Disentangling Bias by Modeling Intra- and Inter-modal Causal Attention for Multimodal Sentiment Analysis
Pith reviewed 2026-05-21 22:58 UTC · model grok-4.3
The pith
Modeling multimodal data as a multi-relational graph and applying backdoor adjustment after disentangling features yields stable sentiment predictions under distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
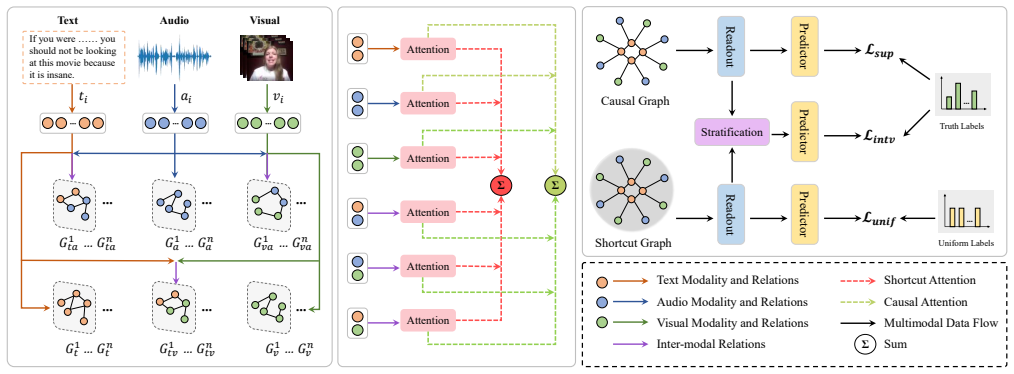
The central claim is that representing multimodal inputs as a multi-relational graph, estimating and disentangling causal versus shortcut features for intra- and inter-modal relations via attention, and then applying backdoor adjustment to stratify the shortcut features and dynamically combine them with the causal features produces stable predictions under distribution shifts.
What carries the argument
The Multi-relational Multimodal Causal Intervention (MMCI) framework, which first builds a multi-relational graph to capture dependencies, then uses attention to separate causal features from shortcut features, and finally performs backdoor adjustment to intervene on the shortcuts.
If this is right
- Predictions remain consistent when test data follows a different distribution from training data.
- Spurious correlations within single modalities and across modalities are suppressed.
- Performance rises on both standard benchmark datasets and dedicated out-of-distribution test sets.
- The model focuses more on true causal relationships rather than statistical shortcuts.
Where Pith is reading between the lines
- The same graph-plus-adjustment pattern could be tested on other multimodal tasks such as emotion recognition in videos or dialogue systems.
- The disentanglement step might generalize to attention mechanisms outside sentiment analysis whenever shortcut biases are suspected.
- Combining this intervention with additional causal tools, such as do-calculus variants, could further reduce sensitivity to distribution changes.
- Running the method on datasets with known modality-specific biases would provide a direct check on whether intra- versus inter-modal shortcuts are handled equally well.
Load-bearing premise
The attention mechanism can accurately estimate and disentangle the causal features from the shortcut features corresponding to intra- and inter-modal relations in the multi-relational graph.
What would settle it
If MMCI shows no gain or even degraded accuracy on out-of-distribution test sets relative to standard multimodal models, or if shortcut features continue to dominate predictions, the claim that the disentanglement plus adjustment removes bias would be refuted.
Figures




read the original abstract
Multimodal sentiment analysis (MSA) aims to understand human emotions by integrating information from multiple modalities, such as text, audio, and visual data. However, existing methods often suffer from spurious correlations both within and across modalities, leading models to rely on statistical shortcuts rather than true causal relationships, thereby undermining generalization. To mitigate this issue, we propose a Multi-relational Multimodal Causal Intervention (MMCI) framework, which leverages the backdoor adjustment from causal theory to address the confounding effects of such shortcuts. Specifically, we first model the multimodal inputs as a multi-relational graph to explicitly capture intra- and inter-modal dependencies. Then, we apply an attention mechanism to separately estimate and disentangle the causal features and shortcut features corresponding to these intra- and inter-modal relations. Finally, by applying the backdoor adjustment, we stratify the shortcut features and dynamically combine them with the causal features to encourage MMCI to produce stable predictions under distribution shifts. Extensive experiments on several standard MSA datasets and out-of-distribution (OOD) test sets demonstrate that our method effectively suppresses biases and improves performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Multi-relational Multimodal Causal Intervention (MMCI) framework for multimodal sentiment analysis. It models multimodal inputs as a multi-relational graph to capture intra- and inter-modal dependencies, applies an attention mechanism to disentangle causal features from shortcut features, and uses backdoor adjustment to stratify the shortcut features and dynamically combine them with causal features, aiming for stable predictions under distribution shifts. Experiments on standard MSA datasets and OOD test sets are reported to show bias suppression and performance gains.
