Cross-Flow Correlations Survive Synthesis: Measuring Source-Level Privacy Leakage in Synthetic Network Traces
Pith reviewed 2026-05-18 22:20 UTC · model grok-4.3
The pith
Synthetic network data generators preserve cross-flow correlations that leak whether a specific user's or service's traffic was in the training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
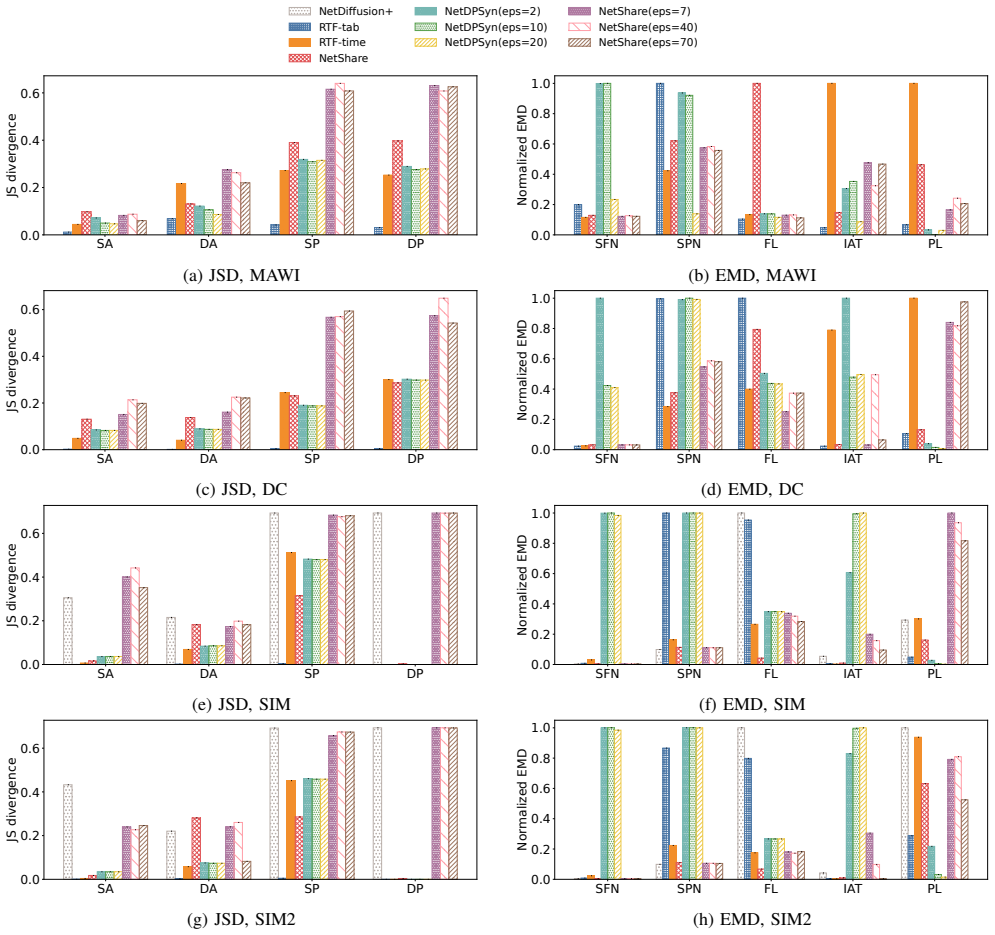
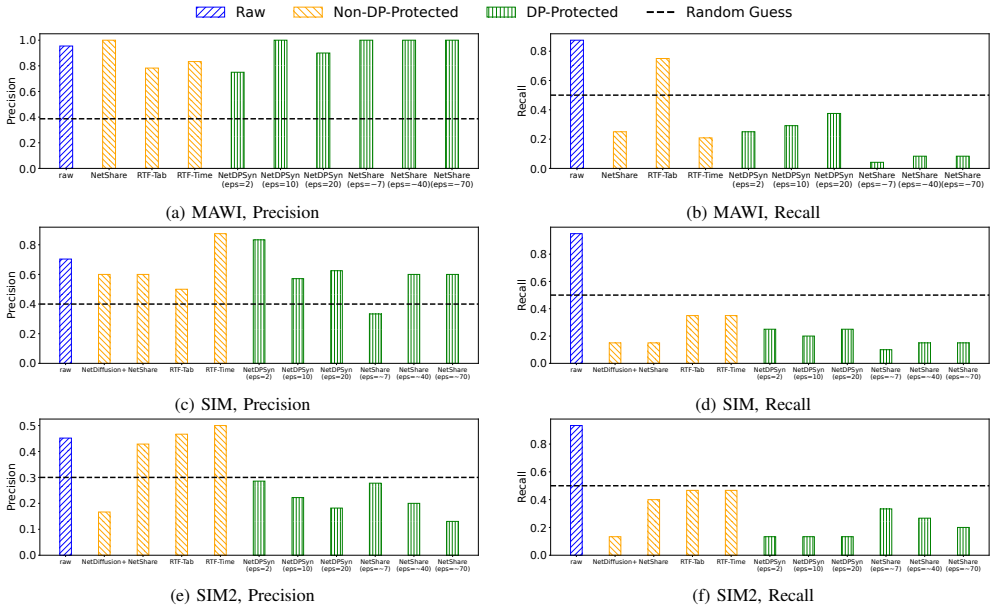
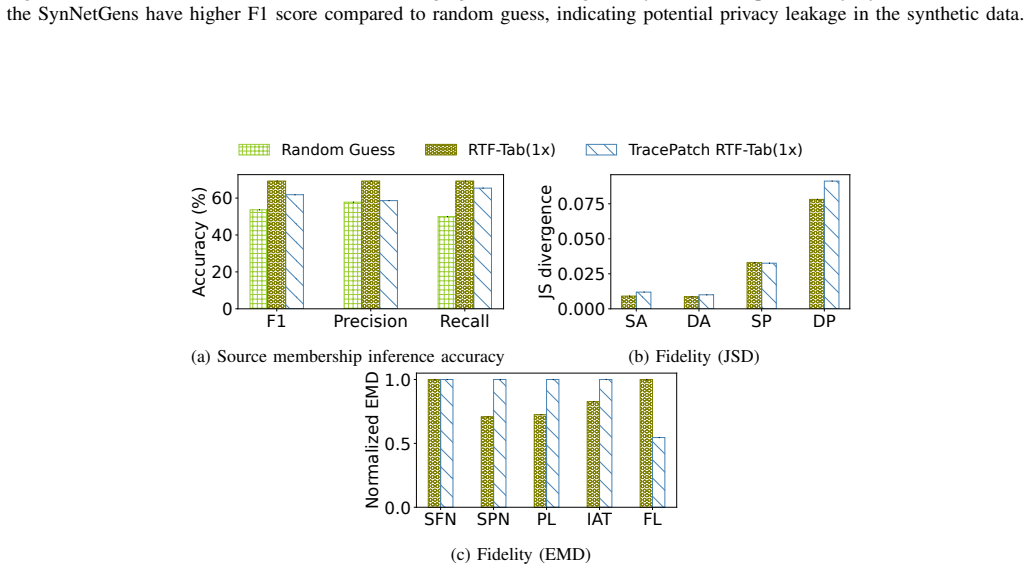
SynNetGens preserve cross-flow behavioral correlations that expose source-level membership, allowing an attacker to determine whether traffic of a specific user or service was included in the training data. This leakage arises from a mismatch in abstraction: existing SynNetGens operate and are protected at the packet or flow level, while sensitive information is encoded in correlations across flows from the same source. TraceBleed, the first source-level membership inference attack against black-box SynNetGens, shows that every generator leaks on at least some datasets, flow- or packet-level differential privacy fails unless fidelity is degraded to unusable levels, and releasing 10X more合成数据
What carries the argument
TraceBleed attack that exploits preserved cross-flow behavioral correlations to perform source-level membership inference on outputs of black-box SynNetGens.
