Exploiting repeated matrix block structures for more efficient CFD on modern supercomputers
Pith reviewed 2026-05-18 23:34 UTC · model grok-4.3
The pith
By grouping repeated matrix blocks, CFD codes can replace sparse matrix-vector multiplies with matrix-matrix multiplies to raise arithmetic intensity and cut run times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
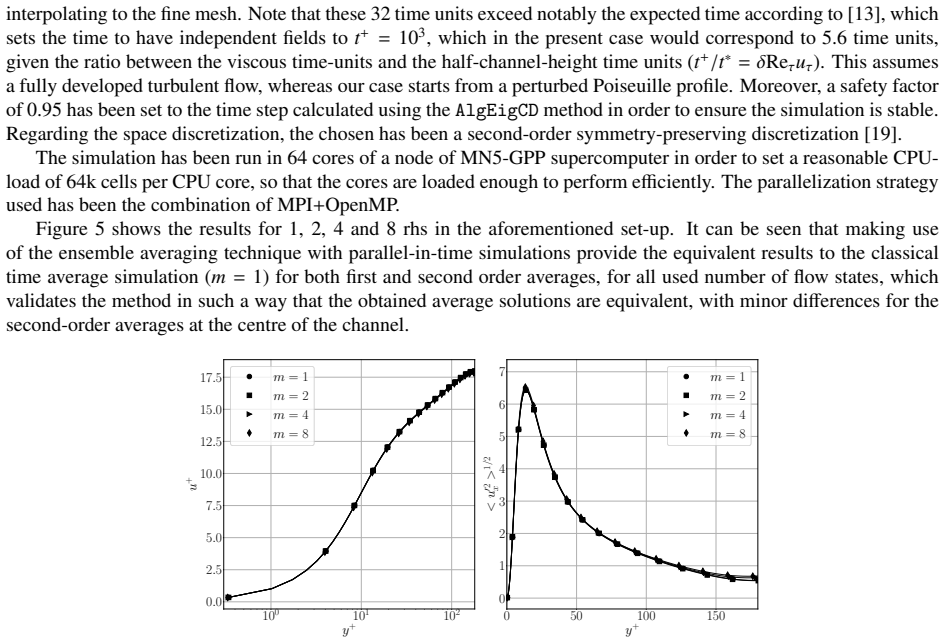
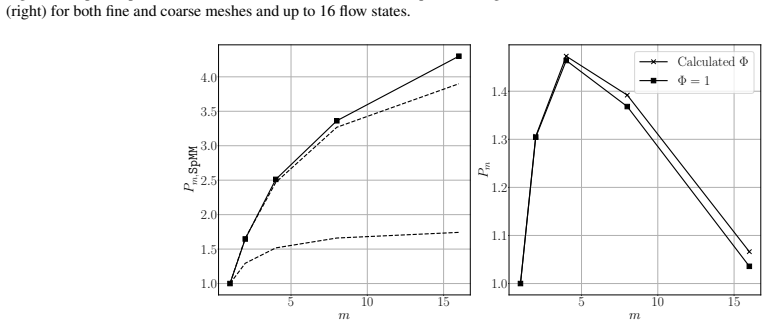
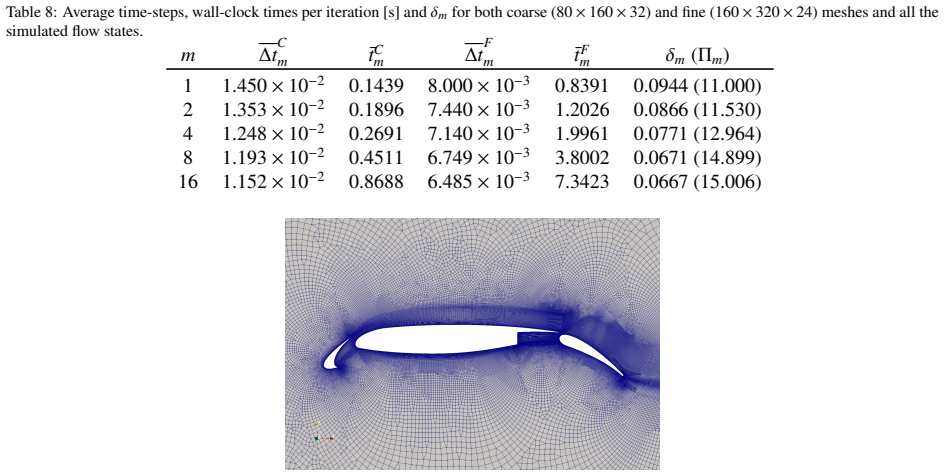
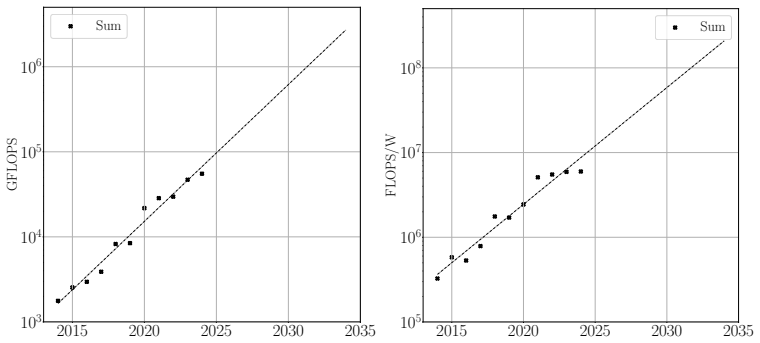
The paper claims that repeated matrix block structures allow the reformulation of sparse matrix-vector products into sparse matrix-matrix products for CFD operators. This enables the handling of several right-hand sides at once, increasing arithmetic intensity by reusing matrix data. The approach is complemented by an inline mesh-refinement method that establishes statistically steady flow on a coarse mesh before refining to the target resolution, thereby reducing overall computational time while maintaining solution quality.
What carries the argument
The reformulation of SpMV as SpMM through exploitation of identical repeated matrix blocks across multiple right-hand sides in CFD operators.
If this is right
- SpMM can be applied to all major operators including divergence, gradient and Laplacian for broad efficiency gains.
- Substantial speed-ups are achieved, exceeding 50% in setups that include the mesh-refinement strategy.
- The coarse-mesh initialization reaches transition to steady state faster at equivalent cost.
- Theoretical bounds and test cases validate the performance shift on modern HPC hardware.
Where Pith is reading between the lines
- The method could apply to other codes with block-repetitive structures in their linear operators.
- Dynamic adaptation of block grouping during simulation might further optimize performance.
- Energy savings on large clusters may result from the reduced wall-clock times.
- Integration with adaptive refinement techniques could extend benefits to unsteady problems.
Load-bearing premise
CFD discrete operators feature enough identical matrix blocks for the SpMM reformulation to produce noticeable arithmetic intensity gains.
What would settle it
