Evaluating the Quality of the Quantified Uncertainty for (Re)Calibration of Data-Driven Regression Models
Pith reviewed 2026-05-18 20:43 UTC · model grok-4.3
The pith
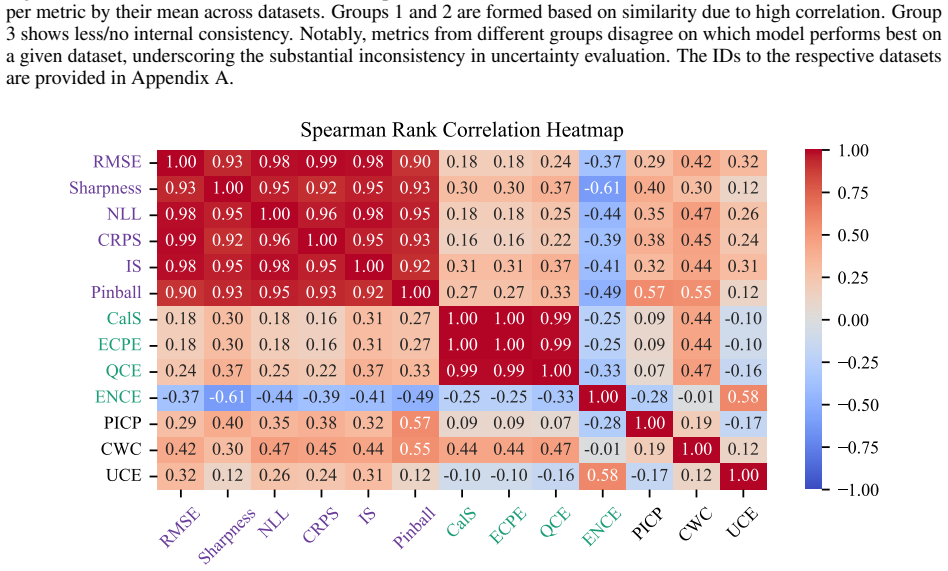
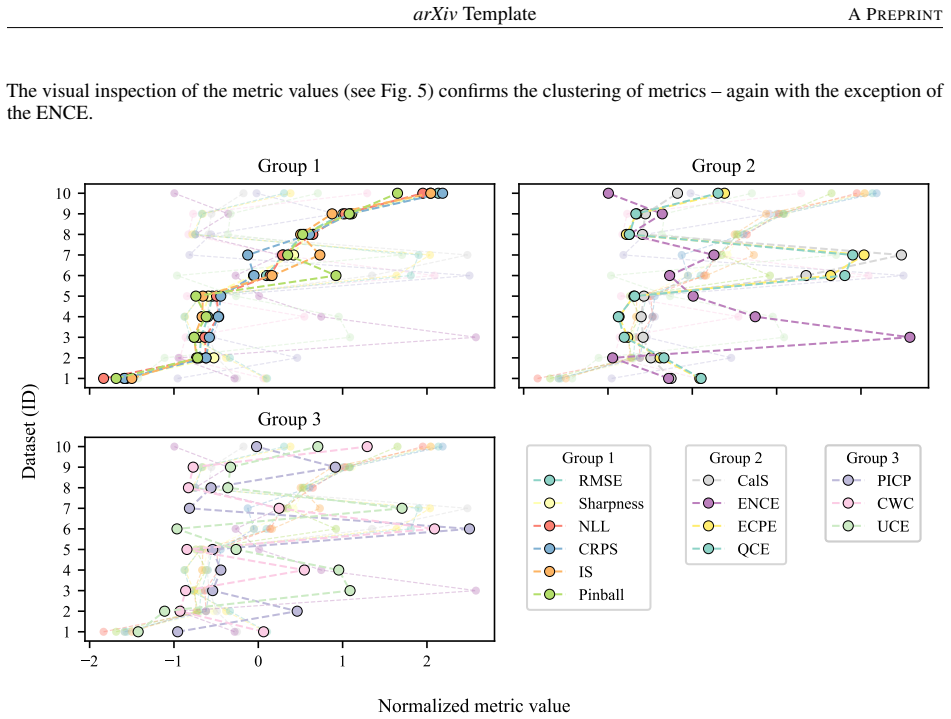
Calibration metrics for regression models frequently disagree when evaluating the same recalibration results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through controlled experiments with real-world, synthetic and artificially miscalibrated data, calibration metrics frequently produce conflicting results. Many metrics disagree in their evaluation of the same recalibration result, and some even indicate contradictory conclusions. This inconsistency is particularly concerning as it potentially allows cherry-picking of metrics to create misleading impressions of success. The Expected Normalized Calibration Error (ENCE) and the Coverage Width-based Criterion (CWC) are identified as the most dependable metrics in the tests.