If this is right
- Every tested generator leaks source-level information on at least some of the five evaluated datasets.
- Flow- or packet-level differential privacy does not protect source privacy unless the synthetic data fidelity is reduced to levels that make the traces unusable.
- Releasing ten times more synthetic data increases average leakage by 130 percent.
- A public privacy-fidelity leaderboard can help practitioners select generators that balance their specific privacy and utility needs.
Where Pith is reading between the lines
- Source-level privacy may require new synthesis methods that deliberately decorrelate flows belonging to the same user or service.
- The same cross-record correlation leakage pattern could appear in other synthetic data domains where individual entities generate multiple related records.
- Future generators could incorporate explicit source-level privacy budgets rather than relying on flow-level mechanisms.
Load-bearing premise
That differential privacy or other protections applied at the individual flow or packet level will also prevent inference about whether any particular source's data was used to train the generator.
What would settle it
An experiment in which a generator is modified to explicitly break cross-flow correlations from the same source and the TraceBleed attack success rate falls to random guessing while synthetic fidelity remains high enough for downstream tasks.
Figures













read the original abstract
Synthetic network data generators (SynNetGens) are increasingly used to share realistic traffic traces without exposing sensitive raw data. While substantial effort has gone into improving fidelity, privacy is either assumed to be a built-in property of synthesis or addressed through differential privacy at the packet or flow level. This paper uncovers a fundamental privacy vulnerability: SynNetGens preserve cross-flow behavioral correlations that expose source-level membership, allowing an attacker to determine whether traffic of specific user, or service was included in the training data. This leakage arises from a mismatch in abstraction: existing SynNetGens operate and are protected at the packet or flow level, while sensitive information is encoded in correlations across flows from the same source. To demonstrate that this vulnerability is exploitable in practice, we develop TraceBleed, the first source-level membership inference attack against black-box SynNetGens. Our evaluation spans five datasets and six SynNetGens, revealing that: (i) every generator leaks source-level information on at least some datasets; (ii) flow- or packet-level differential privacy fails to protect source privacy unless fidelity is degraded to unusable levels; and (iii) releasing 10X more synthetic data amplifies leakage by 130% on average. To support ongoing research in this area, we will maintain a public privacy-fidelity leaderboard so practitioners can choose generators that fit their needs and researchers can benchmark new designs faithfully.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that synthetic network trace generators (SynNetGens) preserve cross-flow behavioral correlations from training data, enabling source-level membership inference attacks that reveal whether traffic from a specific user or service was included. The authors introduce TraceBleed as the first such black-box attack and evaluate it on five datasets and six generators, reporting that every generator leaks on at least some datasets, that packet- or flow-level differential privacy fails to protect source privacy unless fidelity is degraded to unusable levels, and that releasing 10X more synthetic data amplifies leakage by 130% on average.
Significance. If the results hold, the work identifies a previously under-appreciated privacy risk arising from an abstraction mismatch: protections and synthesis occur at the packet/flow level while sensitive information resides in cross-flow correlations. This could affect how synthetic traces are shared for research and could motivate new source-level privacy mechanisms. The planned public privacy-fidelity leaderboard is a constructive contribution for ongoing benchmarking.
major comments (2)
- [Evaluation] The central claim that leakage occurs specifically because cross-flow correlations survive synthesis (rather than from generic distributional shifts or per-flow memorization) is load-bearing for the mismatch-in-abstraction narrative. However, the evaluation does not include a feature ablation that compares TraceBleed performance using only per-flow statistics (packet sizes, durations, rates) against the full cross-flow feature set. Without this, it remains possible that reported attack success does not isolate the emphasized mechanism. Evaluation section / TraceBleed feature description.