A benchmark comparing wall-clock time and performance metrics such as flops per byte for a CFD simulation before and after applying the SpMM transformation on the same mesh and hardware.
Figures













read the original abstract
Computational Fluid Dynamics (CFD) simulations are often constrained by the memory-bound nature of sparse matrix-vector operations, which eventually limits performance on modern high-performance computing (HPC) systems. This work introduces a novel approach to increase arithmetic intensity in CFD by leveraging repeated matrix block structures. The method transforms the conventional sparse matrix-vector product (SpMV) into a sparse matrix-matrix product (SpMM), enabling simultaneous processing of multiple right-hand sides. This shifts the computation towards a more compute-bound regime by reusing matrix coefficients. Additionally, an inline mesh-refinement strategy is proposed: simulations initially run on a coarse mesh to establish a statistically steady flow, then refine to the target mesh. This reduces the wall-clock time to reach transition, leading to faster convergence with equivalent computational cost. The methodology is evaluated using theoretical performance bounds and validated through three test cases: a turbulent channel flow, Rayleigh-B\'{e}nard convection, and an industrial airfoil simulation. Results demonstrate substantial speed-ups - from modest improvements in basic configurations to over 50% in the mesh-refinement setup - highlighting the benefits of integrating SpMM across all CFD operators, including divergence, gradient, and Laplacian.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes transforming sparse matrix-vector products (SpMV) into sparse matrix-matrix products (SpMM) in CFD codes by exploiting repeated block structures in discrete operators (divergence, gradient, Laplacian), thereby increasing arithmetic intensity. It further introduces an inline coarse-to-fine mesh-refinement strategy that runs an initial coarse-mesh phase to reach statistically steady flow before refining, claiming this reduces wall-clock time to transition with equivalent cost. Theoretical performance bounds and three test cases (turbulent channel flow, Rayleigh-Bénard convection, industrial airfoil) are presented, with reported speed-ups ranging from modest gains to over 50% in the refinement configuration.
