Improving the Accuracy of Amortized Model Comparison with Self-Consistency
Pith reviewed 2026-05-18 21:12 UTC · model grok-4.3
The pith
Self-consistency training on unlabeled real data improves amortized Bayesian model comparison accuracy when all candidate models are misspecified.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the open-world scenario where all models are misspecified, self-consistency training on unlabeled real data strongly improves the accuracy of amortized BMC estimators that rely on analytic likelihoods or on surrogate likelihoods that remain locally accurate near the true parameter posterior, even for severely misspecified models.
What carries the argument
Self-consistency loss applied to unlabeled real data, which regularizes the neural surrogates by enforcing agreement in model probability estimates across different transformations of the same observations.
If this is right
- Classifier-based BMC methods perform adequately without self-consistency in closed-world settings but improve the least from the added training.
- Self-consistency yields substantial gains in open-world settings whenever analytic likelihoods or locally accurate surrogates are present.
- Practical use of amortized BMC should incorporate self-consistency whenever misspecification is suspected.
- Future extensions could explore self-consistency for other forms of distribution shift in simulation-based inference.
Where Pith is reading between the lines
- Similar consistency losses on real data could improve other amortized inference pipelines that face distribution shifts.
- The approach suggests hybrid simulation-plus-real training can lessen dependence on perfectly specified generative models.
- Testing the method on hierarchical or high-dimensional models would clarify how far the local-accuracy condition can stretch.
- The pattern connects to consistency regularization techniques already used to handle shifts in supervised learning.
Load-bearing premise
Surrogate likelihoods must remain locally accurate near the true parameter posterior or analytic likelihoods must be available for at least some of the models being compared.
What would settle it
An experiment showing no accuracy improvement from self-consistency training in an open-world case where surrogate likelihoods deviate substantially outside the region near the true posterior would falsify the central claim.
Figures



read the original abstract
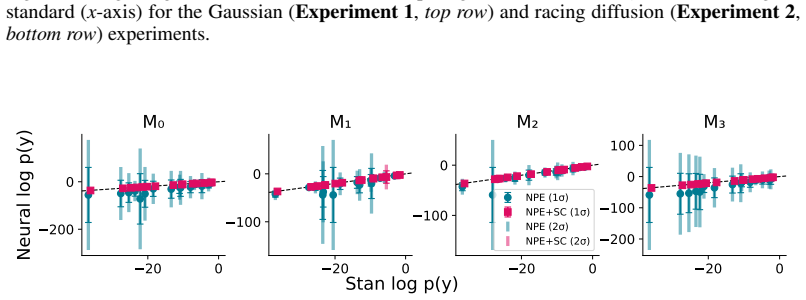
Amortized Bayesian model comparison (BMC) enables fast probabilistic ranking of models via simulation-based training of neural surrogates. However, the accuracy of neural surrogates deteriorates when simulation models are misspecified; the very case where model comparison is most needed. We evaluate four different amortized BMC methods. We supplement traditional simulation-based training of these methods with a \emph{self-consistency} (SC) loss on unlabeled real data to improve BMC estimates under distribution shifts. Using one artificial and two real-world case studies, we compare amortized BMC estimators with and without SC against analytic or bridge sampling benchmarks. In the \emph{closed-world} case (data is generated by one of the candidate models), BMC estimators using classifiers work acceptably well even without SC training. However, these methods also benefit the least from SC training. In the \emph{open-world} scenario (all models misspecified), SC training strongly improves BMC estimators when having access to analytic likelihoods, or when surrogate likelihoods are locally accurate near the true parameter posterior, even for severely misspecified models. We conclude with practical recommendations for amortized BMC and suggestions for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a self-consistency (SC) loss on unlabeled real data to supplement simulation-based training of four amortized Bayesian model comparison (BMC) methods. It evaluates these with and without SC on one artificial and two real-world case studies, benchmarking against analytic likelihoods or bridge sampling. Key findings: classifiers perform adequately without SC in closed-world settings (data generated by a candidate model) but gain least from SC; in open-world settings (all models misspecified), SC yields strong improvements when analytic likelihoods are available or when surrogate likelihoods remain locally accurate near the true posterior, even under severe misspecification. The work concludes with practical recommendations.