Significance. If the disentanglement step is reliable, the work would offer a concrete way to integrate causal intervention with multimodal graph attention, addressing a recognized limitation in MSA generalization. This could influence downstream applications requiring robustness to shifts, though the absence of an identifiability argument for the attention-based separation limits the strength of the causal claim.
major comments (2)
- [Abstract / §3] Abstract and method description: the attention mechanism is stated to 'separately estimate and disentangle the causal features and shortcut features' for intra- and inter-modal relations, yet no explicit identification criterion, auxiliary loss, or validation against known confounders is supplied. Without such grounding, the subsequent backdoor adjustment is applied to an unverified partition, so the stability-under-shift claim does not necessarily follow.
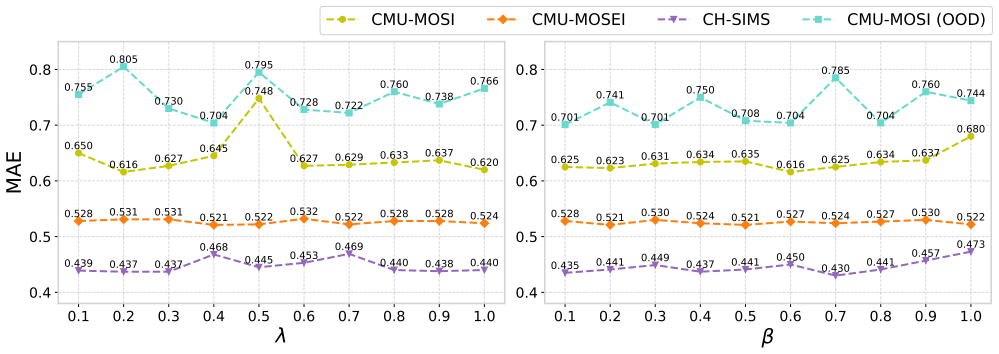
- [§4 / Experiments] The stratification and dynamic combination step under backdoor adjustment is described as producing 'stable predictions under distribution shifts,' but the manuscript provides no quantitative ablation isolating the contribution of the causal versus shortcut branches on the OOD test sets, leaving open whether observed gains arise from the causal intervention or from the added capacity of the multi-relational graph.
minor comments (2)
- [§3] Notation for the multi-relational graph edges and the attention weights for causal versus shortcut paths should be defined explicitly with symbols before the backdoor-adjustment formula is introduced.
- [Abstract / §4] The abstract mentions 'extensive experiments' but does not list the exact OOD construction protocol or the number of runs; these details belong in the main text or a dedicated appendix table.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions to strengthen the manuscript while maintaining an honest assessment of its contributions and limitations.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method description: the attention mechanism is stated to 'separately estimate and disentangle the causal features and shortcut features' for intra- and inter-modal relations, yet no explicit identification criterion, auxiliary loss, or validation against known confounders is supplied. Without such grounding, the subsequent backdoor adjustment is applied to an unverified partition, so the stability-under-shift claim does not necessarily follow.
Authors: We acknowledge that the manuscript does not supply a formal identification criterion or auxiliary supervision to guarantee that the attention mechanism isolates causal from shortcut features. The design relies on separate attention pathways within the multi-relational graph to capture distinct dependency types, motivated by the goal of enabling subsequent backdoor adjustment. We agree this leaves the partition without direct validation against confounders. In revision we will add a dedicated paragraph in §3 explaining the modeling assumptions, introduce an auxiliary contrastive loss term to encourage separation of the two feature sets, and include validation experiments on a controlled synthetic dataset containing known spurious correlations. These additions will provide empirical grounding for the disentanglement step. revision: yes
-
Referee: [§4 / Experiments] The stratification and dynamic combination step under backdoor adjustment is described as producing 'stable predictions under distribution shifts,' but the manuscript provides no quantitative ablation isolating the contribution of the causal versus shortcut branches on the OOD test sets, leaving open whether observed gains arise from the causal intervention or from the added capacity of the multi-relational graph.
