Time-Scale Coupling Between States and Parameters in Recurrent Neural Networks
Pith reviewed 2026-05-18 22:52 UTC · model grok-4.3
The pith
Gating in RNNs induces lag-dependent effective learning rates by coupling state time-scales to gradient updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Gating mechanisms induce lag-dependent and direction-dependent effective learning rates, arising from a coupling between state-space time-scales parametrized by the gates and parameter-space dynamics during gradient descent. Exact Jacobians for leaky-integrator and gated RNNs, combined with a first-order expansion, make explicit how constant, scalar, and multi-dimensional gates reshape gradient propagation, modulate effective step sizes, and introduce anisotropy. Gates thereby act as data-driven preconditioners with formal connections to learning-rate schedules, momentum, and methods such as Adam. Empirical simulations confirm that gates produce the predicted lag-dependent rates and low-rank
What carries the argument
Exact Jacobians of leaky-integrator and gated RNNs under first-order expansion, which reveal how gates modulate gradient propagation and effective step sizes.
If this is right
- Gates function simultaneously as information filters and as preconditioners that align state-space transport with loss-relevant directions.
- Gating and optimizer-driven adaptivity address complementary parts of credit assignment.
- The induced anisotropy matches or exceeds the structure produced by Adam across several tasks.
- The coupling supplies a unified view of why gated RNNs remain trainable on long sequences.
Where Pith is reading between the lines
- Design of new gate functions could target specific anisotropy patterns to accelerate convergence on particular sequence lengths.
- Similar state-parameter couplings may appear in attention-based models and could be diagnosed with the same Jacobian approach.
- The framework suggests experiments that vary gate dimensionality while holding optimizer fixed to isolate the contribution of each to final performance.
Load-bearing premise
The first-order expansion applied to the exact Jacobians sufficiently captures how gates reshape gradient propagation and introduce anisotropy.
What would settle it
Measuring whether the effective learning rates observed in gradient updates of gated RNNs on sequence tasks vary systematically with lag and direction, matching the anisotropy predicted by the Jacobian analysis but absent in non-gated models.
Figures









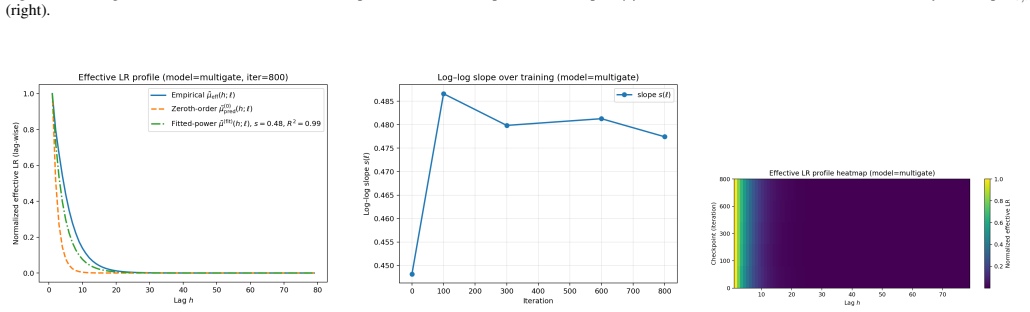





read the original abstract
We show that gating mechanisms in recurrent neural networks (RNNs) induce lag-dependent and direction-dependent effective learning rates, even when training uses a fixed, global step size. This behavior arises from a coupling between state-space time-scales (parametrized by the gates) and parameter-space dynamics during gradient descent. By deriving exact Jacobians for leaky-integrator and gated RNNs and applying a first-order expansion, we make explicit how constant, scalar, and multi-dimensional gates reshape gradient propagation, modulate effective step sizes, and introduce anisotropy in parameter updates. These findings reveal that gates act not only as filters of information flow, but also as data-driven preconditioners of optimization, with formal connections to learning-rate schedules, momentum, and adaptive methods such as Adam. Empirical simulations corroborate these predictions: across several sequence tasks, gates produce lag-dependent effective learning rates and concentrate gradient flow into low-dimensional subspaces, matching or exceeding the anisotropic structure induced by Adam. Notably, gating and optimizer-driven adaptivity shape complementary aspects of credit assignment: gates align state-space transport with loss-relevant directions, while optimizers rescale parameter-space updates. Overall, this work provides a unified dynamical systems perspective on how gating couples state evolution with parameter updates, clarifying why gated architectures achieve robust trainability in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that gating mechanisms in RNNs induce lag-dependent and direction-dependent effective learning rates during gradient descent with a fixed global step size. This arises from coupling between state-space time-scales (parametrized by gates) and parameter-space dynamics. The authors derive exact Jacobians for leaky-integrator and gated RNNs, apply a first-order expansion to show how gates reshape gradient propagation and introduce anisotropy, draw formal connections to learning-rate schedules/momentum/Adam, and corroborate via empirical simulations on sequence tasks where gates concentrate gradient flow into low-dimensional subspaces.