Significance. If the central findings hold after addressing verification gaps, the work would offer a practical enhancement to amortized BMC for the common case of misspecified simulation models, where model comparison is most needed. The explicit conditioning of gains on local surrogate accuracy and the closed- vs. open-world distinction provide useful guidance, and the use of external benchmarks (analytic/bridge sampling) strengthens the evaluation relative to purely internal metrics.
major comments (1)
- [real-world case studies / open-world scenario] Real-world case studies (open-world experiments without analytic likelihoods): The claim that SC training strongly improves BMC estimators 'even for severely misspecified models' when surrogate likelihoods are locally accurate near the true parameter posterior is load-bearing for the open-world conclusion, yet no independent diagnostic is reported to confirm this local accuracy condition holds (e.g., no local KL divergence, restricted posterior-predictive calibration, or likelihood-ratio tests in a neighborhood of the inferred posterior). Without such a check, observed gains cannot be confidently attributed to the stated mechanism rather than other factors.
minor comments (2)
- [abstract and experiments] The abstract and experiments section would benefit from explicit reporting of error bars, number of runs, and any exclusion criteria for the benchmark comparisons to allow readers to assess variability and robustness.
- [methods] Clarify the precise definitions and architectural differences among the four amortized BMC methods early in the methods section, including how the SC loss is integrated with each.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The distinction between closed- and open-world settings and the emphasis on local surrogate accuracy are central to our claims; we address the verification concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [real-world case studies / open-world scenario] Real-world case studies (open-world experiments without analytic likelihoods): The claim that SC training strongly improves BMC estimators 'even for severely misspecified models' when surrogate likelihoods are locally accurate near the true parameter posterior is load-bearing for the open-world conclusion, yet no independent diagnostic is reported to confirm this local accuracy condition holds (e.g., no local KL divergence, restricted posterior-predictive calibration, or likelihood-ratio tests in a neighborhood of the inferred posterior). Without such a check, observed gains cannot be confidently attributed to the stated mechanism rather than other factors.
Authors: We agree that an independent diagnostic would strengthen attribution of the observed SC gains to the local-accuracy mechanism rather than to other factors. In the real-world case studies the surrogate likelihoods were chosen on the basis of domain knowledge and were already subjected to global posterior-predictive checks; however, these checks were not restricted to neighborhoods of the inferred posterior. We will revise the manuscript to (i) report restricted posterior-predictive calibration and local likelihood-ratio diagnostics where computationally feasible, (ii) add an explicit limitations paragraph stating that the local-accuracy assumption remains partly inferential in the absence of analytic likelihoods, and (iii) temper the wording of the open-world conclusion to reflect this conditional support. These additions do not require new simulation experiments but will make the evidential basis for the claim more transparent. revision: partial
Circularity Check
No circularity: improvements validated against external analytic and bridge-sampling benchmarks.
full rationale
The paper defines a self-consistency loss added to simulation-based training of neural surrogates for amortized BMC and reports empirical gains in open-world misspecification settings. All reported improvements are measured against independent external references (analytic likelihoods or bridge sampling) rather than quantities defined by the fitted parameters or loss inside the paper. No derivation step equates a prediction to its own input by construction, renames a fitted quantity as a forecast, or relies on a load-bearing self-citation whose validity is presupposed by the present work. The central claims therefore remain self-contained and falsifiable outside the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural surrogates trained on simulations can approximate model posterior probabilities
