Graph Concept Bottleneck Models
Pith reviewed 2026-05-18 21:57 UTC · model grok-4.3
The pith
Graph Concept Bottleneck Models capture correlations among concepts using latent graphs to improve classification and interventions while keeping interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GraphCBMs integrate latent concept graphs into Concept Bottleneck Models to model hidden correlations between concepts. This structure yields better image classification performance, richer concept-level interpretability, and stronger intervention results compared with standard CBMs that treat concepts as isolated.
What carries the argument
Latent concept graphs that encode the intrinsic correlations and influence relationships among concepts.
If this is right
- GraphCBMs achieve higher accuracy than standard CBMs on real-world image classification tasks.
- The models supply additional concept structure information that improves interpretability.
- Interventions become more effective because the graph accounts for how one concept change influences others.
- Performance stays stable when training methods or model architectures vary.
Where Pith is reading between the lines
- The same graph-construction step could be tested on tasks beyond images, such as medical diagnosis where symptoms are interdependent.
- If the approach generalizes, other intermediate-representation models might gain from explicit relationship graphs rather than assuming independence.
- Datasets with explicitly annotated concept correlations would provide a direct test of whether the graph component drives the reported gains.
Load-bearing premise
Concepts in these models possess an intrinsic structure in which they are correlated, so that changing one concept necessarily affects its related concepts.
What would settle it
An experiment in which removing the latent graph or forcing concepts to be independent produces no drop in intervention effectiveness or classification accuracy.
Figures




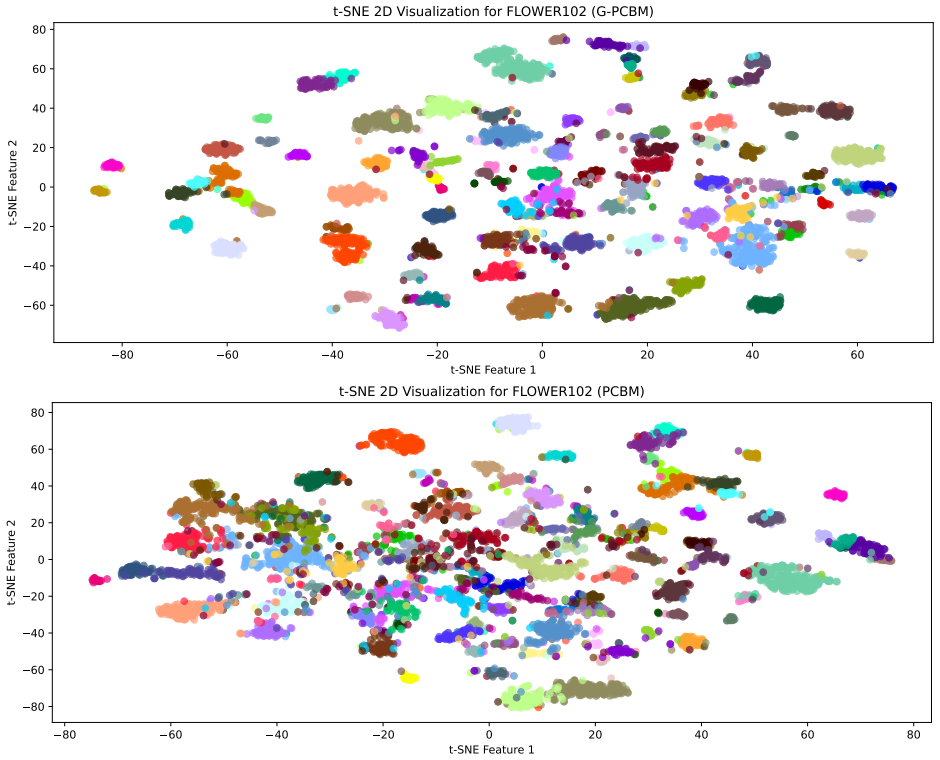
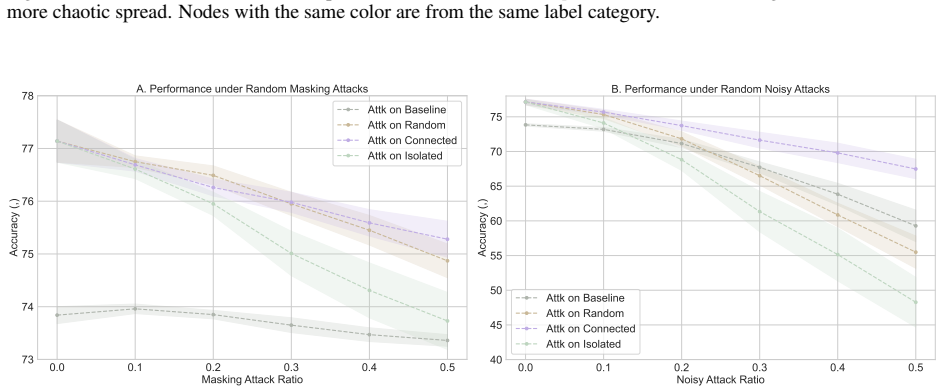







read the original abstract
Concept Bottleneck Models (CBMs) provide explicit interpretations for deep neural networks through concepts and allow intervention with concepts to adjust final predictions. Existing CBMs assume concepts are conditionally independent given labels and isolated from each other, ignoring the hidden relationships among concepts. However, the set of concepts in CBMs often has an intrinsic structure where concepts are generally correlated: changing one concept will inherently impact its related concepts. To mitigate this limitation, we propose GraphCBMs: a new variant of CBM that facilitates concept relationships by constructing latent concept graphs, which can be combined with CBMs to enhance model performance while retaining their interpretability. Our experiment results on real-world image classification tasks demonstrate Graph CBMs offer the following benefits: (1) superior in image classification tasks while providing more concept structure information for interpretability; (2) able to utilize latent