HeteroRAG: A Heterogeneous Retrieval-Augmented Generation Framework for Medical Vision Language Tasks
Pith reviewed 2026-05-18 22:46 UTC · model grok-4.3
The pith
HeteroRAG lifts factual accuracy in medical vision-language models by retrieving from both image reports and varied text sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
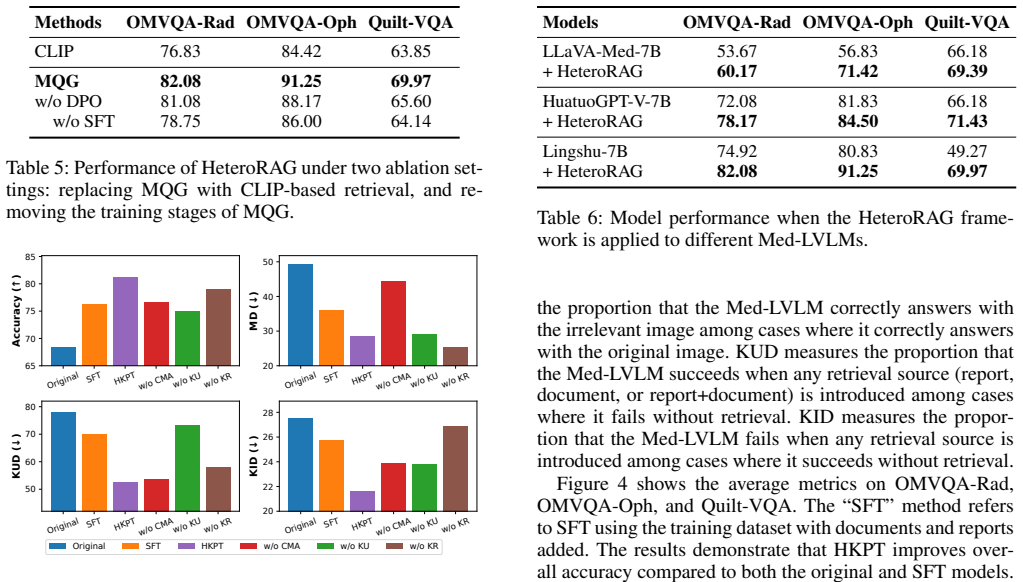
HeteroRAG enhances Med-LVLMs through heterogeneous knowledge sources by constructing MedAtlas with extensive multimodal report repositories and diverse text corpora, introducing Modality-specific CLIPs for effective report retrieval and a Multi-corpora Query Generator for tailoring queries, then performing Heterogeneous Knowledge Preference Tuning to achieve cross-modality and multi-source knowledge alignment.
What carries the argument
HeteroRAG, which combines modality-specific retrieval from medical reports with tailored query generation across text corpora, followed by preference tuning on the combined knowledge to enforce alignment.
If this is right
- Med-LVLMs show higher factual accuracy on image interpretation and clinical question-answering tasks.
- The gains appear across 11 datasets spanning three imaging modalities.
- The same retrieval-plus-tuning pattern reduces credibility problems that currently affect clinical decision support tools.
Where Pith is reading between the lines
- If retrieved sources often contradict each other, the preference tuning step may require an explicit conflict-detection layer to preserve the reported gains.
- The heterogeneous-source design could be tested on non-medical domains that also combine image-like records with unstructured text, such as legal case files paired with statutes.
- Building domain-specific atlases like MedAtlas may prove more scalable than enlarging model size alone for reliability improvements.
Load-bearing premise
The assumption that retrieved content from heterogeneous report and text sources will be relevant and non-conflicting enough to improve rather than degrade the model's factual outputs when used in the preference tuning stage.
What would settle it
Test the tuned model on a medical benchmark where deliberately chosen conflicting reports are inserted into the retrieval pool and measure whether factual accuracy rises or falls relative to a no-retrieval baseline.
Figures




read the original abstract
Medical large vision-language Models (Med-LVLMs) have shown promise in clinical applications but suffer from factual inaccuracies and unreliable outputs, posing risks in real-world diagnostics. While RAG has emerged as a potential solution, current medical multimodal RAG systems are unable to perform effective retrieval across heterogeneous sources. The irrelevance of retrieved reports undermines the factuality of analysis, while insufficient knowledge affects the credibility of clinical decision-making. To bridge the research gap, we construct MedAtlas, which includes extensive multimodal report repositories and diverse text corpora. Based on it, we present HeteroRAG, a novel framework that enhances Med-LVLMs through heterogeneous knowledge sources. The framework introduces Modality-specific CLIPs for effective report retrieval and a Multi-corpora Query Generator for tailoring queries to diverse corpora. Incorporating knowledge from such multifaceted sources, Heterogeneous Knowledge Preference Tuning is performed to achieve cross-modality and multi-source knowledge alignment. Extensive experiments across 11 datasets and 3 modalities demonstrate that HeteroRAG achieves state-of-the-art performance in most medical vision language benchmarks, significantly improving factual accuracy and reliability of Med-LVLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HeteroRAG, a heterogeneous retrieval-augmented generation framework for medical vision-language models. It constructs MedAtlas containing multimodal report repositories and diverse text corpora, introduces Modality-specific CLIPs for report retrieval and a Multi-corpora Query Generator for tailoring queries, and performs Heterogeneous Knowledge Preference Tuning to align cross-modality and multi-source knowledge. Extensive experiments across 11 datasets and 3 modalities are reported to achieve state-of-the-art performance in most medical vision-language benchmarks while improving factual accuracy and reliability of Med-LVLMs.
