Are Large Pre-trained Vision Language Models Effective Construction Safety Inspectors?
Pith reviewed 2026-05-18 22:27 UTC · model grok-4.3
The pith
Pre-trained vision-language models generalize to construction safety tasks in zero- and few-shot settings but still require additional training for real sites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that current state-of-the-art large pre-trained VLMs exhibit notable generalization abilities when applied to construction safety inspection in zero-shot and few-shot settings, although additional training is still needed to make them applicable to actual construction sites. This conclusion rests on the new ConstructionSite 10k dataset that supplies 10,000 images with annotations for image captioning, safety rule violation VQA, and construction element visual grounding, allowing systematic testing of models on realistic site imagery.
What carries the argument
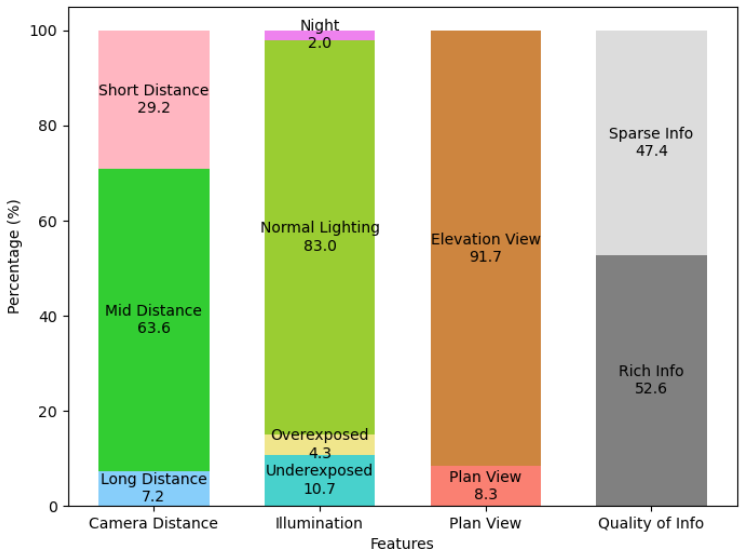
The ConstructionSite 10k dataset, a collection of 10,000 construction site images annotated for the three interconnected tasks of image captioning, safety-rule violation visual question answering, and construction element visual grounding.
If this is right
- The dataset can serve as a public benchmark for training and testing new VLM architectures on construction safety tasks.
- VLMs can already identify safety rule violations from site images without being trained directly on construction data.
- Few-shot fine-tuning on the dataset offers a practical path to improve model accuracy for real-world use.
- Automated image-based inspection could reduce the frequency of full manual walkthroughs while still requiring human oversight for final decisions.
Where Pith is reading between the lines
- If models trained on this dataset transfer well, similar benchmarks could be built for safety inspection in manufacturing plants or transportation infrastructure.
- Drone or fixed-camera systems could feed live images into these VLMs to flag violations in near real time, though integration with site-specific rules would still be required.
- The gap between zero-shot performance and practical readiness suggests that hybrid systems combining pre-trained VLMs with lightweight site-specific adaptation layers may be the fastest route to usable tools.
Load-bearing premise
Performance on captioning, safety-rule VQA, and element grounding is enough to decide whether a VLM can function as an effective construction safety inspector.
What would settle it
Deploying the evaluated VLMs on an active construction site and measuring whether they miss safety violations that on-site human inspectors consistently identify.
Figures









read the original abstract
Construction safety inspections typically involve a human inspector identifying safety concerns on-site. With the rise of powerful Vision Language Models (VLMs), researchers are exploring their use for tasks such as detecting safety rule violations from on-site images. However, there is a lack of open datasets to comprehensively evaluate and further fine-tune VLMs in construction safety inspection. Current applications of VLMs use small, supervised datasets, limiting their applicability in tasks they are not directly trained for. In this paper, we propose the ConstructionSite 10k, featuring 10,000 construction site images with annotations for three inter-connected tasks, including image captioning, safety rule violation visual question answering (VQA), and construction element visual grounding. Our subsequent evaluation of current state-of-the-art large pre-trained VLMs shows notable generalization abilities in zero-shot and few-shot settings, while additional training is needed to make them applicable to actual construction sites. This dataset allows researchers to train and evaluate their own VLMs with new architectures and techniques, providing a valuable benchmark for construction safety inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ConstructionSite 10k dataset of 10,000 construction-site images annotated for three interconnected tasks: image captioning, safety-rule violation visual question answering (VQA), and construction-element visual grounding. It evaluates several state-of-the-art large pre-trained vision-language models in zero-shot and few-shot regimes, asserts that these models exhibit notable generalization on the proposed tasks, and concludes that further training is required before the models can be deployed as practical construction safety inspectors. The dataset is presented as an open benchmark to support training and evaluation of new VLM architectures for this domain.