Authors: We agree that the current experimental section would be strengthened by isolating the effect of the causal intervention. While overall gains on OOD sets are reported, we did not include branch-specific ablations. In the revised version we will add quantitative results in §4 that compare the full MMCI model against variants that (i) remove the shortcut branch entirely and (ii) disable the dynamic combination step, with all metrics reported on the OOD test sets. This will allow readers to assess whether the observed robustness stems primarily from the causal features and backdoor adjustment rather than increased model capacity. revision: yes
- A formal identifiability argument establishing that the attention-based separation recovers true causal features rather than an approximation; such a proof would require substantial additional theoretical work beyond the scope of the present empirical framework.
Circularity Check
No significant circularity; derivation applies standard causal adjustment to learned attention outputs without reducing to input fit by construction
full rationale
The paper models inputs as a multi-relational graph, uses attention to produce separate causal and shortcut feature estimates, then applies backdoor adjustment via stratification and dynamic combination. This chain does not contain self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central claim. The stability claim rests on the external causal intervention formula rather than re-deriving from the same fitted values; OOD experiments supply independent falsifiability. No equations or sections reduce the output to the input by algebraic identity or statistical forcing.
Axiom & Free-Parameter Ledger
free parameters (2)
- attention parameters for causal and shortcut paths
- stratification and combination weights
axioms (2)
- domain assumption Multimodal inputs can be represented as a multi-relational graph that explicitly captures intra- and inter-modal dependencies
- domain assumption Backdoor adjustment can be realized by stratifying shortcut features estimated via attention
Reference graph
Works this paper leans on
-
[1]
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
Association for Computational Linguistics. Liu, Y .; Li, G.; and Lin, L. 2023. Cross-modal causal rela- tional reasoning for event-level visual question answering. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 45(10): 11624–11641. Liu, Z.; Shen, Y .; Lakshminarasimhan, V . B.; Liang, P. P.; Zadeh, A.; and Morency, L.-P. 2018. Efficient...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In Proceedings of the 30th ACM International Conference on Multimedia, 15–23
Counterfactual reasoning for out-of-distribution mul- timodal sentiment analysis. In Proceedings of the 30th ACM International Conference on Multimedia, 15–23. Sun, Z.; Sarma, P.; Sethares, W.; and Liang, Y . 2020. Learn- ing relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the...
work page 2020
-
[3]
In Proceedings of the ACM Web Confer- ence 2022, 3562–3571
Causal representation learning for out-of-distribution recommendation. In Proceedings of the ACM Web Confer- ence 2022, 3562–3571. Wu, S.; He, D.; Wang, X.; Wang, L.; and Dang, J. 2025. En- riching multimodal sentiment analysis through textual emo- tional descriptions of visual-audio content. In Proceed- ings of the AAAI Conference on Artificial Intellige...
-
[4]
Tensor Fusion Network for Multimodal Sentiment Analysis
Springer. Yang, D.; Yang, K.; Li, M.; Wang, S.; Wang, S.; and Zhang, L. 2024b. Robust emotion recognition in context debiasing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12447–12457. Yang, J.; Yu, Y .; Niu, D.; Guo, W.; and Xu, Y . 2023. Con- fede: Contrastive feature decomposition for multimodal sen- timent ana...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Learning language-guided adaptive hyper-modality representation for multimodal sentiment analysis. arXiv preprint arXiv:2310.05804. Zhang, K.; Zhang, Z.; Li, Z.; and Qiao, Y . 2016. Joint face detection and alignment using multitask cascaded convo- lutional networks. IEEE signal processing letters , 23(10): 1499–1503. Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y .;...
