CoRR, abs/2402.03046. Hyde, G.; and Santos Jr, E. 2024. Detecting Hidden Trig- gers: Mapping Non-Markov Reward Functions to Markov. InECAI 2024, 1357–1364. IOS Press. Jordan, B. D.; Ross, S. A.; and Westerfield, R. W. 2003. Fun- damentals of Corporate Finance. 122–177. Kaelb...
-
[4]
InInternational Conference on Machine Learning, 5156–5165
Transformers are RNNs: Fast Autoregressive Trans- formers with Linear Attention. InInternational Conference on Machine Learning, 5156–5165. PMLR. K¨uttler, H.; Nardelli, N.; Miller, A.; Raileanu, R.; Selvatici, M.; Grefenstette, E.; and Rockt¨aschel, T. 2020. The Nethack Learning Environment.Advances in Neural Information Processing Systems, 33: 7671–7684...
-
[5]
In Reinforcement Learning Conference
Benchmarking Partial Observability in Reinforcement Learning with a Suite of Memory-Improvable Domains. In Reinforcement Learning Conference. Todorov, E.; Erez, T.; and Tassa, Y . 2012. Mujoco: A Physics Engine for Model-Based Control. In2012 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems, 5026–5033. IEEE. V oelker, A.; Kaji´c, I.; ...
-
[6]
If(a, b)∈ϕ, then(b, a)∈ϕ=⇒(b, a)∈ϕ∨ψ
-
[7]
If(a, b)∈(ψ◦ϕ) ∗, then∃k∈N,∃x 0:2k−1 ∈S 2k, a=x 0, b=x 2k−1,∀i∈N, i < k,(x 2i, x2i+1)∈ ψ,(x 2i+1, x2i+2)∈ϕ=⇒(x 2i+1, x2i)∈ψ,(x 2i+2, x2i+1)∈ϕ=⇒(b, a)∈(ψ◦ϕ) k ⊆(ψ◦ϕ) ∗ ⊆ϕ∨ψ. – Transitivity:∀a, b, c∈S,(a, b),(b, c)∈ϕ∨ψ=⇒(a, b),(b, c)∈ϕor(a, b)∈ϕ,(b, c)∈(ψ◦ϕ) ∗ or(a, b)∈ (ψ◦ϕ) ∗,(b, c)∈ϕor(a, b),(b, c)∈(ψ◦ϕ) ∗
-
[8]
If(a, b),(b, c)∈ϕ, then(a, c)∈ϕ⊆ϕ∨ψ
-
[9]
If(a, b)∈ϕ,(b, c)∈(ψ◦ϕ) ∗, then(a, c)∈ϕ◦(ψ◦ϕ) ∗ = ({(x, x)|x∈S} ◦ϕ)◦(ψ◦ϕ) ∗ ⊆(ψ◦ϕ)◦(ψ◦ϕ) ∗ = (ψ◦ϕ) ∗ ⊆ϕ∨ψ
-
[10]
If(a, b)∈(ψ◦ϕ) ∗,(b, c)∈ϕ, then∃k∈N,(a, c)∈(ψ◦ϕ) k ◦ϕ= (ψ◦ϕ) k ⊆(ψ◦ϕ) ∗ ⊆ϕ∨ψ
-
[11]
Then we show that such definitions of∧,∨meet the properties required by Def
If(a, b),(b, c)∈(ψ◦ϕ) ∗, then(a, c)∈(ψ◦ϕ) ∗ ◦(ψ◦ϕ) ∗ = (ψ◦ϕ) ∗ ⊆ϕ∨ψ. Then we show that such definitions of∧,∨meet the properties required by Def. C.5. •Supremum: –ϕ⊆ϕ∨ψ: ϕ⊆ϕ∪(ψ◦ϕ) ∗ =⇒ϕ⊆ϕ∨ψ. –ψ⊆ϕ∨ψ: ψ=ψ◦ {(x, x)|x∈S} ⊆ψ◦ϕ⊆(ψ◦ϕ) ∗ ⊆ϕ∪(ψ◦ϕ) ∗ =⇒ψ⊆ϕ∨ψ. –ϕ⊆φ, ψ⊆φ=⇒ϕ∨ψ⊆φ: ϕ∨ψ=ϕ∪(ψ◦ϕ) ∗ ⊆φ∪(φ◦φ) ∗ =φ=⇒ϕ∨ψ⊆φ. •Infimum: –ϕ∧ψ⊆ϕ: ϕ∧ψ=ϕ∩ψ⊆ϕ. –ϕ∧ψ⊆ψ: ϕ∧ψ=ϕ∩ψ⊆ψ=⇒ϕ∧ψ⊆ψ...