Significance. If the quantitative evaluation is strengthened and the task proxies are shown to be adequate, the work would be a useful contribution by releasing the first sizable open dataset for VLM-based construction safety inspection. The empirical demonstration of zero- and few-shot behavior on captioning, VQA, and grounding tasks provides a concrete starting point for the community; credit is given for the public release of the annotated corpus, which directly addresses the data-scarcity problem noted in the abstract.
major comments (2)
- [Abstract] Abstract: the claim of 'notable generalization abilities in zero-shot and few-shot settings' is presented without any quantitative metrics, error bars, or statistical tests, leaving the central evaluation claim unsupported by numbers.
- [Abstract, paragraph 3] Abstract, paragraph 3: the three tasks (captioning, safety-rule VQA, element grounding) are treated as sufficient to assess whether a VLM can function as an effective construction safety inspector, yet the paper does not demonstrate how these single-image tasks capture sequential observation, integration with site plans or regulations, risk prioritization, or handling of dynamic/occluded scenes that characterize real inspections.
minor comments (1)
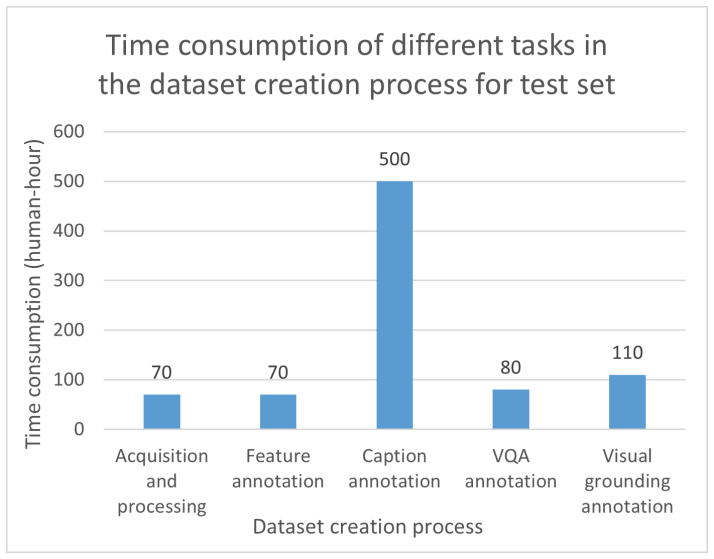
- [Section 3] Section 3: the annotation protocol would benefit from explicit reporting of inter-annotator agreement scores or quality-control procedures for the VQA and grounding labels.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below, clarifying the scope of our claims and indicating revisions where they strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'notable generalization abilities in zero-shot and few-shot settings' is presented without any quantitative metrics, error bars, or statistical tests, leaving the central evaluation claim unsupported by numbers.
Authors: We agree that the abstract's phrasing would be strengthened by direct reference to quantitative results. The full paper reports concrete metrics in Section 4 (e.g., BLEU-4 and CIDEr for captioning, accuracy for VQA, and IoU for grounding across zero- and few-shot regimes), including comparisons against random and supervised baselines. In the revised manuscript we have added a concise sentence to the abstract summarizing the key observed improvements (e.g., X-point gains in few-shot VQA accuracy) while preserving brevity; error bars and statistical details remain in the experimental section as is conventional for abstracts. revision: yes
-
Referee: [Abstract, paragraph 3] Abstract, paragraph 3: the three tasks (captioning, safety-rule VQA, element grounding) are treated as sufficient to assess whether a VLM can function as an effective construction safety inspector, yet the paper does not demonstrate how these single-image tasks capture sequential observation, integration with site plans or regulations, risk prioritization, or handling of dynamic/occluded scenes that characterize real inspections.
Authors: We do not claim that the three single-image tasks fully replicate operational inspections. The manuscript explicitly frames them as interconnected benchmark tasks that probe core VLM capabilities (description, violation detection, localization) and states in both the introduction and conclusion that real deployment would require further training, multi-view reasoning, and integration with site documentation. To address the referee's concern we have added a new paragraph in the revised discussion section that maps each task to specific inspection elements while openly listing the missing aspects (sequential observation, dynamic scenes, risk prioritization) as directions for future work. revision: partial
Circularity Check
No circularity: dataset creation plus evaluation of external pre-trained models
full rationale
The paper introduces the ConstructionSite 10k dataset with annotations for captioning, safety-rule VQA, and element grounding, then reports zero-shot and few-shot results of existing large VLMs on those tasks. No equations, fitted parameters, or internal predictions appear; the central claims rest on empirical performance numbers obtained from models whose weights and training data are external to the paper. The three tasks are presented as a benchmark rather than derived from any self-referential construction, and no self-citation chain is invoked to justify uniqueness or force a result. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained VLMs exhibit meaningful zero-shot and few-shot generalization on previously unseen domain-specific visual question answering and grounding tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the ConstructionSite 10k, featuring 10,000 construction site images with annotations for three inter-connected tasks, including image captioning, safety rule violation visual question answering (VQA), and construction element visual grounding.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our subsequent evaluation of current state-of-the-art large pre-trained VLMs shows notable generalization abilities in zero-shot and few-shot settings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Integration of Object Detection and Small VLMs for Construction Safety Hazard Identification
Detection-guided prompting raises small VLM hazard F1 from 34.5% to 50.6% and BERTScore from 0.61 to 0.82 on construction images with only 2.5 ms added latency.