Significance. If the performance claims hold after verification, the work offers a practical route to higher arithmetic intensity in memory-bound CFD kernels on modern HPC systems without altering the underlying discretization. The combination of SpMM reformulation across multiple operators and the inline refinement strategy could shorten time-to-solution for statistically steady turbulent simulations, provided the refinement preserves the target statistics.
major comments (2)
- [§4 and results] §4 (Mesh-refinement strategy) and results section: the headline claim of >50% wall-clock reduction in the refinement setup rests on the assumption that the coarse-to-fine transition reaches an equivalent statistically steady state. No quantitative comparison (mean profiles, Reynolds stresses, integral quantities, or convergence metrics) is shown between a pure fine-mesh run and the inline-refined run; without such checks or error bounds on transient bias, the reported speed-up cannot be unambiguously attributed to the SpMM reformulation or the cheaper coarse phase.
- [§3.2] §3.2 (SpMM implementation across operators): the theoretical bounds assume that all target operators contain sufficiently many identical matrix blocks to amortize the SpMM overhead. The manuscript should quantify the fraction of blocks that are actually repeated in each test case and demonstrate that the measured speed-ups scale with this fraction rather than with other implementation details.
minor comments (2)
- [Figures and §5] Figure captions and timing methodology: clarify whether the reported wall-clock times include or exclude the refinement overhead and whether statistical convergence criteria (e.g., running averages of drag or Nusselt number) are identical across all compared runs.
- [§2] Notation: the definition of arithmetic intensity and the transition from SpMV to SpMM should be stated explicitly with the relevant matrix dimensions before the performance model is introduced.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on our manuscript. We address each major comment in detail below and outline the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4 and results] §4 (Mesh-refinement strategy) and results section: the headline claim of >50% wall-clock reduction in the refinement setup rests on the assumption that the coarse-to-fine transition reaches an equivalent statistically steady state. No quantitative comparison (mean profiles, Reynolds stresses, integral quantities, or convergence metrics) is shown between a pure fine-mesh run and the inline-refined run; without such checks or error bounds on transient bias, the reported speed-up cannot be unambiguously attributed to the SpMM reformulation or the cheaper coarse phase.
Authors: We agree that quantitative verification of statistical equivalence is necessary to support the claimed wall-clock reductions. In the revised manuscript we will add direct comparisons of mean velocity profiles, Reynolds stresses, skin-friction coefficients (channel flow), and Nusselt numbers (Rayleigh-Bénard) between the pure fine-mesh runs and the corresponding coarse-to-fine simulations. Convergence metrics and error bounds on transient bias will also be included for the two canonical cases; for the industrial airfoil we will report lift and drag coefficients. These additions will allow unambiguous attribution of the observed speed-ups. revision: yes
-
Referee: [§3.2] §3.2 (SpMM implementation across operators): the theoretical bounds assume that all target operators contain sufficiently many identical matrix blocks to amortize the SpMM overhead. The manuscript should quantify the fraction of blocks that are actually repeated in each test case and demonstrate that the measured speed-ups scale with this fraction rather than with other implementation details.
