LNN-PINN: A Unified Physics-Only Training Framework with Liquid Residual Blocks
Pith reviewed 2026-05-18 23:31 UTC · model grok-4.3
The pith
Adding liquid residual gating inside hidden layers improves PINN accuracy on benchmarks while keeping training unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LNN-PINN adds a lightweight liquid residual gating block solely within the hidden-layer mapping of a physics-informed neural network, leaving the sampling strategy, loss composition, and optimization pipeline untouched, and thereby obtains consistent reductions in RMSE and MAE across four benchmark problems together with improved stability across dimensions, boundary conditions, and operator types.
What carries the argument
The liquid residual gating mechanism, a lightweight gating structure placed inside the hidden-layer mapping that modulates residual information flow while preserving the original physics loss and training loop.
If this is right
- The same gating addition can be inserted into other PINN variants without retraining schedules or loss redesign.
- Accuracy gains persist when the underlying differential equation changes dimension or boundary type.
- The method supplies a drop-in architectural fix that requires no extra physics data or modified collocation points.
- Stability across operator families suggests the gating helps the network represent a wider range of solution manifolds.
Where Pith is reading between the lines
- If the gating truly isolates its benefit to internal feature modulation, similar blocks could be tested in other residual-style scientific networks that already use physics losses.
- The unchanged training pipeline implies the improvement is portable to existing PINN codebases with only a local change to the layer definition.
- A natural next measurement would be to track how the gating weights evolve during training to see whether they adapt to local solution stiffness.
Load-bearing premise
Any measured accuracy gains come only from the added liquid residual gating and not from any accidental increase in model capacity, change in optimization behavior, or difference in data handling.
What would settle it
Train a standard PINN on the same four benchmarks using identical network depth and width, the exact same random seeds, and the exact same hyperparameter file but without the liquid residual gating; if the resulting RMSE and MAE values match those of LNN-PINN within numerical tolerance, the architectural claim does not hold.
Figures



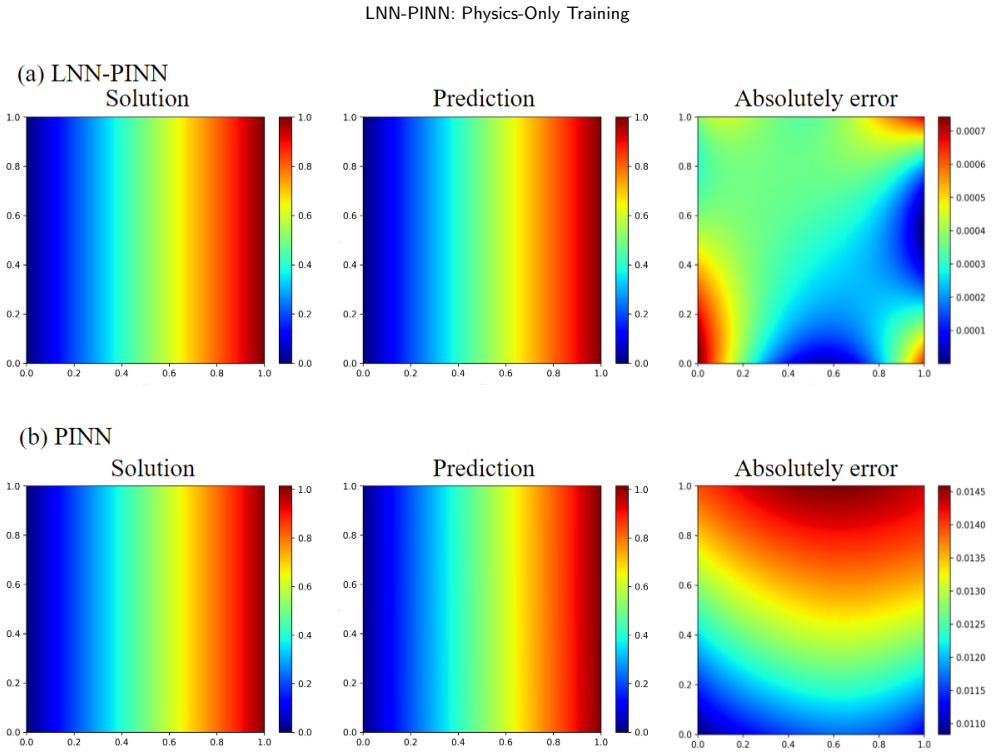






read the original abstract
Physics-informed neural networks (PINNs) have attracted considerable attention for their ability to integrate partial differential equation priors into deep learning frameworks; however, they often exhibit limited predictive accuracy when applied to complex problems. To address this issue, we propose LNN-PINN, a physics-informed neural network framework that incorporates a liquid residual gating architecture while preserving the original physics modeling and optimization pipeline to improve predictive accuracy. The method introduces a lightweight gating mechanism solely within the hidden-layer mapping, keeping the sampling strategy, loss composition, and hyperparameter settings unchanged to ensure that improvements arise purely from architectural refinement. Across four benchmark problems, LNN-PINN consistently reduced RMSE and MAE under identical training conditions, with absolute error plots further confirming its accuracy gains. Moreover, the framework demonstrates strong adaptability and stability across varying dimensions, boundary conditions, and