- [DP experiments] The claim that flow- or packet-level DP fails to protect source privacy unless fidelity is degraded to unusable levels is a key practical finding. The manuscript should specify the exact DP mechanisms tested, the epsilon values used, and the quantitative fidelity thresholds (e.g., which similarity metrics and cutoffs) that render the data unusable, so readers can assess the trade-off precisely. §6 or DP experiments subsection.
minor comments (2)
- [Abstract] The abstract states that a public privacy-fidelity leaderboard will be maintained; the manuscript should include a concrete URL, repository link, or current status of this resource to make the commitment verifiable.
- [Introduction] Notation for source-level membership (e.g., how a 'source' is defined across datasets) could be clarified earlier to help readers map the attack to different network environments.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the major comments point-by-point below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] The central claim that leakage occurs specifically because cross-flow correlations survive synthesis (rather than from generic distributional shifts or per-flow memorization) is load-bearing for the mismatch-in-abstraction narrative. However, the evaluation does not include a feature ablation that compares TraceBleed performance using only per-flow statistics (packet sizes, durations, rates) against the full cross-flow feature set. Without this, it remains possible that reported attack success does not isolate the emphasized mechanism. Evaluation section / TraceBleed feature description.
Authors: We agree that an ablation study would more rigorously isolate the role of cross-flow correlations and strengthen the abstraction-mismatch argument. In the revised manuscript we will add this analysis to the Evaluation section, reporting TraceBleed performance when restricted to per-flow statistics alone versus the complete cross-flow feature set. This will allow readers to quantify how much of the observed leakage is attributable to the cross-flow mechanism we emphasize. revision: yes
-
Referee: [DP experiments] The claim that flow- or packet-level DP fails to protect source privacy unless fidelity is degraded to unusable levels is a key practical finding. The manuscript should specify the exact DP mechanisms tested, the epsilon values used, and the quantitative fidelity thresholds (e.g., which similarity metrics and cutoffs) that render the data unusable, so readers can assess the trade-off precisely. §6 or DP experiments subsection.
Authors: We will revise the DP experiments subsection to provide the requested details. The updated text will name the concrete DP mechanisms and implementations used, list the specific epsilon values evaluated, and define quantitative fidelity thresholds (e.g., acceptable ranges for Jensen-Shannon divergence, Wasserstein distance, or other similarity metrics) together with the cutoff values at which the synthetic traces are considered unusable for downstream research tasks. revision: yes
Circularity Check
No circularity: empirical attack evaluation is self-contained
full rationale
The paper develops and evaluates TraceBleed, an empirical source-level membership inference attack on synthetic network generators across five datasets and six generators. Claims rest on experimental measurements of attack success rates under varying privacy mechanisms and data volumes, without any first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The central results (leakage existence, DP ineffectiveness at source level, amplification with more data) are directly measured outcomes, not reductions to quantities defined within the paper's own equations or prior author work. This is a standard empirical security study with independent grounding from multi-generator testing.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TraceBleed employs contrastive learning to group traffic segments from the same source closer together in embedding space while pushing apart segments from different sources, without depending on fixed label sets.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We frame privacy as membership inference at the traffic-source level—a realistic and actionable threat for data holders.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Flow-based network traffic generation using generative adversarial networks,