concept graphs for more effective interventions; and (3) robust in performance across different training and architecture settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Graph Concept Bottleneck Models (GraphCBMs) as an extension of standard Concept Bottleneck Models. It constructs latent concept graphs to capture intrinsic correlations among concepts (which standard CBMs treat as conditionally independent), and claims that the resulting models achieve superior accuracy on image classification tasks, support more effective concept interventions, and remain robust across training regimes and architectures while preserving interpretability.
Significance. If the central claims hold after capacity-controlled validation, the work would meaningfully advance interpretable deep learning by adding an explicit relational inductive bias to concept bottlenecks. This could improve intervention reliability in safety-critical domains where concept dependencies are known to exist.
major comments (2)
- [Experiments] Experiments section (and associated tables/figures): the reported gains in classification accuracy and post-intervention performance are not accompanied by capacity-matched ablations. If the latent concept graph module increases parameter count relative to the baseline CBM, the observed improvements could be explained by added expressivity rather than by correctly modeling concept correlations. A direct comparison (e.g., baseline CBM augmented with an equivalent number of unstructured parameters) is required to substantiate the central claim that the graph structure itself drives the benefits.
- [Method] §3 (Method): the construction of the latent concept graph is described at a high level, but the paper does not specify how the graph edges or adjacency matrix are learned or regularized, nor whether the graph parameters are frozen during intervention experiments. This detail is load-bearing for the intervention-effectiveness claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'superior in image classification tasks' is vague; quantitative deltas, dataset names, and baseline comparisons should be stated explicitly.
- Notation: the distinction between the original CBM concept vector and the graph-augmented representation is not always clear in equations; consistent symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, agreeing where additional controls and clarifications are warranted, and outlining the revisions we will make.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and associated tables/figures): the reported gains in classification accuracy and post-intervention performance are not accompanied by capacity-matched ablations. If the latent concept graph module increases parameter count relative to the baseline CBM, the observed improvements could be explained by added expressivity rather than by correctly modeling concept correlations. A direct comparison (e.g., baseline CBM augmented with an equivalent number of unstructured parameters) is required to substantiate the central claim that the graph structure itself drives the benefits.