-
[6]
TFN (Zadeh et al. 2017): Tensor Fusion Network (TFN) computes the outer product of three unimodal represen- tations to generate an expressive multimodal tensor that explicitly captures interactions at uni-modal, bi-modal, and tri-modal levels
work page 2017
-
[7]
LMF (Liu et al. 2018): Low-rank Modality Fusion (LMF) decomposes the weight tensors of the multimodal tensor into low-rank tensors, reducing both space and time complexity
work page 2018
-
[8]
MulT (Tsai et al. 2019): Multimodal Transformer (MulT) generates multimodal representations by trans- lating source modalities into target modalities via cross- modal Transformers
work page 2019
-
[9]
MISA (Hazarika, Zimmermann, and Poria 2020): Modality-Invariant and -Specific Representation (MISA) projects modality-specific and modality-invariant uni- modal features into two distinct embedding subspaces for each modality
work page 2020
-
[10]
MAG-BERT(Rahman et al. 2020): Multimodal Adapta- tion Gate BERT (MAG-BERT) introduces a multimodal adaptation gate that enables large pre-trained transform- ers to incorporate multimodal data during fine-tuning
work page 2020
-
[11]
Self-MM (Yu et al. 2021): Self-Supervised Multi- task Multimodal sentiment analysis network (Self-MM) leverages annotated global sentiment labels to generate pseudo labels for each modality, enabling the model to learn discriminative unimodal representations
work page 2021
-
[12]
MMIM (Han, Chen, and Poria 2021): MultiModal In- foMax (MMIM) jointly maximizes mutual information among unimodal representations and between multi- modal and unimodal representations, leading to richer multimodal feature learning
work page 2021
-
[13]
HGraph-CL (Lin et al. 2022): Hierarchical Graph Con- trastive Learning (HGraph-CL) constructs unimodal and multimodal graphs to capture intra- and inter-modal sen- timent dependencies, applying graph contrastive learning at both levels
work page 2022
-
[14]
HyCon (Mai et al. 2022): Hybrid Contrastive Learn- ing (HyCon) combines intra-modal and inter-modal con- trastive learning to capture interactions within individual samples and across different samples or categories
work page 2022
-
[15]
C-MIB (Mai, Zeng, and Hu 2022): Complete Multi- modal Information Bottleneck (C-MIB) applies the in- formation bottleneck principle to reduce redundancy and noise in unimodal and multimodal representations
work page 2022
-
[16]
ConFEDE (Yang et al. 2023): Contrastive FEature DE- composition (ConFEDE) performs contrastive represen- tation learning alongside contrastive feature decomposi- tion to enrich multimodal representations
work page 2023
-
[17]
ALMT (Zhang et al. 2023): Adaptive Language-guided Multimodal Transformer (ALMT) introduces an Adap- tive Hyper-modality Learning (AHL) module that guides visual and audio representations under language supervi- sion, suppressing unrelated or conflicting features
work page 2023
-
[18]
ITHP (Xiao et al. 2024): Information-Theoretic Hier- archical Perception (ITHP), based on the information bottleneck principle, designates a primary modality and treats other modalities as detectors to distill salient infor- mation
work page 2024
-
[19]
DLF (Wang et al. 2025): Disentangled-Language- Focused (DLF) disentangles modality-shared and modality-specific features, introduces geometric measures to reduce redundancy, and applies a language- focused attractor with cross-attention to enhance textual representations
work page 2025
-
[20]
DEV A(Wu et al. 2025): DEV A generates textual sen- timent descriptions from audio-visual inputs to enrich emotional cues, and uses a text-guided progressive fusion module for better alignment and fusion under nuanced emotional scenarios. Additionally, we include three causality-based baselines:
work page 2025
-
[21]
CLUE (Sun et al. 2022): CounterfactuaL mUltimodal sEntiment (CLUE) leverages causal inference and coun- terfactual reasoning to subtract spurious direct textual ef- fects, preserving only reliable indirect multimodal effects for improved OOD generalization
work page 2022
-
[22]
GEAR (Sun et al. 2023): General dEbiAsing fRame- work (GEAR) disentangles robust and biased features, estimates sample bias, and applies inverse probability weighting to down-weight heavily biased samples, thus enhancing OOD robustness
work page 2023
-
[23]
MulDeF (Huan et al. 2024): Multimodal Debiasing Framework (MulDeF) uses causal intervention with frontdoor adjustment and multimodal causal attention during training, and applies counterfactual reasoning dur- ing inference to remove verbal and nonverbal biases, im- proving OOD generalization. Feature Extraction Details Text Modality: For the CMU-MOSI and ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.