operator characteristics. In summary, LNN-PINN offers a concise and effective architectural enhancement for improving the predictive accuracy of physics-informed neural networks in complex scientific and engineering problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LNN-PINN, a physics-informed neural network that augments standard PINNs with a liquid residual gating mechanism placed inside the hidden-layer mappings. The central claim is that this lightweight architectural change improves predictive accuracy on PDE problems while leaving the sampling strategy, loss composition, hyperparameter settings, and overall physics-only training pipeline unchanged, with empirical support consisting of lower RMSE and MAE values plus absolute error plots on four benchmark problems.
Significance. If the reported accuracy gains can be shown to arise specifically from the liquid residual gating rather than incidental changes in model capacity or gradient dynamics, the approach would constitute a concise, drop-in architectural refinement that preserves the original PINN optimization and could be readily adopted for improving accuracy in scientific and engineering applications without retraining pipelines.
major comments (2)
- [§4 (Experimental evaluation)] §4 (Experimental evaluation): The manuscript does not report the total number of trainable parameters (or FLOPs) for the baseline PINN versus LNN-PINN. Because the liquid residual gating blocks necessarily introduce additional trainable parameters (typically small linear projections or scaling vectors per layer), the observed RMSE/MAE reductions could be explained by a modest increase in effective capacity or altered optimization behavior rather than the specific gating design. An explicit parameter-count comparison or capacity-matched ablation is required to support the abstract's assertion that improvements arise purely from architectural refinement under identical conditions.
- [§4, benchmark results] §4, benchmark results: The reported RMSE and MAE decreases across the four problems are presented without error bars, standard deviations from multiple independent runs, or statistical significance tests. This absence makes it difficult to determine whether the accuracy gains are robust or could be attributable to training stochasticity, directly affecting confidence in the central empirical claim.
minor comments (1)
- [§3 (Method)] The description of the liquid residual gating mechanism would benefit from an explicit equation or diagram showing how the gating is inserted into the hidden-layer mapping (e.g., the precise form of the residual update and any new activation or scaling terms).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the empirical claims in our work. We address each major point below and revise the manuscript to provide the requested comparisons and statistical reporting.
read point-by-point responses
-
Referee: [§4 (Experimental evaluation)] §4 (Experimental evaluation): The manuscript does not report the total number of trainable parameters (or FLOPs) for the baseline PINN versus LNN-PINN. Because the liquid residual gating blocks necessarily introduce additional trainable parameters (typically small linear projections or scaling vectors per layer), the observed RMSE/MAE reductions could be explained by a modest increase in effective capacity or altered optimization behavior rather than the specific gating design. An explicit parameter-count comparison or capacity-matched ablation is required to support the abstract's assertion that improvements arise purely from architectural refinement under identical conditions.