Authors: We agree that capacity-matched ablations are necessary to isolate the contribution of the graph structure from potential gains due to increased model capacity. In the revised manuscript we will add direct comparisons in which the baseline CBM is augmented with an equivalent number of unstructured parameters (for example by expanding hidden-layer dimensions or inserting additional fully-connected layers) to match the parameter count of the latent concept graph module. Updated tables and figures will report these results alongside the original experiments. revision: yes
-
Referee: [Method] §3 (Method): the construction of the latent concept graph is described at a high level, but the paper does not specify how the graph edges or adjacency matrix are learned or regularized, nor whether the graph parameters are frozen during intervention experiments. This detail is load-bearing for the intervention-effectiveness claim.
Authors: We acknowledge that the current description in §3 is high-level and omits explicit details on how the adjacency matrix and edges are learned or regularized, as well as the treatment of graph parameters during interventions. This information is important for reproducibility and for interpreting the intervention results. In the revised version we will expand §3 with a precise account of the graph-construction procedure, including the learning mechanism, any regularization terms, and whether graph parameters remain frozen during the intervention experiments. revision: yes
Circularity Check
No significant circularity in the proposed architectural extension or empirical claims
full rationale
The paper proposes GraphCBMs as an extension to standard Concept Bottleneck Models by adding latent concept graphs to capture correlations among concepts. This construction is motivated by a stated premise about intrinsic concept structure rather than derived from any equation or prior result within the paper. All claimed benefits—superior classification performance, more effective interventions, and robustness—are presented as outcomes of experiments on real-world image tasks, without any fitted parameters, predictions, or first-principles results that reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way in the provided text. The derivation chain is therefore self-contained as an empirical architectural proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concepts are generally correlated such that changing one inherently impacts related concepts.
invented entities (1)
-
Latent concept graphs
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the set of concepts in CBMs often has an intrinsic structure where concepts are generally correlated: changing one concept will inherently impact its related concepts... constructing latent concept graphs... GNN Message Passing... V^l_emb = σ( D̃^{-1/2} Ã^l D̃^{-1/2} [V^{l-1}_act ⊙ V^{l-1}_emb] )
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesize the existence of a unified, input-independent concept graph that encodes prior semantic knowledge... contrastive regularization term based on the normalized temperature-scaled cross-entropy loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
work page 2021
-
[3]
Mlp-mixer: An all-mlp architecture for vision
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. Advances in neural information processing systems, 34:24261–24272, 2021
work page 2021
-
[4]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[5]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human 9 Language Technologies, Vo...
work page 2019
-
[6]
Association for Computational Linguistics
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[8]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[9]
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017
work page 2017
-
[10]
Graph contrastive learning with augmentations
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. Advances in neural information processing systems, 33:5812–5823, 2020
work page 2020
-
[11]
Deep graph learning: Foundations, advances and applications
Yu Rong, Tingyang Xu, Junzhou Huang, Wenbing Huang, Hong Cheng, Yao Ma, Yiqi Wang, Tyler Derr, Lingfei Wu, and Tengfei Ma. Deep graph learning: Foundations, advances and applications. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3555–3556, 2020
work page 2020
-
[12]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International conference on machine learning, pages 5338–5348. PMLR, 2020
work page 2020
-
[13]
Neural representations for object perception: structure, category, and adaptive coding
Zoe Kourtzi and Charles E Connor. Neural representations for object perception: structure, category, and adaptive coding. Annual review of neuroscience, 34(1):45–67, 2011
work page 2011
-
[14]
Concept embedding models: Beyond the accuracy-explainability trade-off
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelan- gelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, Pietro Lio, and Mateja Jamnik. Concept embedding models: Beyond the accuracy-explainability trade-off. Advances in Neural Information Processing Systems, 35, 2022
work page 2022
-
[15]
Probabilistic concept bottleneck models
Eunji Kim, Dahuin Jung, Sangha Park, Siwon Kim, and Sungroh Yoon. Probabilistic concept bottleneck models. International conference on machine learning, 2023
work page 2023
-
[16]
Post-hoc concept bottleneck models
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[17]