Significance. If the central derivations hold without uncontrolled approximation error, the work supplies a dynamical-systems account of why gated RNNs train robustly, framing gates as data-driven preconditioners that align state transport with loss-relevant directions while optimizers handle parameter rescaling. The explicit links to adaptive methods and the empirical match to Adam's anisotropy are potentially useful for understanding credit assignment in recurrent models.
major comments (1)
- [Jacobian derivation and first-order expansion] The first-order expansion of the Jacobians (described in the abstract and the derivation sections) is load-bearing for the lag- and direction-dependent effective learning-rate claims. In recurrent unrolling the total gradient is a product of Jacobians over many steps; when the spectral radius is near unity or gate values vary, higher-order terms in the expansion can accumulate and may not be negligible relative to the retained linear term. The manuscript should either bound the remainder or demonstrate that the anisotropy and preconditioning conclusions survive a multi-step analysis.
minor comments (1)
- [Empirical simulations] The empirical section should report the precise sequence tasks, the method used to extract effective learning rates from simulations, and any controls for post-hoc gate-value selection.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential value of the dynamical-systems framing of gating as a preconditioner. We address the single major comment below and will incorporate revisions to strengthen the multi-step analysis.
read point-by-point responses
-
Referee: The first-order expansion of the Jacobians (described in the abstract and the derivation sections) is load-bearing for the lag- and direction-dependent effective learning-rate claims. In recurrent unrolling the total gradient is a product of Jacobians over many steps; when the spectral radius is near unity or gate values vary, higher-order terms in the expansion can accumulate and may not be negligible relative to the retained linear term. The manuscript should either bound the remainder or demonstrate that the anisotropy and preconditioning conclusions survive a multi-step analysis.
Authors: We agree that the accumulation of higher-order terms in the product of Jacobians over many steps is a valid concern when the spectral radius approaches unity. The first-order expansion is applied locally to each Jacobian to derive an interpretable expression for the leading effect of gates on per-step gradient scaling and anisotropy; the exact (non-expanded) Jacobians are used for all empirical gradient computations. To address the referee's point directly, we will add a new subsection that (1) provides an explicit bound on the remainder for the multi-step product under the assumption of slowly varying gates (a regime observed in trained models) and (2) reports numerical comparisons of the first-order prediction versus the full unrolled gradient for sequence lengths up to several hundred steps. These additions will show that the reported lag- and direction-dependent effects remain dominant. The core claims are therefore unchanged, but the manuscript will be revised to include this supporting analysis. revision: yes
Circularity Check
Derivation of Jacobians and first-order expansion from RNN equations is self-contained with no circular reduction
full rationale
The paper derives exact Jacobians for leaky-integrator and gated RNNs directly from their defining differential or discrete equations and applies a first-order expansion to analyze lag-dependent and direction-dependent effective learning rates. This is a forward mathematical analysis of gradient propagation under the model dynamics, without any parameter fitting to subsets of data followed by prediction of related quantities, without self-definitional loops, and without load-bearing reliance on self-citations for uniqueness theorems or ansatzes. The abstract and reader's summary confirm the steps start from the RNN state equations themselves, rendering the claimed coupling between state time-scales and parameter updates a direct consequence rather than a reconstruction of inputs. No evidence of the enumerated circularity patterns appears in the provided derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leaky-integrator and gated RNNs follow their standard state-update equations as commonly defined in the literature.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By deriving exact Jacobians for leaky-integrator and gated RNNs and applying a first-order expansion, we make explicit how constant, scalar, and multi-dimensional gates reshape gradient propagation, modulate effective step sizes, and introduce anisotropy in parameter updates.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the effective learning rate reads: μ*_{t,k} = μ α^{t-k} + (perturbative correction terms)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the difficulty of training recurrent neural networks,