What carries the argument
Systematic categorization and independent benchmarking of regression calibration metrics on controlled datasets, independent of specific modeling methods or recalibration approaches.
If this is right
- Recalibration methods may appear successful under one metric but fail under others, so reported improvements may not generalize across notions of calibration.
- Researchers could select only favorable metrics to present misleading impressions of recalibration success.
- Metric choice becomes a decisive factor in how calibration research outcomes are interpreted and compared.
- ENCE and CWC offer more stable evaluations than many alternatives in the tested scenarios.
Where Pith is reading between the lines
- Future studies might benefit from reporting results across a standardized set of multiple metrics to limit selective interpretation.
- Developing metrics with stronger mutual agreement could address the root cause of conflicting conclusions.
- Practical deployment of calibrated models may need ensemble checks using several metrics rather than any single one.
Load-bearing premise
Controlled experiments using artificially miscalibrated data can reliably expose the strengths and weaknesses of calibration metrics as they would behave on real-world data.
What would settle it
Demonstrating consistent agreement across a wide range of calibration metrics on diverse real-world recalibrated regression models would challenge the finding of substantial inconsistencies.
Figures







read the original abstract
In safety-critical applications data-driven models must not only be accurate but also provide reliable uncertainty estimates. This property, commonly referred to as calibration, is essential for risk-aware decision-making. In regression a wide variety of calibration metrics and recalibration methods have emerged. However, these metrics differ significantly in their definitions, assumptions and scales, making it difficult to interpret and compare results across studies. Moreover, most recalibration methods have been evaluated using only a small subset of metrics, leaving it unclear whether improvements generalize across different notions of calibration. In this work, we systematically extract and categorize regression calibration metrics from the literature and benchmark these metrics independently of specific modelling methods or recalibration approaches. Through controlled experiments with real-world, synthetic and artificially miscalibrated data, we demonstrate that calibration metrics frequently produce conflicting results. Our analysis reveals substantial inconsistencies: many metrics disagree in their evaluation of the same recalibration result, and some even indicate contradictory conclusions. This inconsistency is particularly concerning as it potentially allows cherry-picking of metrics to create misleading impressions of success. We identify the Expected Normalized Calibration Error (ENCE) and the Coverage Width-based Criterion (CWC) as the most dependable metrics in our tests. Our findings highlight the critical role of metric selection in calibration research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically categorizes regression calibration metrics from the literature and evaluates them through controlled experiments on real-world, synthetic, and artificially miscalibrated data. It claims that these metrics frequently disagree or yield contradictory verdicts on identical recalibration outcomes, raising concerns about cherry-picking, and identifies ENCE and CWC as the most reliable based on the tests.
Significance. If the inconsistencies are robust, the work would highlight a methodological weakness in how calibration is assessed across studies, potentially improving standards for uncertainty quantification in safety-critical regression applications. The empirical benchmarking approach, independent of specific models, is a strength if the experimental construction holds.
major comments (2)
- [Experimental setup / controlled experiments section] Experimental setup (artificial miscalibration): The perturbations such as uniform variance scaling and mean shifts may generate miscalibration patterns whose joint error-uncertainty distribution differs from those arising in naturally trained regressors (e.g., input-dependent heteroscedasticity or quantile distortions correlated with features). This risks inflating reported metric disagreements; a direct comparison to naturally miscalibrated models from standard training procedures is needed to confirm the inconsistencies indict the metrics rather than the construction.