L. Han, Y . Sheng, and X. Zeng, “Flow-based network traffic generation using generative adversarial networks,” in2019 IEEE 10th Annual Infor- mation Technology, Electronics and Mobile Communication Conference (IEMCON). IEEE, 2019, pp. 728–734
work page 2019
-
[2]
——, “A packet-length-adjustable attention model based on bytes em- bedding using flow-wgan for smart cybersecurity,” IEEE Access, vol. 7, pp. 82 913–82 926, 2019
work page 2019
-
[3]
Using gans for sharing networked time series data: Challenges, initial promise, and open questions,
Z. Lin, A. Jain, C. Wang, G. Fanti, and V . Sekar, “Using gans for sharing networked time series data: Challenges, initial promise, and open questions,” inProceedings of the ACM internet measurement conference, 2020, pp. 464–483
work page 2020
-
[4]
Flow-based network traffic generation using generative adversarial networks,
M. Ring, D. Schl ¨or, D. Landes, and A. Hotho, “Flow-based network traffic generation using generative adversarial networks,” Computers & Security, vol. 82, pp. 156–172, 2019
work page 2019
-
[5]
Packetcgan: Exploratory study of class imbalance for encrypted traffic classification using cgan,
P. Wang, S. Li, F. Ye, Z. Wang, and M. Zhang, “Packetcgan: Exploratory study of class imbalance for encrypted traffic classification using cgan,” in ICC 2020 - 2020 IEEE International Conference on Communications (ICC). IEEE, 2020, pp. 1–7
work page 2020
-
[6]
Modeling tabular data using conditional gan,
L. Xu, M. Skoularidou, A. Cuesta-Infante, and K. Veeramacha- neni, “Modeling tabular data using conditional gan,” arXiv preprint arXiv:1907.00503, 2019
-
[7]
Stan: Synthetic network traffic generation using autoregressive neural models,
S. Xu, M. Marwah, and N. Ramakrishnan, “Stan: Synthetic network traffic generation using autoregressive neural models,” arXiv preprint arXiv:2009.12740, 2020
-
[8]
Practical gan-based synthetic ip header trace generation using netshare,
Y . Yin, Z. Lin, M. Jin, G. Fanti, and V . Sekar, “Practical gan-based synthetic ip header trace generation using netshare,” in Proceedings of the ACM SIGCOMM 2022 Conference , 2022, pp. 458–472
work page 2022
-
[9]
Netdpsyn: synthe- sizing network traces under differential privacy,
D. Sun, J. Q. Chen, C. Gong, T. Wang, and Z. Li, “Netdpsyn: synthe- sizing network traces under differential privacy,” in Proceedings of the 2024 ACM on Internet Measurement Conference , 2024, pp. 545–554
work page 2024
-
[10]
Netdiffusion: Network data augmentation through protocol-constrained traffic generation,
X. Jiang, S. Liu, A. Gember-Jacobson, A. N. Bhagoji, P. Schmitt, F. Bronzino, and N. Feamster, “Netdiffusion: Network data augmentation through protocol-constrained traffic generation,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 8, no. 1, pp. 1–32, 2024
work page 2024
-
[11]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE symposium on security and privacy (SP) . IEEE, 2017, pp. 3–18
work page 2017
-
[12]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson et al., “Extracting training data from large language models,” in 30th USENIX security symposium (USENIX Security 21) , 2021, pp. 2633–2650
work page 2021
-
[13]
A. Salem, Y . Zhang, M. Humbert, P. Berrang, M. Fritz, and M. Backes, “Ml-leaks: Model and data independent membership inference at- tacks and defenses on machine learning models,” arXiv preprint arXiv:1806.01246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Deep fingerprinting: Undermining website fingerprinting defenses with deep learning,