Significance. If the central results hold, the work could meaningfully advance reliable medical VLMs by showing how heterogeneous sources can be leveraged for better factuality, addressing a key limitation in clinical applications. The construction of MedAtlas and the scale of evaluation across 11 datasets and multiple modalities are clear strengths that support reproducibility and broad applicability.
major comments (1)
- [Heterogeneous Knowledge Preference Tuning] Heterogeneous Knowledge Preference Tuning section: no explicit mechanism (conflict detection, source weighting, or negative sampling) is described for resolving contradictory information that can arise when retrieving from heterogeneous report and text sources. This is load-bearing for the central claim, as a single conflicting medical report can introduce hallucinations that standard accuracy metrics may not penalize; without ablations on conflict rate or controlled contradiction injection, gains on the 11 datasets cannot be confidently attributed to the heterogeneous design rather than retrieval volume or generic tuning.
minor comments (2)
- [Abstract] Abstract: states performance gains and SOTA results but provides no quantitative metrics, baseline details, or error analysis, weakening the summary's informativeness.
- [Experiments] Experiments section: more detail on baseline selection criteria and whether baselines had equivalent retrieval access would improve fairness assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comment point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Heterogeneous Knowledge Preference Tuning] Heterogeneous Knowledge Preference Tuning section: no explicit mechanism (conflict detection, source weighting, or negative sampling) is described for resolving contradictory information that can arise when retrieving from heterogeneous report and text sources. This is load-bearing for the central claim, as a single conflicting medical report can introduce hallucinations that standard accuracy metrics may not penalize; without ablations on conflict rate or controlled contradiction injection, gains on the 11 datasets cannot be confidently attributed to the heterogeneous design rather than retrieval volume or generic tuning.
Authors: We agree that the manuscript does not currently provide an explicit description of mechanisms such as conflict detection or source weighting within the Heterogeneous Knowledge Preference Tuning section. The preference tuning is designed to align cross-modality and multi-source knowledge through constructed preference pairs that prioritize factual consistency, but this process is not detailed with respect to contradiction handling. In the revised manuscript we will expand the section to clarify how the tuning objective implicitly mitigates conflicts by favoring reliable alignments across sources. We will also add controlled experiments that inject contradictions at varying rates into the retrieved knowledge and report the resulting performance to better attribute gains to the heterogeneous design. revision: yes
Circularity Check
No circularity: framework is architectural and empirical with external benchmarks
full rationale
The paper presents HeteroRAG as a system-level framework built on a newly constructed MedAtlas repository, modality-specific CLIP models for report retrieval, a multi-corpora query generator, and heterogeneous knowledge preference tuning. No equations, fitted parameters, or derivations appear that reduce by construction to the paper's own inputs or prior self-citations. Performance is evaluated on 11 external datasets across modalities, providing independent empirical grounding rather than self-referential claims. The approach is therefore self-contained against external validation and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MedAtlas
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Heterogeneous Knowledge Preference Tuning (HKPT) ... cross-modality alignment ... multi-source knowledge alignment ... DPO loss on preferred/dispreferred QA pairs
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Modality-specific CLIPs ... contrastive learning on image-text pairs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
He, S.; Nie, Y .; Chen, Z.; Cai, Z.; Wang, H.; Yang, S.; and Chen, H
AAAI Press. He, S.; Nie, Y .; Chen, Z.; Cai, Z.; Wang, H.; Yang, S.; and Chen, H. 2024. MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning. CoRR, abs/2404.15127. He, X.; Zhang, Y .; Mou, L.; Xing, E. P.; and Xie, P. 2020. PathVQA: 30000+ Questions for Medical Visual Question Answering. CoRR, abs/2003.10286. Hu, E. J.; S...