- [Results / analysis of inconsistencies] Results on conflicting verdicts: The claim that 'some even indicate contradictory conclusions' requires explicit quantification (e.g., percentage of recalibration cases where one metric improves while another worsens, with statistical significance). Without this, it is unclear whether the inconsistencies are frequent enough to undermine typical recalibration evaluations.
minor comments (2)
- [Metric categorization] Clarify the exact definitions and formulas for all categorized metrics in a dedicated table or appendix to aid reproducibility.
- [Abstract and results] The abstract mentions 'real-world, synthetic and artificially miscalibrated data' but the relative contribution of each to the inconsistency findings should be broken out more clearly.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and robustness of our analysis. We address each major comment in detail below.
read point-by-point responses
-
Referee: [Experimental setup / controlled experiments section] Experimental setup (artificial miscalibration): The perturbations such as uniform variance scaling and mean shifts may generate miscalibration patterns whose joint error-uncertainty distribution differs from those arising in naturally trained regressors (e.g., input-dependent heteroscedasticity or quantile distortions correlated with features). This risks inflating reported metric disagreements; a direct comparison to naturally miscalibrated models from standard training procedures is needed to confirm the inconsistencies indict the metrics rather than the construction.
Authors: We agree that artificial perturbations such as uniform variance scaling and mean shifts may produce joint error-uncertainty distributions that differ from those in naturally trained regressors. While our experiments already incorporate real-world datasets (where miscalibrations arise from standard training) and synthetic data, we acknowledge that a more explicit comparison would strengthen the claim that metric inconsistencies are not an artifact of the artificial construction. In the revised manuscript we will add a subsection that directly compares the distributions and metric behaviors under artificial perturbations versus naturally miscalibrated models obtained from standard training procedures on the same datasets. revision: yes
-
Referee: [Results / analysis of inconsistencies] Results on conflicting verdicts: The claim that 'some even indicate contradictory conclusions' requires explicit quantification (e.g., percentage of recalibration cases where one metric improves while another worsens, with statistical significance). Without this, it is unclear whether the inconsistencies are frequent enough to undermine typical recalibration evaluations.
Authors: We agree that explicit quantification would make the prevalence of conflicting verdicts clearer. In the revised results section we will add a table reporting the percentage of recalibration cases (across all datasets, models, and recalibration methods) in which one metric registers improvement while another registers degradation or no change. We will also include statistical significance assessments using paired Wilcoxon tests or bootstrap confidence intervals to evaluate whether the observed disagreements are systematic rather than due to sampling variability. revision: yes
Circularity Check
No circularity: empirical benchmarking of calibration metrics on controlled data
full rationale
The paper performs an empirical analysis by cataloging regression calibration metrics from the literature and evaluating them through direct comparisons on real-world, synthetic, and artificially miscalibrated datasets. Central claims about metric inconsistencies and contradictory conclusions arise from observable differences in metric outputs under these experiments, without any derivation chains, fitted parameters renamed as predictions, or self-referential definitions that reduce the results to their inputs by construction. The study is self-contained against external benchmarks, relying on reproducible experimental disagreements rather than theoretical constructs or self-citations that bear the load of the main findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Calibration metrics can be meaningfully compared and benchmarked independently of any specific modeling method or recalibration technique.