Moshe Bar. Visual objects in context. Nature Reviews Neuroscience, 5(8):617–629, 2004
work page 2004
-
[18]
The role of context in object recognition
Aude Oliva and Antonio Torralba. The role of context in object recognition. Trends in cognitive sciences , 11(12):520–527, 2007
work page 2007
-
[19]
Addressing leakage in concept bottleneck models
Marton Havasi, Sonali Parbhoo, and Finale Doshi-Velez. Addressing leakage in concept bottleneck models. Advances in Neural Information Processing Systems, 35:23386–23397, 2022
work page 2022
-
[20]
Xinyue Xu, Yi Qin, Lu Mi, Hao Wang, and Xiaomeng Li. Energy-based concept bottleneck models: Unifying prediction, concept intervention, and probabilistic interpretations. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[21]
Tuomas Oikarinen, Subhro Das, Lam M. Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[22]
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19187–19197, 2023
work page 2023
-
[23]
Learning concise and descriptive attributes for visual recognition
An Yan, Yu Wang, Yiwu Zhong, Chengyu Dong, Zexue He, Yujie Lu, William Yang Wang, Jingbo Shang, and Julian McAuley. Learning concise and descriptive attributes for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3090–3100, October 2023
work page 2023
-
[24]
Learning graphs from data: A signal representation perspective
Xiaowen Dong, Dorina Thanou, Michael Rabbat, and Pascal Frossard. Learning graphs from data: A signal representation perspective. IEEE Signal Processing Magazine, 36(3):44–63, 2019
work page 2019
-
[25]
DAG-GNN: DAG structure learning with graph neural networks
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. DAG-GNN: DAG structure learning with graph neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 7154–7163. PMLR, 09–15 Jun 2019
work page 2019
-
[26]
Learning discrete structures for graph neural networks
Luca Franceschi, Mathias Niepert, Massimiliano Pontil, and Xiao He. Learning discrete structures for graph neural networks. In International conference on machine learning, pages 1972–1982. PMLR, 2019. 10
work page 1972
-
[27]
Neural relational inference for interacting systems
Thomas Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard Zemel. Neural relational inference for interacting systems. In International conference on machine learning, pages 2688–2697. PMLR, 2018
work page 2018
-
[28]
Discrete graph structure learning for forecasting multiple time series
Chao Shang, Jie Chen, and Jinbo Bi. Discrete graph structure learning for forecasting multiple time series. In International Conference on Learning Representations, 2020
work page 2020
-
[29]
Differentiable graph module (dgm) for graph convolutional networks
Anees Kazi, Luca Cosmo, Seyed-Ahmad Ahmadi, Nassir Navab, and Michael M Bronstein. Differentiable graph module (dgm) for graph convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1606–1617, 2022
work page 2022
-
[30]
Federated learning of models pre-trained on different features with consensus graphs
Tengfei Ma, Trong Nghia Hoang, and Jie Chen. Federated learning of models pre-trained on different features with consensus graphs. In Uncertainty in Artificial Intelligence, pages 1336–1346. PMLR, 2023
work page 2023
-
[31]
Augmentations in hypergraph contrastive learning: Fabricated and generative
Tianxin Wei, Yuning You, Tianlong Chen, Yang Shen, Jingrui He, and Zhangyang Wang. Augmentations in hypergraph contrastive learning: Fabricated and generative. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 1909–1922. Curran Associates, Inc., 2022
work page 1909
-
[32]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020
work page 2020
-
[33]
struc2vec: Learning node representations from structural identity
Leonardo FR Ribeiro, Pedro HP Saverese, and Daniel R Figueiredo. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 385–394, 2017
work page 2017
-
[34]
Fan-Yun Sun, Jordan Hoffman, Vikas Verma, and Jian Tang. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[35]
Graph contrastive learning with augmentations
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 5812–5823. Curran Associates, Inc., 2020
work page 2020
-
[36]
Multi-level contrastive learning framework for sequential recommendation
Ziyang Wang, Huoyu Liu, Wei Wei, Yue Hu, Xian-Ling Mao, Shaojian He, Rui Fang, and Dangyang Chen. Multi-level contrastive learning framework for sequential recommendation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM ’22, page 2098–2107, New York, NY , USA, 2022. Association for Computing Machinery
work page 2098
-
[37]
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International conference on machine learning, pages 9929–9939. PMLR, 2020
work page 2020
-
[38]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
work page 2011
-
[39]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In Indian Conference on Computer Vision, Graphics and Image Processing, Dec 2008
work page 2008
-
[40]
Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly
Yongqin Xian, Christoph H Lampert, Bernt Schiele, and Zeynep Akata. Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly. IEEE transactions on pattern analysis and machine intelligence, 41(9):2251–2265, 2018
work page 2018
-
[41]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[42]
Philipp Tschandl. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions, 2018
work page 2018
-
[43]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019
work page 2019
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine...