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We supplement simulation-based training with a self-consistency (SC) loss on unlabeled real data to improve BMC estimates under empirical distribution shifts.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
log p(y | Mk) ≈ log p(θ∗k | Mk) + log p(y | θ∗k, Mk) − log qϕ(θ∗k | y, Mk)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cambridge university press, 2003
David JC MacKay.Information theory, inference and learning algorithms. Cambridge university press, 2003
work page 2003
-
[2]
Bayesian model selection, the marginal likelihood, and generalization
Sanae Lotfi, Pavel Izmailov, Gregory Benton, Micah Goldblum, and Andrew Gordon Wil- son. Bayesian model selection, the marginal likelihood, and generalization. In International Conference on Machine Learning, pages 14223–14247. PMLR, 2022
work page 2022
-
[3]
Amortized bayesian model comparison with evidential deep learning
Stefan T Radev, Marco D’Alessandro, Ulf K Mertens, Andreas V oss, Ullrich Koethe, and Paul-Christian Buerkner. Amortized bayesian model comparison with evidential deep learning. IEEE Transactions on Neural Networks and Learning Systems, 34(8):4903–4917, 2021
work page 2021
-
[4]
JANA: Jointly amortized neural approximation of complex Bayesian models
Stefan T Radev, Marvin Schmitt, Valentin Pratz, Umberto Picchini, Ullrich Köthe, and Paul- Christian Bürkner. JANA: Jointly amortized neural approximation of complex Bayesian models. In Uncertainty in Artificial Intelligence, pages 1695–1706. PMLR, 2023
work page 2023
-
[5]
Generalized out-of-distribution detection: A survey
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey. International Journal of Computer Vision, 132(12):5635–5662, 2024
work page 2024
-
[6]
Detecting model misspecification in amortized Bayesian inference with neural networks
Marvin Schmitt, Paul-Christian Bürkner, Ullrich Köthe, and Stefan T Radev. Detecting model misspecification in amortized Bayesian inference with neural networks. In Dagm german conference on pattern recognition, pages 541–557. Springer, 2023
work page 2023
-
[7]
The statistical accuracy of neural posterior and likelihood estimation
David T Frazier, Ryan Kelly, Christopher Drovandi, and David J Warne. The statistical accuracy of neural posterior and likelihood estimation. arXiv preprint arXiv:2411.12068, 2024
-
[8]
Ivanova, Daniel Habermann, Ullrich Köthe, Paul-Christian Bürkner, and Stefan T
Marvin Schmitt, Desi R. Ivanova, Daniel Habermann, Ullrich Köthe, Paul-Christian Bürkner, and Stefan T. Radev. Leveraging Self-Consistency for Data-Efficient Amortized Bayesian Inference, July 2024. URL http://arxiv.org/abs/2310.04395. arXiv:2310.04395 [cs]
-
[9]
Ivanova, Marvin Schmitt, and Stefan T
Desi R. Ivanova, Marvin Schmitt, and Stefan T. Radev. Data-Efficient Variational Mutual Infor- mation Estimation via Bayesian Self-Consistency. In NeurIPS BDU Workshop 2024, October
work page 2024
-
[10]
URL https://openreview.net/forum?id=QfiyElaO1f¬eId=aRvehpmMkK
-
[11]
Radev, and Paul-Christian Bürkner
Aayush Mishra, Daniel Habermann, Marvin Schmitt, Stefan T. Radev, and Paul-Christian Bürkner. Robust Amortized Bayesian Inference with Self-Consistency Losses on Unlabeled Data, May 2025. URL http://arxiv.org/abs/2501.13483. arXiv:2501.13483 [stat]. 5
-
[12]
Robert E Kass and Adrian E Raftery. Bayes factors. Journal of the american statistical association, 90(430):773–795, 1995
work page 1995
-
[13]
bridgesampling: An R package for estimating normalizing constants
Quentin F Gronau, Henrik Singmann, and Eric-Jan Wagenmakers. bridgesampling: An R package for estimating normalizing constants. Journal of Statistical Software, 92:1–29, 2020
work page 2020
-
[14]
Marginal likelihood computation for model selection and hypothesis testing: an extensive review
Fernando Llorente, Luca Martino, David Delgado, and Javier Lopez-Santiago. Marginal likelihood computation for model selection and hypothesis testing: an extensive review. SIAM review, 65(1):3–58, 2023
work page 2023
-
[15]
Bayesian evidence and model selection
Kevin H Knuth, Michael Habeck, Nabin K Malakar, Asim M Mubeen, and Ben Placek. Bayesian evidence and model selection. Digital Signal Processing, 47:50–67, 2015
work page 2015
-
[16]