Authors: We accept the need for explicit quantification. The revised manuscript will contain a new table reporting the fraction of identical blocks for the divergence, gradient, and Laplacian operators in each of the three test cases. We will also add an analysis showing how the measured speed-ups correlate with these fractions, either by comparing operators that exhibit different repetition levels or by controlled numerical experiments that vary the repetition fraction while holding other factors fixed. revision: yes
Circularity Check
No circularity: empirical timings and algorithmic reformulation stand independently
full rationale
The paper introduces an SpMM reformulation for repeated matrix blocks in CFD operators and an inline coarse-to-fine mesh strategy, then reports wall-clock speed-ups measured directly on three concrete test cases (turbulent channel, Rayleigh-Bénard, airfoil). No derivation chain reduces a claimed result to a fitted parameter or self-citation by construction; performance bounds are theoretical and independent, while numerical gains come from external timing runs rather than any self-referential prediction. The central claims therefore remain falsifiable against standard SpMV baselines without internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CFD discrete operators contain sufficient identical matrix blocks to make SpMM advantageous
- domain assumption Coarse-mesh statistically steady state provides a valid initial condition for fine-mesh continuation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
transforms the conventional sparse matrix-vector product (SpMV) into a generalized sparse matrix-matrix product (SpMM), enabling simultaneous processing of multiple right-hand sides
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
repeated matrix block structures ... I_s ⊗ Ã
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Williams, A. Waterman, D. Patterson, Roofline: An insightful visual performance model for multicore architectures, Communications of the ACM 52 (2009) 65–76. doi:10.1145/1498765.1498785
-
[2]
J. L. Greathouse, M. Daga, Efficient Sparse Matrix-Vector Multiplication on GPUs Using the CSR Storage Format, in: International Conference for High Performance Computing, Networking, Storage and Analysis, SC, volume 2015-January, IEEE Computer Society, 2014, pp. 769–780. doi:10.1109/SC.2014.68, issue: January ISSN: 21674337
-
[3]
V . Makarashvili, E. Merzari, A. Obabko, A. Siegel, P. Fischer, A performance analysis of ensemble averaging for high fidelity turbulence simulations at the strong scaling limit, Computer Physics Communications 219 (2017) 236–245. doi:10.1016/j.cpc.2017.05.023, publisher: Elsevier B.V
-
[4]
G. Nastac, J. W. Labahn, L. Magri, M. Ihme, Lyapunov exponent as a metric for assessing the dynamic content and predictability of large-eddy simulations, Physical Review Fluids 2 (2017). doi:10.1103/PhysRevFluids.2.094606, publisher: American Physical Society
-
[5]
R. Tosi, M. Núñez, J. Pons-Prats, J. Principe, R. Rossi, On the use of ensemble averaging techniques to accelerate the Uncer- tainty Quantification of CFD predictions in wind engineering, Journal of Wind Engineering and Industrial Aerodynamics 228 (2022). doi:10.1016/j.jweia.2022.105105, publisher: Elsevier B.V
-
[6]
B. I. Krasnopolsky, An approach for accelerating incompressible turbulent flow simulations based on simultaneous modelling of multiple ensembles, Computer Physics Communications 229 (2018) 8–19. doi:10.1016/j.cpc.2018.03.023, publisher: Elsevier B.V
-
[7]