P. Sirinam, M. Imani, M. Juarez, and M. Wright, “Deep fingerprinting: Undermining website fingerprinting defenses with deep learning,” in Proceedings of the 2018 ACM SIGSAC conference on computer and communications security, 2018, pp. 1928–1943
work page 2018
-
[15]
A. V . Solatorio and O. Dupriez, “Realtabformer: Generating real- istic relational and tabular data using transformers,” arXiv preprint arXiv:2302.02041, 2023
-
[16]
Differential privacy has disparate impact on model accuracy,
E. Bagdasaryan, O. Poursaeed, and V . Shmatikov, “Differential privacy has disparate impact on model accuracy,” in Advances in Neural Information Processing Systems , vol. 32, 2019, pp. 15 453–15 462. [Online]. Available: https://proceedings.neurips.cc/paper/2019/hash/fc0 de4e0396fff257ea362983c2dda5a-Abstract.html
work page 2019
-
[17]
Utility-privacy tradeoffs in databases: An information-theoretic approach,
L. Sankar, S. R. Rajagopalan, and H. V . Poor, “Utility-privacy tradeoffs in databases: An information-theoretic approach,” IEEE Transactions on Information Forensics and Security , vol. 8, no. 6, pp. 838–852,
-
[18]
Utility-Privacy Tradeoff in Databases: An Information-theoretic Approach
[Online]. Available: https://arxiv.org/abs/1102.3751
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Stable internet routing without global coor- dination,
L. Gao and J. Rexford, “Stable internet routing without global coor- dination,” IEEE/ACM Transactions on networking , vol. 9, no. 6, pp. 681–692, 2001
work page 2001
-
[20]
LOGAN: Membership Inference Attacks Against Generative Models
J. Hayes, L. Melis, G. Danezis, and E. De Cristofaro, “Logan: Mem- bership inference attacks against generative models,” arXiv preprint arXiv:1705.07663, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Privacy risk in machine learning: Analyzing the connection to overfitting,
S. Yeom, I. Giacomelli, M. Fredrikson, and S. Jha, “Privacy risk in machine learning: Analyzing the connection to overfitting,” in 2018 IEEE 31st computer security foundations symposium (CSF) . IEEE, 2018, pp. 268–282
work page 2018
-
[22]
Bro: A system for detecting network intruders in real-time,
V . Paxson, “Bro: A system for detecting network intruders in real-time,” in Proceedings of the 7th USENIX Security Symposium . San Antonio, TX: USENIX Association, 1998. [Online]. Available: https://www.usenix.org/conference/7th-usenix-security-symposium/bro -system-detecting-network-intruders-real-time
work page 1998
-
[23]
Accurate, scalable in- network identification of p2p traffic using application signatures,
S. Sen, O. Spatscheck, and D. Wang, “Accurate, scalable in- network identification of p2p traffic using application signatures,” in Proceedings of the 13th International Conference on World Wide Web (WWW) . ACM, 2004, pp. 512–521. [Online]. Available: https://doi.org/10.1145/988672.988742
-
[24]
Calibrating imbalanced classifiers with focal loss: An empirical study,
C. Wang, J. Balazs, G. Szarvas, P. Ernst, L. Poddar, and P. Danchenko, “Calibrating imbalanced classifiers with focal loss: An empirical study,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track , 2022, pp. 145–153
work page 2022
-
[25]
Adafocal: Calibration-aware adaptive focal loss,
A. Ghosh, T. Schaaf, and M. Gormley, “Adafocal: Calibration-aware adaptive focal loss,” Advances in Neural Information Processing Sys- tems, vol. 35, pp. 1583–1595, 2022
work page 2022
-
[26]
Tam: topology-aware margin loss for class-imbalanced node classification,
J. Song, J. Park, and E. Yang, “Tam: topology-aware margin loss for class-imbalanced node classification,” in International Conference on Machine Learning. PMLR, 2022, pp. 20 369–20 383
work page 2022
-
[27]
Robustifying ml-powered network classifiers with pants,
M. Jin and M. Apostolaki, “Robustifying ml-powered network classifiers with pants,” in34th USENIX Security Symposium (USENIX Security 25), 2025