Strictly proper scoring rules, prediction, and estimation
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007
work page 2007
-
[17]
https://doi.org/10.48550/arXiv.2311.15650, arXiv:2311.15650
Konstantin Karchev, Roberto Trotta, and Christoph Weniger. SimSIMS: Simulation-based Su- pernova Ia Model Selection with thousands of latent variables.arXiv preprint arXiv:2311.15650, 2023
-
[18]
Konstantina Sokratous, Anderson K Fitch, and Peter D Kvam. How to ask twenty questions and win: Machine learning tools for assessing preferences from small samples of willingness-to-pay prices. Journal of choice modelling, 48:100418, 2023
work page 2023
-
[19]
Validation and comparison of non-stationary cognitive models: A diffusion model application
Lukas Schumacher, Martin Schnuerch, Andreas V oss, and Stefan T Radev. Validation and comparison of non-stationary cognitive models: A diffusion model application. Computational Brain & Behavior, 8(2):191–210, 2025
work page 2025
-
[20]
A deep learning method for comparing Bayesian hierarchical models
Lasse Elsemüller, Martin Schnuerch, Paul-Christian Bürkner, and Stefan T Radev. A deep learning method for comparing Bayesian hierarchical models. Psychological Methods, 2024
work page 2024
-
[21]
Simultaneous identification of models and parameters of scientific simulators
Cornelius Schröder and Jakob H Macke. Simultaneous identification of models and parameters of scientific simulators. In Proceedings of the 41st International Conference on Machine Learning, pages 43895–43927, 2024
work page 2024
-
[22]
Evidence Networks: Simple losses for fast, amortized, neural Bayesian model comparison
Niall Jeffrey and Benjamin D Wandelt. Evidence Networks: Simple losses for fast, amortized, neural Bayesian model comparison. Machine Learning: Science and Technology, 5(1):015008, 2024
work page 2024
-
[23]
Bayesian model comparison for simulation-based inference
A Spurio Mancini, MM Docherty, MA Price, and JD McEwen. Bayesian model comparison for simulation-based inference. RAS Techniques and Instruments, 2(1):710–722, 2023
work page 2023
-
[24]
Bayesian evidence estimation from posterior samples with normalizing flows
Rahul Srinivasan, Marco Crisostomi, Roberto Trotta, Enrico Barausse, and Matteo Breschi. Bayesian evidence estimation from posterior samples with normalizing flows. Physical Review D, 110(12):123007, 2024
work page 2024
-
[25]
A diffusion model account of criterion shifts in the lexical decision task
Eric-Jan Wagenmakers, Roger Ratcliff, Pablo Gomez, and Gail McKoon. A diffusion model account of criterion shifts in the lexical decision task. Journal of memory and language, 58(1): 140–159, 2008
work page 2008
-
[26]
Gabriel Tillman, Trish Van Zandt, and Gordon D Logan. Sequential sampling models without random between-trial variability: The racing diffusion model of speeded decision making. Psychonomic Bulletin & Review, 27(5):911–936, 2020
work page 2020
-
[27]
Stan Development Team. Stan Reference Manual, 2025. URL https://mc-stan.org/. version 2.32.2
work page 2025
-
[28]
RStan: the R interface to Stan, 2025
Stan Development Team. RStan: the R interface to Stan, 2025. URL https://mc-stan.org/. R package version 2.32.7
work page 2025
-
[29]
Eurostat. International extra-eu air passenger transport by reporting country and partner world regions and countries, doi:10.2908/avia_paexcc, 2022
-
[30]
Eurostat. Household debt, consolidated including Non-profit institutions serving households - % of GDP, doi:10.2908/TIPSD22, 2022. 6
-
[31]
Real gdp per capita, doi:10.2908/SDG_08_10, 2022
Eurostat. Real gdp per capita, doi:10.2908/SDG_08_10, 2022
-
[32]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
Mish: A self regularized non-monotonic activation function
Diganta Misra. Mish: A self regularized non-monotonic activation function. arXiv preprint arXiv:1908.08681, 2019
- [34]
-
[35]
Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural spline flows. Advances in neural information processing systems, 32, 2019
work page 2019
-
[36]
Thomas Müller, Brian McWilliams, Fabrice Rousselle, Markus Gross, and Jan Novák. Neural importance sampling. ACM Transactions on Graphics (ToG), 38(5):1–19, 2019. 7 Appendix A The marginal likelihood and self-consistency We start with the Bayes’ theorem for parameter posterior given data, p(θk | y, Mk) = p(θk | Mk) × p(y | θk, Mk) p(y | Mk) , (8) where th...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.