Reference graph
Works this paper leans on
-
[1]
Max-Heinrich Laves, Sontje Ihler, Jacob F
doi:10.1109/TITS.2025.3532803. Max-Heinrich Laves, Sontje Ihler, Jacob F. Fast, Lüder A. Kahrs, and Tobias Ortmaier. Well-Calibrated Regression Uncertainty in Medical Imaging with Deep Learning. InProceedings of the Third Conference on Medical Imaging with Deep Learning, volume 121 ofProceedings of Machine Learning Research, pages 393–412. PMLR, July
-
[2]
doi:https://doi.org/10.1016/j.eswa.2022.116659
ISSN 0957-4174. doi:https://doi.org/10.1016/j.eswa.2022.116659. Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1050–1059, New York, New York, USA, 20–22 Jun
-
[3]
doi:10.1109/MCI.2022.3155327. Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U. Rajendra Acharya, Vladimir Makarenkov, and Saeid Nahavandi. A review of uncertainty quantification in deep learning: Techniques, applications and challenges.Information Fusion, 76: 243–...
-
[4]
doi:10.1016/j.inffus.2021.05.008. H. M. Dipu Kabir, Abbas Khosravi, Mohammad Anwar Hosen, and Saeid Nahavandi. Neural Network-Based Uncertainty Quantification: A Survey of Methodologies and Applications.IEEE Access, 6:36218–36234,
-
[5]
doi:10.1109/ACCESS.2018.2836917. Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, Muhammad Shahzad, Wen Yang, Richard Bamler, and Xiao Xiang Zhu. A survey of uncertainty in deep neural networks.Artificial Intelligence Review, 56(1):1513–1...
-
[6]
doi:10.1007/s10462-023-10562-9
ISSN 1573-7462. doi:10.1007/s10462-023-10562-9. Eyke Hüllermeier and Willem Waegeman. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods.Machine Learning, 110(3):457–506, March
-
[7]
Laurens Sluijterman, Eric Cator, and Tom Heskes
doi:10.1007/s10994-021-05946-3. Laurens Sluijterman, Eric Cator, and Tom Heskes. How to evaluate uncertainty estimates in machine learning for regression?Neural Networks, 173:106203,
-
[8]
Wenchong He, Zhe Jiang, Tingsong Xiao, Zelin Xu, and Yukun Li
doi:https://doi.org/10.1016/j.neunet.2024.106203. Wenchong He, Zhe Jiang, Tingsong Xiao, Zelin Xu, and Yukun Li. A Survey on Uncertainty Quantification Methods for Deep Learning, January
-
[9]
arXiv:2302.13425 [cs]. Apostolos F. Psaros, Xuhui Meng, Zongren Zou, Ling Guo, and George Em Karniadakis. Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons.Journal of Computational Physics, 477:111902, March
-
[10]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q
doi:10.1016/j.jcp.2022.111902. Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On Calibration of Modern Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, August
-
[11]
Victor Dheur and Souhaib Ben Taieb
doi:10.3390/s22155540. Victor Dheur and Souhaib Ben Taieb. A Large-Scale Study of Probabilistic Calibration in Neural Network Regression. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 7813–7836. PMLR, July
-
[12]
Parametric and Multivariate Uncertainty Calibration for Regression and Object Detection
Fabian Küppers, Jonas Schneider, and Anselm Haselhoff. Parametric and Multivariate Uncertainty Calibration for Regression and Object Detection. InComputer Vision – ECCV 2022 Workshops, pages 426–442, Cham,
work page 2022
-
[13]
doi:10.1371/journal.pcbi.1011392. A. Khosravi, S. Nahavandi, D. Creighton, and A. F. Atiya. Comprehensive Review of Neural Network-Based Prediction Intervals and New Advances.IEEE Transactions on Neural Networks, 22(9):1341–1356, September
-
[14]
doi:10.1109/TNN.2011.2162110. 23 arXivTemplateA PREPRINT Simon Kristoffersson Lind, Ziliang Xiong, Per-Erik Forssén, and V olker Krüger. Uncertainty quantification metrics for deep regression.Pattern Recognition Letters, 186:91–97, October
-
[15]
doi:10.1016/j.patrec.2024.09.011
ISSN 01678655. doi:10.1016/j.patrec.2024.09.011. Tilmann Gneiting and Adrian E Raftery. Strictly Proper Scoring Rules, Prediction, and Estimation.Journal of the American Statistical Association, 102(477):359–378, March
-
[16]
Strictly proper scoring rules, prediction, and estimation
doi:10.1198/016214506000001437. Eric Zelikman, Christopher Healy, Sharon Zhou, and Anand Avati. CRUDE: Calibrating Regression Uncertainty Distributions Empirically, March
-
[17]
Shengjia Zhao, Tengyu Ma, and Stefano Ermon
arXiv:2005.12496 [cs]. Shengjia Zhao, Tengyu Ma, and Stefano Ermon. Individual Calibration with Randomized Forecasting. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 11387–11397. PMLR, July
-
[18]
Youngseog Chung, Ian Char, Han Guo, Jeff Schneider, and Willie Neiswanger
arXiv:2506.01486 [cs.LG]. Youngseog Chung, Ian Char, Han Guo, Jeff Schneider, and Willie Neiswanger. Uncertainty Toolbox: an Open-Source Library for Assessing, Visualizing, and Improving Uncertainty Quantification, 2021b. arXiv:2109.10254 [cs.LG]. F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. W...