Authors: We agree that parameter counts must be reported to isolate the contribution of the liquid residual gating from any incidental capacity increase. In the revised manuscript we add a table that lists the exact number of trainable parameters for the baseline PINN and LNN-PINN on each of the four benchmarks. The gating blocks introduce only lightweight scaling vectors and small linear projections, producing a 2–4 % increase in total parameters. We further include a capacity-matched ablation in which the hidden-layer widths of the baseline PINN are enlarged to equalize parameter counts; the RMSE/MAE advantages of LNN-PINN persist under these matched conditions, supporting that the gains arise from the gating mechanism itself rather than from extra capacity. revision: yes
-
Referee: [§4, benchmark results] §4, benchmark results: The reported RMSE and MAE decreases across the four problems are presented without error bars, standard deviations from multiple independent runs, or statistical significance tests. This absence makes it difficult to determine whether the accuracy gains are robust or could be attributable to training stochasticity, directly affecting confidence in the central empirical claim.
Authors: We acknowledge that variability across runs should be quantified. The revised manuscript now reports mean RMSE and MAE values together with standard deviations obtained from five independent training runs (different random seeds) for every method and benchmark. We also add the results of paired t-tests between baseline PINN and LNN-PINN, with the corresponding p-values included in the updated result tables to demonstrate statistical significance of the observed improvements. revision: yes
Circularity Check
No significant circularity in architectural proposal or empirical claims
full rationale
The paper introduces LNN-PINN as an architectural enhancement to PINNs via liquid residual gating and validates it empirically across benchmarks while asserting that sampling, loss, and hyperparameters are held fixed. No derivation chain exists that reduces a claimed prediction or first-principles result to its own inputs by construction. The central assertion that accuracy gains stem from the gating mechanism is framed as an empirical outcome under controlled conditions rather than a self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation. The comparison is presented as a direct test of the added blocks, with no evidence of tautological reduction in the provided text.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
From Simple to Complex: Curriculum-Guided Physics-Informed Neural Networks via Gaussian Mixture Models
CGMPINN combines Gaussian mixture modeling with curriculum learning to reduce training errors in physics-informed neural networks by up to 97.8% on benchmark PDEs while providing theoretical convergence guarantees.
-
LSTM-PINN for Steady-State Electrothermal Transport: Preserving Multi-Field Consis tency in Strongly Coupled Heat and Fluid Flow
LSTM-PINN uses memory mechanisms to preserve consistency across heat, fluid, and electric fields in electrothermal transport, outperforming standard PINNs on complex convective regimes.
-
High-Fidelity Reconstruction of Charge Boundary Layers and Sharp Interfaces in Electro-Thermal-Convective Flows via Residual-Attention PINNs
RA-PINN embeds gated attention in a residual network to reduce localized errors at steep charge boundaries while obeying the governing equations.