R. Pascanu, T. Mikolov, and Y . Bengio, “On the difficulty of training recurrent neural networks,” in Proceedings of the 30th International Conference on Machine Learning, vol. 28, Atlanta, Georgia, USA, 2013, pp. 1310–1318
work page 2013
-
[2]
Recurrent neural networks: vanishing and exploding gradients are not the end of the story,
N. Zucchet and A. Orvieto, “Recurrent neural networks: vanishing and exploding gradients are not the end of the story,” Advances in Neural Information Processing Systems , vol. 37, pp. 139 402–139 443, 2024
work page 2024
-
[3]
A. Ceni, “Random orthogonal additive filters: A solution to the van- ishing/exploding gradient of deep neural networks,” IEEE Transactions on Neural Networks and Learning Systems , vol. 36, no. 6, pp. 10 794– 10 807, 2025
work page 2025
-
[4]
Efficiently Modeling Long Sequences with Structured State Spaces
A. Gu, K. Goel, and C. Ré, “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Combining recurrent, convolutional, and continuous-time models with linear state space layers,
A. Gu, I. Johnson, K. Goel, K. K. Saab, T. Dao, A. Rudra, and C. Ré, “Combining recurrent, convolutional, and continuous-time models with linear state space layers,” in Thirty-Fifth Conference on Neural Infor- mation Processing Systems , 2021
work page 2021
-
[6]
The- oretical foundations of deep selective state-space models,
N. Muca Cirone, A. Orvieto, B. Walker, C. Salvi, and T. Lyons, “The- oretical foundations of deep selective state-space models,” Advances in Neural Information Processing Systems , vol. 37, pp. 127 226–127 272, 2024
work page 2024
-
[7]
Wide neural networks of any depth evolve as linear models under gradient descent,
J. Lee, L. Xiao, S. Schoenholz, Y . Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington, “Wide neural networks of any depth evolve as linear models under gradient descent,” Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[8]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
A. M. Saxe, J. L. McClelland, and S. Ganguli, “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks,” arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[9]
Orthogonal recurrent neural networks with scaled Cayley transform,
K. Helfrich, D. Willmott, and Q. Ye, “Orthogonal recurrent neural networks with scaled Cayley transform,” in Proceedings of the 35th International Conference on Machine Learning , ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1969–1978
work page 2018
-
[10]
Efficient or- thogonal parametrisation of recurrent neural networks using householder reflections,
Z. Mhammedi, A. Hellicar, A. Rahman, and J. Bailey, “Efficient or- thogonal parametrisation of recurrent neural networks using householder reflections,” in Proceedings of the 34th International Conference on Machine Learning, 2017, p. 2401–2409
work page 2017
-
[11]
Unitary evolution recurrent neural networks,
M. Arjovsky, A. Shah, and Y . Bengio, “Unitary evolution recurrent neural networks,” in International Conference on Machine Learning , New York, USA, June 2016, pp. 1120–1128
work page 2016
-
[12]
Full- capacity unitary recurrent neural networks,
S. Wisdom, T. Powers, J. Hershey, J. Le Roux, and L. Atlas, “Full- capacity unitary recurrent neural networks,” in Advances in Neural In- formation Processing Systems, D. D. Lee, M. Sugiyama, U. V . Luxburg, I. Guyon, and R. Garnett, Eds. Barcelona, Spain: Curran Associates, Inc., Dec. 2016, pp. 4880–4888
work page 2016
-
[13]
On orthogonality and learning recurrent networks with long term dependencies,
E. V orontsov, C. Trabelsi, S. Kadoury, and C. Pal, “On orthogonality and learning recurrent networks with long term dependencies,” in Proceedings of the 34th International Conference on Machine Learning , 2017, p. 3570–3578
work page 2017
-
[14]
Lipschitz recurrent neural networks,
N. B. Erichson, O. Azencot, A. Queiruga, L. Hodgkinson, and M. W. Mahoney, “Lipschitz recurrent neural networks,” arXiv preprint arXiv:2006.12070, 2021
-
[15]
G. Kerg, K. Goyette, M. P. Touzel, G. Gidel, E. V orontsov, Y . Bengio, and G. Lajoie, “Non-normal recurrent neural network (nnrnn): learning long time dependencies while improving expressivity with transient dynamics,” arXiv preprint arXiv:1905.12080 , 2019
-
[16]
A. Kag, Z. Zhang, and V . Saligrama, “RNNs incrementally evolving on an equilibrium manifold: A panacea for vanishing and exploding gradients?” in International Conference on Learning Representations , 2020
work page 2020
-
[17]
AntisymmetricRNN: A dynamical system view on recurrent neural networks,
B. Chang, M. Chen, E. Haber, and E. H. Chi, “AntisymmetricRNN: A dynamical system view on recurrent neural networks,” in International Conference on Learning Representations , 2019. [Online]. Available: https://openreview.net/forum?id=ryxepo0cFX