-
[19]
https: //doi.org/10.24432/C5QK55. Jacob Feldmesser. Computer hardware. UCI Machine Learning Repository,
-
[20]
Warwick Nash, Tracy Sellers, Simon Talbot, Andrew Cawthorn, and Wes Ford
https://doi.org/10.24432/ C5830D. Warwick Nash, Tracy Sellers, Simon Talbot, Andrew Cawthorn, and Wes Ford. Abalone. UCI Machine Learning Repository, 1995.https://doi.org/10.24432/C55C7W. Paulo Cortez, António Cerdeira, Fernando Almeida, Telmo Matos, and José Reis. Modeling wine preferences by data mining from physicochemical properties.Decision Support S...
-
[21]
https://doi.org/10.24432/C5VW2C. Kam Hamidieh. Superconductivty data. UCI Machine Learning Repository,
-
[22]
https: //doi.org/10.24432/C5PG66. Karl Ulrich. Servo. UCI Machine Learning Repository, 1993.https://doi.org/10.24432/C5Q30F. I-Cheng Yeh. Concrete compressive strength. UCI Machine Learning Repository,
-
[23]
Athanasios Tsanas, Max Little, Patrick McSharry, and Lorraine Ramig
https: //doi.org/10.24432/C5002N. Athanasios Tsanas, Max Little, Patrick McSharry, and Lorraine Ramig. Accurate telemonitoring of parkinson’s disease progression by non-invasive speech tests.Nature Precedings, pages 1–1,
-
[24]
An Dinh, Stacey Miertschin, Amber Young, and Somya D
https: //doi.org/10.24432/C51307. An Dinh, Stacey Miertschin, Amber Young, and Somya D. Mohanty. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning.BMC medical informatics and decision making, 19(1):1–15,
-
[25]
net:cal - Uncertainty Calibration
24 arXivTemplateA PREPRINT Table 2: List of used real-world datasets. No. (ID) Name Number of samples after cleaning Ref. 1 forest-fires 513 [Cortez and Morais, 2008] 2 facebook-metrics 493 [Moro et al., 2016] 3 computer-hardware 206 [Feldmesser, 1987] 4 abalone 4145 [Nash et al., 1995] 5 winequality-white 6494 [Cortez et al., 2009] 6 airfoil-self-noise 1...
work page 2008
-
[26]
All synthetic datasets consist of 1000 samples and are generated without noise
Some of the synthetic datasets are created using the sklearn library [Pedregosa et al., 2011]. All synthetic datasets consist of 1000 samples and are generated without noise. For both dataset types, all features are normalized by minmax-scaling between 0 and
work page 2011
-
[27]
To avoid model distortions due to exceeding noise or erroneous samples, all datasets are cleaned of outliers using an isolation forest outlier detection with a probability threshold of 0.8 [Liu et al., 2012]. 4https://github.com/EFS-OpenSource/calibration-framework 5https://uncertainty-toolbox.github.io/ 6https://archive.ics.uci.edu/ 25 arXivTemplateA PRE...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.