-
[12]
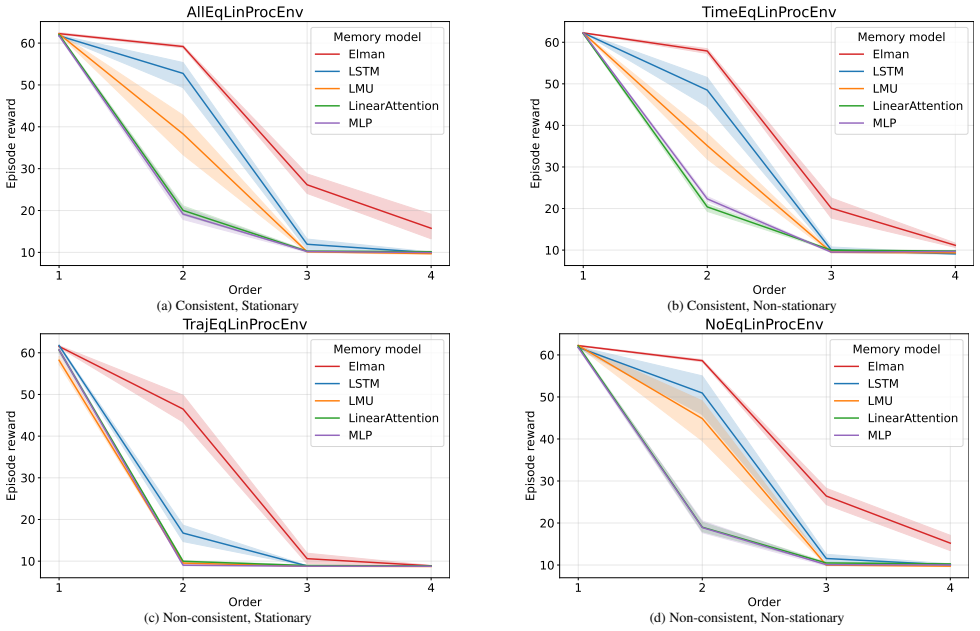
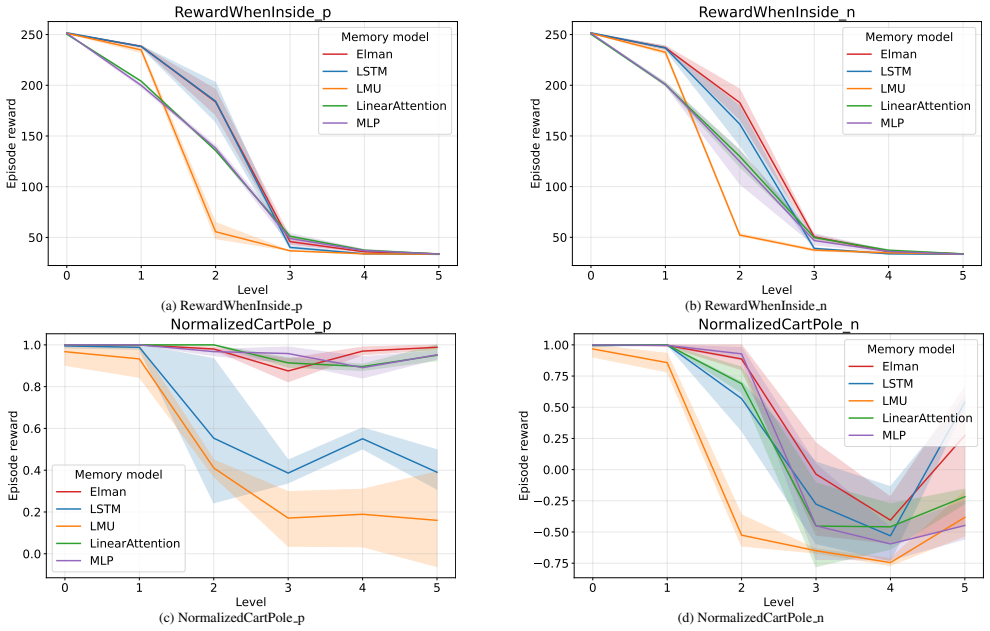
D HDP Environments Constructed from Scratch Order Range:k∈ {0,1,2,3,4,5,6,7}
zt+1 = wt 0zt +w t 1zt−1 (z0 ≤ 1 2) w′t 0 zt +w ′t 1 zt−1 (z0 > 1 2) Table 2: Examples of observation generation AR processes under different stationarity and consistency conditions. D HDP Environments Constructed from Scratch Order Range:k∈ {0,1,2,3,4,5,6,7}. Observation Space:[0,1). Action Space:{0,1,2,3,4,5,6,7}. Trajectory Length:64. Initialization:z ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.