À. Alsalti-Baldellou, X. Álvarez-Farré, G. Colomer, A. Gorobets, C. D. Pérez-Segarra, A. Oliva, F. X. Trias, Lighter and faster simulations on domains with symmetries, Computers and Fluids 275 (2024). doi:10.1016/j.compfluid.2024.106247, publisher: Elsevier Ltd
-
[8]
À. Alsalti-Baldellou, C. Janna, X. Álvarez-Farré, F. X. Trias, A Multigrid Reduction Framework for Domains with Symme- tries, SIAM Journal on Scientific Computing 46 (2024) B860–B883. URL:https://epubs.siam.org/doi/10.1137/24M1638513. doi:10.1137/24M1638513
-
[9]
X. Álvarez, A. Gorobets, F. X. Trias, R. Borrell, G. Oyarzun, HPC2—A fully-portable, algebra-based framework for heterogeneous comput- ing. Application to CFD, Computers and Fluids 173 (2018) 285–292. doi:10.1016/j.compfluid.2018.01.034, publisher: Elsevier Ltd
-
[10]
B. I. Krasnopolsky, Optimal Strategy for Modelling Turbulent Flows with Ensemble Averaging on High Performance Computing Systems, Lobachevskii Journal of Mathematics 39 (2018) 533–542. doi:10.1134/S199508021804008X, publisher: Pleiades Publishing
-
[11]
A. Alsalti-Baldellou, X. Álvarez-Farré, F. X. Trias, A. Oliva, Exploiting spatial symmetries for solving Poisson’s equation, Journal of Computational Physics 486 (2023). doi:10.1016/j.jcp.2023.112133, publisher: Academic Press Inc
-
[12]
F. X. Trias, O. Lehmkuhl, A. Oliva, C. D. Pérez-Segarra, R. W. Verstappen, Symmetry-preserving discretization of Navier-Stokes equations on collocated unstructured grids, Journal of Computational Physics 258 (2014) 246–267. doi:10.1016/j.jcp.2013.10.031, publisher: Academic Press Inc
-
[13]
N. V . Nikitin, Disturbance growth rate in turbulent wall flows, Fluid Dynamics 44 (2009) 652–657. doi:10.1134/S0015462809050032
-
[14]
L. Keefe, P. Moin, J. Kim, The dimension of attractors underlying periodic turbulent Poiseuille flow, Journal of Fluid Mechanics 242 (1992) 1–29. doi:10.1017/S0022112092002258
-
[15]
R. Badii, K. Heinzelmann, P. F. Meier, A. Politi, Correlation functions and generalized Lyapunov exponents, Physical Review A 37 (1988) 1323–1328. URL:https://link.aps.org/doi/10.1103/PhysRevA.37.1323. doi:10.1103/PhysRevA.37.1323
-
[16]
C. F. O. Mendes, R. M. Da Silva, M. W. Beims, Decay of the distance autocorrelation and Lyapunov exponents, Physical Review E 99 (2019) 062206. URL:https://link.aps.org/doi/10.1103/PhysRevE.99.062206. doi:10.1103/PhysRevE.99.062206
-
[17]
A. Cheskidov, C. Foias, On global attractors of the 3D Navier–Stokes equations, Journal of Differential Equations 231 (2006) 714–754. URL:https://linkinghub.elsevier.com/retrieve/pii/S002203960600338X. doi:10.1016/j.jde.2006.08.021
-
[18]
M. C. Bortolan, A. N. de Carvalho, P. Marín-Rubio, J. Valero, Weak global attractor for the 3D-Navier-Stokes equations via the globally mod- ified Navier-Stokes equations (2024). URL:http://arxiv.org/abs/2402.06435. doi:10.48550/arXiv.2402.06435, arXiv: 2402.06435
-
[19]
R. W. C. P. Verstappen, A. E. P. Veldman, Symmetry-preserving discretization of turbulent flow, Journal of Computational Physics 187 (2003) 343–368. doi:10.1016/S0021-9991(03)00126-8, publisher: Academic Press Inc
-
[20]
B. Sanderse, B. Koren, Accuracy analysis of explicit Runge-Kutta methods applied to the incompressible Navier-Stokes equations, Journal of Computational Physics 231 (2012) 3041–3063. doi:10.1016/j.jcp.2011.11.028, publisher: Academic Press Inc
-
[21]
F. Capuano, G. Coppola, L. Rández, L. de Luca, Explicit Runge–Kutta schemes for incompressible flow with improved energy-conservation properties, Journal of Computational Physics 328 (2017) 86–94. doi:10.1016/j.jcp.2016.10.040, publisher: Academic Press Inc
-
[22]