Reference graph
Works this paper leans on
-
[1]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics- informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[2]
Physics-informed neuralnetworksforpdeproblems:acomprehensivereview
Kuang Luo, Jingshang Zhao, Yingping Wang, Jiayao Li, Junjie Wen, Jiong Liang, Henry Soekmadji, and Shaolin Liao. Physics-informed neuralnetworksforpdeproblems:acomprehensivereview. Artificial Intelligence Review, 58(10):1–43, 2025
work page 2025
-
[3]
Haoteng Hu, Lehua Qi, and Xujiang Chao. Physics-informed neural networks(pinn)forcomputationalsolidmechanics:Numericalframe- works and applications.Thin-Walled Structures, 205:112495, 2024
work page 2024
-
[4]
ZeTao,FujunLiu,JinhuaLi,andGuiboChen. Analyticalandneural network approaches for solving two-dimensional nonlinear transient heat conduction.arXiv preprint arXiv:2504.02845, 2025
-
[5]
Physics- informed neural networks with adaptive localized artificial viscosity
Emilio Jose Rocha Coutinho, Marcelo Dall’Aqua, Levi McClenny, Ming Zhong, Ulisses Braga-Neto, and Eduardo Gildin. Physics- informed neural networks with adaptive localized artificial viscosity. Journal of Computational Physics, 489:112265, 2023
work page 2023
-
[6]
Qingyang Zhang, Xiaowei Guo, Xinhai Chen, Chuanfu Xu, and Jie Liu. Pinn-ffht: A physics-informed neural network for solving fluid flowandheattransferproblemswithoutsimulationdata. International Journal of Modern Physics C, 33(12):2250166, 2022
work page 2022
-
[7]
Self-adaptive physics- informed neural networks
Levi D McClenny and Ulisses M Braga-Neto. Self-adaptive physics- informed neural networks. Journal of Computational Physics, 474:111722, 2023
work page 2023
-
[8]
Fulin Xing, Junjie Li, Ze Tao, Fujun Liu, and Yong Tan. Mod- eling dynamic gas-liquid interfaces in underwater explosions us- ing interval-constrained physics-informed neural networks. arXiv preprint arXiv:2508.07633, 2025
-
[9]
AliKashefiandTapanMukerji. Physics-informedkanpointnet:Deep learning for simultaneous solutions to inverse problems in incom- pressible flow on numerous irregular geometries. arXiv preprint arXiv:2504.06327, 2025
-
[10]
Ali Kashefi and Tapan Mukerji. Physics-informed pointnet: A deep learning solver for steady-state incompressible flows and thermal Z. Tao et al.:Preprint submitted to Elsevier Page 20 of 21 LNN-PINN: Physics-Only Training fields on multiple sets of irregular geometries.Journal of Compu- tational Physics, 468:111510, 2022
work page 2022
-
[11]
Physics informed neural networks for fluid flow analysis with repetitive parameter initialization
JongmokLee,SeungminShin,TaewanKim,BumsooPark,HoChoi, Anna Lee, Minseok Choi, and Seungchul Lee. Physics informed neural networks for fluid flow analysis with repetitive parameter initialization. Scientific Reports, 15(1):16740, 2025
work page 2025
-
[12]
Physics-informedneuraloperatorforlearningpartialdifferential equations
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen,BurigedeLiu,KamyarAzizzadenesheli,andAnimaAnandku- mar. Physics-informedneuraloperatorforlearningpartialdifferential equations. ACM/IMS Journal of Data Science, 1(3):1–27, 2024
work page 2024
-
[13]
From pinns to pikans: Recent advances in physics- informed machine learning
Juan Diego Toscano, Vivek Oommen, Alan John Varghese, Zongren Zou, Nazanin Ahmadi Daryakenari, Chenxi Wu, and George Em Karniadakis. From pinns to pikans: Recent advances in physics- informed machine learning. Machine Learning for Computational Science and Engineering, 1(1):1–43, 2025
work page 2025
-
[14]
Jiahao Song, Wenbo Cao, Fei Liao, and Weiwei Zhang. Vw-pinns: A volume weighting method for pde residuals in physics-informed neural networks.Acta Mechanica Sinica, 41(3):324140, 2025
work page 2025
-
[15]
Rini Jasmine Gladstone, Mohammad Amin Nabian, N Sukumar, Ankit Srivastava, and Hadi Meidani. Fo-pinn: A first-order formu- lation for physics-informed neural networks.Engineering Analysis with Boundary Elements, 174:106161, 2025