work page 2021
-
[45]
Learning to exploit temporal structure for biomedical vision-language processing
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. Learning to exploit temporal structure for biomedical vision-language processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15016–150...
work page 2023
-
[46]
Learning bottleneck concepts in image classification
Bowen Wang, Liangzhi Li, Yuta Nakashima, and Hajime Nagahara. Learning bottleneck concepts in image classification. In Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages 10962–10971, 2023
work page 2023
-
[47]
Panousis, Dino Ienco, and Diego Marcos
Konstantinos P. Panousis, Dino Ienco, and Diego Marcos. Sparse linear concept discovery models. In 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 2759–2763, 2023
work page 2023
-
[48]
Incremental residual concept bottleneck models
Chenming Shang, Shiji Zhou, Hengyuan Zhang, Xinzhe Ni, Yujiu Yang, and Yuwang Wang. Incremental residual concept bottleneck models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11030–11040, June 2024
work page 2024
-
[49]
Stochastic concept bottleneck models
Moritz Vandenhirtz, Sonia Laguna, Riˇcards Marcinkeviˇcs, and Julia E V ogt. Stochastic concept bottleneck models. In Thirty-eighth Conference on Neural Information Processing Systems, 2024
work page 2024
-
[50]
A closer look at the intervention procedure of concept bottleneck models
Sungbin Shin, Yohan Jo, Sungsoo Ahn, and Namhoon Lee. A closer look at the intervention procedure of concept bottleneck models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learni...
work page 2023
-
[51]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[52]
Linear explanations for individual neurons
Tuomas Oikarinen and Tsui-Wei Weng. Linear explanations for individual neurons. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 38639–3866...
work page 2024
-
[53]
Torchvision: Pytorch’s computer vision library.https://github
TorchVision maintainers and contributors. Torchvision: Pytorch’s computer vision library.https://github. com/pytorch/vision, 2016
work page 2016
-
[54]
Semantic-aware scene recognition
Alejandro López-Cifuentes, Marcos Escudero-Viñolo, Jesús Bescós, and Álvaro García-Martín. Semantic-aware scene recognition. Pattern Recognition, page 107256, 2020
work page 2020
-
[55]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. A Dataset Introduction • Caltech-UCSD Birds-200-2011, CUB [ 37]: CUB is the most widely-used dataset for fine-grained visual categorization task...
work page 2009
-
[56]
Heart failure can lead to pleural effusion (fluid in the pleural space), which may manifest as a "Pleural Other" abnormality. 18
-
[57]
Aortic aneurysm or dissection may affect surrounding pleural structures due to proximity, causing pleural thickening or effusions. Malignancies: Tumors in the mediastinum (e.g., lymphomas or metastatic disease) can enlarge the cardiomediastinum and simultaneously invade or affect the pleura, leading to pleural abnormalities. Infections and inflammatory co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.