Reference graph
Works this paper leans on
- [1]
-
[2]
Flamingo: a visual language model for few-shot learning
Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., et al. (2022). “Flamingo: a visual language model for few-shot learning.” NeurIPS, <https://openreview.net/forum?id=EbMuimAbPbs>. An,X.,Zhou,L.,Liu,Z.,Wang,C.,Li,P.,andLi,Z.(2021).“Datasetandbenchmarkfordetecting moving objects in construction sites.”Automation in Construction, 122, 103482
work page 2022
-
[3]
Spice: Semantic propositional image caption evaluation
Anderson, P., Fernando, B., Johnson, M., and Gould, S. (2016). “Spice: Semantic propositional image caption evaluation.”ECCV, Vol. 9909, 382–398
work page 2016
-
[4]
Language models are few-shot learners
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, et al. (2020). “Language models are few-shot learners.”NeurIPS, Vol. 33, Curran Associates, Inc., 1877–1901
work page 2020
-
[5]
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Zhang, P., Krishnamoorthi, R., Chandra, V., Xiong, Y., and Elhoseiny, M. (2023). “Minigpt-v2: large language model as a unified interface for vision-language multi-task learning.”arXiv preprint arXiv:2310.09478
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Chen, S. and Demachi, K. (2021). “Towards on-site hazards identification of improper use of personalprotectiveequipmentusingdeeplearning-basedgeometricrelationshipsandhierarchical scene graph.”Automation in Construction, 125, 103619
work page 2021
-
[7]
Chen, X., Fang, H., Lin, T.-Y., Vedantam, R., Gupta, S., Dollar, P., and Zitnick, C. L. (2015). “Microsoft coco captions: Data collection and evaluation server
work page 2015
-
[8]
Gonzalez, J. E., Stoica, I., and Xing, E. P. (2023). “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,<https://lmsys.org/blog/2023-03-30-vicuna/>
work page 2023
-
[9]
Meteor universal: Language specific translation evaluation foranytargetlanguage
Denkowski, M. and Lavie, A. (2014). “Meteor universal: Language specific translation evaluation foranytargetlanguage.”ProceedingsoftheNinthWorkshoponStatisticalMachineTranslation
work page 2014
-
[10]
Soda: A large-scale open site object detection dataset for deep learning in construction
Duan, R., Deng, H., Tian, M., Deng, Y., and Lin, J. (2022). “Soda: A large-scale open site object detection dataset for deep learning in construction.”Automation in Construction, 142, 104499
work page 2022
-
[11]
Fang, W., Love, P. E., Ding, L., Xu, S., Kong, T., and Li, H. (2023). “Computer vision and deep learning to manage safety in construction: Matching images of unsafe behavior and semantic rules.”IEEE Transactions on Engineering Management, 70(12), 4120–4132
work page 2023
-
[12]
Eva: Exploring the limits of masked visual representation learning at scale
Fang, Y., Wang, W., Xie, B., Sun, Q., Wu, L., Wang, X., Huang, T., Wang, X., and Cao, Y. (2022). “Eva: Exploring the limits of masked visual representation learning at scale.”arXiv preprint arXiv:2211.07636
-
[13]
Gil, D. and Lee, G. (2024). “Zero-shot monitoring of construction workers’ personal protective equipment based on image captioning.”Automation in Construction, 164, 105470
work page 2024
-
[14]
Vizwiz grand challenge: Answering visual questions from blind people
Gurari, D., Li, Q., Stangl, A., Guo, A., Lin, C., Grauman, K., Luo, J., and Bigham, J. P. (2018). “Vizwiz grand challenge: Answering visual questions from blind people.”CVPR, 3608–3617
work page 2018
-
[15]
‘clips’core: A reference- free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y. (2021). “‘clips’core: A reference- free evaluation metric for image captioning.”EMNLP
work page 2021
-
[16]
Framingimagedescriptionasarankingtask: Data, models and evaluation metrics
Hessel, J., Marasović, A., Hwang, J. D., Lee, L., Da, J., Zellers, R., Mankoff, R., and Choi, Y. (2023).“Doandroids laughatelectricsheep? humor’understanding’benchmarks fromthenew yorker caption contest. Hodosh,M.,Young,P.,andHockenmaier,J.(2013).“Framingimagedescriptionasarankingtask: Data, models and evaluation metrics.”Journal of Artificial Intelligenc...