work page 2025
-
[28]
The caida ucsd anonymized internet traces,
“The caida ucsd anonymized internet traces,” https://www.caida.org/ca talog/datasets/passive dataset, accessed: 2025-03-18
work page 2025
-
[29]
A decade long view of internet traffic composition in japan,
I. Tsareva, T. V . Doan, and V . Bajpai, “A decade long view of internet traffic composition in japan,” in2023 IFIP Networking Conference (IFIP Networking). IEEE, 2023, pp. 1–9
work page 2023
-
[30]
Network traffic characteristics of data centers in the wild,
T. Benson, A. Akella, and D. A. Maltz, “Network traffic characteristics of data centers in the wild,” in Proceedings of the 10th ACM SIGCOMM conference on Internet measurement , 2010, pp. 267–280
work page 2010
-
[31]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems , vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[32]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language mod- els are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[33]
PrivSyn: Differentially private data synthesis,
Z. Zhang, T. Wang, N. Li, J. Honorio, M. Backes, S. He, J. Chen, and Y . Zhang, “PrivSyn: Differentially private data synthesis,” in 30th USENIX Security Symposium (USENIX Security 21) . USENIX Association, Aug. 2021, pp. 929–946. [Online]. Available: https://ww w.usenix.org/conference/usenixsecurity21/presentation/zhang-zhikun
work page 2021
-
[34]
Overlearning in marginal distribution-based ica: analysis and solutions,
J. S ¨arel¨a and R. Vig ´ario, “Overlearning in marginal distribution-based ica: analysis and solutions,”Journal of machine learning research, vol. 4, no. Dec, pp. 1447–1469, 2003
work page 2003
- [35]
-
[36]
The devil and packet trace anonymization,
R. Pang, M. Allman, V . Paxson, and J. Lee, “The devil and packet trace anonymization,” SIGCOMM Comput. Commun. Rev. , vol. 36, no. 1, p. 29–38, Jan. 2006. [Online]. Available: https: //doi.org/10.1145/1111322.1111330
-
[37]
Extracting training data from diffusion models,
N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V . Sehwag, F. Tramer, B. Balle, D. Ippolito, and E. Wallace, “Extracting training data from diffusion models,” in 32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 5253–5270
work page 2023
-
[38]
A comparative study of network traffic representations for novelty detection,
K. Yang, S. Kpotufe, and N. Feamster, “A comparative study of network traffic representations for novelty detection,” arXiv preprint arXiv:2006.16993, 2020
-
[39]
Online website fingerprinting: Evaluating website fingerprinting attacks on tor in the real world,
G. Cherubin, R. Jansen, and C. Troncoso, “Online website fingerprinting: Evaluating website fingerprinting attacks on tor in the real world,” in 31st USENIX Security Symposium (USENIX Security 22) . Boston, MA: USENIX Association, Aug. 2022, pp. 753–770. [Online]. Available: ht tps://www.usenix.org/conference/usenixsecurity22/presentation/cherubin
work page 2022
-
[40]
X. Deng, Q. Li, and K. Xu, “Robust and reliable early-stage website fingerprinting attacks via spatial-temporal distribution analysis,” in Pro- ceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1997–2011
work page 2024
-
[41]
Enabling qoe learning and prediction of webrtc video communication in wifi networks,
S. Yan, Y . Guo, Y . Chen, F. Xie, C. Yu, and Y . Liu, “Enabling qoe learning and prediction of webrtc video communication in wifi networks,” 2015. [Online]. Available: https://api.semanticscholar.org/Co rpusID:30220021
work page 2015
-
[42]
Characterization of encrypted and vpn traffic using time-related features,
G. Draper-Gil, A. H. Lashkari, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of encrypted and vpn traffic using time-related features,” in Proceedings of the 2nd International Conference on Information Systems Security and Privacy , 2016, pp. 407– 414, https://doi.org/10.5220/0005740704070414. [Online]. Available: https://app.dimensions.ai/details...