-
[2]
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 , 22170– 22183. IEEE. Huang, J.-H.; Yang, C.-H. H.; Liu, F.; Tian, M.; Liu, Y .-C.; Wu, T.-W.; Lin, I.; Wang, K.; Morikawa, H.; Chang, H.; et al
work page 2024
-
[3]
Deepopht: medical report generation for retinal im- ages via deep models and visual explanation. In Proceed- ings of the IEEE/CVF winter conference on applications of computer vision, 2442–2452. Ikezogwo, W.; Seyfioglu, S.; Ghezloo, F.; Geva, D.; Sheikh Mohammed, F.; Anand, P. K.; Krishna, R.; and Shapiro, L. 2023. Quilt-1m: One million image-text pairs f...
-
[4]
Slake: A Semantically-Labeled Knowledge-Enhanced Dataset For Medical Visual Question Answering. In 18th IEEE International Symposium on Biomedical Imaging, ISBI 2021, Nice, France, April 13-16, 2021 , 1650–1654. IEEE. Luo, Y .; Shi, M.; Khan, M. O.; Afzal, M. M.; Huang, H.; Yuan, S.; Tian, Y .; Song, L.; Kouhana, A.; Elze, T.; et al
work page 2021
-
[5]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12289–12301
FairCLIP: Harnessing fairness in vision-language learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12289–12301. NCBI. 2025. PubMed Baseline Data. https://ftp.ncbi.nlm. nih.gov/pubmed/baseline/. Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W. 2002. Bleu: a Method for Automatic Evaluation of Machine Transla- tio...
work page 2025
-
[6]
PMLR. R¨uckert, J.; Bloch, L.; Br ¨ungel, R.; Idrissi-Yaghir, A.; Sch¨afer, H.; Schmidt, C. S.; Koitka, S.; Pelka, O.; Abacha, A. B.; G. Seco de Herrera, A.; et al. 2024. ROCOv2: Ra- diology objects in context version 2, an updated multimodal image dataset. Scientific Data, 11(1): 688. Sellergren, A.; Kazemzadeh, S.; Jaroensri, T.; Kiraly, A.; Traverse, M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In Wang, L.; Dou, Q.; Fletcher, P
Consistency-Preserving Visual Question Answering in Medical Imaging. In Wang, L.; Dou, Q.; Fletcher, P. T.; Speidel, S.; and Li, S., eds., Medical Image Computing and Computer Assisted Intervention - MICCAI 2022 - 25th In- ternational Conference, Singapore, September 18-22, 2022, Proceedings, Part VIII, volume 13438 of Lecture Notes in Computer Science, 3...
-
[8]
MKGF: A multi-modal knowledge graph based RAG framework to enhance LVLMs for Medical visual question answering. Neurocomputing, 635: 129999. Xia, P.; Zhu, K.; Li, H.; Wang, T.; Shi, W.; Wang, S.; Zhang, L.; Zou, J.; and Yao, H. 2025. MMed-RAG: Versatile Mul- timodal RAG System for Medical Vision Language Mod- els. In The Thirteenth International Conferenc...
work page 2025
-
[9]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Association for Computational Linguistics. Xu, W.; Chan, H. P.; Li, L.; Aljunied, M.; Yuan, R.; Wang, J.; Xiao, C.; Chen, G.; Liu, C.; Li, Z.; et al. 2025. Ling- shu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning. arXiv preprint arXiv:2506.07044. Yang, R.; Liu, H.; Marrese-Taylor, E.; Zeng, Q.; Ke, Y .; Li, W.; C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Medical document-retrieval methods are described as fol- lows: • MKGF (Wu et al
by introducing cross-modality alignment to ensure image utilization and proposing overall alignment to bet- ter incorporate external reports. Medical document-retrieval methods are described as fol- lows: • MKGF (Wu et al. 2025) uses a multimodal retriever to fetch knowledge graphs and supplement knowledge for LVLMs. We reproduce it using ModCLIP for imag...
work page 2025
-
[11]
for efficient fine-tuning. For the SFT process, its learning rate is set to 2e-4, the batch size is set to 64, and the number of epochs is 3. For the DPO process, its learning rate is set to 2e-5, the batch size is set to 64, and the number of epochs is set to 3. For the training of HKPT, the Med-LVLM is initialized from Lingshu-7B. We also use LoRA (Hu e...
work page 2022
-
[12]
Each corpus in # Corpus Description must have search queries constructed
-
[13]
Each corpus should have 6 queries, separated by ’;’
Please give the search queries following the format in # Query Format. Each corpus should have 6 queries, separated by ’;’
-
[14]
The queries generated for each corpus should exhibit diversity and be closely aligned with the specific information needs and characteristics of that corpus. Prompt C.4: Query Judging through Retrieved Doc- uments by the Expert Med-LVLM {question image} # Question (based on the image) {question text} # Gold Answer {gold} # Documents {documents} You are a ...
-
[15]
Please give the search queries following the format in # Query Format. For each corpus, if you think no information retrieval is needed, simply output an empty tag for that corpus, for example: <book></book>
-
[16]
The queries generated for each corpus should be closely aligned with the specific information needs and characteristics of that corpus
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.