F. X. Trias, X. Álvarez-Farré, A. Alsalti-Baldellou, A. Gorobets, A. Oliva, An efficient eigenvalue bounding method: CFL condition revisited, Computer Physics Communications 305 (2024). doi:10.1016/j.cpc.2024.109351, publisher: Elsevier B.V
-
[23]
R. D. Falgout, J. E. Jones, U. M. Yang, The Design and Implementation of hypre, a Library of Parallel High Performance Preconditioners, in: A. Bruaset, A. Tveito (Eds.), Numerical Solution of Partial Differential Equations on Parallel Computers. Lecture Notes in Computational Science and Engineering, volume 51, Springer, Berlin, Heidelberg, 2006, pp. 267–294
work page 2006
-
[24]
G. Isotton, M. Frigo, N. Spiezia, C. Janna, Chronos: A General Purpose Classical AMG Solver for High Performance Computing, SIAM Journal on Scientific Computing 43 (2021) C335–C357. doi:10.1137/21M1398586. 24
-
[25]
V . A. Paludetto Magri, A. Franceschini, C. Janna, A Novel Algebraic Multigrid Approach Based on Adaptive Smooth- ing and Prolongation for Ill-Conditioned Systems, SIAM Journal on Scientific Computing 41 (2019) A190–A219. URL: https://epubs.siam.org/doi/10.1137/17M1161178. doi:10.1137/17M1161178
-
[26]
H. De Sterck, U. M. Yang, J. J. Heys, Reducing Complexity in Parallel Algebraic Multigrid Preconditioners, SIAM Journal on Matrix Analysis and Applications 27 (2006) 1019–1039. URL:http://epubs.siam.org/doi/10.1137/040615729. doi:10.1137/040615729
-
[27]
H. De Sterck, R. D. Falgout, J. W. Nolting, U. M. Yang, Distance-two interpolation for parallel algebraic multigrid, Numerical Linear Algebra with Applications 15 (2008) 115–139. URL:https://onlinelibrary.wiley.com/doi/10.1002/nla.559. doi:10.1002/nla.559
-
[28]
F. X. Trias, A. Gorobets, M. Soria, A. Oliva, Direct numerical simulation of a differentially heated cavity of aspect ratio 4 with Rayleigh numbers up to 1011 - Part I: Numerical methods and time-averaged flow, International Journal of Heat and Mass Transfer 53 (2010) 665–673. doi:10.1016/j.ijheatmasstransfer.2009.10.026
-
[29]
M. Mosqueda-Otero, À. Alsalti-Baldellou, X. Álvarez-Farré, J. Plana-Riu, G. Colomer, F. X. Trias, A. Oliva, A Portable Algebraic Im- plementation for Reliable Overnight Industrial LES, Proceedings of the 35th Parallel CFD International Conference 2024 35th Parallel CFD International Conference 2024 ParCFD 2024 (2025) pages 119 – 126. URL:https://juser.fz-...
-
[30]
A. D. Demou, D. G. E. Grigoriadis, Direct numerical simulations of Rayleigh–Bénard convection in water with non-Oberbeck–Boussinesq effects, Journal of Fluid Mechanics 881 (2019) 1073–1096. doi:10.1017/jfm.2019.787
-
[31]
P. Moin, K. Mahesh, DIRECT NUMERICAL SIMULATION: A Tool in Turbulence Research, Annual Review of Fluid Mechanics 30 (1998) 539–578. URL:https://www.annualreviews.org/doi/10.1146/annurev.fluid.30.1.539. doi:10.1146/annurev.fluid.30.1.539
-
[32]
A. Kolmogorov, The local structure of turbulence in incompressible viscous fluid for very large Reynolds numbers, Doklady Akademii Nauk SSSR 30 (1941) 9–13. doi:10.1098/rspa.1991.0075
-
[33]
A. Kolmogorov, On degeneration (decay) of isotropic turbulence in an incompressible viscous liquid, Doklady Akademii Nauk SSSR 31 (1941) 538–540
work page 1941
-
[34]
R. Courant, K. Friedrichs, H. Lewy, Über die partiellen Differenzengleichungen der mathematischen Physik, Mathematische Annalen 100 (1928) 32–74. doi:10.1007/BF01448839
-
[35]
J. Dongarra, M. A. Heroux, P. Luszczek, High-performance conjugate-gradient benchmark: A new metric for ranking high- performance computing systems, The International Journal of High Performance Computing Applications 30 (2016) 3–10. URL: https://journals.sagepub.com/doi/10.1177/1094342015593158. doi:10.1177/1094342015593158. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.