work page 2023
-
[17]
Text encoders bottleneck compositionality in contrastive vision-language models
Kamath, A., Hessel, J., and Chang, K.-W. (2023). “Text encoders bottleneck compositionality in contrastive vision-language models.”EMNLP. Kazemzadeh,S.,Ordonez,V.,Matten,M.,andBerg,T.(2014).“ReferItGame: Referringtoobjects inphotographsofnaturalscenes.” EMNLP,AssociationforComputationalLinguistics,787–798, <https://aclanthology.org/D14-1086>
work page 2023
-
[18]
Liu, H., Li, C., Li, Y., and Lee, Y. J. (2024). “Improved baselines with visual instruction tuning
work page 2024
-
[19]
Liu, H., Li, C., Wu, Q., and Lee, Y. J. (2023a). “Visual instruction tuning..”NeurIPS, Vol. 36, Curran Associates, Inc. Liu,H.,Wang,G.,Huang,T.,He,P.,Skitmore,M.,andLuo,X.(2020).“Manifestingconstruction activity scenes via image captioning.”Automation in Construction, 119, 103334. Liu,J.,Fang,W.,Love,P.E.,Hartmann,T.,Luo,H.,andWang,L.(2022).“Detectionandl...
work page 2020
-
[20]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.-W., Zhu, S.-C., Tafjord, O., Clark, P., and Kalyan, A. (2022). “Learn to explain: Multimodal reasoning via thought chains for science question answering.”NeurIPS. Macháček, M. and Bojar, O. (2014). “Results of the WMT14 metrics shared task.”Proceedings of theNinthWorkshoponStatisticalMachineTranslation ,Balt...
work page 2022
-
[21]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Marino, K., Rastegari, M., Farhadi, A., and Mottaghi, R. (2019). “Ok-vqa: A visual question answering benchmark requiring external knowledge.”CVPR
work page 2019
-
[22]
Altenschmidt, J., et al. (2024). “GPT-4 technical report
work page 2024
-
[23]
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin,P.,Clark,J.,Krueger,G.,andSutskever,I.(2021).“Learningtransferablevisualmodels from natural language supervision
work page 2021
-
[24]
Generatingconstructionsafetyobservationsviaclip- basedimage-languageembedding
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). “Language models are unsupervised multitask learners,<https://api.semanticscholar.org/CorpusID:160025533>. Tsai,W.L.,Lin,J.J.,andHsieh,S.-H.(2023).“Generatingconstructionsafetyobservationsviaclip- basedimage-languageembedding.”ComputerVision–ECCV2022Workshops ,L.Karlinsky,T. M...
work page 2019
-
[25]
Cider: Consensus-based image description evaluation
Vedantam, R., Zitnick, C., and Parikh, D. (2015). “Cider: Consensus-based image description evaluation.” 4566–4575
work page 2015
-
[26]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Zhou, D. (2023). “Chain-of-thought prompting elicits reasoning in large language models, <https://arxiv.org/abs/2201.11903>. WorkSafeBC (2024). “Worksafebc.”www.worksafebc.com
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Development of an image data set of construction machines for deep learning object detection
Xiao, B. and Kang, S.-C. (2021). “Development of an image data set of construction machines for deep learning object detection.”Journal of Computing in Civil Engineering, 35(2)
work page 2021
-
[28]
Deep learning image captioning in construction 27 management: A feasibility study
Xiao, B., Wang, Y., and Kang, S.-C. (2022). “Deep learning image captioning in construction 27 management: A feasibility study.”Journal of Construction Engineering and Management, 148(7), 04022049
work page 2022
-
[29]
Pose guided anchoring for detecting proper use of personal protective equipment
Xiong, R. and Tang, P. (2021). “Pose guided anchoring for detecting proper use of personal protective equipment.”Automation in Construction, 130, 103828
work page 2021
-
[30]
Bertscore: Evaluating text generation with bert
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y. (2020). “Bertscore: Evaluating text generation with bert.”ICLR, <https://openreview.net/forum?id=SkeHuCVFDr>
work page 2020
-
[31]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. (2023). “Judging llm-as-a-judge with mt-bench and chatbot arena,<https://arxiv.org/abs/2306.05685>
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. (2023). “Minigpt-4: Enhancing vision- language understanding with advanced large language models
work page 2023
-
[33]
Bringing semantics into focus using visual abstraction
Zitnick, C. L. and Parikh, D. (2013). “Bringing semantics into focus using visual abstraction.” CVPR. 28
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.