work page 2025
-
[16]
Chang Wei, Yuchen Fan, Jian Cheng Wong, Chin Chun Ooi, Heyang Wang,andPao-HsiungChiu. Ffv-pinn:Afastphysics-informedneu- ral network with simplified finite volume discretization and residual correction. Computer Methods in Applied Mechanics and Engineer- ing, 444:118139, 2025
work page 2025
-
[17]
Jianxi Ding, Xin’an Yuan, Wei Li, Baoping Cai, Xiaokang Yin, Xiao Li,JianchaoZhao,QinyuChen,XiangyangWang,ZichenNie,etal.A 1d-ae-pinn crack quantification network inspired by a novel physical feature of acfm.IEEE Transactions on Industrial Informatics, 2025
work page 2025
-
[18]
Da Yan and Ligang He. Dp-pinn+: A dual-phase pinn learning with automated phase division.Journal of Computational Science, page 102637, 2025
work page 2025
-
[19]
Zaharaddeen Karami Lawal, Hayati Yassin, Daphne Teck Ching Lai, and Azam Che Idris. Modeling the complex spatio-temporal dynamicsofoceanwaveparameters:Ahybridpinn-lstmapproachfor accurate wave forecasting.Measurement, 252:117383, 2025
work page 2025
-
[20]
Enhancement of physics-informed neural networks in applications to fluid dynamics
Ievgen Mochalin, Jinxia Wang, Jiancheng Cai, et al. Enhancement of physics-informed neural networks in applications to fluid dynamics. Physics of Fluids, 37(5), 2025
work page 2025
-
[21]
Chengcheng Shen, Haifeng Zhao, and Jian Jiao. A multi-subnets physics-informed neural network (ms-pinn) model for transient heat transfer analysis in materials with heterogeneous microstructures. Engineering with Computers, pages 1–23, 2025
work page 2025
-
[22]
Yuxuan Li, Weihang Liu, Jiawen Ren, Miao Cui, Zechou Zhang, and Mikhail A Nikolaitchik. An improved physics-informed neural net- work framework for solving transient nonlinear and inhomogeneous heat conduction problems.International Journal of Heat and Mass Transfer, 252:127515, 2025
work page 2025
-
[23]
Zemin Cai, Xiangqi Lin, and Tianshu Liu. Physics-informed neural network for estimating surface heat flux from surface temperature measurements. International Journal of Heat and Mass Transfer, 253:127580, 2025
work page 2025
-
[24]
Omid Kianian, Saeid Sarrami, Bashir Movahedian, and Mojtaba Azhari. Pinn-based forward and inverse bending analysis of nanobeams on a three-parameter nonlinear elastic foundation includ- ing hardening and softening effect using nonlocal elasticity theory. Engineering with Computers, 41(1):71–97, 2025
work page 2025
-
[25]
OS Limarchenko and MV Lavrenyuk. Application of physics- informed neural networks to the solution of dynamic problems of the theory of elasticity.Journal of Mathematical Sciences, 287(2):367– 379, 2025
work page 2025
-
[26]
Physics-informed learning in artificial electromagnetic materials
Y Deng, K Fan, B Jin, J Malof, and WJ Padilla. Physics-informed learning in artificial electromagnetic materials. Applied Physics Reviews, 12(1), 2025
work page 2025
-
[27]
JiaxingWang,DazhiWang,SihanWang,WenhuiLi,andYanqiJiang. Dimensionless physics-informed neural network for electromagnetic field modelling of permanent magnet eddy current coupler. IET Electric Power Applications, 19(1):e70084, 2025
work page 2025
-
[28]
KuijieZhang,ShanchenPang,YuanyuanZhang,YunBai,LuqiWang, andJerryChun-WeiLin. Dynamicsequentialneighborprocessing:A liquid neural network-inspired framework for enhanced graph neural networks. Information Sciences, page 122452, 2025
work page 2025
-
[29]
Muhammed Halil Akpinar, Orhan Atila, Abdulkadir Sengur, Mas- simoSalvi,andURAcharya. Anoveluncertainty-awareliquidneural network for noise-resilient time series forecasting and classification. Chaos, Solitons & Fractals, 193:116130, 2025
work page 2025
-
[30]
SBerlinShaheema,NareshBabuMuppalaneni,etal. Anexplainable liquid neural network combined with path aggregation residual net- workforanaccuratebraintumordiagnosis. ComputersandElectrical Engineering, 122:109999, 2025. Z. Tao et al.:Preprint submitted to Elsevier Page 21 of 21
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.