-
[43]
Estimating webrtc video qoe metrics without using application headers,
T. Sharma, T. Mangla, A. Gupta, J. Jiang, and N. Feamster, “Estimating webrtc video qoe metrics without using application headers,” in Pro- ceedings of the 2023 ACM on Internet Measurement Conference , 2023, pp. 485–500
work page 2023
-
[44]
Utmobilenettraffic2021: A labeled public network traffic dataset,
Y . Heng, V . Chandrasekhar, and J. G. Andrews, “Utmobilenettraffic2021: A labeled public network traffic dataset,” IEEE Networking Letters , vol. 3, no. 3, pp. 156–160, 2021
work page 2021
-
[45]
Deepcorr: Strong flow correlation attacks on tor using deep learning,
M. Nasr, A. Bahramali, and A. Houmansadr, “Deepcorr: Strong flow correlation attacks on tor using deep learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS) . ACM, 2018, pp. 1962–1976. [Online]. Available: https://doi.org/10.1145/3243734.3243824
-
[46]
Flow correlation attacks on Tor onion service sessions with sliding subset sum,
D. Lopes, J.-D. Dong, D. Castro, P. Medeiros, D. Barradas, B. Portela, J. Vinagre, B. Ferreira, N. Christin, and N. Santos, “Flow correlation attacks on Tor onion service sessions with sliding subset sum,” in Proceedings of the 32nd Network and Distributed System Security Symposium (NDSS) , San Diego, CA, 2024. [Online]. Available: https://www.ndss-sympos...
work page 2024
-
[47]
The duster attack: Tor onion service attribution based on flow watermarking with track hiding,
A. Iacovazzi, D. Frassinelli, and Y . Elovici, “The duster attack: Tor onion service attribution based on flow watermarking with track hiding,” in Proceedings of the 22nd International Symposium on Research in Attacks, Intrusions and Defenses (RAID) . USENIX Association, 2019, pp. 213–225. [Online]. Available: https://www.usenix.org/conference/ra id2019/p...
work page 2019
-
[48]
T. Brekne, A. ˚Arnes, and A. Øslebø, “Anonymization of ip traffic mon- itoring data: Attacks on two prefix-preserving anonymization schemes and some proposed remedies,” in International Workshop on Privacy Enhancing Technologies. Springer, 2005, pp. 179–196
work page 2005
-
[49]
Circumventing ip-address pseudonymization
T. Brekne and A. ˚Arnes, “Circumventing ip-address pseudonymization.” in Communications and Computer Networks , 2005, pp. 43–48
work page 2005
-
[50]
Browser finger- printing from coarse traffic summaries: Techniques and implications,
T.-F. Yen, X. Huang, F. Monrose, and M. K. Reiter, “Browser finger- printing from coarse traffic summaries: Techniques and implications,” in Detection of Intrusions and Malware, and Vulnerability Assessment: 6th International Conference, DIMVA 2009, Como, Italy, July 9-10, 2009. Proceedings 6. Springer, 2009, pp. 157–175
work page 2009
-
[51]
The risk-utility tradeoff for ip address truncation,
M. Burkhart, D. Brauckhoff, M. May, and E. Boschi, “The risk-utility tradeoff for ip address truncation,” in Proceedings of the 1st ACM workshop on Network data anonymization , 2008, pp. 23–30
work page 2008
-
[52]
Practical application of deep generative models to network traces and use cases,
Y . Yin, “Practical application of deep generative models to network traces and use cases,” Ph.D. dissertation, 2024, copyright - Database copyright ProQuest LLC; ProQuest does not claim copyright in the individual underlying works; Last updated - 2024-11-01. [Online]. Available: https://login.ezproxy.princeton.edu/login?url=https: //www.proquest.com/diss...
-
[53]
Work-in-progress: Cangen: Practical synthetic can traces generation using deep generative models,
Y . Yin, J. G. Merchan, P. Pappachan, and V . Sekar, “Work-in-progress: Cangen: Practical synthetic can traces generation using deep generative models,” in 2024 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), 2024, pp. 1–9
work page 2024
-
[54]
The design and operation of CloudLab,
D. Duplyakin, R. Ricci, A. Maricq, G. Wong, J. Duerig, E. Eide, L. Stoller, M. Hibler, D. Johnson, K. Webb, A. Akella, K. Wang, G. Ricart, L. Landweber, C. Elliott, M. Zink, E. Cecchet, S. Kar, and P. Mishra, “The design and operation of CloudLab,” in 2019 USENIX Annual Technical Conference (USENIX ATC 19) . Renton, W A: USENIX Association, Jul. 2019, pp....
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.