work page 2019
-
[18]
T. K. Rusch and S. Mishra, “Coupled oscillatory recurrent neural network (cornn): An accurate and (gradient) stable architecture for learning long time dependencies,” ICLR, 2021
work page 2021
-
[19]
Long expressive memory for sequence modeling,
T. K. Rusch, S. Mishra, N. B. Erichson, and M. W. Mahoney, “Long expressive memory for sequence modeling,” arXiv preprint arXiv:2110.04744, 2021
-
[20]
J. Koutnik, K. Greff, F. Gomez, and J. Schmidhuber, “A clockwork RNN,” in International Conference on Machine Learning, vol. 32, no. 2, 2014, pp. 1863–1871
work page 2014
-
[21]
M. Chen, J. Pennington, and S. Schoenholz, “Dynamical isometry and a mean field theory of RNNs: Gating enables signal propagation in recurrent neural networks,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. Stockholmsmässan, Stockholm Sweden: PMLR...
work page 2018
-
[22]
Dynamical Isometry and a Mean Field Theory of LSTMs and GRUs
D. Gilboa, B. Chang, M. Chen, G. Yang, S. S. Schoenholz, E. H. Chi, and J. Pennington, “Dynamical isometry and a mean field theory of lstms and grus,” arXiv preprint arXiv:1901.08987 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[23]
Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice,
J. Pennington, S. Schoenholz, and S. Ganguli, “Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice,” in Advances in Neural Information Processing Systems , 2017, pp. 4785– 4795
work page 2017
-
[24]
Gating revisited: Deep multi-layer rnns that can be trained,
M. O. Turkoglu, S. D’Aronco, J. D. Wegner, and K. Schindler, “Gating revisited: Deep multi-layer rnns that can be trained,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 44, no. 8, pp. 4081– 4092, 2022
work page 2022
-
[25]
The unreasonable effectiveness of the forget gate
J. Van Der Westhuizen and J. Lasenby, “The unreasonable effectiveness of the forget gate,” arXiv preprint arXiv:1804.04849 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Theory of gating in recurrent neural networks,
A. Krishnamurthy, C. Gehring, D. K. Misra, and C. Zhang, “Theory of gating in recurrent neural networks,” Journal of Machine Learning Research, vol. 23, no. 157, pp. 1–39, 2022
work page 2022
-
[27]
Gates create slow modes in recurrent neural networks,
O. Can, K. Kapanova, and A. Søgaard, “Gates create slow modes in recurrent neural networks,” in International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[28]
Adaptive time scales in recurrent neural networks,
R. Quax, D. Kandhai, and P. M. A. Sloot, “Adaptive time scales in recurrent neural networks,” Scientific Reports, vol. 10, no. 1, p. 7442, 2020
work page 2020
-
[29]
Can recurrent neural networks warp time?
C. Tallec and Y . Ollivier, “Can recurrent neural networks warp time?” in International Conference on Learning Representations , 2018. [Online]. Available: https://openreview.net/forum?id=SJcKhk-Ab
work page 2018
-
[30]
Optimization and applications of echo state networks with leaky-integrator neurons,
H. Jaeger, M. Lukoševi ˇcius, D. Popovici, and U. Siewert, “Optimization and applications of echo state networks with leaky-integrator neurons,” Neural Networks, vol. 20, no. 3, pp. 335–352, 2007
work page 2007
-
[31]
Backpropagation through time: what it does and how to do it,
P. J. Werbos, “Backpropagation through time: what it does and how to do it,” Proceedings of the IEEE , vol. 78, no. 10, pp. 1550–1560, 1990
work page 1990
-
[32]
An overview of gradient descent optimization algorithms
S. Ruder, “An overview of gradient descent optimization algorithms,” arXiv preprint arXiv:1609.04747 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[34]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, Ł. Kaiser, and I. Polo- sukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017
work page 2017
-
[36]
N. J. Higham, Functions of Matrices: Theory and Computation. SIAM, 2008
work page 2008
-
[37]
S. G. Krantz and H. R. Parks, The Implicit Function Theorem: History, Theory, and Applications . Boston, MA: Birkhäuser, 2003
work page 2003
-
[38]
Adam: A Method for Stochastic Optimization
D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 , 2014. 11 SUPPLEMENTARY MATERIAL A. Matrix product expansion via the Fréchet derivative formulation We derive here the first-order expansion of a product of matrices with structured perturbations, starting from the product rule for the Fréchet derivative (Th...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Since the space is finite-dimensional, all norms are equivalent
Fréchet differentiability and the first-order expansion: Let Cn×n denote the finite-dimensional vector space of complex n × n matrices equipped with a matrix norm (specifically, the operator 2-norm, unless otherwise stated). Since the space is finite-dimensional, all norms are equivalent. Definition VIII.1 (Fréchet differentiability [37], [36]) . Let f : ...
-
[40]
The direction of perturbation E in (57) is now the tuple E ≡ (B1, B2,
Matrix products with structured perturbations: We now consider a product of n factors, each with a perturbation proportional to a scalar parameter ε: F (ε) = nY j=1 Aj + εBj , (59) where: • Aj ∈ Cd×d is the unperturbed factor at position j, • Bj ∈ Cd×d is the perturbation at position j, • ε ∈ R controls the magnitude of all perturbations. The direction of...
-
[41]
We now apply the product rule (58) to Fn by setting g(ε) = Fn−1(ε), h (ε) = An + εBn
Recursive application of the product rule: For any k ≤ n, ϵ > 0, define the product Fk(ε) := kY j=1 Aj + εBj , so that Fn(ε) = Fn−1(ε) An + εBn . We now apply the product rule (58) to Fn by setting g(ε) = Fn−1(ε), h (ε) = An + εBn. At ε = 0 we have: g(0) = Fn−1(0) = A1A2 . . . An−1, h (0) = An, L h(0, E) = Bn. The product rule gives: LFn(0, E) = Lg(0, E) ...
-
[42]
First-order expansion: Applying the first-order Taylor expansion (57) to (59) gives F (ε) = F (0) + ε LF (0, E) + O(ε2), (65) where F (0) =Qn j=1 Aj and LF (0, E) is given by (61). Substituting, we obtain the explicit first-order expansion: F (ε) = nY j=1 Aj | {z } dominant dynamics + ε nX m=1 nY j=m+1 Aj Bm m−1Y j=1 Aj | {z } pert...
-
[43]
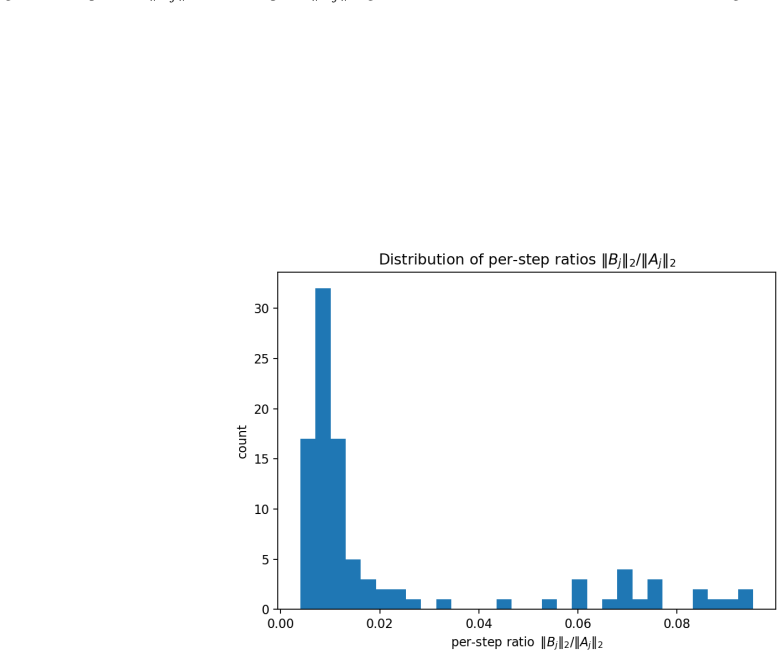
Simulations supporting the validity of the first-order approximation: The first-order expansion (66) is accurate when all ∥Bj∥ are small compared to ∥Aj∥ (in operator norm), so that the accumulated O(ε2) terms remain negligible. In the main text, Bj represents gate-induced corrections, which are typically low-norm compared to the dominant dynamics in Aj. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.